Arm Announces Mobile Armv9 CPU Microarchitectures: Cortex-X2, Cortex-A710 & Cortex-A510
by Andrei Frumusanu on May 25, 2021 9:00 AM EST- Posted in
- SoCs
- CPUs
- Arm
- Smartphones
- Mobile
- Cortex
- ARMv9
- Cortex-X2
- Cortex-A710
- Cortex-A510
The Cortex-A710: More Performance with More Efficiency
While the Cortex-X2 goes for all-out performance while paying the power and area penalties, Arm's Cortex-A710 design goes for a more efficient approach.
First of all, the new product nomenclature now is self-evident in regards to what Arm will be doing going forward- they’re skipping the A79 designation and simply starting fresh with a new three-digit scheme with the A710. Not very important in the grand scheme of things but an interesting marketing tidbit.

The Cortex-A710, much like the X2, is an Armv9 core with all new features that come with the new architecture version. Unlike the X2, the A710 also supports EL0 AArch32 execution, and as mentioned in the intro, this was mostly a design choice demanded by customers in the Chinese market where the ecosystem is still slightly lagging behind in moving all applications over to AArch64.

In terms of front-end enhancements, we’re seeing the same branch prediction improvements as on the X2, with larger structures as well as better accuracy. Other structures such as the L1I TLB have also seen an increase from 32 entries to 48 entries. Other front-end structures such as the macro-OP cache remain the same at 1.5K entries (The X2 also remains at 3K entries).

A very interesting choice for the A710 mid-core is that Arm has reduced the macro-OP cache and dispatch stage throughputs from 6-wide to 5-wide. This was mainly a targeted power and efficiency optimization for this generation, as we’re seeing a more important divergence between the Cortex-A and Cortex-X cores in terms of their specializations and targeted use-cases for performance and power.
