Hot Chips 33 (2021) Schedule Announced: Alder Lake, IBM Z, Sapphire Rapids, Ponte Vecchio
by Dr. Ian Cutress on May 18, 2021 8:00 AM EST
Once a year the promise of super hot potatoes graces the semiconductor world. Hot Chips in 2021 is set to be held virtually for the second successive year, and the presentation schedule has just been announced. Coming this August, there will be deeper disclosures on next-generation processor architectures, infrastructure compute platforms, new enabling technologies such as processing-in-memory, a number of upcoming AI solutions, as well as a deeper look into custom accelerators.
If you thought last year's Hot Chips was a good conference, this one is a strong competitor. Hot Chips is an annual two-day semiconductor disclosure event where the latest processor technology from around the industry (except Apple*, see at the bottom) is presented by the engineers behind the projects. A number of key players use Hot Chips as the first opportunity to promote key details of their designs in the market for potential customers, and startups with enough backing also get to talk about what makes their new chips unique in a crowded market.
A highlight of each event is also the keynotes, with previous years involving Dr. Lisa Su, CEO AMD discussing the companies success, Dr. Phillip Wong of TSMC giving the lay of the land at the leading edge of manufacturing, Jon Masters of Red Hat going through a number of the issues stemming from Spectre and Meltdown, and Raja Koduri covering Intel's vision of a full scalar-vector-matrix-spatial XPU strategy.

TSMC Keynote, Hot Chips 31 (2019)
Normally Hot Chips is an on-location event, but similar to last year due to restrictions on travel it will be an all-virtual event again. This means that most presentations are pre-recorded, but there was a lot of interaction at the event last year. Anyone can attend, and the virtual prices are low, at most $160, which provides the attendee with live presentations, a chance to ask Q&A, access to all the slide decks, and continued access to the talks for several months before they are made public. Last year's online solution went really well.
This year's event will be held August 22-24th, and will run to the Pacific Time Zone. All times below are in PT.
| Hot Chips 33 (2021) Schedule | |||
| AnandTech | Time and Session | Session Title | |
| Day 0 Aug 22nd |
08h30 | Tutorial 1 | ML Performance |
| 14h00 | Tutorial 2 | Advanced Packaging | |
| Day 1 Aug 23rd |
08h45 | Session 1 | Processors |
| 11h30 | Session 2 | Academic Spinout Chips | |
| 12h30 | Keynote | Synopsys | |
| 14h30 | Session 3 | Infrastructure and Data Processors | |
| 16h00 | Keynote | Skydio | |
| 17h30 | Session 4 | Enabling Technologies | |
| Day 2 Aug 24th |
08h30 | Session 1 | ML Inference for the Cloud |
| 10h00 | Keynote | Department of Energy | |
| 11h30 | Session 2 | ML and Computation Platforms | |
| 14h30 | Session 3 | Graphics and Video | |
| 17h00 | Session 4 | New Technologies | |
Here's a quick overview of the Hot Chips 2021 schedule.
Day 0: Tutorial Day
Because Hot Chips caters to both professionals and students, the pseudo-first day of the event is typically a chance for attendees to get to grips with new topics in the industry. Of late these sessions have covered topics such as building scaleout systems, quantum computing, new networking paradigms, and security.
| Hot Chips 33 (2021): Tutorial Day August 22nd, Sunday |
|
| AnandTech | Info |
| 08h30 - 13h00 | Machine Learning Performance |
| Hardware and software co-optimization of the industry-standard MLPerf benchmarks, as well as applications, performance characteristics, key challenges, and considerations for those deploying unique workloads | |
| 14h00 - 17h15 | Advanced Packaging |
| How advanced packaging techniques enable performance and density improvements, covering how current technologies in the market work, how they are used, and the cutting edge of packaging and chip design by the industry leaders | |
The first tutorial here is an expansion of previous talks by MLCommons, the incorporated industry body behind MLPerf. Over the past year we have seen the benchmark reach a full v1.0 with respect to inference, and much in the same way that the industry-standard SPEC benchmarks are optimized to the n-th degree, this session is here to assist with how companies can optimize their hardware and software stack to get the best MLPerf results.

The second tutorial sounds really interesting. Packaging (and interconnect) are the next frontiers of scaled computational resources, with lots of research from the big players already put to use in modern mobile processors to big AI chips. This session is likely to cover TSMC's 3DFabric family of packaging methods, along with associated roadmaps that were disclosed last year, but also Intel's EMIB, Foveros, and ODI packaging. Other companies with advanced packaging products are also likely to get involved in how they use TSMC's and Intel's designs.
Day One: Morning
Day One is going to be very busy, and is split into six sessions, from 8:45 am to 7pm PT.
