Arm Announces Mobile Armv9 CPU Microarchitectures: Cortex-X2, Cortex-A710 & Cortex-A510
by Andrei Frumusanu on May 25, 2021 9:00 AM EST- Posted in
- SoCs
- CPUs
- Arm
- Smartphones
- Mobile
- Cortex
- ARMv9
- Cortex-X2
- Cortex-A710
- Cortex-A510
A new CI-700 Coherent Interconnect & NI-700 NoC For SoCs
Finally, the last new announcement of the day is a new interconnect and network-on-chip generation. The last time Arm had announced a mobile/client interconnect was back in in 2015 with the CCI-550. The reason for the large gap between IPs, in Arm’s own words, is that ever since Arm’s introduction of the DSU in its CPU complexes, there really hasn’t been any need for a cache coherent interconnect in the market. While that’s eyebrow-raising from a GPU perspective, it makes perfect sense from a CPU perspective, as coherency between CPU cores was the primary driver for such interconnects until then.
With the advent of new more complex computing platforms, such as NPUs, accelerators, and hopeful more use of GPUs in cache-coherent fashions, Arm saw a need gap in its portfolio and decided to update its client-side interconnect IP.


The new CI-700 is a mobile and client optimised variant of Arm’s infrastructure CMN mesh network, implementing important new interoperability with the new IP announced today, such as the new DSU or CPU cores.
The new mesh interconnect scales up from 1 to 8 DSU clusters, and supports up to 8 memory controllers, and also introduces innovations such as a system level cache.
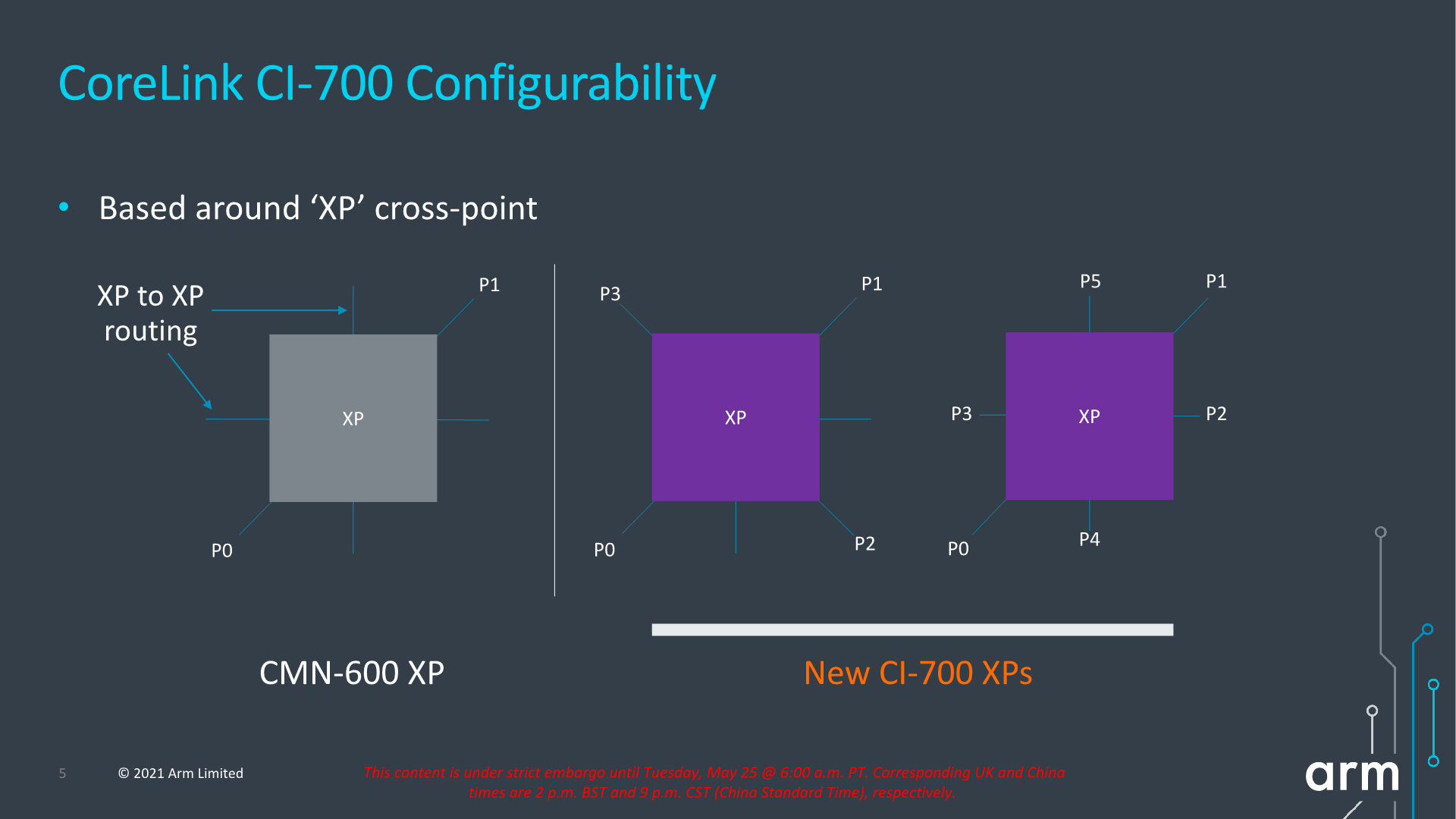

The mesh network topology and building blocks is very similar to what we’ve seen in the CMN infrastructure IP, in that “points” in the mesh are comprised of “cross-points” or “XP”. One differentiation that’s unique to the client mesh implementation is that XPs can have more attached connectivity ports, trading in routing connection paths. The new IP can also be configured as just a sole XP with no real mesh so to speak of, or essentially a 1x1 mesh configuration. This can grow up to a 4x3 mesh in the largest possible configuration.
