Arm Announces Mobile Armv9 CPU Microarchitectures: Cortex-X2, Cortex-A710 & Cortex-A510
by Andrei Frumusanu on May 25, 2021 9:00 AM EST- Posted in
- SoCs
- CPUs
- Arm
- Smartphones
- Mobile
- Cortex
- ARMv9
- Cortex-X2
- Cortex-A710
- Cortex-A510
The Cortex-A710: More Performance with More Efficiency
While the Cortex-X2 goes for all-out performance while paying the power and area penalties, Arm's Cortex-A710 design goes for a more efficient approach.
First of all, the new product nomenclature now is self-evident in regards to what Arm will be doing going forward- they’re skipping the A79 designation and simply starting fresh with a new three-digit scheme with the A710. Not very important in the grand scheme of things but an interesting marketing tidbit.

The Cortex-A710, much like the X2, is an Armv9 core with all new features that come with the new architecture version. Unlike the X2, the A710 also supports EL0 AArch32 execution, and as mentioned in the intro, this was mostly a design choice demanded by customers in the Chinese market where the ecosystem is still slightly lagging behind in moving all applications over to AArch64.

In terms of front-end enhancements, we’re seeing the same branch prediction improvements as on the X2, with larger structures as well as better accuracy. Other structures such as the L1I TLB have also seen an increase from 32 entries to 48 entries. Other front-end structures such as the macro-OP cache remain the same at 1.5K entries (The X2 also remains at 3K entries).

A very interesting choice for the A710 mid-core is that Arm has reduced the macro-OP cache and dispatch stage throughputs from 6-wide to 5-wide. This was mainly a targeted power and efficiency optimization for this generation, as we’re seeing a more important divergence between the Cortex-A and Cortex-X cores in terms of their specializations and targeted use-cases for performance and power.