As with any conference, the opening minutes are spent detailing the conference, what’s new for the year, and some of the rules (such as no streaming). I suspect there will be a large discussion about how the COVID situation will affect the presentations, what to do if one of the presentations fails, or such. I actually hope that the presentations are pre-recorded so that doesn’t happen.
The first session is on Processors.
| Hot Chips 33 (2021): Day One, Session 1 Server Processors |
|||
| AnandTech | Speaker | Company | Info |
| 08h45 | Opening Remarks | ||
| 09h00 | Efraim Rotem | Intel | Intel Alder Lake CPU Architectures |
| 09h30 | Mark Evers | AMD | AMD Next Generation Zen 3 Core |
| 10h00 | Christian Jacobi | IBM | The > 5 GHz next-generation IBM Z processor chip |
| 10h30 | Arijit Biswas | Intel | Next-Generation Intel Xeon CPU Sapphire Rapids |
| Sailesh Kottapalli | |||
The first official day of presentations always starts with discussing leading-edge processors, and this year looks to be a stellar set of talks.
First up is Intel discussing Alder Lake, its second-generation heterogeneous processor architecture (after Lakefield) that is set to be the next-generation processor for both desktops and high-end laptops. We already know that Alder Lake will use both Golden Cove and Gracemont microarchitectures, to the hope here is that Intel will spend time going deep into both. Normally this is the sort of thing they would have disclosed over several hours at an Intel-specific event, and given 30 minutes for the talk I wonder how much will actually be disclosed - it might instead be a talk solely about the SoC and we won't get microarchitecture detail at all.

Second is an AMD talk about its latest Zen 3 core microarchitecture. As Zen 3 was launched into the market in Q4 last year, with an updated back-end and unified L3 cache structure, I doubt we will see anything new in this talk. The hardware has been thoroughly tested; AMD typically uses Hot Chips to refresh what's already out in the market, and there's an RDNA2 talk on the second day which is expected to be of a similar nature.
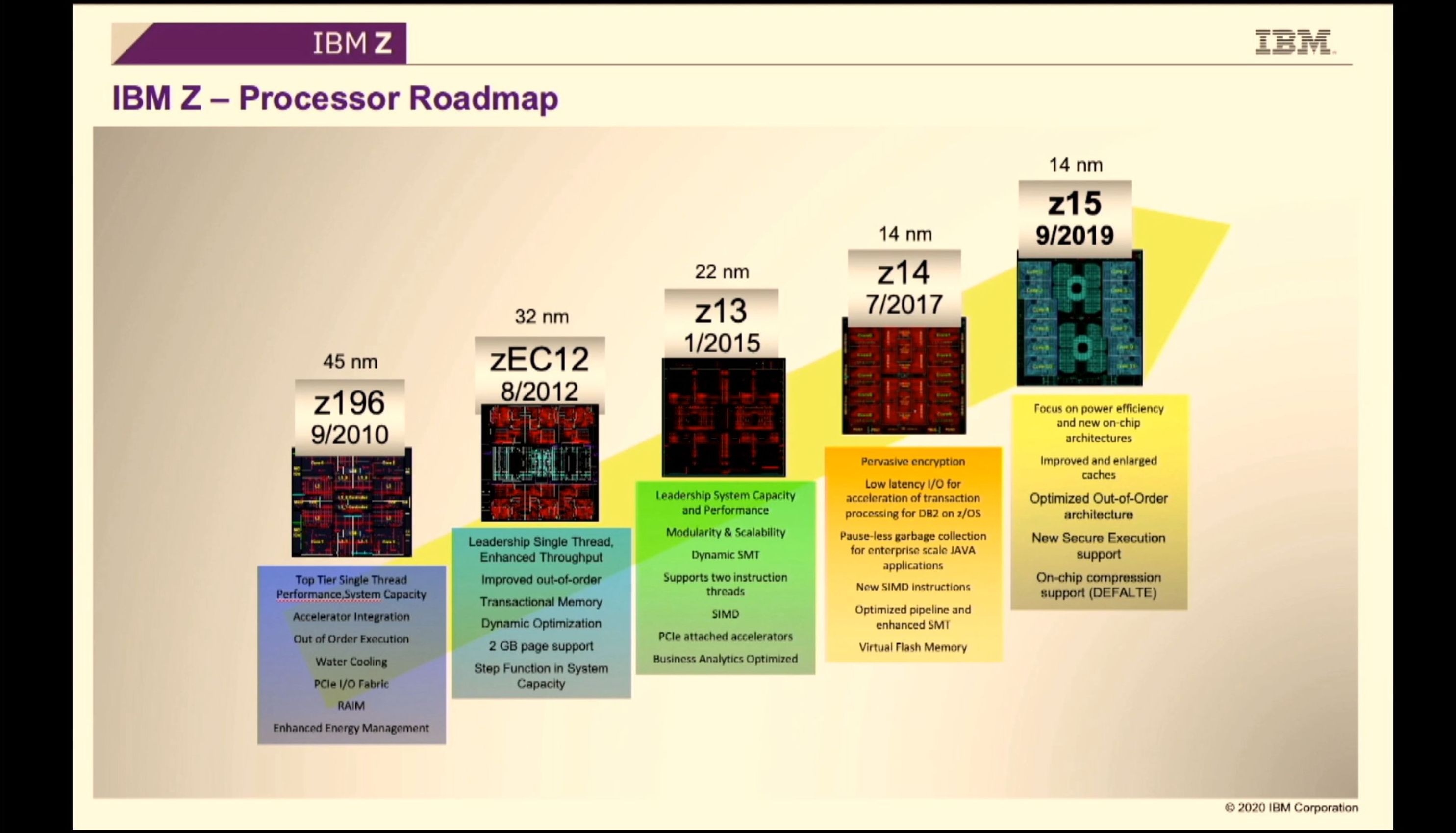
Third is IBM discussing its next-generation mainframe architecture and product line, the Z processor. We've covered IBM discussing z14 and z15 in previous Hot Chips events, and so this is either a deeper dive into z15 (which was presented last year in lots of detail) or a new look at an upcoming z16 design. The Z mainframe solution usually consists of compute processors and control/cache processors across a unified multi-rack approach - because this talk is titled 'processor chip', I suspect it is more about the compute processor than the solution, but hopefully there will be a slide or two on how it all fits together.

