Apple's M1 Pro, M1 Max SoCs Investigated: New Performance and Efficiency Heights
by Andrei Frumusanu on October 25, 2021 9:00 AM EST- Posted in
- Laptops
- Apple
- MacBook
- Apple M1 Pro
- Apple M1 Max
Section by Ryan Smith
GPU Performance: 2-4x For Productivity, Mixed Gaming
Arguably the star of the show for Apple’s latest Mac SoCs is the GPU, as well as the significant resources that go into feeding it. While Apple doesn’t break down how much of their massive, 57 billion transistor budget on the M1 Max went to the GPU, it and its associated hardware were the only thing to be quadrupled versus the original M1 SoC. Last year Apple proved that it could develop competitive, high-end CPU cores for a laptop; now they are taking their same shot on the GPU side of matters.
Driving this has been one of the biggest needs for Apple – and one of the greatest friction points between Apple and former partner Intel – which is GPU performance. With tight control over their ecosystem and little fear over pushing (or pulling) developers forward, Apple has been on the cutting edge of expanding the role of GPUs within a system for nearly the past two decades. GPU-accelerated composition (Quartz Extreme), OpenCL, GPU-accelerated machine learning, and more have all been developed or first implemented by Apple. Though often rooted in efficiency gains and getting incredibly taxing tasks off of the CPU, these have also pushed up Apple’s GPU performance requirements.
This has led to Apple using Intel’s advanced Iris iGPU configurations over most of the last 10 years (often being the only OEM to make significant use of them). But even Iris was never quite enough for what Apple would like to do. For their largest 15/16-inch MacBook Pros, Apple has been able to turn to discrete GPUs to make up the difference, but the lack of space and power for a dGPU in the 13-inch MacBook Pro form factor has been a bit more constraining. Ultimately, all of this has pushed Apple to develop their own GPU architecture, not only to offer a complete SoC for lower-tier parts, but also to be able to keep the GPU integrated in their high-end parts as well.

It’s the latter that is arguably the unique aspect of Apple’s position right now. Traditional OEMs have been fine with a small(ish) CPU and then adding a discrete GPU as necessary. It’s cost and performance effective: you only need to add as big of a dGPU as the customer needs performance, and even laptop-grade dGPUs can offer very high performance. But like any other engineering decision, it’s a trade-off: discrete GPUs result in multiple display adapters, require their own VRAM, and come with a power/cooling cost.
Apple has long been a vertically integrated company, so it’s only fitting that they’ve been focused on SoC integration as well. Bringing what would have been the dGPU into their high-end laptop SoCs eliminates the drawbacks of a discrete part. And, again leveraging Apple’s ecosystem advantage, it means they can provide the infrastructure for developers to use the GPU in a heterogeneous computing fashion – able to quickly pass data back and forth with the CPU since they’re all processing blocks on the same chip, sharing the same memory. Apple has already been pushing this paradigm for years in its A-series SoC, but this is still new territory in the laptop space – no PC processor has ever shipped with such a powerful GPU integrated into the main SoC.
The trade-off for Apple, in turn, is that the M1 inherits the costs of providing such a powerful GPU. That not only includes die space for the GPU blocks themselves, but the fatter fabric needed to pass that much data around, the extra cache needed to keep the GPU immediately fed, and the extra external memory bandwidth needed to keep the GPU fed over the long run. Integrating a high-end GPU means Apple has inherited the design and production costs of a high-end GPU.
ALUs and GPU cores aside, the most interesting thing Apple has done to make this possible comes via their memory subsystem. GPUs require a lot of memory bandwidth, which is why discrete GPUs typically come with a sizable amount of dedicated VRAM using high-speed interfaces like HBM2 or GDDR6. But being power-minded and building their own SoC, Apple has instead built an incredibly large LPDDR5 memory interface; M1 Max has a 512-bit interface, four-times the size of the original M1’s 128-bit interface. To be sure, it’s always been possible to scale up LPDDR in this fashion, but at least in the consumer SoC space, it’s never been done before. With such a wide interface, Apple is able to give the M1 Max 400GB/sec (technically, 409.6 GB/sec) of memory bandwidth, which is comparable to the amount of bandwidth found on NVIDIA’s fastest laptop SKUs.
