Apple's M1 Pro, M1 Max SoCs Investigated: New Performance and Efficiency Heights
by Andrei Frumusanu on October 25, 2021 9:00 AM EST- Posted in
- Laptops
- Apple
- MacBook
- Apple M1 Pro
- Apple M1 Max
Huge Memory Bandwidth, but not for every Block
One highly intriguing aspect of the M1 Max, maybe less so for the M1 Pro, is the massive memory bandwidth that is available for the SoC.
Apple was keen to market their 400GB/s figure during the launch, but this number is so wild and out there that there’s just a lot of questions left open as to how the chip is able to take advantage of this kind of bandwidth, so it’s one of the first things to investigate.
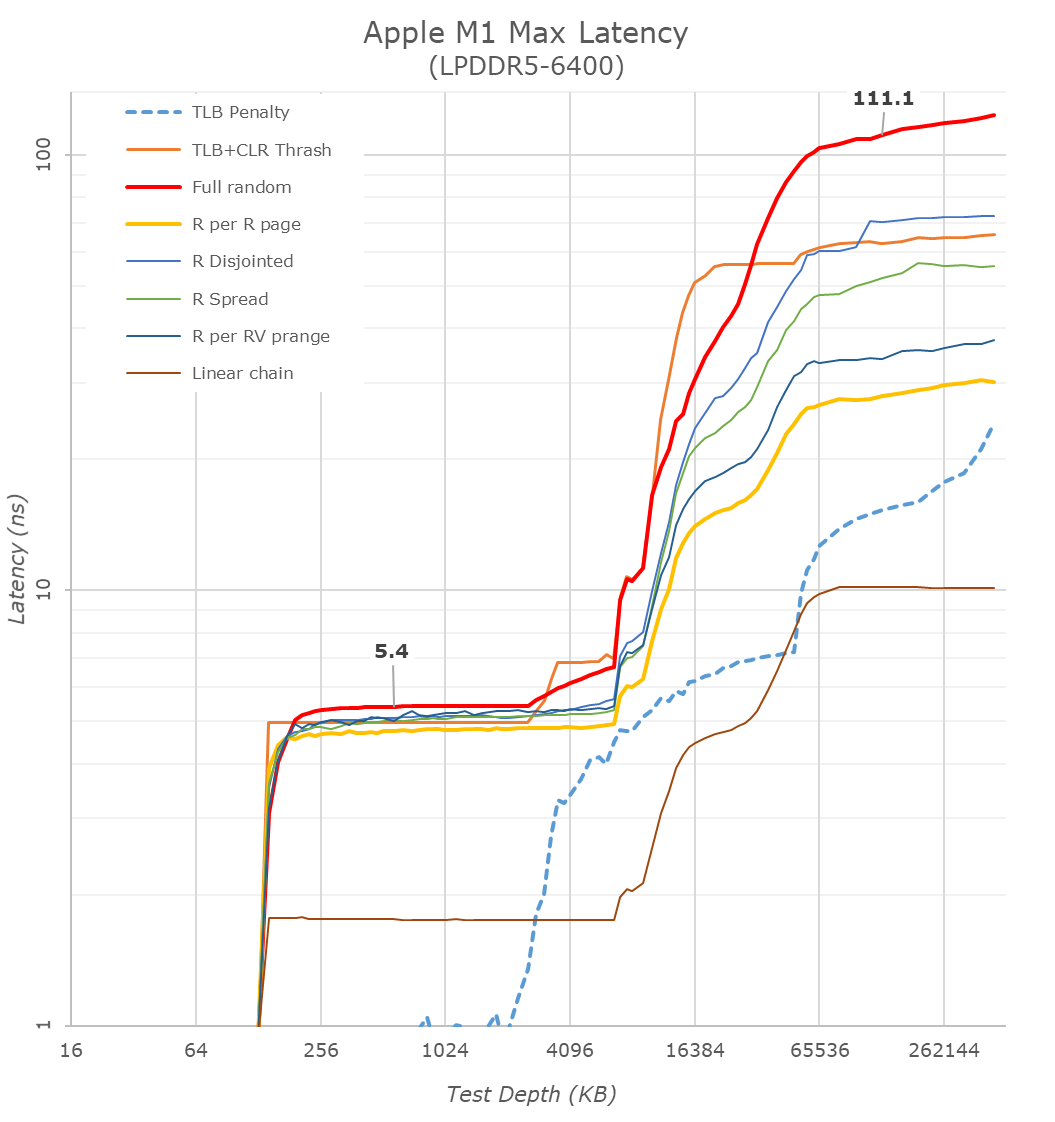
Starting off with our memory latency tests, the new M1 Max changes system memory behaviour quite significantly compared to what we’ve seen on the M1. On the core and L2 side of things, there haven’t been any changes and we consequently don’t see much alterations in terms of the results – it’s still a 3.2GHz peak core with 128KB of L1D at 3 cycles load-load latencies, and a 12MB L2 cache.