The final talk of the session is another Intel talk, this time discussing the upcoming next-generation Sapphire Rapids platform, set to launch either sometime at the end of this year or early next year (Intel has a contract with DoE for the Aurora supercomputer it needs to fill by the end of the year with this part, so general availability might be after). Sapphire Rapids is using Intel's 10nm Enhanced SuperFin process, and the same Golden Cove cores mentioned in Alder Lake, though perhaps cache optimized for server use. I suspect this talk will be heavy on the die configuration and new elements, such as PCIe 5.0 and DDR5.
After a short break, we get to the Academic section.
| Hot Chips 33 (2021): Day One, Session 2 Academic Spinout Chips |
|||
| AnandTech | Speaker | Company | Info |
| 11h30 | Karu Sankaralingam | University of Wisconsin-Madison | Mozart, Designing for Software Maturity and the Next Paradigm for Chip Architectures |
| 12h00 | Todd Austin | University of Michigan | Morpheus II: A RISC-V Security Extension for Protecting Vulnerable Software and Hardware |
It's not often we pay too much attention here given the research nature of the devices, however the second talk on a RISC-V security extension is rather interesting. Coming from the University of Michigan, the Morpheus II core has been reported as being the target for 500+ cybersecurity researchers for 3 months as part of the DARPA red-teaming challenge, and had zero penetrations in that time.
Day One: Keynote One
| 12h30 | Aart de Geus | Synopsys | Synopsys Keynote |
This year is a little different to most, with the first day having two separate keynotes. First up is an untitled presentation from the CEO of Synopsys, a company well known in the industry for its EDA (electronic design automation) tools. This includes logic synthesis, place and route, static timing analysis, hardware language simulators, and transistor-level circuit simulation. This talk should give the company a chance to discuss its next-generation technologies, especially as we move into an era of 3D design and packaging.
When we get the full title of the talk, this segment will be updated.
Day One: Afternoon
After lunch the next series of talks are on non-standard processor designs, typically optimized for infrastructure or data processing.