The dispatch stage also features the same optimizations as on the X2, removing 1 cycle from the pipeline towards an overall 10-cycle pipeline design.
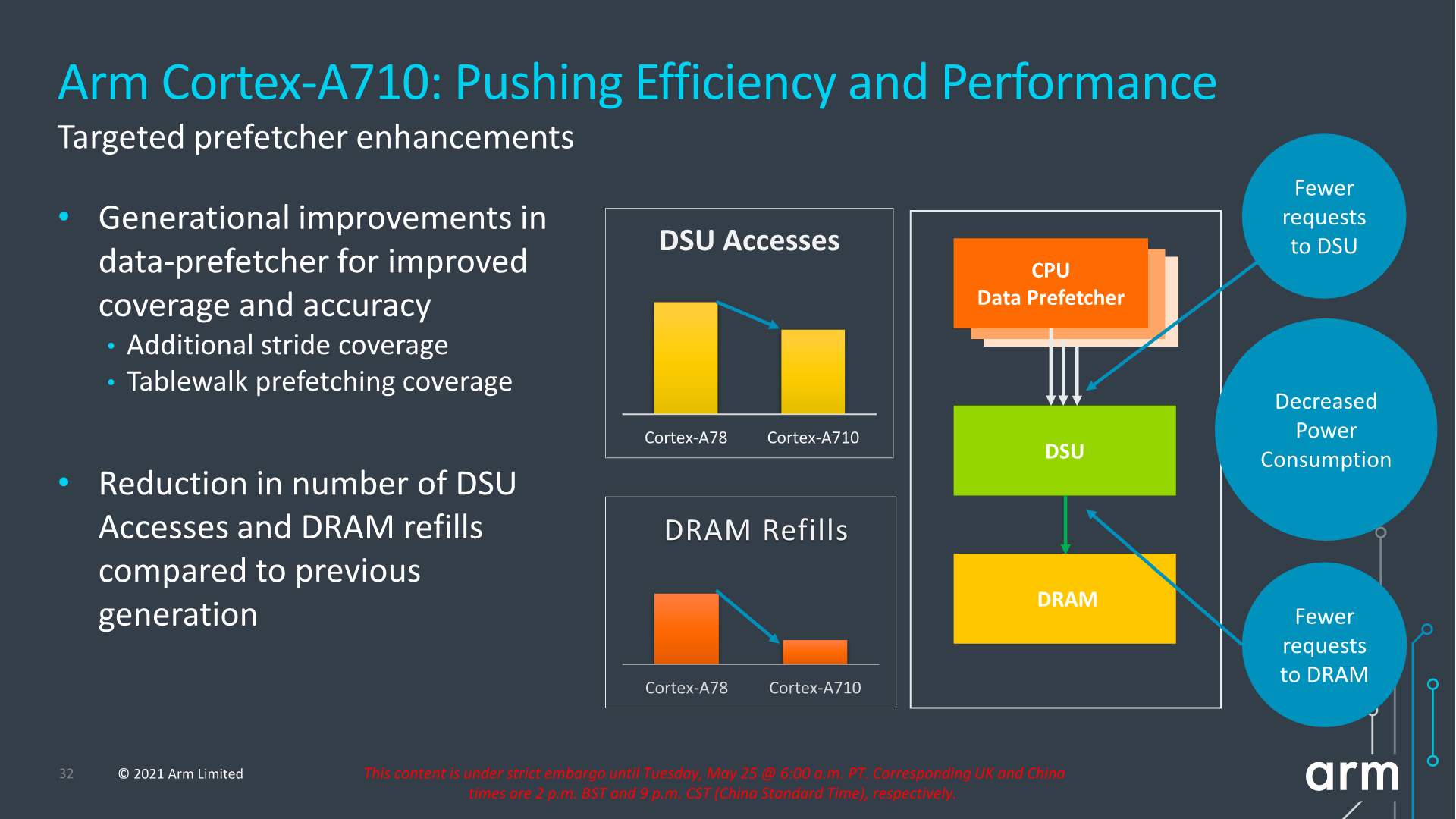
Arm also focuses on core improvements that affect the uncore parts of the system, which take place thanks to the new improvements in the prefetcher designs and how they interact with the new DSU-110 (which we’ll cover later). The new combination of core and DSU are able to reduce access from the core towards the L3 cache, as well as reducing the costly DRAM accesses thanks to the more efficiency prefetchers and larger L3 cache.
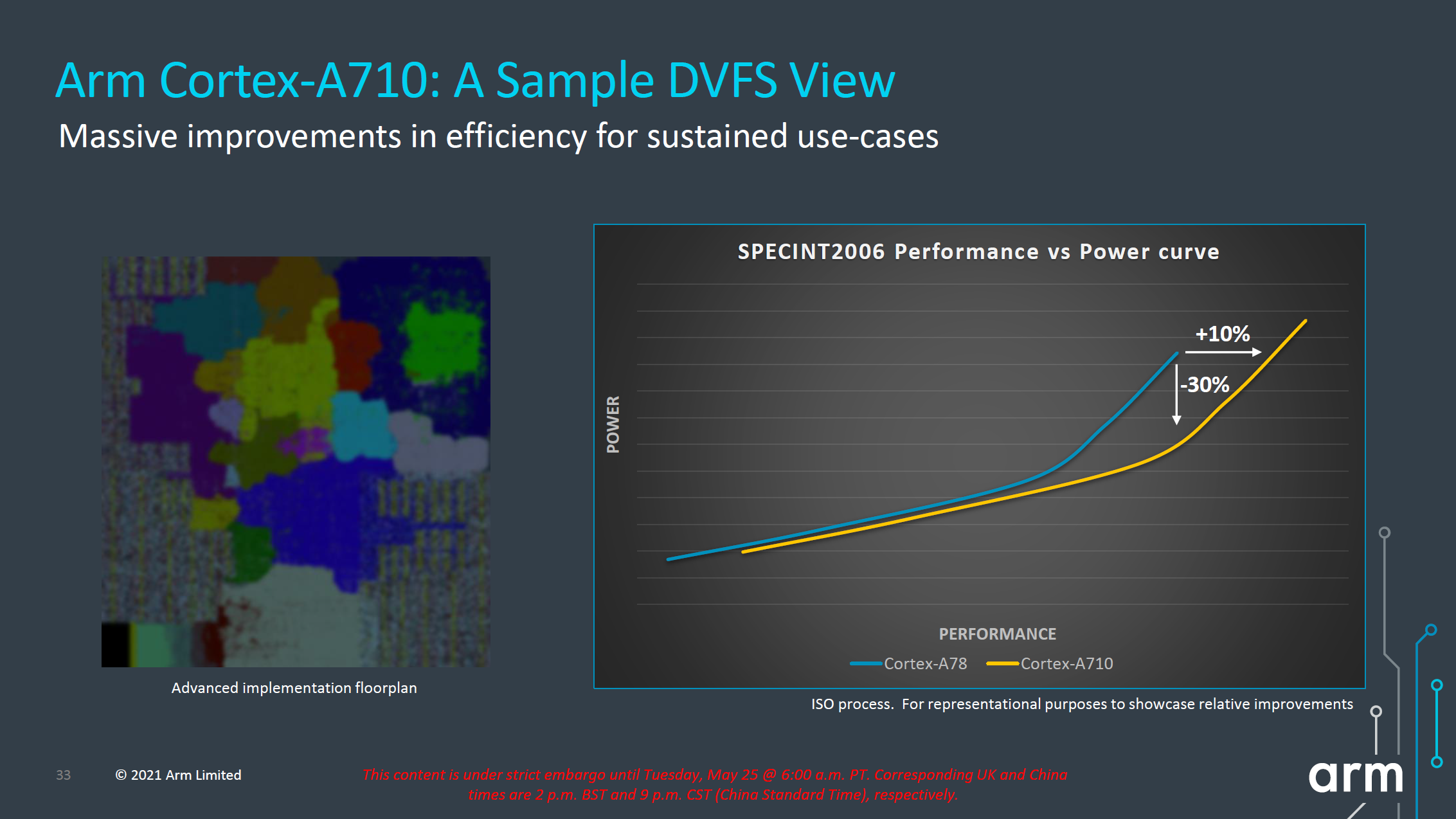
In terms of IPC, Arm advertises +10%, but again the issue with this figure here is that we’re comparing an 8MB L3 cache design to a 4MB L3 cache design. While this is a likely comparison for flagship SoCs next year, because the Cortex-A710 is also a core that would be used in mid-range or lower-end SoCs which might use much smaller L3 caches, it’s unlikely we’ll be seeing such IPC improvements in that sector unless the actual SoCs really do also improve their DSU sizes.
More important than the +10% improvement in performance is that, when backing off slightly in frequency, we can see that the power reduction can be rather large. According to Arm, at iso-performance the A710 consumes up to 30% less power than the Cortex-A78. This is something that would greatly help with sustained performance and power efficiency of more modestly clocked “middle” core implementations of the Cortex-A710.