The mesh supports from 1 to 8 SLC slices, with up to 4MB per slice for a total of 32MB, and snoop filter SRAM with coverage of up to 8MB address space per slice. It’s noted that generally Arm recommends 1.5-2x of coverage of the underlying private cache hierarchies of the mesh clients.
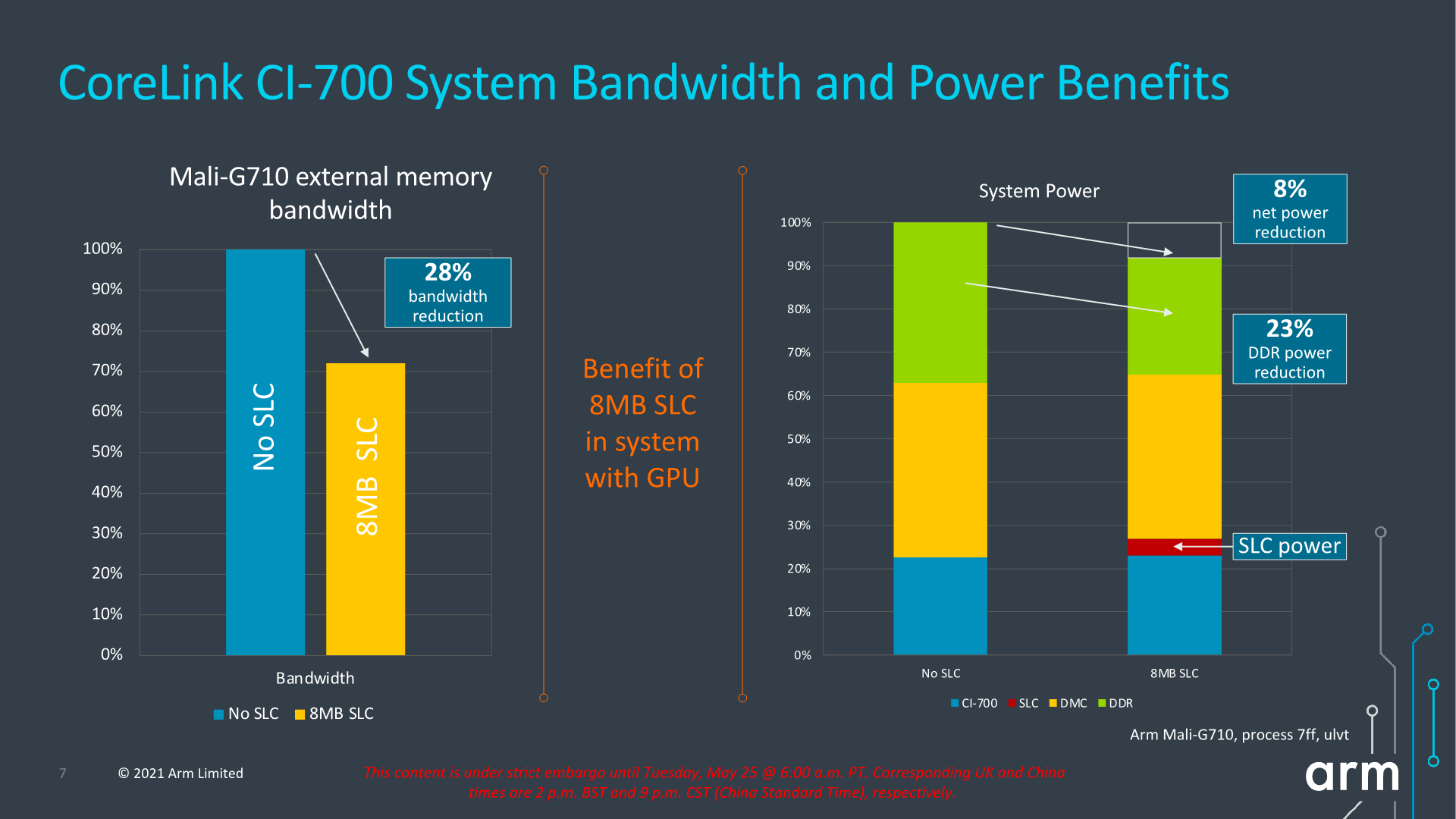
The SLC can server as both a bandwidth amplifier as well as reducing external memory/DRAM transactions, reducing system power reduction.
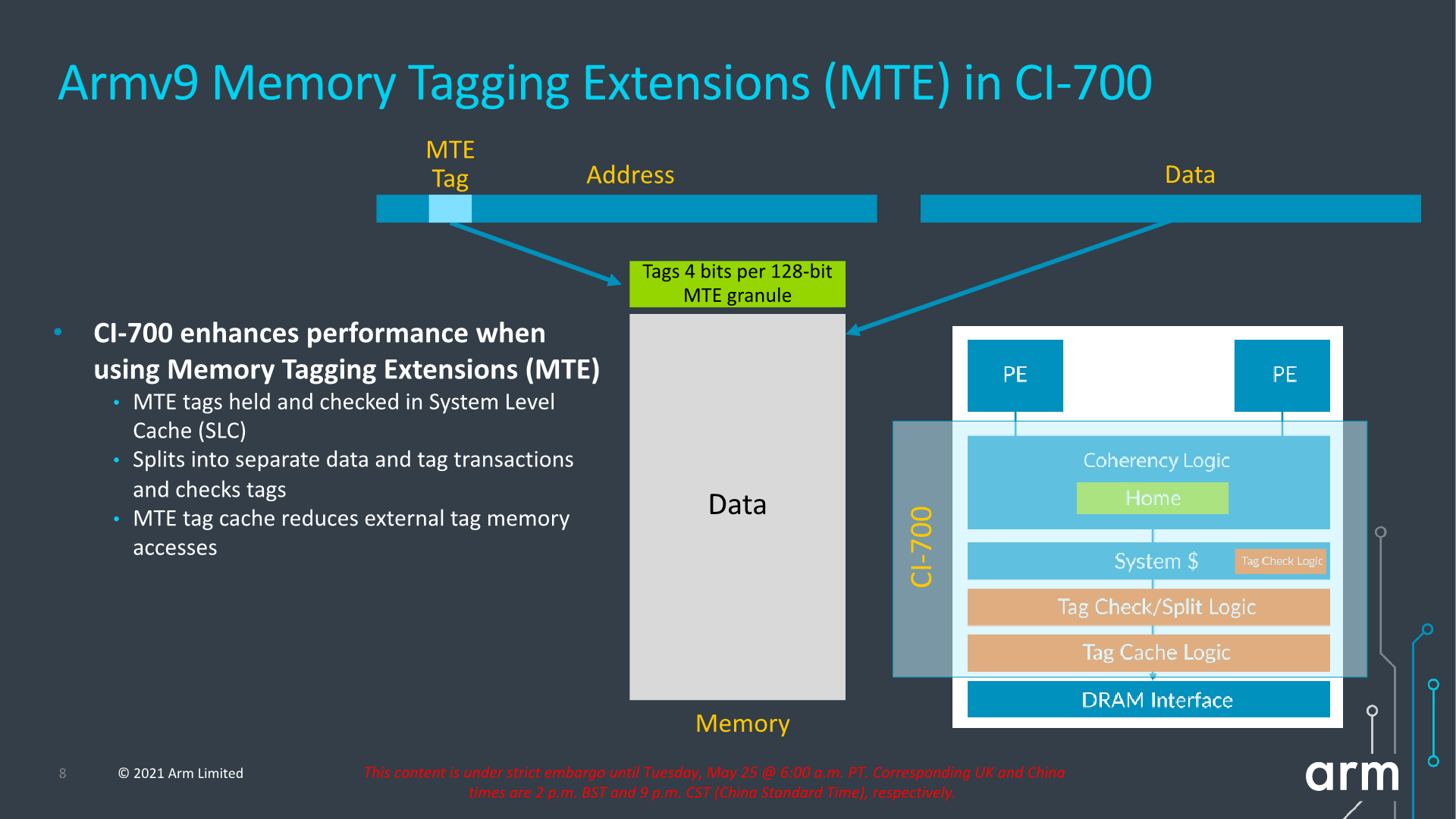
We see a reiteration of the support for MTE, allowing for this generation of IPs to support the feature across the new CPU IP, the DSU, and the new cache coherent interconnect.

Alongside the new CI-700 coherent interconnect, we’re also seeing a new NI-700 network-on-chip for non-coherent data transfers between a SoC’s various IP blocks. The big new improvements here is the introduction of packetization for data transfers, which leads to a reduction of wires and thus improves area efficiency of the NoC on the SoC.
Overall, the new system IP announced today is very interesting, but the one question that’s one has to ask oneself is exactly who these net interconnects are meant for. Over the last few years, we’ve seen essentially every major mobile vendor roll out their own in-house cache-coherent interconnect IP, such as Samsung’s SCI or MediaTek’s MCSI, and other times we don’t see vendors talk about their in-house interconnects at all (Qualcomm). Due to almost everybody having their own IP, I’m not sure what the likelihood would be that any of the big players would jump back to Arm’s own solutions – if somebody were to adopt it, it would rather be amongst the smaller name vendors and newcomers to the market. From a business and IP portfolio perspective, the new designs make a lot of sense and allows to have the building blocks to create a mostly Arm-only SoC, which is an important item to have on the menu for Arm’s more diverse customer base.








