The AMD Ryzen 7 5700G, Ryzen 5 5600G, and Ryzen 3 5300G Review
by Dr. Ian Cutress on August 4, 2021 1:45 PM ESTCPU Tests: Encoding
One of the interesting elements on modern processors is encoding performance. This covers two main areas: encryption/decryption for secure data transfer, and video transcoding from one video format to another.
In the encrypt/decrypt scenario, how data is transferred and by what mechanism is pertinent to on-the-fly encryption of sensitive data - a process by which more modern devices are leaning to for software security.
Video transcoding as a tool to adjust the quality, file size and resolution of a video file has boomed in recent years, such as providing the optimum video for devices before consumption, or for game streamers who are wanting to upload the output from their video camera in real-time. As we move into live 3D video, this task will only get more strenuous, and it turns out that the performance of certain algorithms is a function of the input/output of the content.
HandBrake 1.32: Link
Video transcoding (both encode and decode) is a hot topic in performance metrics as more and more content is being created. First consideration is the standard in which the video is encoded, which can be lossless or lossy, trade performance for file-size, trade quality for file-size, or all of the above can increase encoding rates to help accelerate decoding rates. Alongside Google's favorite codecs, VP9 and AV1, there are others that are prominent: H264, the older codec, is practically everywhere and is designed to be optimized for 1080p video, and HEVC (or H.265) that is aimed to provide the same quality as H264 but at a lower file-size (or better quality for the same size). HEVC is important as 4K is streamed over the air, meaning less bits need to be transferred for the same quality content. There are other codecs coming to market designed for specific use cases all the time.
Handbrake is a favored tool for transcoding, with the later versions using copious amounts of newer APIs to take advantage of co-processors, like GPUs. It is available on Windows via an interface or can be accessed through the command-line, with the latter making our testing easier, with a redirection operator for the console output.
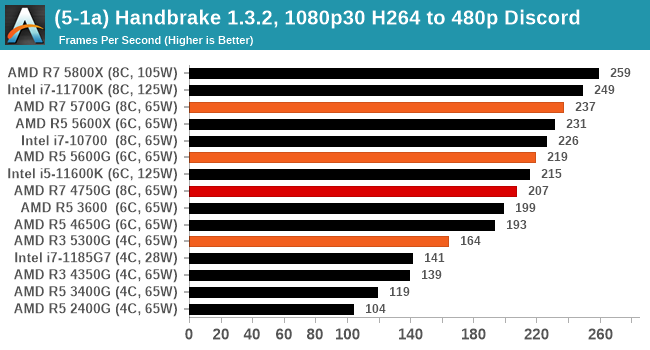
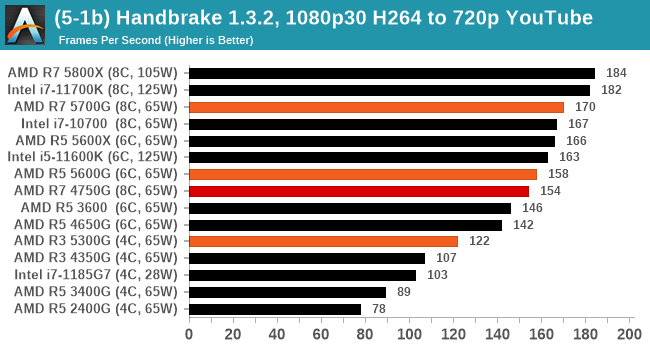
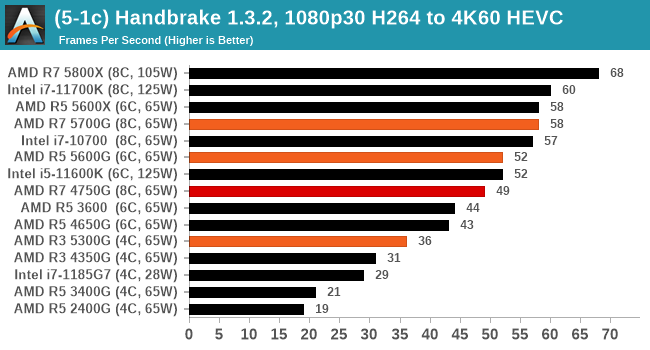
We take the compiled version of this 16-minute YouTube video about Russian CPUs at 1080p30 h264 and convert into three different files: (1) 480p30 ‘Discord’, (2) 720p30 ‘YouTube’, and (3) 4K60 HEVC.
7-Zip 1900: Link
The first compression benchmark tool we use is the open-source 7-zip, which typically offers good scaling across multiple cores. 7-zip is the compression tool most cited by readers as one they would rather see benchmarks on, and the program includes a built-in benchmark tool for both compression and decompression.