Where things are quite different is when we enter the system cache, instead of 8MB, on the M1 Max it’s now 48MB large, and also a lot more noticeable in the latency graph. While being much larger, it’s also evidently slower than the M1 SLC – the exact figures here depend on access pattern, but even the linear chain access shows that data has to travel a longer distance than the M1 and corresponding A-chips.
DRAM latency, even though on paper is faster for the M1 Max in terms of frequency on bandwidth, goes up this generation. At a 128MB comparable test depth, the new chip is roughly 15ns slower. The larger SLCs, more complex chip fabric, as well as possible worse timings on the part of the new LPDDR5 memory all could add to the regression we’re seeing here. In practical terms, because the SLC is so much bigger this generation, workloads latencies should still be lower for the M1 Max due to the higher cache hit rates, so performance shouldn’t regress.
A lot of people in the HPC audience were extremely intrigued to see a chip with such massive bandwidth – not because they care about GPU or other offload engines of the SoC, but because the possibility of the CPUs being able to have access to such immense bandwidth, something that otherwise is only possible to achieve on larger server-class CPUs that cost a multitude of what the new MacBook Pros are sold at. It was also one of the first things I tested out – to see exactly just how much bandwidth the CPU cores have access to.
Unfortunately, the news here isn’t the best case-scenario that we hoped for, as the M1 Max isn’t able to fully saturate the SoC bandwidth from just the CPU side;
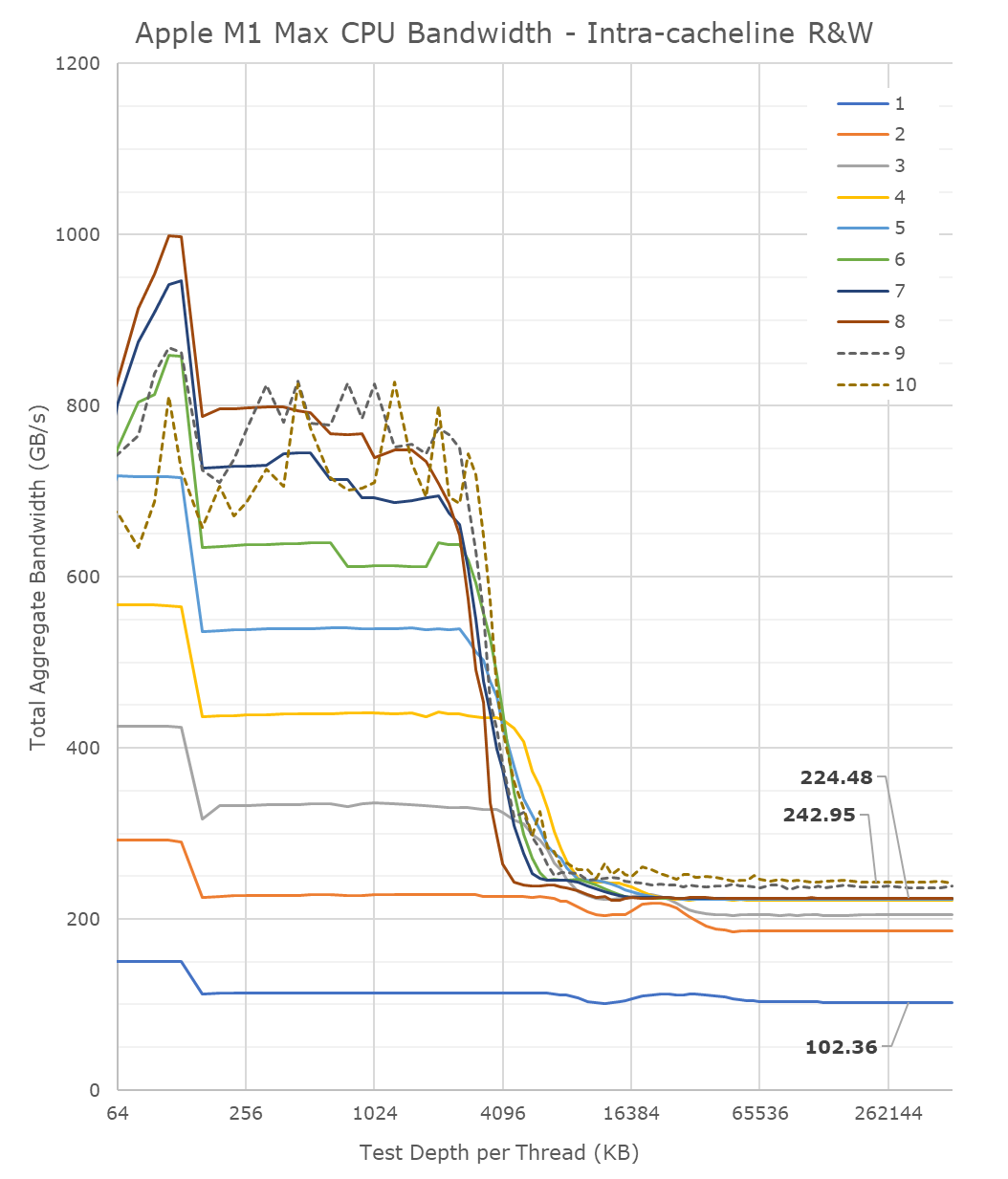
From a single core perspective, meaning from a single software thread, things are quite impressive for the chip, as it’s able to stress the memory fabric to up to 102GB/s. This is extremely impressive and outperforms any other design in the industry by multiple factors, we had already noted that the M1 chip was able to fully saturate its memory bandwidth with a single core and that the bottleneck had been on the DRAM itself. On the M1 Max, it seems that we’re hitting the limit of what a core can do – or more precisely, a limit to what the CPU cluster can do.
The little hump between 12MB and 64MB should be the SLC of 48MB in size, the reduction in BW at the 12MB figure signals that the core is somehow limited in bandwidth when evicting cache lines back to the upper memory system. Our test here consists of reading, modifying, and writing back cache lines, with a 1:1 R/W ratio.
