The AMD Ryzen 7 5700G, Ryzen 5 5600G, and Ryzen 3 5300G Review
by Dr. Ian Cutress on August 4, 2021 1:45 PM ESTCPU Tests: Synthetic
Most of the people in our industry have a love/hate relationship when it comes to synthetic tests. On the one hand, they’re often good for quick summaries of performance and are easy to use, but most of the time the tests aren’t related to any real software. Synthetic tests are often very good at burrowing down to a specific set of instructions and maximizing the performance out of those. Due to requests from a number of our readers, we have the following synthetic tests.
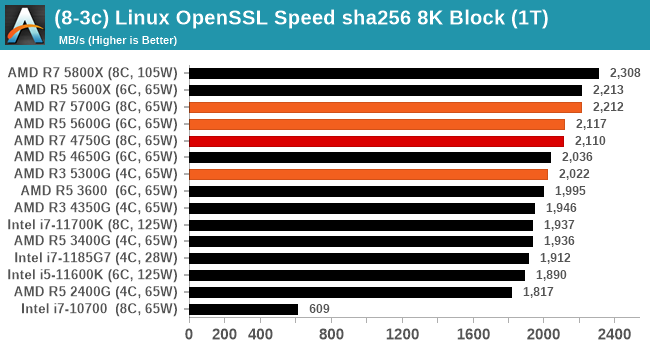
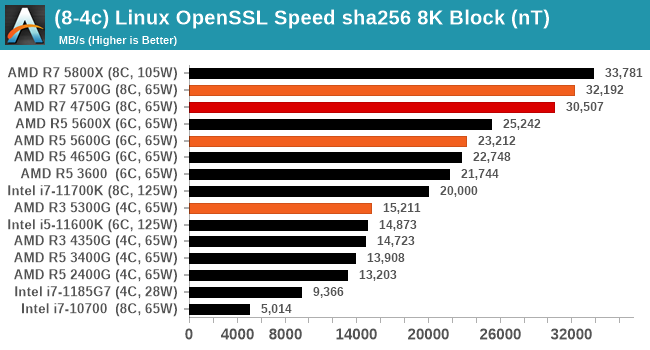
Linux OpenSSL Speed: SHA256
One of our readers reached out in early 2020 and stated that he was interested in looking at OpenSSL hashing rates in Linux. Luckily OpenSSL in Linux has a function called ‘speed’ that allows the user to determine how fast the system is for any given hashing algorithm, as well as signing and verifying messages.
OpenSSL offers a lot of algorithms to choose from, and based on a quick Twitter poll, we narrowed it down to the following:
- rsa2048 sign and rsa2048 verify
- sha256 at 8K block size
- md5 at 8K block size
For each of these tests, we run them in single thread and multithreaded mode. All the graphs are in our benchmark database, Bench, and we use the sha256 results in published reviews.
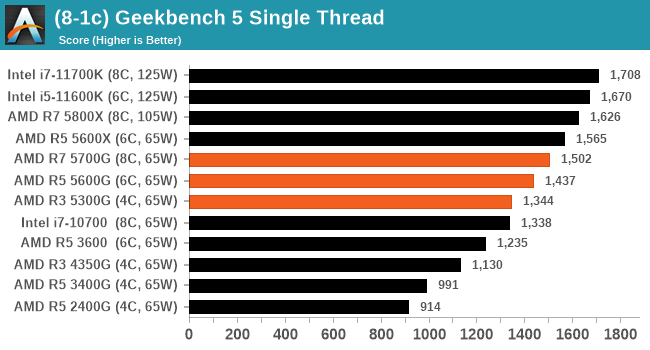
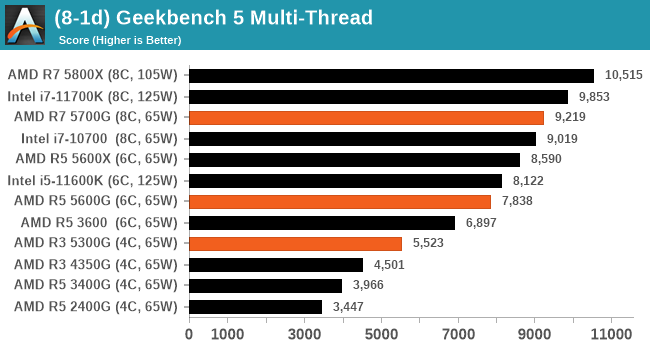
GeekBench 5: Link
As a common tool for cross-platform testing between mobile, PC, and Mac, GeekBench is an ultimate exercise in synthetic testing across a range of algorithms looking for peak throughput. Tests include encryption, compression, fast Fourier transform, memory operations, n-body physics, matrix operations, histogram manipulation, and HTML parsing.