In general, both the X2 and the A710’s performance and power figures are quite modest, making them the smallest generation-over-generation figures we’ve seen from Arm in quite a few years. Arm explains that due to this generation having made larger architectural changes with the move to Armv9, there has been an impact in regards to the usual efficiency and performance improvements that we’ve seen in prior generations.
Both the X2 and the A710 are also the fourth generation of this Austin microarchitecture family, so we’re hitting a wall of diminishing returns and maturity of the design. A few years ago we were under impression that the Austin family would only go on for three generations before handing things over to a new clean-sheet design from the Sophia team, but that original roadmap has been changed, and now we'll be seeing the new Sophia core with larger leaps in performance being disclosed next year.








181 Comments
View All Comments
mode_13h - Wednesday, May 26, 2021 - link
> Android needs to get their developers to stop using Java and use C/C++/Rust for their apps to eek out the max performance possible.No, I'm sure Google would rather they use Go.
Also, unless you compile your C++ to web asm, it has the disadvantage of leaving out users on newer devices not supported by the NDK version where you built your app. Like RISC V, for instance. Interpreted languages and those that compile into a portable intermediate representation don't have this problem.
> it's a long time nagging issue that I wish the Android community would solve.
Your best hope is that Web Assembly takes over, then.
hlovatt - Thursday, May 27, 2021 - link
> Android needs to get their developers to stop using Java and use C/C++/Rust for their apps to eek out the max performance possible.> Apple's App code base is generally C/C++, that's why they have the performance
Apple code is mainly Objective-C and Swift (neither are particularly fast).
> https://benchmarksgame-team.pages.debian.net/bench...
