The Ampere Altra Max Review: Pushing it to 128 Cores per Socket
by Andrei Frumusanu on October 7, 2021 8:00 AM EST- Posted in
- Servers
- Arm
- Neoverse N1
- Ampere
- Altra Max
Compiling Performance / LLVM
As we’re trying to rebuild our server test suite piece by piece – and there’s still a lot of work go ahead to get a good representative “real world” set of workloads, one more highly desired benchmark amongst readers was a more realistic compilation suite. Chrome and LLVM codebases being the most requested, I landed on LLVM as it’s fairly easy to set up and straightforward.
git clone https://github.com/llvm/llvm-project.gitcd llvm-projectgit checkout release/11.xmkdir ./buildcd ..mkdir llvm-project-tmpfssudo mount -t tmpfs -o size=10G,mode=1777 tmpfs ./llvm-project-tmpfscp -r llvm-project/* llvm-project-tmpfscd ./llvm-project-tmpfs/buildcmake -G Ninja \ -DLLVM_ENABLE_PROJECTS="clang;libcxx;libcxxabi;lldb;compiler-rt;lld" \ -DCMAKE_BUILD_TYPE=Release ../llvmtime cmake --build .We’re using the LLVM 11.0.0 release as the build target version, and we’re compiling Clang, libc++abi, LLDB, Compiler-RT and LLD using GCC 10.2 (self-compiled). To avoid any concerns about I/O we’re building things on a ramdisk – on a 4KB page system 5GB should be sufficient but on the Altra’s 64KB system it used up to 9.5GB, including the source directory. We’re measuring the actual build time and don’t include the configuration phase as usually in the real world that doesn’t happen repeatedly.
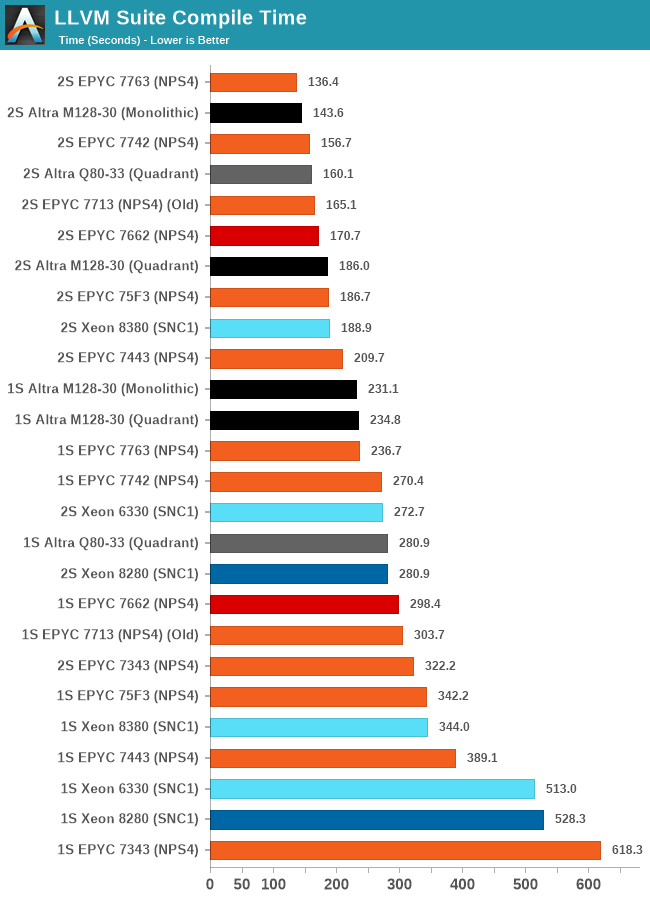
The LLVM compile test results here are quite more special and demand more attention that what meets the eye at first.
Inherently, the biggest work slice of the test is massively parallel, able to take advantage of all cores in a system, 256 cores in the 2-socket results of the M128-30, however as it’s also a real-world test, the compilation also incurs linking phases where the chip is inherently just under a single-core load and all other cores are just sitting idle.
This behaviour results in some more complex behaviour in the different test scenarios of the M128-30, as the ratio between the parallel/MT and ST phases of the test changes.
In the single-socket results, the chip showcases a +14% performance boost over the Q80-33, while in the 2S results under quadrant mode, this actually transforms into a 16% performance regression. What’s happening here is that while the increased core count of the chip massively helps in improving the actual compilation of objects, the linking phase of the test is significantly slower and takes up a larger percentage of total test time than on the Q80-33, due to the lower CPU frequencies and smaller SLC of the new chip.