Going from 1 core/threads to 2, what the system is actually doing is spreading the workload across the two performance clusters of the SoC, so both threads are on their own cluster and have full access to the 12MB of L2. The “hump” after 12MB reduces in size, ending earlier now at +24MB, which makes sense as the 48MB SLC is now shared amongst two cores. Bandwidth here increases to 186GB/s.
Adding a third thread there’s a bit of an imbalance across the clusters, DRAM bandwidth goes to 204GB/s, but a fourth thread lands us at 224GB/s and this appears to be the limit on the SoC fabric that the CPUs are able to achieve, as adding additional cores and threads beyond this point does not increase the bandwidth to DRAM at all. It’s only when the E-cores, which are in their own cluster, are added in, when the bandwidth is able to jump up again, to a maximum of 243GB/s.
While 243GB/s is massive, and overshadows any other design in the industry, it’s still quite far from the 409GB/s the chip is capable of. More importantly for the M1 Max, it’s only slightly higher than the 204GB/s limit of the M1 Pro, so from a CPU-only workload perspective, it doesn’t appear to make sense to get the Max if one is focused just on CPU bandwidth.
That begs the question, why does the M1 Max have such massive bandwidth? The GPU naturally comes to mind, however in my testing, I’ve had extreme trouble to find workloads that would stress the GPU sufficiently to take advantage of the available bandwidth. Granted, this is also an issue of lacking workloads, but for actual 3D rendering and benchmarks, I haven’t seen the GPU use more than 90GB/s (measured via system performance counters). While I’m sure there’s some productivity workload out there where the GPU is able to stretch its legs, we haven’t been able to identify them yet.
That leaves everything else which is on the SoC, media engine, NPU, and just workloads that would simply stress all parts of the chip at the same time. The new media engine on the M1 Pro and Max are now able to decode and encode ProRes RAW formats, the above clip is a 5K 12bit sample with a bitrate of 1.59Gbps, and the M1 Max is not only able to play it back in real-time, it’s able to do it at multiple times the speed, with seamless immediate seeking. Doing the same thing on my 5900X machine results in single-digit frames. The SoC DRAM bandwidth while seeking around was at around 40-50GB/s – I imagine that workloads that stress CPU, GPU, media engines all at the same time would be able to take advantage of the full system memory bandwidth, and allow the M1 Max to stretch its legs and differentiate itself more from the M1 Pro and other systems.