I’m including this test due to popular demand, although the results do come across as overly synthetic, and a lot of users often put a lot of weight behind the test due to the fact that it is compiled across different platforms (although with different compilers).
We have both GB5 and GB4 results in our benchmark database. GB5 was introduced to our test suite after already having tested ~25 CPUs, and so the results are a little sporadic by comparison. These spots will be filled in when we retest any of the CPUs.
CPU Tests: SPEC
SPEC2017 and SPEC2006 is a series of standardized tests used to probe the overall performance between different systems, different architectures, different microarchitectures, and setups. The code has to be compiled, and then the results can be submitted to an online database for comparison. It covers a range of integer and floating point workloads, and can be very optimized for each CPU, so it is important to check how the benchmarks are being compiled and run.
We run the tests in a harness built through Windows Subsystem for Linux, developed by our own Andrei Frumusanu. WSL has some odd quirks, with one test not running due to a WSL fixed stack size, but for like-for-like testing is good enough. SPEC2006 is deprecated in favor of 2017, but remains an interesting comparison point in our data. Because our scores aren’t official submissions, as per SPEC guidelines we have to declare them as internal estimates from our part.
For compilers, we use LLVM both for C/C++ and Fortan tests, and for Fortran we’re using the Flang compiler. The rationale of using LLVM over GCC is better cross-platform comparisons to platforms that have only have LLVM support and future articles where we’ll investigate this aspect more. We’re not considering closed-sourced compilers such as MSVC or ICC.
clang version 10.0.0
-Ofast -fomit-frame-pointer
-march=x86-64
-mtune=core-avx2
-mfma -mavx -mavx2
Our compiler flags are straightforward, with basic –Ofast and relevant ISA switches to allow for AVX2 instructions. We decided to build our SPEC binaries on AVX2, which puts a limit on Haswell as how old we can go before the testing will fall over. This also means we don’t have AVX512 binaries, primarily because in order to get the best performance, the AVX-512 intrinsic should be packed by a proper expert, as with our AVX-512 benchmark. All of the major vendors, AMD, Intel, and Arm, all support the way in which we are testing SPEC.
To note, the requirements for the SPEC licence state that any benchmark results from SPEC have to be labelled ‘estimated’ until they are verified on the SPEC website as a meaningful representation of the expected performance. This is most often done by the big companies and OEMs to showcase performance to customers, however is quite over the top for what we do as reviewers.
For each of the SPEC targets we are doing, SPEC2006 1T, SPEC2017 1T, and SPEC2017 nT, rather than publish all the separate test data in our reviews, we are going to condense it down into a few interesting data points. The full per-test values are in our benchmark database.
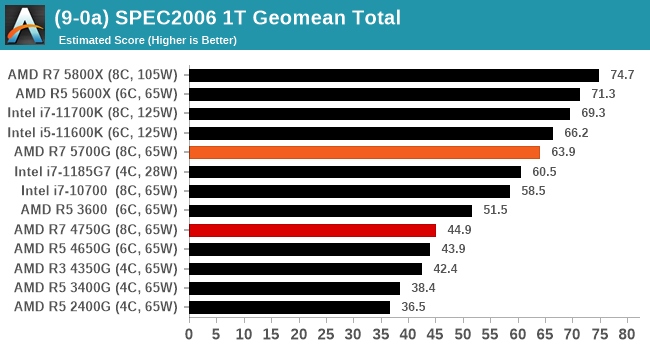
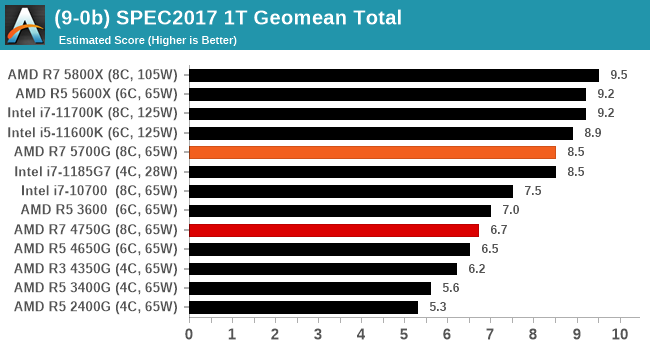
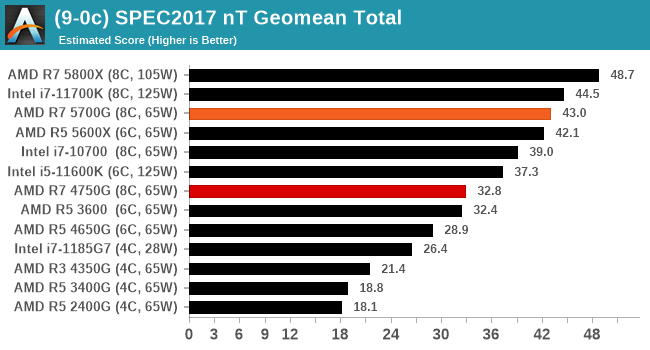
We’re still running the tests for the Ryzen 5 5600G and Ryzen 3 5300G, but the Ryzen 7 5700G scores strong.








