Intel Xeon Sapphire Rapids: How To Go Monolithic with Tiles
by Dr. Ian Cutress on August 31, 2021 10:00 AM ESTAdd In Some HBM, Optane
The other angle to Sapphire Rapids is the versions with HBM on board. Intel announced this back in June, but there haven’t been many details. As part of Architecture Day, Intel stated that that HBM versions of Sapphire Rapids would be made public, and be made socket compatible with standard Sapphire Rapids. The first customer of the HBM versions of SPR is the Argonne National Lab, as part of its Aurora Exascale supercomputer.
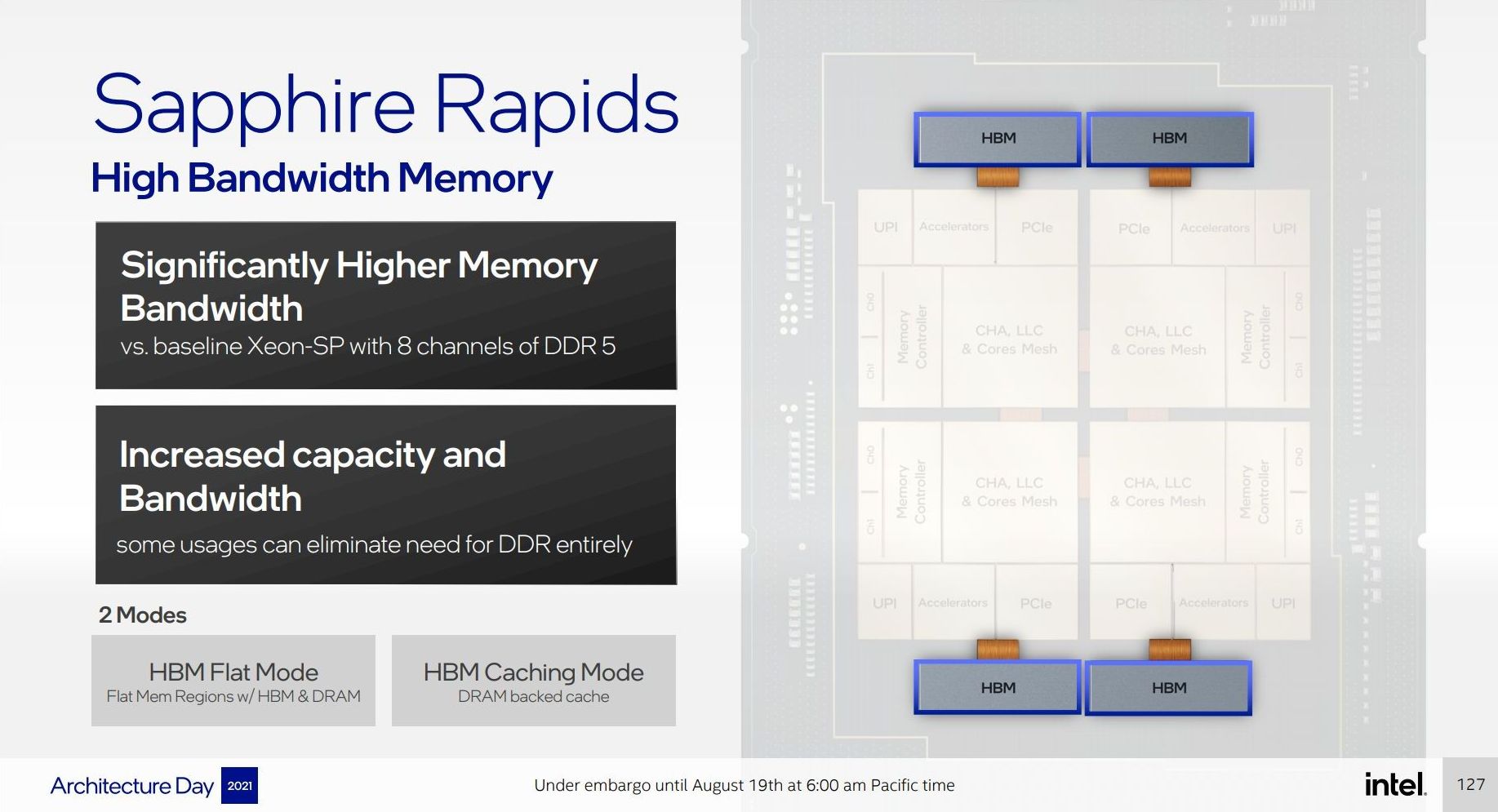
This diagram it showcases four HBM connections, one to each compute tile. Looking at the package, however, I don’t think that there’s realistically enough space unless Intel has commissioned some novel HBM that is long and narrow as it is in the diagram.