The dispatch stage also features the same optimizations as on the X2, removing 1 cycle from the pipeline towards an overall 10-cycle pipeline design.
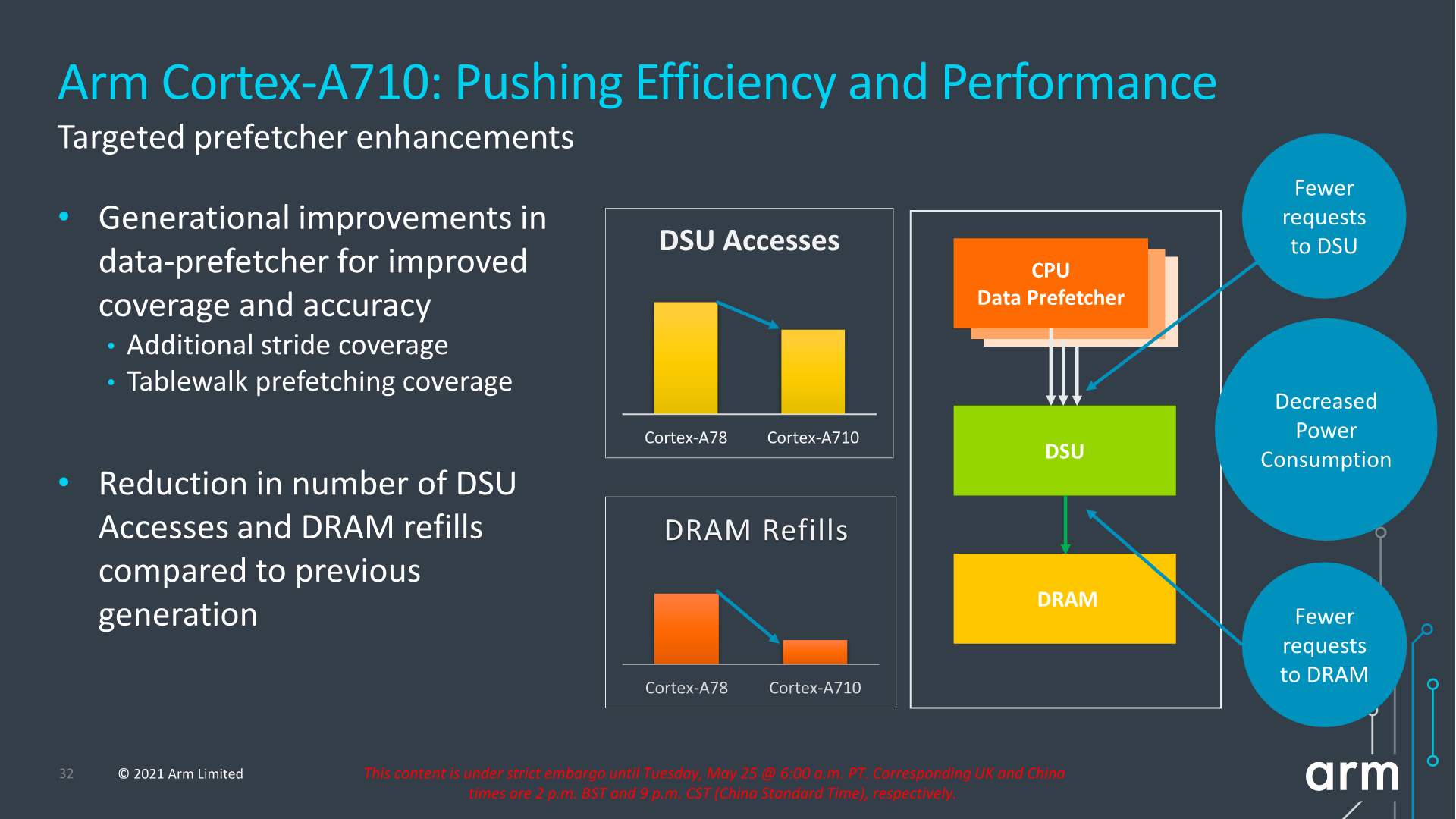
Arm also focuses on core improvements that affect the uncore parts of the system, which take place thanks to the new improvements in the prefetcher designs and how they interact with the new DSU-110 (which we’ll cover later). The new combination of core and DSU are able to reduce access from the core towards the L3 cache, as well as reducing the costly DRAM accesses thanks to the more efficiency prefetchers and larger L3 cache.
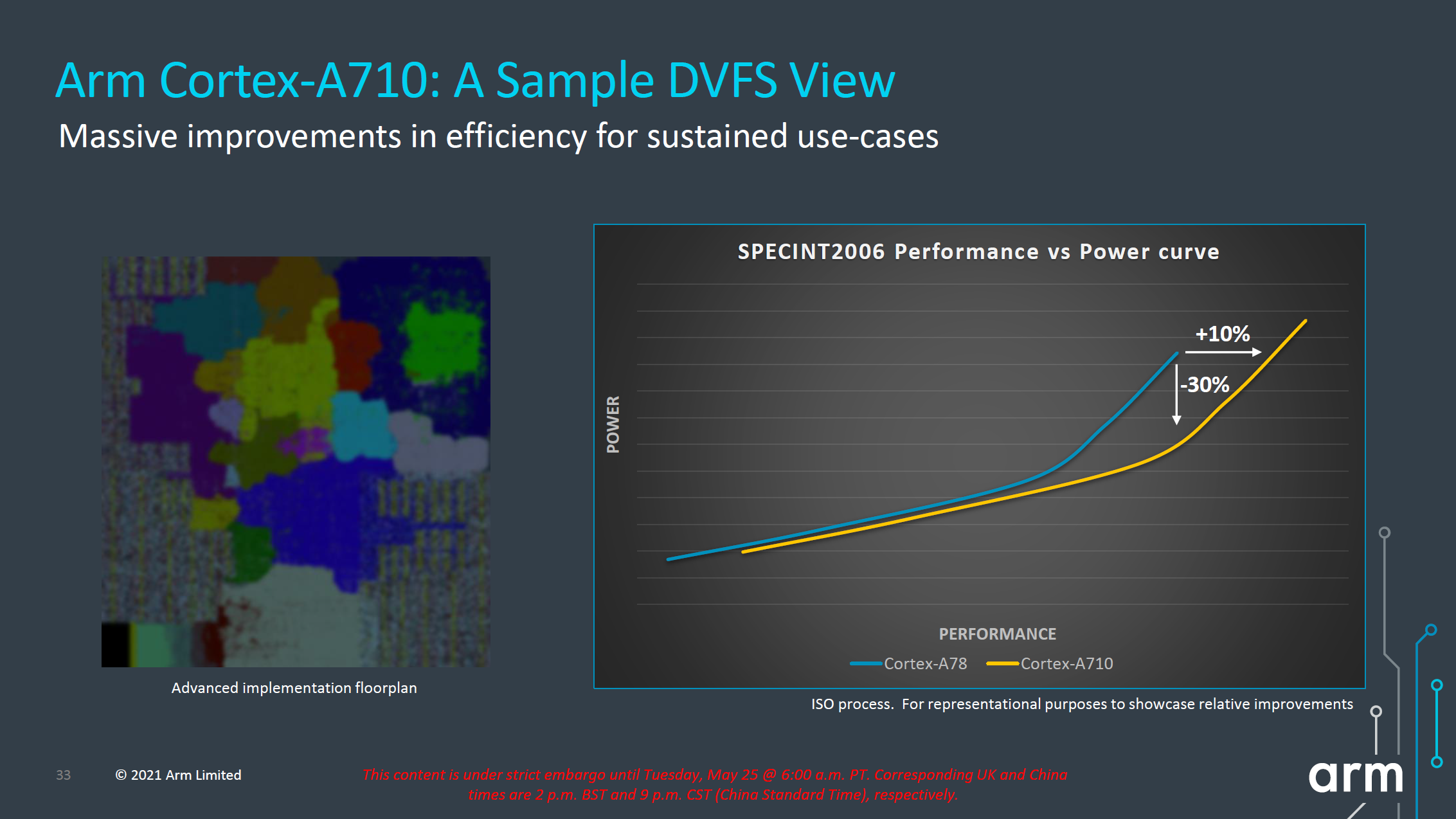
In terms of IPC, Arm advertises +10%, but again the issue with this figure here is that we’re comparing an 8MB L3 cache design to a 4MB L3 cache design. While this is a likely comparison for flagship SoCs next year, because the Cortex-A710 is also a core that would be used in mid-range or lower-end SoCs which might use much smaller L3 caches, it’s unlikely we’ll be seeing such IPC improvements in that sector unless the actual SoCs really do also improve their DSU sizes.
More important than the +10% improvement in performance is that, when backing off slightly in frequency, we can see that the power reduction can be rather large. According to Arm, at iso-performance the A710 consumes up to 30% less power than the Cortex-A78. This is something that would greatly help with sustained performance and power efficiency of more modestly clocked “middle” core implementations of the Cortex-A710.