Running the M128-30 in monolithic mode actually results in a 24% reduction in compile time, mostly through a large speedup of the linking phase of the compilation as we’re giving that one active core access to the whole 16MB SLC rather than just a 4MB slice.
AMD’s EPYC 7763, even though it has only half the core count, still manages to outperform the M128-30 in the total test time because the linking phase is much sped up thanks to the much superior single-threaded performance of the cores when few threads are active on the SoC. The 34% advantage of the ST SPEC scores here comes more into play than the MT throughput of the chip.
These results are very interesting, and showcase that even in a more real-world scenario like this, the flock-of-chickens approach doesn’t work out as well even in what would consider a massively parallel workload, as some things just cannot be spread out over multiple cores well. It reminds me very much of the eMAG chip, which also suffered in real world code compilations due to the very same reasons.








60 Comments
View All Comments
Jurgen B - Thursday, October 7, 2021 - link
Love your thorough article and testing. This is some serious firing power from the Ampere and makes some great competition for Intel and AMD. I really like the 256T runs on the AMD Dual socket EPYCs (they really are serving me well in floating point research computing), but it seems that future holds some nice innovations in the field!mode_13h - Thursday, October 7, 2021 - link
Lack of cache seems to be a serious liability, though. For many, it'll be a deal breaker.Wilco1 - Friday, October 8, 2021 - link
Yet it still beats AMD's 7763 with its humongous 256MB L3 in all the multithreaded benchmarks. Sure, it would be even faster if it had a 64MB L3 cache, however it doesn't appear to be a serious liability. Doing more with far less silicon at a lower price (and power) is an interesting design point (and apparently one that cloud companies asked for).Jurgen B - Friday, October 8, 2021 - link
Yes, Cache will play a role for many. However, people buying such servers likely have a very specific workload in mind. And thus they now have more choices which of the manufacturer options they prefer, and these choices are really good to see. Compared to 10 years ago, when AMD was much less competitive, it is wonderful to see the innovation.schujj07 - Friday, October 8, 2021 - link
That isn't true at all. The SPEC java benchmarks have the Epyc ahead, SpecINT Base Rate-N Estimated they are almost equal (despite having half the cores), FP Base Rate-N Estimated the Epyc is ahead, compiling the Epyc is ahead. Anything that will tax the memory subsystem by not fitting into the small cache of the Altra and the performance is lower for the Altera. Per core performance isn't even close.mode_13h - Saturday, October 9, 2021 - link
Thanks for correcting the record, @schujj07.The whole concept of adding 60% more cores while halving cache is mighty suspicious. In the most charitable view, this is intended to micro-target specific applications with low memory bandwidth requirements. From a more cynical perspective, it's merely an exercise in specsmanship and maybe trying to gin up a few specific benchmark numbers.
Wilco1 - Saturday, October 9, 2021 - link
If you're that cynical one could equally claim that adding *more* cache is mighty suspicious and gaming benchmark numbers. Obviously nobody would spend a few hundred million on a chip just to game benchmarks. The fact is there is a market for chips with lots of cores. Half the SPEC subtests show huge gains from 60% extra cores despite the lower frequency and halved L3. So clearly there are lots of applications that benefit from more cores and don't need a huge L3.Wilco1 - Saturday, October 9, 2021 - link
The Altra Max wins the more useful critical-jOPS benchmark by over 30%. It also wins the LLVM compile test and SPECINT_rate by a few percent. The 7763 only wins SPECFP by 18% (not Altra's market) and max-jOPS by 13%.So yes my point is spot on, the small cache does not look at all like a serious liability. Per-core performance isn't interesting when comparing a huge SMT core with a tiny non-SMT core - you can simply double the number of cores to make up for SMT and still use half the area...
mode_13h - Saturday, October 9, 2021 - link
> Per-core performance isn't interesting when comparing ...Trying to change the subject? We didn't mention that. We were talking only about cache.
> The Altra Max wins the more useful critical-jOPS benchmark by over 30%.
That's really about QoS, which is a different story. Surely, relevant for some. I wonder if x86 CPUs would do better on that front with SMT disabled.
> the small cache does not look at all like a serious liability.
Of course it's a liability! It's just a very workload-dependent one. You need only note the cases where Max significantly underperforms, relative to its 80-core sibling, to see where the cache reduction is likely an issue.
The reason why there are so many different benchmarks is that you can't just seize on the aggregate numbers to tell the whole story.
mode_13h - Saturday, October 9, 2021 - link
Apologies, I now see where schujj07 mentioned per-core performance. I even searched for "per-core" but not "per core".