Even though Intel said that the HBM variants would be in the same socket, even their own slide from Hot Chips says different.
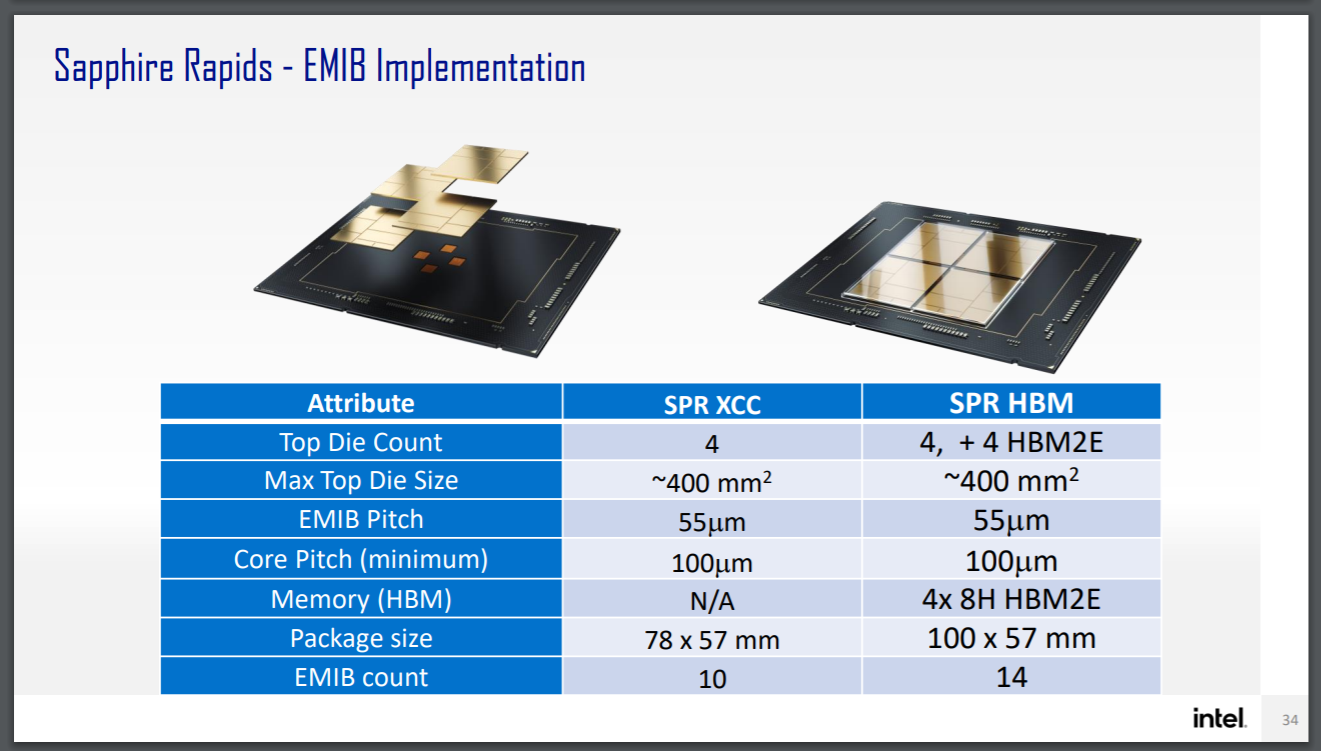
Here the package size with HBM says 100x57mm, compared to the SPR which is 78x57mm. So unless Intel is planning a reduced version for the 78x57mm socket, it's going to be in a different socket.
It is important to note that HBM will act in a similar capacity to Optane – either as an HBM flat mode with DRAM that equates the two, or as an HBM caching mode that acts similar to an L4 cache before hitting main memory. Optane on top of this can also be in a flat mode, a caching mode, or as a separate storage volume.
HBM will add power consumption to the package, which means we’re unlikely to see the best CPU frequencies paired with HBM if it is up against the socket limit. Intel has not announced how many HBM stacks or what capacities will be used in SPR, however it has said that they will be underneath the heatspreader. If Intel are going for a non-standard HBM size, then it’s anyone’s guess what the capacity is. But we do know that it will be connected to the tiles via EMIB.