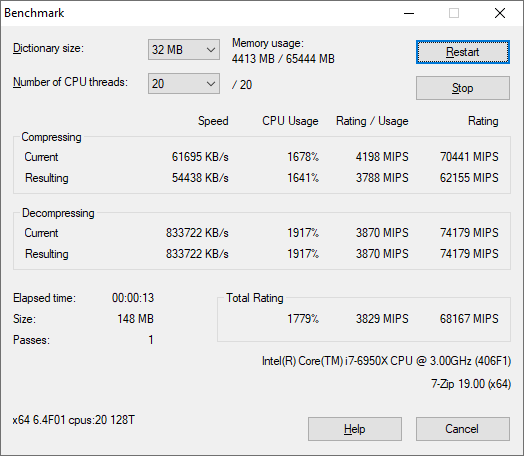
The tool can either be run from inside the software or through the command line. We take the latter route as it is easier to automate, obtain results, and put through our process. The command line flags available offer an option for repeated runs, and the output provides the average automatically through the console. We direct this output into a text file and regex the required values for compression, decompression, and a combined score.
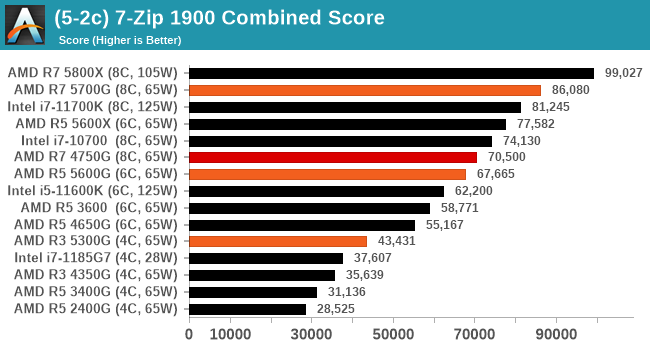
AES Encoding
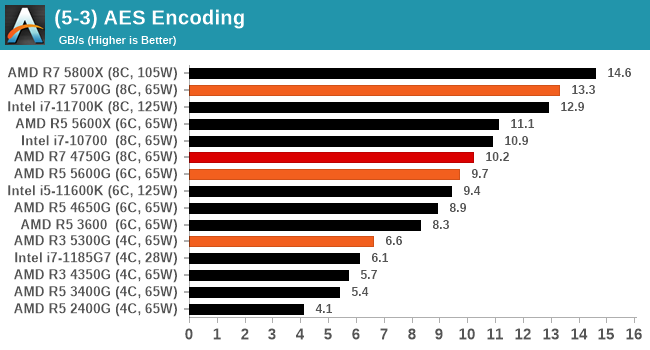
Algorithms using AES coding have spread far and wide as a ubiquitous tool for encryption. Again, this is another CPU limited test, and modern CPUs have special AES pathways to accelerate their performance. We often see scaling in both frequency and cores with this benchmark. We use the latest version of TrueCrypt and run its benchmark mode over 1GB of in-DRAM data. Results shown are the GB/s average of encryption and decryption.
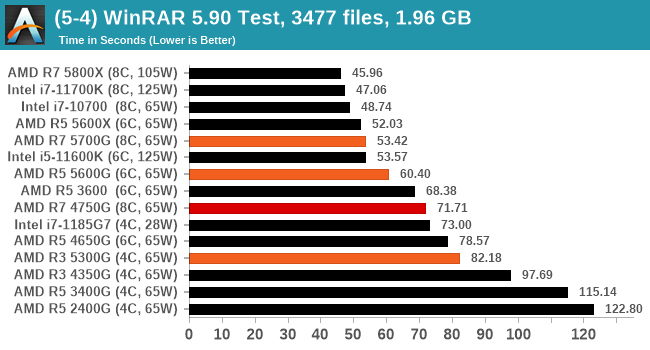
WinRAR 5.90: Link
For the 2020 test suite, we move to the latest version of WinRAR in our compression test. WinRAR in some quarters is more user friendly that 7-Zip, hence its inclusion. Rather than use a benchmark mode as we did with 7-Zip, here we take a set of files representative of a generic stack
- 33 video files , each 30 seconds, in 1.37 GB,
- 2834 smaller website files in 370 folders in 150 MB,
- 100 Beat Saber music tracks and input files, for 451 MB
This is a mixture of compressible and incompressible formats. The results shown are the time taken to encode the file. Due to DRAM caching, we run the test for 20 minutes times and take the average of the last five runs when the benchmark is in a steady state.
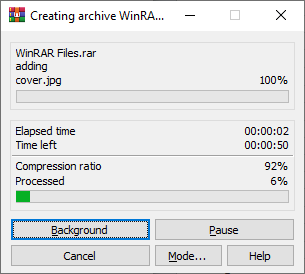
For automation, we use AHK’s internal timing tools from initiating the workload until the window closes signifying the end. This means the results are contained within AHK, with an average of the last 5 results being easy enough to calculate.