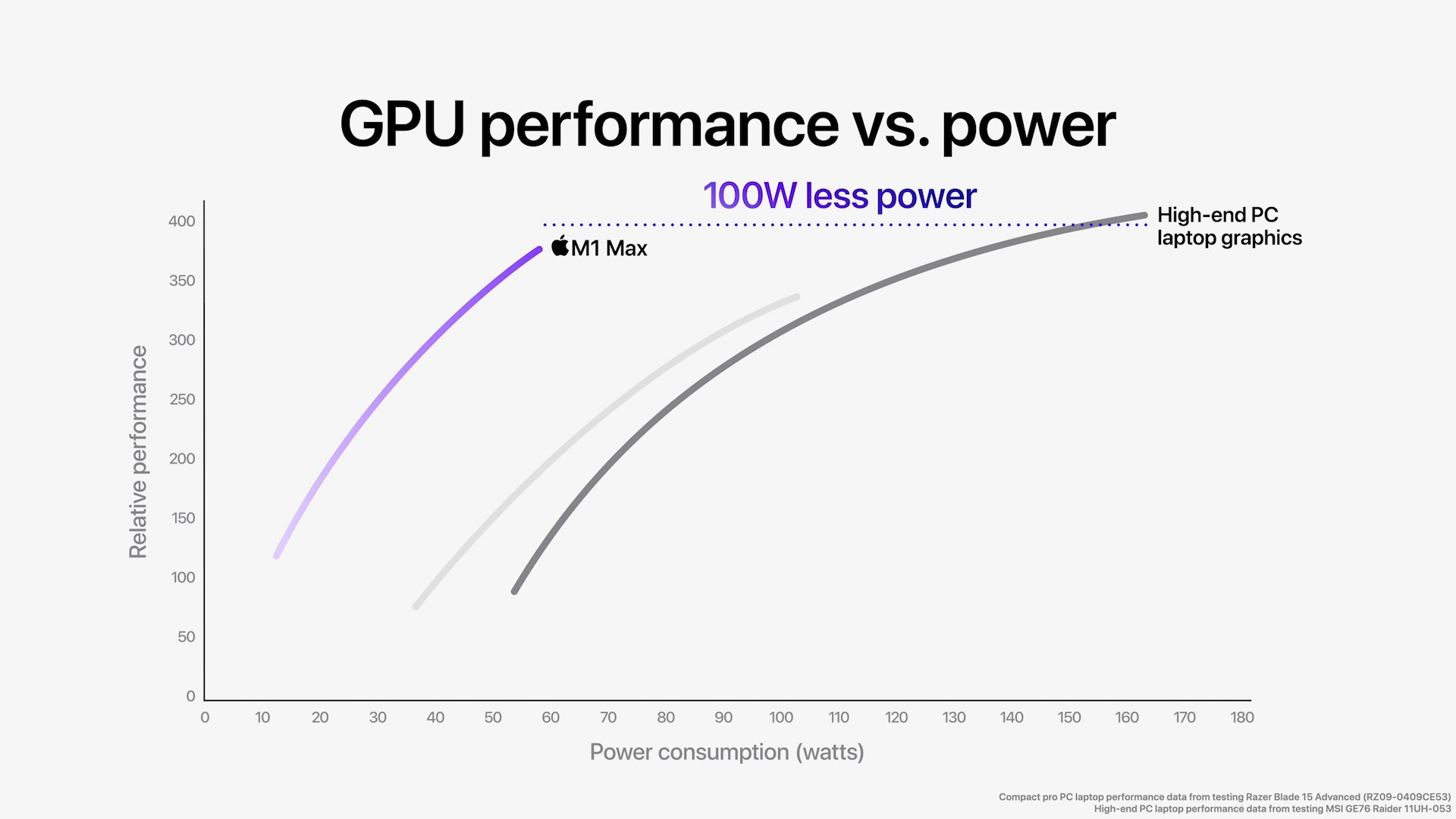
Ultimately, this enables Apple to feed their high-end GPU with a similar amount of bandwidth as a discrete laptop GPU, but with a fraction of the power cost. GDDR6 is very fast per pin – over 2x the rate – but efficient it ain’t. So while Apple does lose some of their benefit by requiring such a large memory bus, they more than make it up by using LPDDR5. This saves them over a dozen Watts under load, not only benefitting power consumption, but keeping down the total amount of heat generated by their laptops as well.