| Hot Chips 33 (2021): Day One, Session 3 Infrastructure and Data Processors |
|||
| AnandTech | Speaker | Company | Info |
| 14h30 | Andrea Pellegrini | Arm | Arm Neoverse N2: Arm's second-generation high-performance infrastructure CPUs and system products |
| 15h00 | Idan Burstein | NVIDIA | NVIDIA Data Center Processing Unit (DPU) Architecture |
| 15h30 | Bradley Burres | Intel | Intel's Hyperscale-Ready Smart-NIC for Infrastructure Processing |
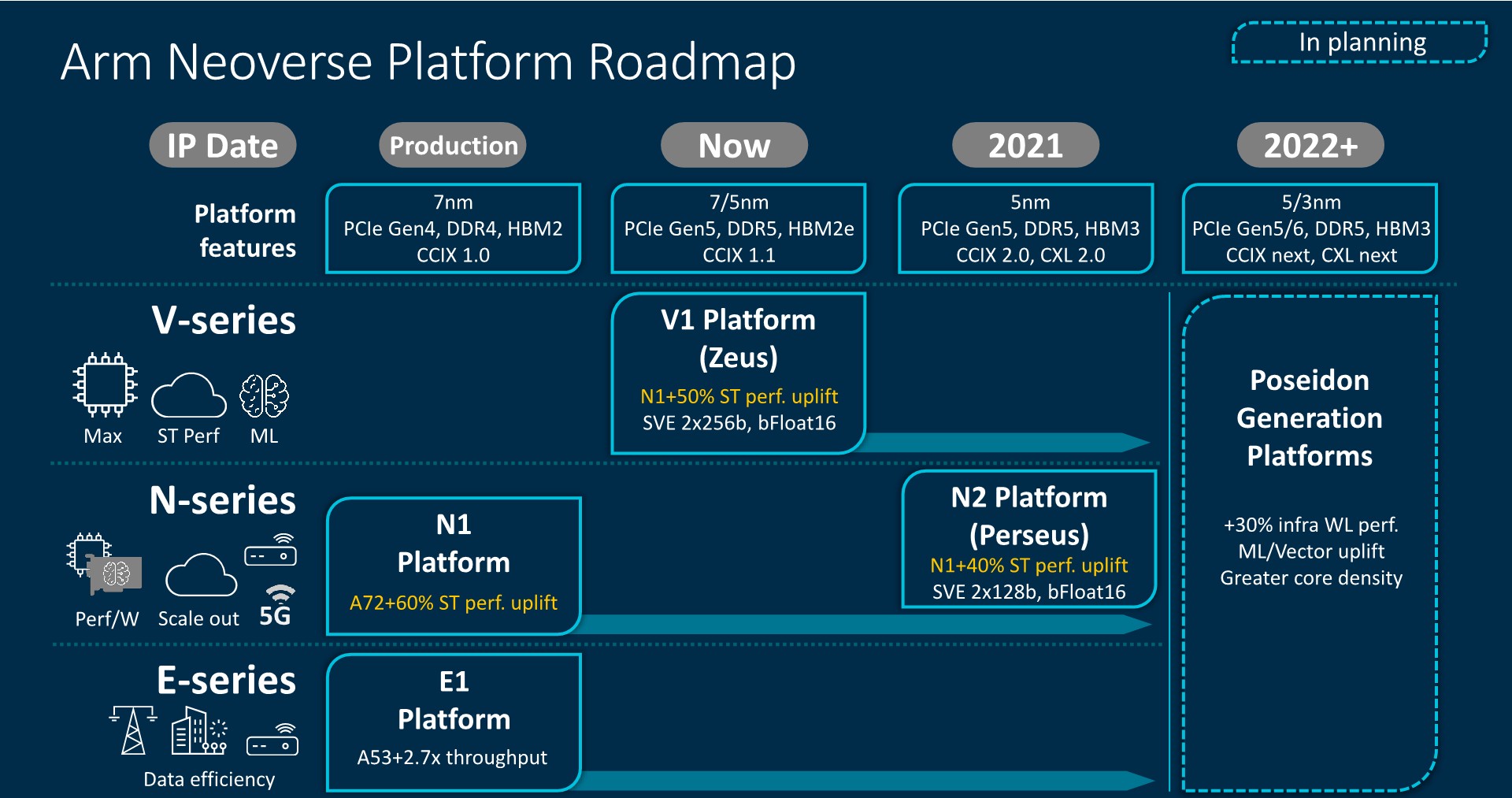
The first talk is regarding Arm's Neoverse N2 core, the upgraded model of the N1, which was announced in late April. N2 products aren't due out until next year, however companies working with N2 are likely already designing their SoCs with the core. Arm didn't disclose many of the pipeline details in the April announcement, and so we might see more information along these lines, however there is the potential for it to just be the same announcement as April. We shall wait and see.
The second talk from NVIDIA is about its Data Processor Unit architecture, also known as Bluefield. Coming from its acquisition of Mellanox, the Bluefield line of DPUs enables Smart-NIC like network acceleration by integrating a network controller, general-purpose compute cores, and PCIe connectivity into the same device. The latest product is Bluefield-2, however murmurings of Bluefield-3 have been made as to the future roadmap replacement. The title of the talk does not specifically state NVIDIA will talk about current generation architectures or next generation.

Third up is the Intel SmartNIC solution which has been announced previously as the C5000X platform. A number of Intel's customers and OEM partners, are already shipping the hardware, based on Intel Altera FPGAs, to key customers such as Baidu. Partners such as Silicom are selling the parts under their own brand. There hasn't been much presentational material about the architecture of the SmartNIC, so this might be an interesting insight into one of Intel's new market pushes.