493 Comments
View All Comments
Ppietra - Thursday, October 28, 2021 - link
Gosh, no! not 2.35m people. You are so obsessed with a GPU having everything on silicon for itself that you fail to see how much more cache resources the SoC has when compared with other processors. Even if there was 1GB of cache you would still be complaining because the CPU can use it. Get some common sense.richardnpaul - Friday, October 29, 2021 - link
You're wrong. I've shown that your fringe is larger than some country's populations and you've dismissed it and pivoted back to another talking point, a point that is a misrepresentation of what I was saying.I was wondering what the effect was on performance of the CPU and GPU when both are being used and both are using the shared cache simultaneously given that we know that in isolation with just their own cache it improves efficiency. I'm not and haven't been saying it's an actual issue, it's something that could be tested, and also, we have no clue as to whether it's a real world problem or not.
The article was the one that was talking about the GPU and it having access to all the 512bit memory interface, I was challenging that saying that actually the CPU is going to use some of that bandwidth, but the benefit of the design is that when the GPU needs more and the CPU isn't using it it has access to it and vice-versa.
And if you knew anything about common sense you wouldn't say to get some of it. You're rude and dismissive of anyone else who doesn't fit into your world view, you might want to do something about fixing that about yourself; but probably you won't.
Ppietra - Friday, October 29, 2021 - link
No, you haven’t shown anything, because for whatever reason you continue to ignore how big the cache is when compared with anything else out there, and how big the L2 cache is, also when compared with anything else out there - something that they don’t share. Thirdly, if you even tried to pay attention to what was said, you would see that the M1 Max has double the system cache size, and yet not much different CPU performance.You also continue to ignore that in a game (which is the thing you are obsessing about), CPU and GPU work together. Not having to send instructions to an external GPU, and CPU and GPU being able to work on the same data stored in cache, gives a big performance improvement, it removes bottlenecks. So you obsessing because the CPU can use system cache during a game makes no sense, because the sharing can actually give a boost in game performance.
Fringe cases would never be equivalent to every gamer.
richardnpaul - Friday, October 29, 2021 - link
"continue to ignore how big the cache is when compared with anything else out there"Like the previously mentioned RX 6800 which has 256MB? I've not mentioned the RX6800 (infinity) cache at all?
The L2 cache is large, but then it doesn't have an L3 cache. This is a balancing act that chip architects engage with all the time. It seems that zen3 and the M1 Max graphs are very similar for latency with full random being a little higher but most everything else looking close enough that I'm not going to stick my neck out and declare either a winner.
"and CPU and GPU being able to work on the same data stored in cache, gives a big performance improvement, it removes bottlenecks"
This is not represented in the benchmarking, which might be because there needs to be some specific optimisation done, or it could be due to something else. I expect the situation to improve though, probable with more focus on the M1 Pro which will carry over to the Max.
Ppietra - Friday, October 29, 2021 - link
You are not going to see something in benchmark that is inherent to how the system works, how it manages memory, there is no off switch. You need to have the knowledge of how things work."The L2 cache is large, but then it doesn't have an L3 cache."????????????????
System cache behaves as if it was a L3 cache for the CPU. How can you say that zen 3 and M1 are similar when the M1 Max has 3.5 times the cache size of a laptop Ryzen??? Just the L2 cache is larger than all the cache available in a laptop Ryzen.
"RX 6800 which has 256MB?" A RX6800 isn’t a laptop chip. [" laptop processors " - - it’s there in one of the first comments]
richardnpaul - Saturday, October 30, 2021 - link
This is where you need to look at the latency graphs for M1 Pro/Max and then go and find the Zen 3 article and compare the graphs for yourself. And I haven't been comparing the M1 Max to a laptop Ryzen, I have repeatedly compared it to a single zen3 core complex where they are much closer in terms of total cache. Compare the 5nm M1 Max to the 7nm Zen3 all you like, with its much higher transistor count. You're not talking about the same thing as I was all along.I have repeatedly compared whatever is the closest comparison, regardless of where its used to get a helpful idea of what benefits it could bring. That Apple have managed to do this in a laptop's power budget is, and I'll quote myself here "a technological marvel". The M1 Pro/Max are combined GPUs and CPUs, that means you can compare them to standalone GPUs and to CPUs. You're the one who can't seem to understand that they both need to stand on their own merits.
Ppietra - Saturday, October 30, 2021 - link
Really!??? You want to compare a laptop processor with Desktop chips that can consume 3-4 times more than the all laptop, and you think that is close? no common sense whatsoever!But guess what even then a M1 Max has more cache available than a consumer desktop Ryzen!
The latency graphs are for the CPU (which, by the way you can actually see differences because of the size of the level 1 and 2 caches even with desktop Ryzen), they don’t tell you anything when you want to compare the response latency between CPU and GPU, nor about the performance boost from processing the CPU and GPU being able to process the same data in cache without having to access RAM.