M1 Max and M1 Pro: Select-A-Size
There is one more knock-on effect for Apple in using integrated GPUs throughout their laptop SoC lineup: they needed some way to match the scalability afforded by dGPUs. As nice as it would be for every MacBook Pro to come with a 57 billion transistor M1 Max, the costs and chip yields of such a thing are impractical. The actual consumer need isn’t there either; M1 Max is designed to compete with high-end discrete GPU solutions, but most consumer (and even a lot of developer) workloads simply don’t fling around enough pixels to fully utilize M1 Max. And that’s not meant to be a subtle complement to Apple – M1 Max is overkill for desktop work and arguably even a lot of 1080p-class gaming.
So Apple has developed not one, but two new M1 SoCs, allowing Apple to have a second, mid-tier graphics option below M1 Max. Dubbed M1 Pro, this chip has half of M1 Max’s GPU clusters, half of its system level cache, and half of its memory bandwidth. In every other respect it’s the same. M1 Pro is a much smaller chip – Andrei estimates it’s around 245mm2 in size – which makes it cheaper to manufacture for Apple. So for lower-end 14 and 16-inch MacBook Pros that don’t need high-end graphics performance, Apple is able to offer a smaller slice of their big integrated GPU still paired with all of the other hardware that makes the latest M1 SoCs as a whole so powerful.
| Apple Silicon GPU Specifications | |||||
| M1 Max | M1 Pro | M1 | |||
| ALUs | 4096 (32 Cores) |
2048 (16 Cores) |
1024 (8 Cores) |
||
| Texture Units | 256 | 128 | 64 | ||
| ROPs | 128 | 64 | 32 | ||
| Peak Clock | 1296MHz | 1296MHz | 1278MHz | ||
| Throughput (FP32) | 10.6 TFLOPS | 5.3 TFLOPS | 2.6 TFLOPS | ||
| Memory Clock | LPDDR5-6400 | LPDDR5-6400 | LPDDR4X-4266 | ||
| Memory Bus Width | 512-bit (IMC) |
256-bit (IMC) |
128-bit (IMC) |
||
Taking a quick look at the GPU specifications across the M1 family, Apple has essentially doubled (and then doubled again) their integrated GPU design. Whereas the original M1 had 8 GPU cores, M1 Pro gets 16, and M1 Max gets 32. Every aspect of these GPUs has been scaled up accordingly – there are 2x/4x more texture units, 2x/4x more ROPs, 2x/4x the memory bus width, etc. All the while the GPU clockspeed remains virtually unchanged at about 1.3GHz. So the GPU performance expectation for M1 Pro and M1 Max are very straightforward: ideally, Apple should be able to get 2x or 4x the GPU performance of the original M1.
Otherwise, not reflected in the specifications or in Apple’s own commentary, Apple will need to have scaled up their fabric as well. Connecting 32 cores means passing around a massive amount of data, and the original M1’s fabric certainly wouldn’t have been up to the task. Still, whatever Apple had to do has been accomplished (and concealed) very neatly. From the outside the M1 Pro/Max GPUs behave just like M1, so even with those fabric changes, this is very clearly a virtually identical GPU architecture.
Synthetic Performance
Finally diving into GPU performance itself, let’s start with our synthetic benchmarks.
In an effort to try to get as much comparable data as possible, I’ve started with GFXBench 5.0 Aztec Ruins. This is one of our standard laptop benchmarks, so we can directly compare the M1 Max and M1 Pro to high-end PC laptops we’ve recently tested. As for Aztec Ruins itself, this is a benchmark that can scale from phones to high-end laptops; it’s natively available for multiple platforms and it has almost no CPU overhead, so the sky is the limit on the GPU font.

Aztec makes for a very good initial showing for Apple’s new SoCs. M1 Max falls just short of topping the chart here, coming in a few FPS behind MSI’s GE76, a GeForce RTX 3080 Laptop-equipped notebook. As we’ll see, this is likely to be something of a best-case scenario for Apple since Aztec scales so purely with GPU performance (and has a very good Metal implementation). But it goes to show where Apple can be when everything is just right.