Day One: Keynote Two
In an interesting turn of events, the first day of Hot Chips has two keynotes.
| 16h00 | Abraham Bachrach | Skydio | Skydio Autonomy Engine: Enabling the Next Generation of Autonomous Flight |
The second keynote of the day comes from Skydio, a company I had not heard of before the announcement, but appears to be on the leading edge of AI-based pilot technology. The Skydio 2 platform for example seems to be powered by an NVIDIA Tegra TX2, and the concept of autonomous flight / drone technology has always been on the cusp in the evolution on AI. Skydio looks set to talk about its next-generation platform, given that its Skydio 2 was released in 2019 and since then it has had another round of VC funding.
Day One: Even More Talks
To end the first day, Hot Chips will discuss future technologies. After a long day, I do wonder why they don't extend Hot Chips out into a third day of talks - normally at this point I am truly on information overload. Out of the three talks in this session, the one I'm most familiar with is the final one, by Samsung, about its compute-in-memory solution.
| Hot Chips 33 (2021): Day One, Session 4 Enabling Technologies |
|||
| AnandTech | Speaker | Company | Info |
| 17h30 | Ramanujan Venkatadri | Infineon | Heterogeneous computing to enable the highest level of safety in automotive systems |
| 18h00 | Sriram Rajagopal | EdgeQ | Architecting an Open RISC-V 5G and AI SoC for Next Generation 5G Open Radio Acess Network |
| 18h30 | Jin Hyun Kim | Samsung | Aquabolt-XL: Samsung HBM2-PIM with in-memory processing for machine learning accelerators |
The Aquabolt-XL was unveiled earlier this year, with Samsung able to add compute cores per memory bank into its HBM2 memory without any hardware modifications on the host side. Aquabolt-XL works by sending commands to specific memory addresses and can perform simple compute tasks on its in-order cores on the data within that memory bank. The idea is that energy will be saved by not having to move data from memory to the core for the simplest operations. At the time, I asked Samsung if this requires extra power, as other compute-in-memory solutions, and Samsung said no - this is very much a simple drop-in replacement for any HBM2 solution today, and requires software modification for use.

Day Two: Morning
The second day starts early, at 8:30am, and runs until 7pm. The first session starts with discussing Machine Learning inference processors from some of the big companies looking for cloud deployment.
| Hot Chips 33 (2021): Day Two, Session 1 ML Inference for the Cloud |
|||
| AnandTech | Speaker | Company | Info |
| 08h30 | David Ditzel | Esperanto Technologies | Accelerating ML Recommendation with over a Thousand RISC-V Tensor Processors on Esperanto's ET-SoC-1 Chip |
| 09h00 | Ryan Liu | Enflame Technology | AI Compute Chip from Enflame |
| Chuang Feng | |||
| 09h30 | Karam Catha | Qualcomm | Qualcomm Cloud AI 100: 12 TOPs/W Scalable, High Performance and Low Latency Deep Learning Accelerator |
The first talk in this session is from Esperanto, a startup with $58m+ in funding to create recommendation engine processors for the could. All the major hyperscalers and retailers use recommendation engines - showing users what product would most interest them at any given time. Esperanto's solution seems to be a 1000-core RISC-V solution, with combined tensor cores for inference acceleration. This talk should be the first disclosure of the chip and the architecture underneath.
Second is another AI semiconductor startup, this time from China with a large backing from Tencent. The last funding round in January this year was for some $279m+ in Series C, although exactly what Enflame is producing hasn't been announced.
