Intel 12th Gen Core Alder Lake for Desktops: Top SKUs Only, Coming November 4th
by Dr. Ian Cutress on October 27, 2021 12:00 PM EST- Posted in
- CPUs
- Intel
- DDR4
- DDR5
- PCIe 5.0
- Alder Lake
- Intel 7
- 12th Gen Core
- Z690
Thread Director: Windows 11 Does It Best
Every operating system runs what is called a scheduler – a low-level program that dictates where workloads should be on the processor depending on factors like performance, thermals, and priority. A naïve scheduler that only has to deal with a single core or a homogenous design has it pretty easy, managing only power and thermals. Since those single core days though, schedulers have grown more complex.
One of the first issues that schedulers faced in monolithic silicon designs was multi-threading, whereby a core could run more than one thread simultaneously. We usually consider that running two threads on a core usually improves performance, but it is not a linear relationship. One thread on a core might be running at 100%, but two threads on a single core, while overall throughput might increase to 140%, it might mean that each thread is only running at 70%. As a result, schedulers had to distinguish between threads and hyperthreads, prioritizing new software to execute on a new core before filling up the hyperthreads. If there is software that doesn’t need all the performance and is happy to be background-related, then if the scheduler knows enough about the workload, it might put it on a hyperthread. This is, at a simple level, what Windows 10 does today.
This way of doing things maximizes performance, but could have a negative effect on efficiency, as ‘waking up’ a core to run a workload on it may incur extra static power costs. Going beyond that, this simple view assumes each core and thread has the same performance and efficiency profile. When we move to a hybrid system, that is no longer the case.
Alder Lake has two sets of cores (P-cores and E-cores), but it actually has three levels of performance and efficiency: P-cores, E-Cores, and hyperthreads on P-cores. In order to ensure that the cores are used to their maximum, Intel had to work with Microsoft to implement a new hybrid-aware scheduler, and this one interacts with an on-board microcontroller on the CPU for more information about what is actually going on.
The microcontroller on the CPU is what we call Intel Thread Director. It has a full scope view of the whole processor – what is running where, what instructions are running, and what appears to be the most important. It monitors the instructions at the nanosecond level, and communicates with the OS on the microsecond level. It takes into account thermals, power settings, and identifies which threads can be promoted to higher performance modes, or those that can be bumped if something higher priority comes along. It can also adjust recommendations based on frequency, power, thermals, and additional sensory data not immediately available to the scheduler at that resolution. All of that gets fed to the operating system.

The scheduler is Microsoft’s part of the arrangement, and as it lives in software, it’s the one that ultimately makes the decisions. The scheduler takes all of the information from Thread Director, constantly, as a guide. So if a user comes in with a more important workload, Thread Director tells the scheduler which cores are free, or which threads to demote. The scheduler can override the Thread Director, especially if the user has a specific request, such as making background tasks a higher priority.
What makes Windows 11 better than Windows 10 in this regard is that Windows 10 focuses more on the power of certain cores, whereas Windows 11 expands that to efficiency as well. While Windows 10 considers the E-cores as lower performance than P-cores, it doesn’t know how well each core does at a given frequency with a workload, whereas Windows 11 does. Combine that with an instruction prioritization model, and Intel states that under Windows 11, users should expect a lot better consistency in performance when it comes to hybrid CPU designs.