We also see the scalability of the M1 family in action here. The M1->M1 Pro ->M1 Max performance progression is almost exactly 2x at each step,
Since macOS can also run iOS applications, I’ve also tossed in 3DMark Wild Life Extreme benchmark. This is another cross-platform benchmark that’s available on mobile and desktop alike, with the Extreme version particularly suited for measuring PCs and Macs alike. This is run in Unlimited mode, which draws off-screen in order to ensure the GPU is fully weighed down.
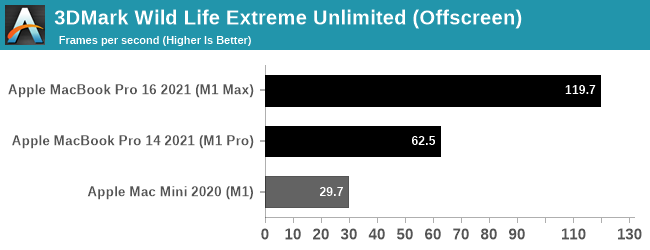
Since 3DMark Wild Life Extreme is not one of our standard benchmarks, we don’t have comparable PC data to draw from. But from the M1 Macs we can once again see that GPU performance is scaling almost perfectly among the SoCs. The M1 Pro doubles performance over the M1, and the M1 Max doubles it again.
Gaming Performance
Switching gears, even though macOS isn’t an especially popular gaming platform, there are plenty of games to be had on the platform, especially as tools like MoltenVK have made it easier for developers to get a Metal API render backend up and running. With that said over, the vast majority of major macOS cross-platform games are still x86 only, so a lot of games are still reliant on Rosetta. Ideally products like the new MacBook Pros will push developers to develop Arm binaries as well, but that will be a bigger ask.
We’ll start with Shadow of the Tomb Raider, which is another one of our standard laptop benchmarks. This gives us a lot of high-end laptop configurations to compare against.
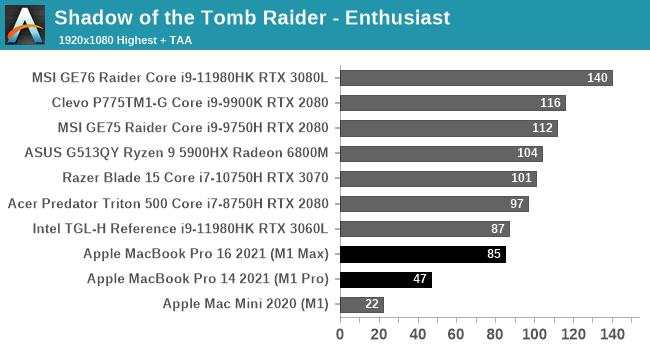
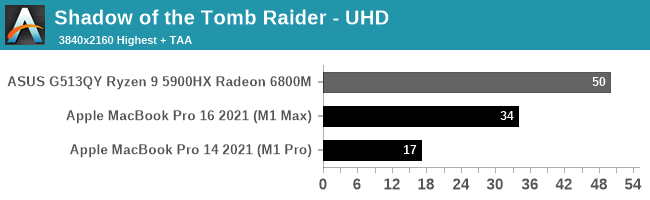
Unfortunately, Apple’s strong GPU performance under our synthetic benchmarks doesn’t extend to our first game. The M1 Macs bring up the tail-end of the 1080p performance chart, and they’re still well behind the Radeon 6800M at 4K.
Digging deeper, there are a couple of factors in play here. First and foremost, the M1 Max in particular is CPU limited at 1080p; the x86-to-Arm translation via Rosetta is not free, and even though Apple’s CPU cores are quite powerful, they’re hitting CPU limitations here. We have to go to 4K just to help the M1 Max fully stretch its legs. Even then the 16-inch MacBook Pro is well off the 6800M. Though we’re definitely GPU-bound at this point, as reported by both the game itself, and demonstrated by the 2x performance scaling from the M1 Pro to the M1 Max.
Our second game is Borderlands 3. This is another macOS port that is still x86-only, and part of our newer laptop benchmarking suite.