In general, both the X2 and the A710’s performance and power figures are quite modest, making them the smallest generation-over-generation figures we’ve seen from Arm in quite a few years. Arm explains that due to this generation having made larger architectural changes with the move to Armv9, there has been an impact in regards to the usual efficiency and performance improvements that we’ve seen in prior generations.
Both the X2 and the A710 are also the fourth generation of this Austin microarchitecture family, so we’re hitting a wall of diminishing returns and maturity of the design. A few years ago we were under impression that the Austin family would only go on for three generations before handing things over to a new clean-sheet design from the Sophia team, but that original roadmap has been changed, and now we'll be seeing the new Sophia core with larger leaps in performance being disclosed next year.








181 Comments
View All Comments
name99 - Tuesday, May 25, 2021 - link
Inrinsity was about circuit design.PA Semi was about microarchitecture.
There was a *lot* of good stuff in PA Semi! I have looked quickly at quite a few of the Intrinsity patents, but I don't know enough about that level of the stack to have any option as to how impressive they were. (This is not a criticism -- even if all that was picked up from Intrinsity was a number of competent engineers capable of implementing the micro-architecture ideas of the PA Semi folks, that's an essential part of shipping a chip!)
I'd honestly love someone who is familiar with the circuit level to look at the Intrinsity (low level and PA Semi patents, like for a new register file design) and let us know an informed opinion.