A side note on Optane DC Persistent Memory – Sapphire Rapids will support a new 300 series Optane design. We asked Intel if this was the 200-series but using a DDR5 controller, and were told that no, this is actually a new design. More details to follow.
UPI Links
Each Sapphire Rapids Processor will have up to four x24 UPI 2.0 links to connect to other processors in a multi-socket design. With SPR, Intel is aiming for up to eight socket platforms, and in order to increase bandwidth has upgraded from three links in ICL to four (CLX had 2x3, technically), and moved to a UPI 2.0 design. Intel would not expand more on what this means, however they will have a new eight-socket UPI topology.
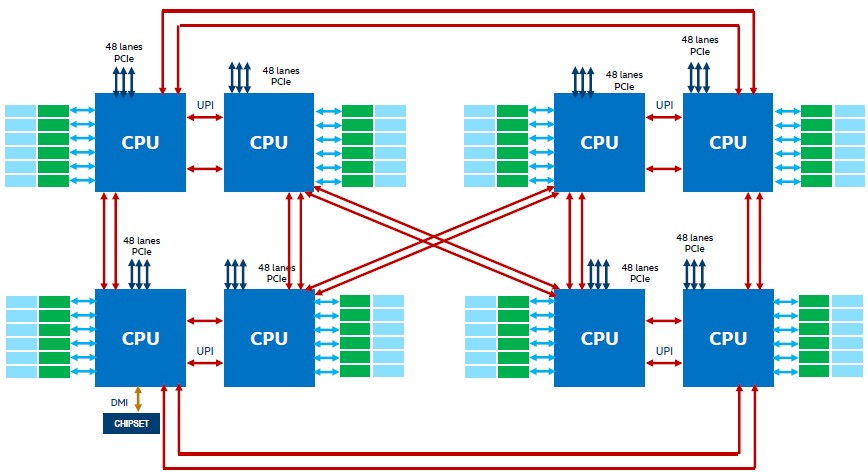
Current Intel Hypercube
Current eight-socket designs use a twisted hypercube topology: two groups of four form a box, and one pair is connected to the same vertex on the other set of four, while the second pair is inverted. Make sense? No, not really. Essentially each CPU is directly connected to three others, and the other four are two hops away. With the new topology, each CPU gets a direct connection to another, which moves the design more towards a fully connected topology, however exactly which CPU that connection should go to, Intel hasn’t stated yet.
Security
Intel has stated that it will be announcing full Security updates for SPR at a later time, however features like MKTME and SGX are key priorities.
Conclusions
For me, the improved cores, upgraded PCIe/DDR, and the ‘appears as a monolith’ approach are the highlights to date. However, there are some very obvious questions still to be answered – core counts, power consumption, how lower core counts would work (even suggestions that the LCC version is actually monolithic), and what the HBM enabled versions will look like. The HBM versions, with the added EMIB, are going to cost a good amount, which isn’t great at a time when AMD’s pricing structure is very competitive.
It is expected that when Sapphire Rapids is released, AMD will still be in the market with Milan (or as some are postulating, 3D V-Cache versions of Milan, but nothing is confirmed) and it won’t be until the end of 2022 when AMD launches Zen 4. If Intel can execute and bring SPR into the market, it will have a small time advantage in which to woo potential customers. Ice Lake is being sold on its specific accelerator advantages, rather than raw core performance, and we will have to wait and see if Sapphire Rapids can bring more to the table.
Intel moving to a tile/chiplet strategy in the enterprise has been expected for a number of years – at least on this side of the fence, ever since AMD made it work and scale beyond standard silicon limits, regardless of whatever horse-based binding agent is used between the silicon, Intel would have to go down this route. It has been delayed, mostly due to manufacturing but also optimizing things like EMIB which also takes time. EMIB as a technology is really impressive, but the more chips and bridges you put together, even if you have a 99% success rate, that cuts into yield. But that's what Intel has been working on, and for the enterprise market, Sapphire Rapids is the first step.








94 Comments
View All Comments
SystemsBuilder - Tuesday, August 31, 2021 - link
page 1, Golden Cove: A High-Performance Core with AMX and AIA, text under the AMX picture:"AMX uses eight 1024-bit registers for basic data operators" should be 1024 BYTE (or 1KByte) not 1024-bit.
AMX has 8 (row/column) configurable 1KB so called T registers, i.e. the 8 T registers can be configured to use a maximum size of 1KByte each but can also be smaller configured by row and columns parameters (you set tile configuration for each tile with the STTILECFG assembly instruction: i.e. row, columns, BF16/INT8 data type etc).