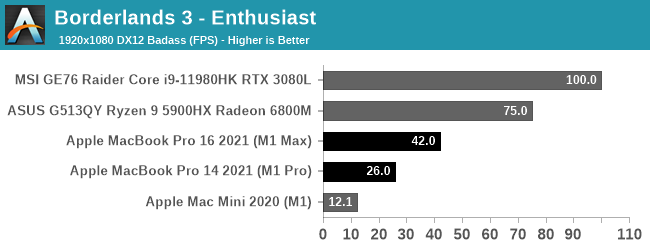

Borderlands 3 ends up being even worse for the M1 chips than Shadow of the Tomb Raider. The game seems to be GPU-bound at 4K, so it’s not a case of an obvious CPU bottleneck. And truthfully, I don’t enough about the porting work that went into the Mac version to say whether it’s even a good port to begin with. So I’m hesitant to lay this all on the GPU, especially when the M1 Max trails the RTX 3080 by over 50%. Still, if you’re expecting to get your Claptrap fix on an Apple laptop, a 2021 MacBook Pro may not be the best choice.
Productivity Performance
Last, but not least, let’s take a look at some GPU-centric productivity workloads. These are not part of our standard benchmark suite, so we don’t have comparable data on hand. But the two benchmarks we’re using are both standardized benchmarks, so the data is portable (to an extent).
We’ll start with Puget System’s PugetBench for Premiere Pro, which is these days the de facto Premiere Pro benchmark. This test involves multiple playback and video export tests, as well as tests that apply heavily GPU-accelerated and heavily CPU-accelerated effects. So it’s more of an all-around system test than a pure GPU test, though that’s fitting for Premiere Pro giving its enormous system requirements.
On a quick note here, this benchmark seems to be sensitive to both the resolution and refresh rate of the desktop – higher refresh rates in particular seem to boost performance. Which means that the 2021 MacBook Pros’ 120Hz ProMotion displays get an unexpected advantage here. So to try to make things more apples-to-apples here, all of our testing is with a 1920x1080 desktop at 60Hz. (For reference, a MBP16 scores 1170 when using its native display)
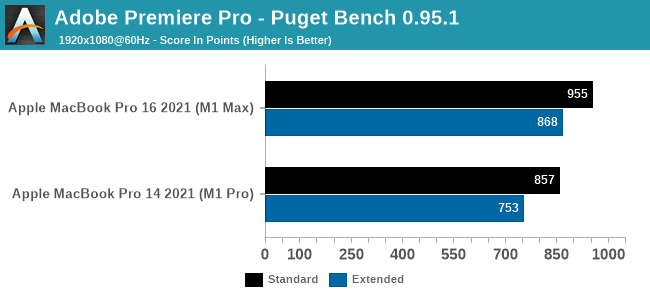
What we find is that both Macs perform well in this benchmark – a score near 1000 would match a high-end, RTX 3080-equipped desktop – and from what I’ve seen from third party data, this is well, well ahead of the 2019 Intel CPU + AMD GPU 16-inch MacBook Pro.
As for how much of a role the GPU alone plays, what we see is that the M1 Max adds about 100 points on both the standard and extended scores. The faster GPU helps with GPU-accelerated effects, and should help with some of the playback and encoding workload. But there are other parts that fall to the CPU, so the GPU alone doesn’t carry the benchmark.
Our other productivity benchmark is DaVinci Resolve, the multi-faceted video editor, color grading, and VFX video package. Resolve comes up frequently in Apple’s promotional materials; not only is it popular with professional Mac users, but color grading and other effects from the editor are both GPU-accelerated and very resource intensive. So it’s exactly the kind of professional workload that benefits from a high-end GPU.
As Resolve doesn’t have a standard test – and Puget Systems’ popular test is not available for the Mac – we’re using a community-developed benchmark. AndreeOnline’s Rocket Science benchmark uses a variety of high-resolution rocket clips, processing them with either a series of increasingly complex blur or temporal noise reduction filters. For our testing we’re using the test’s 4K ProRes video file as an input, though the specific video file has a minimal impact relative to the high cost of the filters.