But as important as both of these has been Apple's willingness to keep pushing the envelope, to keep pouring money into design, to keep taking risks (every design change is a risk...) and not to accept "good enough". That might seem obvious except that, of course,
- Intel has been cruising on "good enough" for 10 years,
- QC (notoriously) made "good enough" its official response to the A7, and followed that up by cancelling Centriq, and
- ARM, for whatever reason, seems to alternate between designs that look like they're trying to at least approach Apple, and designs that feel like "good enough.
melgross - Tuesday, May 25, 2021 - link
Intrinsity was about efficiency. That was what they were known for.mode_13h - Wednesday, May 26, 2021 - link
> anyone in the non-iOS space is stuck with this attempt to inject some> Bulldozer design features into the tired in-order A55 lineage.
Well, they can have just one core per complex, instead of 2.
I'm not really sure why the hate, unless you think you're going to be running a lot of FP/vector threads.
melgross - Thursday, May 27, 2021 - link
That was the problem with Bulldozer. They made the same mistake.mode_13h - Saturday, May 29, 2021 - link
> That was the problem with Bulldozer. They made the same mistake.You mean the 2 cores per complex? But ARM is giving customers the option to order up an A510 with just 1 per complex, if you think you need enough FP/vector throughput to warrant it.
I think a lot of the hate being directed at the A510 is mere guilt by association. It's massively different than Bulldozer, but the sharing of that one feature really seems to have tainted it with all the negative feelings people have towards Bulldozer.
lemurbutton - Tuesday, May 25, 2021 - link
x86 is dead.AMD doing 5% to 15% improvements every year.
Intel doing -5% to 10% every year.
Meanwhile, Apple & ARM are doing 10 - 20%+ every year and including accelerators like machine learning.
M1 runs circles around anything AMD and Intel have. M1X and M2 will allow Apple to claim performance wins across all consumer computing devices. Can't wait for the 32/64 core Mac Pros too. It's going to be ugly for AMD/Intel.
SarahKerrigan - Tuesday, May 25, 2021 - link
I would be hesitant to lump in Apple and ARM, given how far apart the highest-performing shipping licensables and the highest-performing shipping Apple cores are.ARM is still a long way from matching peak AMD or Intel ST (not merely iso clock, where they do okay, but absolute) in any shipping product, and honestly, neither A710 nor X2 look especially groundbreaking. A510 looks really good, but mixed with a certain amount of "well, about frigging time."
ikjadoon - Tuesday, May 25, 2021 - link
I agree on point 1, sadly. The X1 earns 40 points on SPEC2006 1T Geomean, while the A14 broke 70 points and A13 is 59 points.The X2 vs A15 battle will be interesting in terms of power, but the X2 will likely be slower than the A13.
On the second, isn’t the A510 four years late and it has an almost identical power vs performance curve to the A55? Personally, I thought it was the smallest and saddest announcement today.
The only genuine A510 improvement is at the A55’s worst position / peak power: 10% faster for 20% less power. That’s four years later.
The rest of A510 power vs performance is by ramping up the power budget. That +10% perf for -20% power = 37.5% increase in perf-power over four years = 8% perf-power improvements per year. ;(
If they are sticking with in-order, I hoped the A510 could’ve done something more over four years.
Raqia - Tuesday, May 25, 2021 - link
Apple will rule the roost for the next year, at least until Nuvia's Phoenix cores make their debut some time in the second half of 2022 (that announced timeline likely means the design has taped out...) The cache hierarchy of Apple CPU complexes is simpler and fewer in level than what ARM's is capable of, which reflects the scope of their respective ambitions. ARM's hierarchy hobbles performance at mobile device scales but has much more headroom for supercomputing or server scale compute.Wilco1 - Tuesday, May 25, 2021 - link
Your numbers are off. AnandTech's SPECINT2006 results are 63.34 for A14 and 41.3 for SD888: https://images.anandtech.com/doci/16463/SPEC-power...TSMC 5nm offers ~15% speedup over 7nm, so 3.3-3.5GHz may be feasible (compared to 3.1GHz for SD865+ on 7nm), and that should get Cortex-X2 scores in the high 50's, close to the A14.
As for efficiency, it's unrealistic to expect major gains when starting from an already very efficient design. It's the same with performance, you can't expect a doubling of ST performance every few years like in the past.