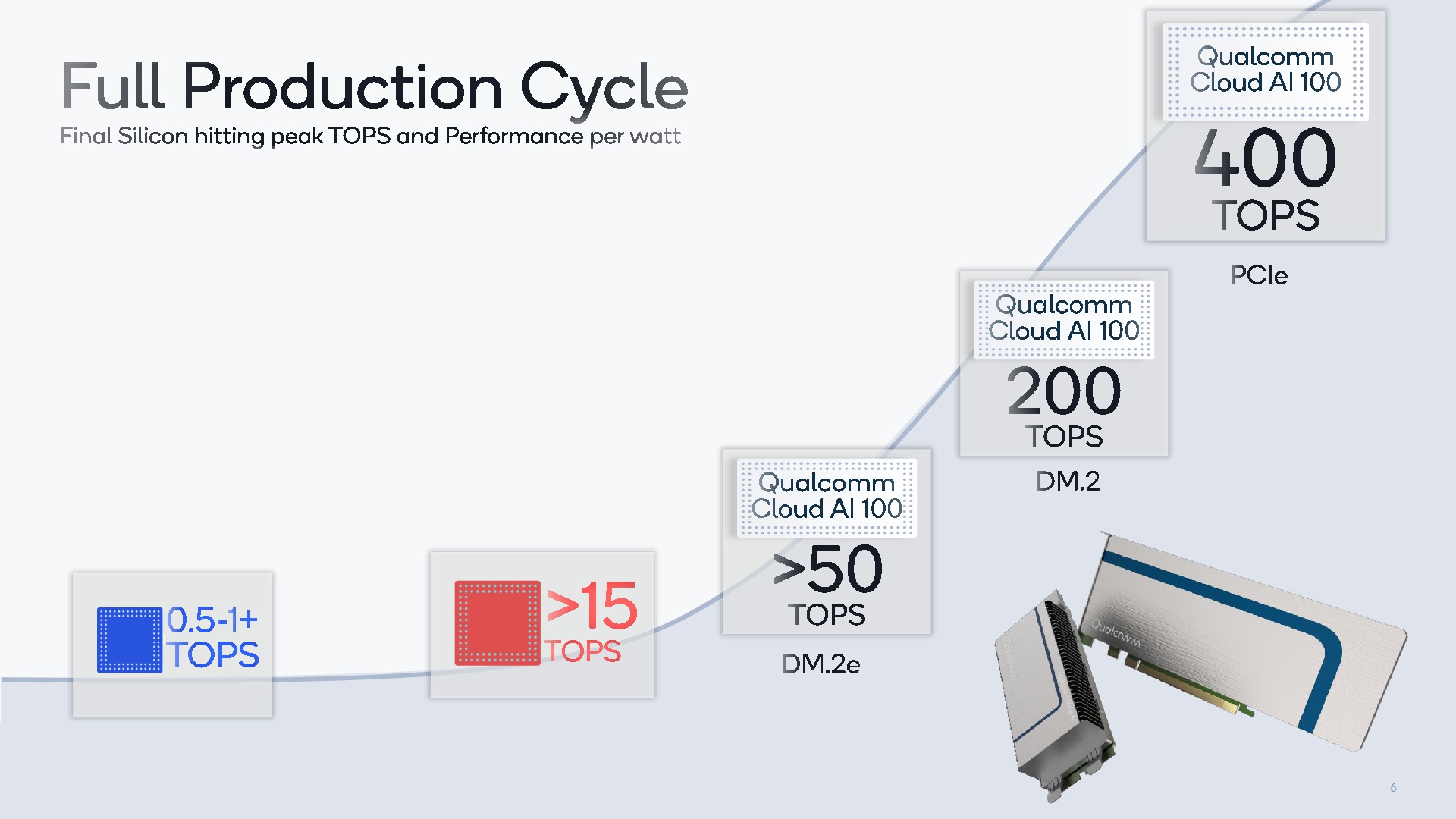
Qualcomm's AI 100 solution is third, a product that was announced just after Hot Chips last year. This AI inference processor is the top version of a range of AI inference hardware built on the same architecture underneath. The Qualcomm Cloud AI 100 has a reported speed of 400 TOPs for 75 W, although the most efficient version is aiming for 12 TOPs per Watt. I expect this talk to go into the architecture details of the processor family.
Day Two: Keynote
The second day only gets a single keynote earlier than usual, but this one should be interesting as it is from the US Department of Energy.
| 10h00 | Dimitri Kusnezov | DoE | DoE AI and Technology |
In this instance, the Deputy Under Secretary for AI and Technology will present an unnamed talk, which could cover a number of talks from the use of AI in current DoE deployed systems, or the DoE approach to adopting AI at scale, in both training and inference. A number of companies at this event have contracts with the DoE in some form, making it an interesting talk from our point of view.
Day Two: Home Stretch
Continuing the machine learning theme, the second session of the day before lunch is about bigger AI chips built more for training, as well as a special surprise.
| Hot Chips 33 (2021): Day Two, Session 2 ML and Computation Platforms |
|||
| AnandTech | Speaker | Company | Info |
| 11h30 | Simon Knowles | Graphcore | Graphcore Colossus Mk2 IPU |
| 12h00 | Sean Lie | Cerebras Systems | The Multi-Million Core, Multi-Wafer AI Cluster |
| 12h30 | Raghu Prabhakar | SambaNova Systems Inc | SambaNova SN10 RDU: Accelerating Software 2.0 with Dataflow |
| Sumti Jairath | |||
| 13h00 | J. Adam Butts | D.E. Shaw Research | The Anton 3 ASIC: a Fire-Breathing Monster for Molecular Dynamics Simulations |
| David E. Shaw | |||
The first talk is from Graphcore, talking about its Mk2 IPU product family. Graphcore has been talking about the Mk2 IPU deployment for over a year, including its four-IPU single server 1U solution all the way up to an IPU Pod and beyond. This talk seems to be a recap of the underlying architecture just at a different event, although fingers crossed we see something about a roadmap here as well.