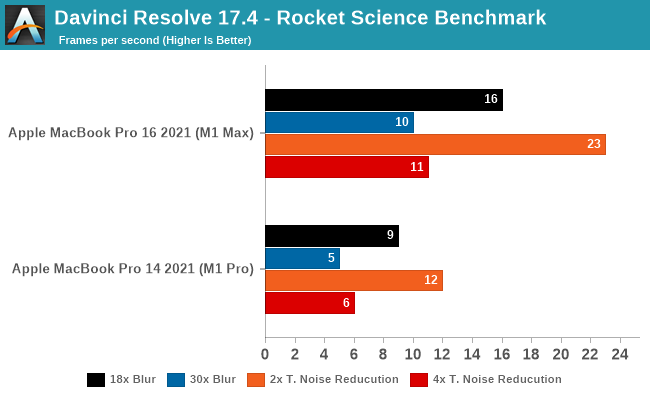
All of these results are well-below real time performance, but it’s to be expected from the complex nature of the filters. Still, the M1 Max comes closer than I was expecting to matching the clip’s original framerate of 25fps; an 18 step blur operation still moves at 16fps, and a 2-step noise resolution is 23fps. This is a fully GPU-bottlenecked scenario, so ramping those up to even larger filter sets has the expected impact to GPU performance.
Meanwhile, this is another case of the M1 Max’s GPU performance scaling very closely to 2x that of the M1 Pro’s. With the exception of 18-step blur, the M1 Max is 80% faster or better. All of which underscores that when a workload is going to be throwing around billions of pixels like Resolve, if it’s GPU-accelerated it can certainly benefit from the M1 Max’s more powerful GPU.
Overall, it’s clear that Apple’s ongoing experience with GPUs has paid off with the development of their A-series chips, and now their M1 family of SoCs. Apple has been able to scale up the small and efficient M1 into a far more powerful configuration; Apple built SoCs with 2x/4x the GPU hardware of the original M1, and that’s almost exactly what they’re getting out of the M1 Pro and M1 Max, respectively. Put succinctly, the new M1 SoCs prove that Apple can build the kind of big and powerful GPUs that they need for their high-end machines. AMD and NVIDIA need not apply.
With that said, the GPU performance of the new chips relative to the best in the world of Windows is all over the place. GFXBench looks really good, as do the MacBooks’ performance productivity workloads. For the true professionals out there – the people using cameras that cost as much as a MacBook Pro and software packages that are only slightly cheaper – the M1 Pro and M1 Max should prove very welcome. There is a massive amount of pixel pushing power available in these SoCs, so long as you have the workload required to put it to good use.
However gaming is a poorer experience, as the Macs aren’t catching up with the top chips in either of our games. Given the use of x86 binary translation and macOS’s status as a traditional second-class citizen for gaming, these aren’t apple-to-apple comparisons. But with the loss of Boot Camp, it’s something to keep in mind. If you’re the type of person who likes to play intensive games on your MacBook Pro, the new M1 regime may not be for you – at least not at this time.








493 Comments
View All Comments
richardnpaul - Wednesday, October 27, 2021 - link
I'm not saying that it's not great and energy efficient marvel of technology (although you're forgetting that the compared part is Zen3 mobile 35W part which has 12MB rather than 32MB of L3 and that's partly because its a small die on 7nm).They mentioned Metal they mentioned how they can't get direct comparative results, this is one of the downsides of this, and the others from Apple, chip, great as it is it has drawbacks that hamper it which are nothing to to do with the architecture.
OreoCookie - Wednesday, October 27, 2021 - link
I don’t think I’m forgetting anything here. I am just saying that Anandtech should compare the M1 Max against actual products rather than speculate how it compares to future products like Alderlake or Zen 3 with V cache. Your claim was that the article “comes across as a fanboi article”, and I am just saying that they are just giving the chip a great review because in their low-level benchmarks it outclasses the competition in virtually every way. That’s not fanboi-ism, it is just rooted in fact.And yes, they explained the issue with APIs and the lack of optimization of games for the Mac. Given that Mac users either aren’t gamers or (if they are gamers) tend to not use their Macs for gaming, we can argue how important that drawback actually is. In more GPU compute-focussed benchmarks (e. g. by Affinity that make cross-platform creativity apps), the results of the GPU seem very impressive.