135 Comments
View All Comments
abufrejoval - Thursday, August 5, 2021 - link
There are indeed so many variables and at least as many shortages these days. And it's becoming a playground for speculators, who are just looking for such fragilities in the suppy chain to extort money.I remember some Kaveri type chips being sold by AMD, which had the GPU parts chopped off by virtue of being "borderline dies" on a round 300mm wafer. Eventually they also had enough of these chips with the CPU (and SoC) portion intact, to sell them as a "GPU-less APU".
Don't know if the general layout of the dies allows for such "halflings" on the left or right of a wafer...
mode_13h - Wednesday, August 4, 2021 - link
Ian, please publish the source of 3DPM, preferably to github, gitlab, etc.mode_13h - Wednesday, August 4, 2021 - link
For me, the fact that 5600X always beats 5600G is proof that the non-APUs' lack of an on-die memory controller is no real deficiency (nor is the fact that the I/O die is fabbed on an older process node).GeoffreyA - Thursday, August 5, 2021 - link
The 5600X's bigger cache and boost could be helping it in that regard. But, yes, I don't think the on-die memory controller makes that much of a difference compared to the on-package one.mode_13h - Friday, August 6, 2021 - link
I wrote that knowing about the cache difference, but it's not going to help in all cases. If the on-die memory controller were a real benefit over having it on the I/O die, I'd expect to see at least a couple benchmarks where the 5600G outperformed the 5600X. However, they didn't switch places, even once!I know the 5600X has a higher boost clock, but they're both 65W and the G has a higher base frequency. So, even on well-threaded, non-graphical benchmarks, it's quite telling that the G can never pass the X.
GeoffreyA - Friday, August 6, 2021 - link
Remember how the Core 2 Duo left the Athlon 64 dead on the floor? And that was without an on-die MC.mode_13h - Saturday, August 7, 2021 - link
That's not relevant, since there were incredible differences in their uArch and fab nodes.In this case, we get to see Zen 3 cores on the same manufacturing process. So, it should be a very well-controlled comparison. Still not perfect, but about as close as we're going to get.
Also, the memory controller is in-package, in both cases. The main difference of concern is whether or not it's integrated into the 7 nm compute die.
GeoffreyA - Saturday, August 7, 2021 - link
In agreement with what you are saying, even in my first comment. I think Cezanne shows that having the memory controller on the package gets the critical gains (vs. the old northbridge), and going onto the main die doesn't add much more.As for K8 and Conroe, I always felt it was notable in that C2D was able to do such damage, even without an IMC. Back when K8 was the top dog, the tech press used to make a big deal about its IMC, as if there were no other improvements besides that.
mode_13h - Sunday, August 8, 2021 - link
One bad thing about moving it on-die is that this gave Intel an excuse to tie ECC memory support to the CPU, rather than just the motherboard. I had a regular Pentium 4 with ECC memory, and all it required was getting a motherboard that supported it.As I recall, the main reason Intel lagged in moving it on-die is that they were still flirting with RAMBUS, which eventually went pretty much nowhere. At work, we built one dual-CPU machine that required RAMBUS memory, but that was about the only time I touched the stuff.
As for the benefits of moving it on-die, it was seen as one of the reasons Opteron was able to pull ahead of Pentium 4. Then, when Nehalem eventually did it, it was seen as one of the reasons for its dominance over Core 2.
GeoffreyA - Sunday, August 8, 2021 - link
Intel has a fondness for technologies that go nowhere. RAMBUS was supposed to unlock the true power of the Pentium 4, whatever that meant. Well, the Willamette I used for a decade had plain SDRAM, not even DDR. But that was a downgrade, after my Athlon 64 3000+ gave up the ghost (cheapline PSU). That was DDR400. Incidentally, when the problems began, they were RAM related. Oh, those beeps!