For more details see AMX section in this document:
https://software.intel.com/content/www/us/en/devel...
SystemsBuilder - Tuesday, August 31, 2021 - link
Cant edit so have to use a comment to clarify: LDTILECFG is used for setting the tile file configuration of all 8 tiles (# of rows and # columns per T register, while Data type is not set by this instruction) while STTILECFG is used for reading out the current tile file configuration and store the read out store that in memory.Ian Cutress - Tuesday, August 31, 2021 - link
My slide from Intel architecture day says 1 Kb = 1 kilo-bit. It literally says that in the slide above the paragraph you're referencing.So either a typo in the slide, or a typo in the AMX doc.
SystemsBuilder - Tuesday, August 31, 2021 - link
It's a type from Intel on the slides that you unfortunately propagated.Should be 1KByte not 1Kb (as in 1 Kbit).
yeah this presentation was not one of intel's finest moment...
just read the full spec ere: https://software.intel.com/content/www/us/en/devel...
There is significantly more detail in the full documentation. all sorts of limitation on number of rows (max 16) for instance which complicates INT8 matrices just as an example... What I would have liked would be to be able to is to fully configure # of rows and # of columns within the 1KByte for a given data type - to fully use each T register 1KByte size. We now need to have rectangular NxM matrix tiles instead of the preferable square NxN matrix tiles (and fit them into 16xM = 1024 bytes, solve for M)- symmetric N x N tiles makes algorithms easier...
SystemsBuilder - Tuesday, August 31, 2021 - link
Ian, to be clear the intel AMX specs in the intel doc:https://software.intel.com/content/www/us/en/devel... spends entire chapter 3 (25 pages) discussing AMX in detail. Stating multiple times that each T register is 1KByte and the whole register files size is 8KByte, also detailing each assembly Instruction etc.Additionally, first rev of this document was published last summer and the latest rev was published in June this year. During this whole time the T register 1KByte size have never changed (but more details have been included with each revision the past 12 months).
Further, glibc and various compliers have already included AMX extensions based on this spec. it would be quite catastrophic for them if intel suddenly cut the T reg size to 1024 bits.
Also, T reg size is not really new news. https://fuse.wikichip.org/news/3600/the-x86-advanc... published a pretty good article already last summer about this (also stating T regs are 1Kbyte).
Lastly, it makes no logical sense to only have 1024bit (128Bytes) tile regs because it is just too small.
Hence, you can safely assume that intel messed up on the slide and adjust your article accordingly. If you still don't believe it, ask intel yourself.
schujj07 - Tuesday, August 31, 2021 - link
One of the rumors for Gen 4 Epyc is 12 channels of DDR5. Now this is just a rumor so it HAS to be taken with a grain of salt. However, if Epyc goes 12 channels, Arm goes 12 channels, and SPR is at 8 channels we could see another instance like Gen 1 & 2 Xeon Scalable not having RAM parity. While going DDR5 does increase the bandwidth, I don't think it does enough to justify not increasing the channels at the same time.JayNor - Wednesday, September 1, 2021 - link
The four stacks of HBM, each with 8 channels DDR should take care of Intel's bandwidth issues for AI operations.schujj07 - Wednesday, September 1, 2021 - link
Bandwidth might be OK for AI with HBM on SPR. One thing to remember is that most of these are going to be running on hypervisors. 6 channel RAM became immediately an issue with Xeon Scalable (especially with their old 1TB/socket limit without L series CPUs where you could only get 768GB RAM). If they only have 8 channels when everyone else has 12 channels you cannot put as much RAM into a system for cheap. Most servers are dual socket and if you are using a hypervisor RAM capacity matters A LOT. If you can have 1.5TB (dual socket with 64GB DIMMs) instead of 1TB (dual socket with 64GB DIMMs) that makes a huge difference for running VMs. All the hosts in my datacenter run with 1TB RAM & dual 32c/64t CPUs. We are not CPU limited but we are RAM limited on each host. While VMware can do RAM compression/ballooning, once you start over provisioning RAM you will start running into performance issues. I've read that after about 10-15% over provisioning on RAM you start getting pretty major performance loss. I've experienced VMs basically stall out (like what happened in the early 2000s when your computer used 512MB RAM and you only had 384MB RAM) at a 50% over provision. Basically depending on the workload bandwidth isn't everything.Spunjji - Tuesday, September 7, 2021 - link
At what cost, though?schujj07 - Tuesday, September 7, 2021 - link
If you have to ask you cannot afford it.