richardnpaul - Thursday, October 28, 2021 - link
My main disagreement was not them comparing with with Zen3, but more that I felt that they failed to adequately cover how the change would impact this use case scenario between M1 versions given that comparing Zen2 to Zen3 has been covered (and AMD have already said that the Vcache will mainly impact gaming and server workloads by around 15% on average) and shown in these specific use cases to have quite a large benefit and I'd just wanted that kind of abstract logical analysis of how the Max might be more positively positioned for this or these use cases above say the original M1. (I know that they mentioned in the article that they didn't have the M1 anymore and the actual AMD 5900HS device is dead which has severely impacted their testing here.I come to Anandtech specifically for the more indepth coverage that you don't get elsewhere and I come for all the hardware articles irrespective of brand because I'm interested in technology not brand names which is why I dislike articles that come across as biased (whilst it'll never be intentionally biased we're all human at the end of the day and it's hard not to let the excitement of novel tech cloud our judgement).
richardnpaul - Wednesday, October 27, 2021 - link
Also my comparison was AMD to AMD between generations and how it might apply to increasing the cache sizes of the M1 and the positive improvement it might have on performance in situations using the GPU such as gaming.Ppietra - Wednesday, October 27, 2021 - link
You are so focused on a fringe case that you don’t stop to think that "maybe" there are other things happening besides "gluing" a CPU and GPU on the same silicon, fighting for memory bandwidth. Unified memory architecture plus CPU and GPU sharing data over the system cache, has an impact on memory bandwidth needs.Besides this, looking at data that it is provided, we seem to be far from saturating memory bandwidth on a regular basis.
It would be interesting though to actually see how applications behave when truly optimised for this hardware and not just ported with some compatibility abstraction layer in the middle. Affinity Photo would probably be the best example.
richardnpaul - Wednesday, October 27, 2021 - link
This is exactly what I wanted coving in the article. If the GPU and CPU are hitting the memory subsystem they are going to be competing for cache hits. My point was that Zen3 (desktop) showed a large positive correlation between doubling the cache (or unifying it into a single blob in reality) and increased FPS in games and that that might also hold true for the increased cache on the M1 Pro and Max.Unfortunately testing this chip is hampered by decisions completely unrelated to the hardware itself, and that also applies to certain use cases.
it'll be more interesting to see testing the same games under Linux between an Nvidia/AMD/Intel based laptop as then the only differences should be the ISA; and immature drivers.
Ppietra - Wednesday, October 27, 2021 - link
"hitting the memory subsystem they are going to be competing for cache hits"CPU and GPU also have their own cache (CPU 24MB L2 total; GPU don’t know how much now) which is very substantial.
And I think you are not seeing the picture about CPU and GPU not having to duplicate resources, working on the same data in an enormous 48MB system cache (when using native APIs of course) before even needing to access RAM, reducing latency, etc. This can be very powerful. So no, I don’t assume that there will any significant impact because of some fringe case while ignoring the great benefits that it brings.
richardnpaul - Wednesday, October 27, 2021 - link
One person's fringe edge case is another person's primary use case.The 24/48MB is a shared cache between the CPU and GPU (and everything else that accesses main memory).
Ppietra - Wednesday, October 27, 2021 - link
no, it’s a fringe case period! You don’t see laptop processors with these amounts of L2 cache and system cache anywhere, not even close, and yet for some reason you feel that it would be at an disadvantage, failing to acknowledge the advantages of sharingrichardnpaul - Thursday, October 28, 2021 - link
What you call a fringe case I call 2.35m people. Okay, so it's probably on about 1.5 to 2% of Mac users; it's ~2.5% of Steam users.I know people who play games on Windows Machines because their GPUs in their Macs aren't good enough. Those people who are frustrated having to maintain a Windows machine just to play games. Those people will buy into an M1 Pro or Max just so they can be rid of the Windows system. It won't be their main concern, but then they're not going to be buying an M1 Pro/Max for the reason of rendering etc when they're a web developer, they're going to buy it so that they can dump the pain in the backside Windows gaming machine. Valve don't maintain their MacOS version of Steam for no good reason.