181 Comments
View All Comments
ChrisGX - Monday, May 31, 2021 - link
There is one part of Andrei's analysis of the X2 core that I don't get. I do get the scepticism about ARM's optimistic estimate of a 30% lift in peak performance being on offer given the dismal underperformance of Samsung's 5nm silicon but my reading of what ARM has said is that the 16% performance gain for the X2 is ISO process, i.e. on the same silicon process at the same power and frequency. Am I wrong to read this as (effectively) an IPC gain without an energy cost associated with it? (Let us ignore for the moment such good news will likely be dashed due of Samsung's iffy silicon.) I know that sounds like a very rosy picture but isn't that the picture that ARM painted? In this context I don't get Andrei's suggestion of a lineal increase in power for that peak performance gain.Personally, I find the claim of a 16% performance gain hard to believe (and the 30% number after unspecified silicon process improvements and processor clock boost, presumably, even harder to believe). Still, I want to be clear on what ARM is claiming and what I have missed (if anything). Any comments would be welcome.
ChrisGX - Monday, May 31, 2021 - link
I have just reviewed Andrei's analysis again and I note he referred to a power increase (not a lineal power increase in proportion to the 16% performance increase) drawing particularly attention to the increased cache size.ChrisGX - Wednesday, June 2, 2021 - link
Regarding the projections of a 30% peak performance increase for a premium mobile SoC in 2022 I can't see how to get to that performance number (after a 16% IPC increase) without a) the prime X2 core being clocked at around 3.3GHz - 3.35GHz and b) corresponding silicon process improvements that permit lower voltages (at the increased core frequency). That implies a process that is better than TSMC's N5.For an 8 core X2 based SoC for consumer computers that performs at a peak rate of 1.4x the performance of a Core i5-1135G7 (which would represent a truly stunning level of performance) I think the SoC would have to be clocked at around 3.7GHz - 3.8GHz (again on a process that is markedly better than TSMC's N5). Performance like that, of course, won't come without elevating core and SoC power consumption to a significant degree.
Getting performance outcomes as good as that doesn't seem especially likely to me.
mode_13h - Wednesday, June 2, 2021 - link
Thanks for the analysis. If correct, this could mark the opening of a significant credibility gap, in ARM's projections.ChrisGX - Sunday, June 6, 2021 - link
I just had a look at the PPA Improvements that TSMC has advertised for its N4 process (there are unconfirmed claims that Qualcomm will be using N4 for the next premium SoC for flagship Android mobile phones) and I don't see ARM's projected performance numbers being reached on that process. N3 would do it but we won't see that before 2H2022. Without inviting thermal problems a performance improvement of 24% at 3.2GHz might fall within the bounds of possibility. (Note: Information on the N4 process is thin but I have assumed 7% more performance will be available at the same power compared to N5. With additional performance improvements of 16% from IPC gains - without pushing the power budget - a performance lift of 24% seems feasible.)https://www.anandtech.com/show/16639/tsmc-update-2...
rohn287 - Thursday, December 2, 2021 - link
Just asking, why not use 2-X2 cores with 2 higher clocked A710 and 2 normal A710. This will help reduce heat and increase performance in Android phones. Similar to Apples approach.The Futuristic - Saturday, April 2, 2022 - link
I know it's too late for comment, but the processors with this core have just entered the market. Depending on them and comparing them with Apple A15 E cores especially, I think they should start using cortex A710 as E cores instead of cortex A55. Apple E cores consumes around 0.44watt, cortex A78 in dimensity 1200 at 6nm uses 1.16W for same performance. So A710 is 30% efficient for same and taking it even further on 5nm. It will close the gap between Apple E cores and cortex cores. So 2x cortex X2 + 4x cortex A710 configured CPU, will catch Apple A15 in multi-core atleast.yeeeeman - Wednesday, May 11, 2022 - link
we're getting very close to the cortex x3 announcement.yeeeeman - Saturday, June 4, 2022 - link
seems like arm is missing the end of may announcements this year. anyone knows why?