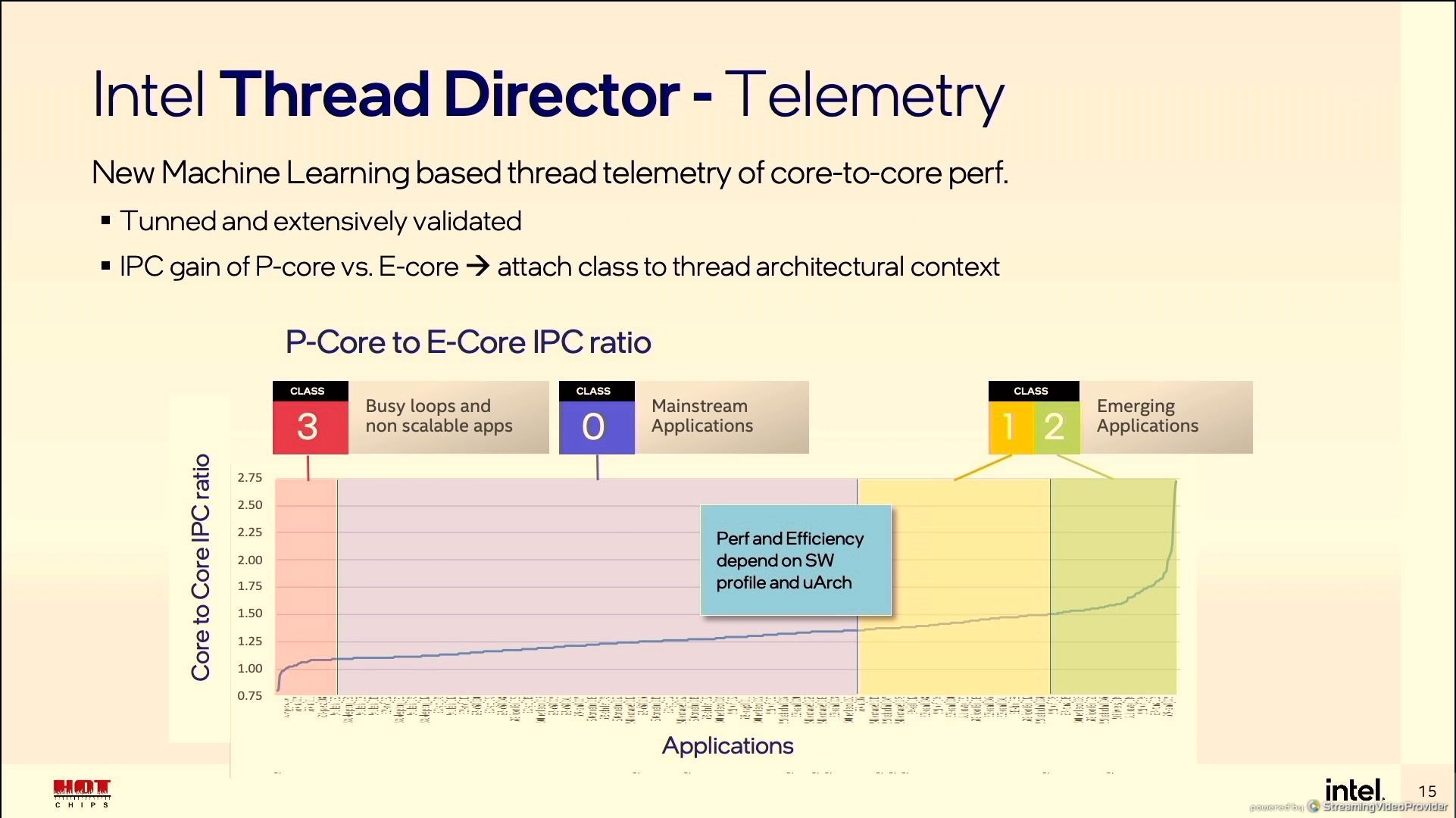
Under the hood, Thread Director is running a pre-trained algorithm based on millions of hours of data gathered during the development of the feature. It identifies the effective IPC of a given workflow, and applies that to the performance/efficiency metrics of each core variation. If there’s an obvious potential for better IPC or better efficiency, then it suggests the thread is moved. Workloads are broadly split into four classes:
- Class 3: Bottleneck is not in the compute, e.g. IO or busy loops that don’t scale
- Class 0: Most Applications
- Class 1: Workloads using AVX/AVX2 instructions
- Class 2: Workloads using AVX-VNNI instructions
Anything in Class 3 is recommended for E-cores. Anything in Class 1 or 2 is recommended for P cores, with Class 2 having higher priority. Everything else fits in Class 0, with frequency adjustments to optimize for IPC and efficiency if placed on the P-cores. The OS may force any class of workload onto any core, depending on the user.
There was some confusion in the press briefing as to whether Thread Director can ‘learn’ during operation, and how long it would take – to be clear, Thread Director doesn’t learn, it already knows from the pre-trained algorithm. It analyzes the instruction flow coming into a core, identifies the class as listed above, calculates where it is best placed (which takes microseconds), and communicates that to the OS. I think the confusion came with the difference in the words ‘learning’ and ‘analyzing’. In this case, it’s ‘learning’ what the instruction mix to apply to the algorithm, but the algorithm itself isn’t updated in the way that it is ‘learning’ and adjusting the classes. Ultimately even if you wanted to make the algorithm self-learn your workflow, the algorithm can’t actually see which thread relates to which program or utility – that’s something on the operating system level, and down to Microsoft. Ultimately, Thread Director could suggest a series of things, and the operating system can choose to ignore them all. That’s unlikely to happen in normal operation though.
One of the situations where this might rear its head is to do with in-focus operation. As showcased by Intel, the default behavior of Windows changes depending on whether on the power plan.