The second talk is Cerebras Systems with its second-generation Wafer Scale Engine - a CPU the size of your head with 850,000 cores, and one wafer becomes one chip. Having announced WSE-2 at the beginning of the year, one of the highlights of those presentations was using multiple WSE-2 systems in the same rack to scale out the solution. That seems to be the focus of this talk.

Third is SambaNova, one of the AI companies that has recently announced hundreds of millions in their latest rounds of funding. The Cardinal AI solution from SambaNova is targeting AI training, and scaling across many systems in a reconfigurable gate array architecture, very similar to that of an FPGA but geared towards AI. SambaNova has presented its architecture at a few select conferences, however this will be the first time I've seen a talk on the topic.

Finally we have the surprise talk of the event, at least from my perspective. Here's a question - what do you do if there isn't any hardware on the market to solve your problem? Simple, build your own! The Anton 3 ASIC is next-generation dedicated hardware for molecular dynamics for all those molecular modeling problems that take too long to complete on conventional hardware. The story behind how the Anton 3 came into being seems fascinating from my short research, so I hope it becomes a part of the talk. The Anton 2 chip was presented at Hot Chips 26, in 2014, before I started covering the event.

After another lunch, the next session will excite a number of users, as they breach the topic of graphics disclosures. It looks like we're going to get a couple of good ones this year, despite the current state of the graphics market.
| Hot Chips 33 (2021): Day Two, Session 3 Graphics and Video |
|||
| AnandTech | Speaker | Company | Info |
| 14h30 | David Blythe | Intel | Intel's Ponte Vecchio GPU Architecture |
| 15h00 | Andrew Pomianowski | AMD | AMD RDNA 2 Graphics Architecture |
| 15h30 | Aki Kuusela | Google's Video Coding Unit (VCU) Accelerator | |
| Clint Smullen | |||
| 16h00 | Juanjo Noguera | Xilinx | Xilinx 7nm Edge Processors |
First up is Intel discussing its Xe-HPC architecture, or rather specifically its Ponte Vecchio HPC chip that uses 47 tiles from multiple process nodes on a single substrate. Ponte Vecchio was initially designed for the Aurora Exascale Supercomputer project, and will be partnered with Sapphire Rapids. As the chip is due to be shipped to production systems later this year, an expose on the architecture is widely welcomed.

The second talk will be AMD recapping its RDNA2 architecture, which is now at the heart of many of its graphics products.
The third talk is one that interests me comes from Google - as with all things at Youtube, it has to be done at scale, and making sure that every video on the platform is available at multiple resolutions requires a lot of computational resources. To help speed that up, Google built its own video co-processor, and through 2021 has been disclosing bits of how it works. Currently, the VCU only caters for a couple of the most regular codecs, but hopefully we will get an insight into what future versions might bring with AV1 and newer codecs.

Finally for this session, Xilinx will talk about its 7nm processor designs for the edge which it announced earlier this year.
The final session of the event is filed under 'New Technologies'. Everything here isn't strictly to do with processors, but certainly involves Hot Chips.
| Hot Chips 33 (2021): Day Two, Session 4 New Technologies |
|||
| AnandTech | Speaker | Company | Info |
| 17h00 | Michael Wiemer | Mojo Vision | Mojo Lens - AR Contact Lenses for Real People |
| Ranaldi Winoto | |||
| 17h30 | Sukki Yoon | Samsung | World's Largest Mobile Image Sensor with All Directional Phase Detection and Auto Focus Function |
| 18h00 | Hidekuni Takao | Kagawa University | New Value Creation by Nano-Tactile Sensor Chip Exceeding our Fingertip Discrimination Ability |
| 18h30 | Christopher Monroe | IonQ Inc | The IonQ Trapped Ion Quantum Computer Architecture |
*A good number of engineers from Apple attend the event every year, and ask a lot of questions, however they have never presented a talk. These events are often a collaborative industry disclosure mechanism, and gives a chance for companies to present their best technology as well as quiz their competitors. Apple's engineers are happy to ask lots of questions, but so far they have never had a talk good enough to be presented (I'm pretty sure they've never submitted a talk) or sponsored the event in any capacity.