Who said you cannot compare with dedicated GPUs?
richardnpaul - Sunday, October 31, 2021 - link
I'm comparing architectures, not products, that's why it seems to you like this is an "unfair" comparison. I also bear in mind what node the architecture is at, as that makes quite a marked difference due to transistor budget constraints.Yes M1 Max has more cache, and where you're not using the GPU (a bit difficult as you'll be running an OS which has a GUI, but let's say that that is basically negligible) it should have a reasonable impact on usages which are heavy on memory bandwidth. In fact you can see that in the benchmarks, there are a number of which heavily reward the M1 Max over anything else, not that many in total but certain use cases will see great uplifts, just the same as Milan-X and the equivalent chiplets in Ryzen CPUs which we'll get to see in the next few days will have benefits in certain use cases.
What I was saying way back was, what's the contention there, when running a game, how much benefit is the GPU getting and if any how much is the CPU losing when contention starts to happen on the SLC. Caches usually work on some kind of LRU basis, so if two separate things are trying to use the same cache (which can have benefits where they are both using the cache for the same data) both suffer as their older cache data is evicted by the other processor. That should be measurable. Workloads that share the same data, if its small enough to fit into the 48MB on the Max, should see huge benefits, and yes, one application that has been highlighted has taken advantage of this. But we are yet to see others take this up, AMD, having tried this before will tell you that if you can't get broad software support that it's a dead duck, however, Apple have often made long term bets and stuck with them over a number of years, which could make the difference.
Apple have approached this in two different ways. They have created a monster APU, AMD's effort was... safe, I think they thought that they could iterate over time to large better designs, however, no-one wanted to put that much time and effort into a bet that AMD would deliver in the future when Intel wasn't making similar noises.
They're on a cutting edge node, with a cutting edge design, and there's no other choice for Apple users, sure you can get the original M1 or M1 Pro, but there's no Intel to get in the way and the only downside of the other chips are that they will be slower due to having fewer resources but it's all much the same design.
OreoCookie - Wednesday, October 27, 2021 - link
No, the 24 MB = 2 x 12 MB are the shared L2 caches amongst the performance core clusters, the two efficiency cores share another 4 MB (so the M1 Pro and M1 Max have close to Zen 3 desktop-level L2 caches if you ignore the system level cache). These caches are not shared between CPUs and GPUs at all. Only the system-level cache of yet *another* 48 MB is shared amongst all logic that has access to main memory. Given that the total memory bandwidth is larger than what CPU and GPU need in a worst-case scenario, I fail to see how this is somehow an edge case.It seems the memory bandwidth so large that it can accommodate all CPU cores running a memory-intensive workload at full tilt *and* the GPU running a memory-intensive workload with room to spare. Even if you could saturate the memory bandwidth by also using the NPU (ML accelerator) and/or the hardware en/decoder, I think you are really reaching. This would be far beyond the capabilities of any comparable machine. Even much more powerful machines would struggle with such a workload.
richardnpaul - Thursday, October 28, 2021 - link
Yes sorry, I do know that, the 24 in 24/48MB was a reference to the M1 Pro which has half the shared buffer. That shared buffer, I'd need to go back and look at the access times (and compare it to Zen3 desktop) because it's almost on the other side of the chip from the cores.I do see that they tested a game at 4K, and I know that some games lean more heavily on the onboard RAM on dGPUs and not all games have specific high resolution 4K textures and so use more RAM than others. And it is mentioned on the second page that they didn't see anything that pushed the GPU over using 90GB/s of bandwidth and I don't know if that they were measuring during that testing run (I would expect that they were but you know what they say about assumptions :D).
I think that you're right and that the architecture team probably went overboard on the bandwidth anticipating certain edge case scenarios where the system has multiple tasks loading multiple parts of the CPU and we'll see some rebalancing in future designs. I would like to see a game run with or without mods that does stress the GPU memory subsystem (games aren't usually hammering the CPU bandwidth so more should be available to the GPU, which may very well never be able to saturate it by design, but the cache may be saturated). This will also tell us something about longevity of the SoC too.
I don't think that I'm reaching, more that I see systems lasting for 7+ years, and when newer generations of hardware move on unusual usage when some hardware is new suddenly becomes common place because newer hardware is a evolving target over time and sometimes software does actually utilise it. (Sometimes CPU bugs rob you of performance and make your hardware feel slow, other times it's just that software is a bit more demanding now than it was years before when you got it)