When a user is on the balanced power plan, Microsoft will move any software or window that is in focus (i.e. selected) onto the P-cores. Conversely, if you click away from one window to another, the thread for that first window will move to an E-core, and the new window now gets P-core priority. This makes perfect sense for the user that has a million windows and tabs open, and doesn’t want them taking immediate performance away.
However, this way of doing things might be a bit of a concern, or at least it is for me. The demonstration that Intel performed was where a user was exporting video content in one application, and then moved to another to do image processing. When the user moved to the image processing application, the video editing threads were moved to the E-cores, allowing the image editor to use the P-cores as needed.
Now usually when I’m dealing with video exports, it’s the video throughput that is my limiting factor. I need the video to complete, regardless of what I’m doing in the interim. By defocusing the video export window, it now moves to the slower E-cores. If I want to keep it on the P-cores in this mode, I have to keep the window in focus and not do anything else. The way that this is described also means that if you use any software that’s fronted by a GUI, but spawns a background process to do the actual work, unless the background process gets focus (which it can never do in normal operation), then it will stay on the E-cores.
In my mind, this is a bad oversight. I was told that this is explicitly Microsoft’s choice on how to do things.
The solution, in my mind, is for some sort of software to exist where a user can highlight programs to the OS that they want to keep on the high-performance track. Intel technically made something similar when it first introduced Turbo Max 3.0, however it was unclear if this was something that had to come from Intel or from Microsoft to work properly. I assume the latter, given the OS has ultimate control here.
I was however told that if the user changes the Windows Power Plan to high-performance, this behavior stops. In my mind this isn’t a proper fix, but it means that we might see some users/reviews of the hardware with lower performance if the workload doing the work is background, and the reviewer is using the default Balanced Power Plan as installed. If the same policy is going to apply to Laptops, that’s a bigger issue.








395 Comments
View All Comments
Qasar - Friday, October 29, 2021 - link
yea, according to leaks maybe. remember how the 1100 series went ?untill reviews are out, its all speculation
Josh128 - Wednesday, October 27, 2021 - link
Intel's only chance to beat Zen 4 is if they get their "Intel 4" 7nm process going. If they have to stay on "Intel 7" 10nm, thats not going to cut it against TSMC 5 /5 +.regsEx - Wednesday, October 27, 2021 - link
Why calling Intel 4 as 7 nm process and Intel 7 as 10 nm process, but not mentioning TSMC N5 as 9 nm process?Spunjji - Thursday, October 28, 2021 - link
Two reasons:N5 was never renamed
"Intel 7" is still not equivalent to TSMC N7 on either density or power characteristics. Who knows how "Intel 4" will compare to N5 - if it's a similar relationship to Intel 7 and TSMC N7, then it should be called Intel 6.
shady28 - Thursday, October 28, 2021 - link
Intel 7 aka 10ESF is about the same density as TSMC N7FF+. It is reportedly 100.76 MT/mm2 vs TSMC N7FF of 96.5 MT/mm2. That's easy to validate doing your own research. This doesn't mean that Intel is not behind TSMC 5nm, but it is no longer behind their 7nm.https://semiwiki.com/semiconductor-manufacturers/s...
https://fuse.wikichip.org/news/1371/a-look-at-inte...
Spunjji - Friday, October 29, 2021 - link
@shady28 - those are the official figures, sure. It's a little more difficult to validate those, but luckily I have done my own research!In reality neither Intel nor TSMC can hit their claimed densities in actual chips, for a variety of reasons. The best information we have suggests that AMD have managed 62.8MTr/mm² on TSMC N7 with Renoir (Cezanne is an oddball because it has blank die space). Meanwhile Intel's competing chip - Ice Lake - clocked in at 53.2MTr/mm² on 10nm+. It's not a vast difference, but it's a difference all the same.
What we don't know is how the 10 SF and 10 ESF (now Intel 7) process changes have affected density. There's circumstantial evidence to suggest that 10 SF involved a relaxation of density, but we don't really know because Intel have been extremely tight-lipped about it.
Zoolook - Saturday, October 30, 2021 - link
In efficiency they sure are i.e performance/watt on the CPU's produced they are way behind.melgross - Friday, October 29, 2021 - link
It’s really more like a 7nm Intel process.Samus - Friday, October 29, 2021 - link
What's important of note here is AMD has had a fantastic run, effectively beating Intel in most categories for the last few years. Now Intel may be caught up and they are neck and neck.But this wouldn't have happened unless Intel had a fire under their ass.
melgross - Friday, October 29, 2021 - link
The way AMD had a fire under their ass