135 Comments
View All Comments
Wereweeb - Wednesday, August 4, 2021 - link
The bottleneck is memory bandwidth. DDR5 will raise the iGPU performance roof by a substantial amount, but I hope for something like quad-channel OMI-esque Serial RAM.abufrejoval - Saturday, August 7, 2021 - link
I'd say so, too, but...I have just had a look at a Kaveri A10-7850K with DDR3-2400 (100 Watt desktop), a 5800U based notebook with LPDDR4 (1333MHz clock) and a Tiger Lake NUC with an i7-1165G7 with DDR4-3200.
The memory bandwidth differences between the Kaveri and the 5800U is absolutely minor, 38.4 GB/s for the Kaveri vs. 42.7GB/s for Cezanne (can't get the TigerLake figures right now, because it's running a Linux server, but it will be very similar).
The Kaveri and Cezanne iGPUs are both 512 shaders and apart from architectural improvements very much differ in clocks 720MHz vs. 2000MHz. The graphics performance difference on things like 3DMark scale pretty exactly with that clock difference.
Yet when Kaveri was launched, Anandtech noted that the 512 shader A10 variant had trouble to do better then the 384 shader APUs, because only with the very fastest RAM it could make these extra shaders pump out extra FPS.
When I compared the Cezanne iGPU against the TigerLake X2, both systems at tightly fixed 15 and 28Watts max power settings, TigerLake was around 50% faster on all synthetic GPU benchmarks.
The only explanation I have for these fantastic performance increases is much larger caches being very smartly used by breaking down GPU workloads to just fit within them, while prefetching the next tile of bitmaps into the cache in the background and likewise pushing processed tiles to the framebuffer RAM asynchronously to avoid stalling GPU pipelines.
And yet I'd agree that there really isn't much wiggling room left, you need exponential bandwidth to cover square resolution increases.
abufrejoval - Saturday, August 7, 2021 - link
need edit!Is TigerLake Xe, not X2.
Another data point:
I also have an NUC8 with an 48EU (+128MB eDRAM) Iris 655 i7 and a NUC10 with an 24EU "no Iris" UHD i7. Even with twice the EUs and the extra eDRAM (which I believe can be used in parallel to the external DRAM), the Iris only gets a 50% performance increase.
The the 96EU TigerLake iGPU is doing so much better (better than linear scale over UHD) while it actually has somewhat less bandwidth (and higher latency) than the 50GB/s eDRAM provides for the 48EU Iris.
bwj - Wednesday, August 4, 2021 - link
Why are these parts getting stomped by Intel and their non-graphics Ryzen siblings?bwj - Wednesday, August 4, 2021 - link
Meh, meant to say "in browser benchmarks". Browser is an important workload (for me at least) and the x86 crowd is already fairly weak versus Apple M1, so I'm not ready to throw away another 30% of browser perf.Lezmaka - Wednesday, August 4, 2021 - link
There are only 3 browser tests and for two of them the 5700G is within a few percent of the 11700K. But otherwise, it's because these are laptop chips with higher TDP. The 11700K has a TDP of "125W" but hit 277W where the 5700G has a TDP of 65W and maxed out at 88W.Makaveli - Wednesday, August 4, 2021 - link
There is something up with the browser scores here anyways compared to what you see in the forum. All the post with similar desktop cpu's in that thread post much high scores than what is listed in the graph. I'm not sure its old browser version being used to keep scores inline with older reviews or something.https://forums.anandtech.com/threads/how-fast-is-y...
abufrejoval - Wednesday, August 4, 2021 - link
When you ask: "Why don't they release the four core variant?" you really should be able to answer that yourself!There are simply not enough defective chips to make it viable just yet. Eventually they may accumulate, but as long as they are trying to produce an 8 core chip, 4 and 6 cores should remain the exception not the rule.
I'd really like to see them struggle putting the lesser chips out there, because it means my 8/16(/32/64) core chips are rock solid!
I would have liked to see full transistor counts of the 5800X and the 5700U side by side. My guess would be that the Cezanne dies even at 50% cache have more transistors overall, meaning you are getting many more pricey 7nm transistors per € on these APUs and should really pay a markup not a discount.
Well even the GF IO die fab capacity might have customers lined up these days, but in normal times those transistors should be much more commodity and cheaper and have the APU cost more in pure foundry (less in packaging) than the X-variants, while AMD wants to fit it into a below premium price slot where it really doesn't belong.
nandnandnand - Wednesday, August 4, 2021 - link
If AMD boosted chiplet/monolithic core count to 12, maybe 6 cores could become the new minimum with 10-core being a possibility. But it doesn't look like they plan to do that.Wereweeb - Wednesday, August 4, 2021 - link
These might have been a stockpile of dies that were rejected for laptop use (High power consumption @ idle?) and they're being dumped into the market after AMD satisfied OEM demand for APU's.Plus, considering that one of the main shortages is for substrates, it's possible that the substrate for the APU's is different - cheaper, higher volume, etc... as it doesn't need to interconnect discrete chiplets.