These benchmarks are largely discredited because they include the start up time in the measurements, which unrealistically hampers virtual machines as used by Java. Its like opening your mailer, typing a couple of characters, and then shutting down your mailer, opening your mailer again, another couple of characters, repeat. Then saying you mailer is slow. Most apps are long running and counting the opening and closing down of the virtual machine for a small task doesn't give useful results.
mode_13h - Wednesday, May 26, 2021 - link
> Apple is in a very very special situation where they control everything. Hardware,> software, product. Plus they use the best process there is at the moment.
> All of this, contributes to their results. Which are very good, but they stem from
> what I told you.
They get a benefit from using the latest process, but that doesn't help them relative to anyone else on that same process node. ARM probably does as much work or more to port their IP to a process node & libraries as Apple does.
They *do* get a benefit from controlling the OS. I'll grant you that. The main thing that can probably help is dialing in clockspeed & thermal management, as well as how load-balancing with the low-power cores is managed.
However, the rest of it is irrelevant for SPEC scores, because the Anandtech team uses the same compilers and the SPEC source is also the same.
> Their cores are not exactly suited for the plethora of android devices that range from 50 bucks to 2000+.
Well, the upper end of that range, yes. That's the biggest thing Apple has in their favor: bigger budgets for bigger cores on newer nodes.
> ARM cpus lose compatibility totally once in a while, which is not something that will work in the long run.
Seems like little-to-no burden for ARMv9 CPUs to retain ARMv8 compatibility, though. When they go to ARMv10, that might be a different story.
> Intel hasn't introduced anything major since 2015!
If Sunny Cove doesn't count as something new, then I think your standards are unrealistic.
BTW, if you want bigger micro-architectural changes, try Gracemont.
Silma - Tuesday, May 25, 2021 - link
Apple & ARM benefit from the best foundries in the world, which has not been the case for Intel for at least 3 years.If Intel catches up in production tech or gets access to the same process than Apple and Co, we'll see who has the better designs for which workloads.
melgross - Tuesday, May 25, 2021 - link
I do think that Intel’s designs are better than AMD designs. They’re not that much s,owner, when they are, and and is on a smaller, faster node. But as far as Apple’s designs, I doubt it. The designs are too different to make that claim. Additionally, and SoC is far more than just CPU cores. That just a fifth of Apple’s SoC.igor velky - Tuesday, May 25, 2021 - link
AMD didnt invent multichip modules, those are lies !IBM had servers with multichip cpus in like 1985ish
Intel Core2 had some cpus which were MCM, too.
ten or so years ago.
mode_13h - Wednesday, May 26, 2021 - link
> Intel Core2 had some cpus which were MCMThe Pentium Pro had its L2 cache on a separate die.
kgardas - Tuesday, May 25, 2021 - link
x86 is dead? Well, it is, welcome amd64.Anyway, I would not consider latest Zen or Sunny Cove/Willow Cove cores as non-competitive even with the latest Apple Mx designs. IMHO they are doing fine. Now, do you know that Alder Lake/Sapphire Rappids will have Golden Cove? And that should arrive this and early next year probably. The core should again provide quite nice bump in IPC. So both ARM and even Apple will have again more than adequate competition. No, neither intel nor amd are dead. Pretty exciting times ahead...
GeoffreyA - Tuesday, May 25, 2021 - link
Oh boy, here we go again. x86, dead. Apple M1, enchanted stuff. Intel/AMD, rubbish for the dump. All hail, Apple!Silver5urfer - Wednesday, May 26, 2021 - link
Logically their tunnel vision has only 2 possible reasonsOne - Apple hardcore fans and somehow their daily tasks and lives rely only on Mac OS or iOS, ignorant on the reality and dumb to believe SPEC and Apple marketing PR.
Two - They hate Intel a lot and also PC platform a lot, have a console probably and a Macbook BGA junk.
I do not know what else and why would anyone hate x86 processors from Intel and AMD, I do not see any point since they are the PCs we can own today and they will last literally for decades. People are using old school Xeon for home server and old school pre SSE4.2, basically Phenom II and Intel Core 2 Quad Q6600 Processors to play damn latest games with community patches for .exes, then we have the latest HW for PC in HEDT and Mainstream for multiple use cases.
Why would anyone hate the only processing standard which has excellent backwards compat full blown parts system for DIY and repair etc, and literally choice of your own OS - Linux, Windows and some Intel HW for Hackintosh. Yep they are dumb and ignorant for sure.