32 Comments
View All Comments
deltaFx2 - Wednesday, May 19, 2021 - link
While I think WARF is a patent troll (produces no products), whether Moshovos imagined the specific use of it or not is irrelevant. They patented store-sets using PC hashing as a way of disambiguating them (I believe). If you use that mechanism, whatever additional metadata you store to get goodness on top of it becomes irrelevant. You're using the mechanism, pay up.I think the IBM paper I linked is a pretty solid argument against vapidity. You're probably looking in the wrong places. Perhaps such papers exist from apple and I'm not aware of them? (unlikely, but there's a non-zero chance of everything)
SIDtech - Wednesday, May 19, 2021 - link
I remember you from Realworldtech forums. Haven't seen you post there in a whiledeltaFx2 - Wednesday, May 19, 2021 - link
Have you ever seen a research paper authored by apple employees in any conference? Never happens. Attend ISCA etc and you'll find several apple employees, but I've never seen one presentation to date from them. PhD students once hired by apple are not permitted to present research work done during their PhD under the pretext of divulging apple's secrets. You can google Yan Le Cun's critique of apple and its lack of success in AI (at the time). His critique was that apple is great at taking other people's ideas and mature technologies and polishing/packaging it to an unprecedented level, but doesn't come up with original ideas. I think this is still true.Patents don't count as publications, btw. They're designed to be as broad and obfuscating as possible.
There's levels of openness. There's apple, which likely implements TAGE, and tons of other algorithms invented in academia but gives nothing in return. Intel research does publish good ideas, many of which become products years down the line. IBM papers have far more detail than what you might expect out of a company. Take this as an example: https://conferences.computer.org/isca/pdfs/ISCA202... but there are several. I recall an AMD paper detailing their uop-cache organization. Apple won't even tell you their ROB size.
Intel, AMD, and IBM reveal at least enough information that someone writing hand-tuned software knows about bottlenecks and how to get around them. Intel's software optimization guide is full of such info. Haven't looked at AMD's much. Your particular interest might not be covered, but most reasonable cases (scheduler organization, branches per cacheline/16b, loop streaming buffer sizes etc) are publicly stated. Do we know apple's rob size from Apple itself?
Samsung vs. apple is a red herring argument. That was about a UI "look and feel" not hardware. Apple and Intel had to pay WARF (Univ of Wisconsin)for their memory disambiguation patent infringement, a sign that hard IP is protected. Even if an array of rounded-cornered squares is not patentable.
name99 - Wednesday, May 19, 2021 - link
You do know that Apple DIDN'T pay WARF, right? They were found non-infringing.https://www.reuters.com/article/us-usa-court-apple...
(As you would have learned if you had read the Apple patents. But of course you don't do that, do you? Complain about how Apple never tells the world anything -- but don't bother to consult one fairly rich source of ground truth.)
This is my point. The internet has created a pool of very loud people Dunning-Kruger's who don't even know how little they know -- but are very certain about how and why they are right and everyone else is wrong.
deltaFx2 - Wednesday, May 19, 2021 - link
And this supports the claim that apple does not add knowledge/value to the larger cpu design community? Exactly how does that logic follow?But sure, classic internet troll behavior of fixating on one inconsequential point to conveniently shift the conversation to how right you were. Show me papers published by apple in hardware. Start with One. I linked an ibm paper, told you where to find others. But no, your response is that I haven’t kept up with some courtroom relitigation. Congrats! And kudos on knowing about denning kruger.
deltaFx2 - Wednesday, May 19, 2021 - link
As to patents, a) patents make broad claims for winning lawsuits. Implementation may or may not be exactly as specified in them and b) your company lawyer will advise against reading patents as it may be used against youJon Tseng - Tuesday, May 18, 2021 - link
D'ya reckon they'll be tortilla chip care packs again this year?? :-pname99 - Tuesday, May 18, 2021 - link
Are these PIM solutions (and the flash equivalent, where you do the processing in the flash drive) actually being used?Obviously they're not being used by Apple or in your basic Wintel laptop, but are they being used by cloud providers, or HPC or universities or anywhere?
For 20 years this ideas has been pushed academically, and for maybe ten years I've been seeing "product-like" announcements. But never any reference to these things in the wild.
I am well aware that I don't know the full range of computing. Hence this question. Not snark, just a genuine curiosity as to whether/when/if these things will exit the lab.
eastcoast_pete - Tuesday, May 18, 2021 - link
Should be an exciting conference! One comment about the sponsorship levels, which currently top out at "Rhodium"; they should have added an "Unobtainium" level above that, would be very a propos the current shortages and prices.jospoortvliet - Wednesday, May 19, 2021 - link
Ha and then not actually offer that level to anyone ;-)