Arm Announces Neoverse V1, N2 Platforms & CPUs, CMN-700 Mesh: More Performance, More Cores, More Flexibility
by Andrei Frumusanu on April 27, 2021 9:00 AM EST- Posted in
- CPUs
- Arm
- Servers
- Infrastructure
- Neoverse N1
- Neoverse V1
- Neoverse N2
- CMN-700
The Neoverse V1 Microarchitecture: X1 with SVE?
Starting off with the new Neoverse V1, the design is both of a familiar origin, but also has a few distinct features that we see for the first time ever in an Arm CPU. As noted in the introduction, the V1 was designed at the same time as the Cortex-X1 by the same team at Arm’s Austin design centre, with large similarities between the two microarchitectures when it comes to the block structures.
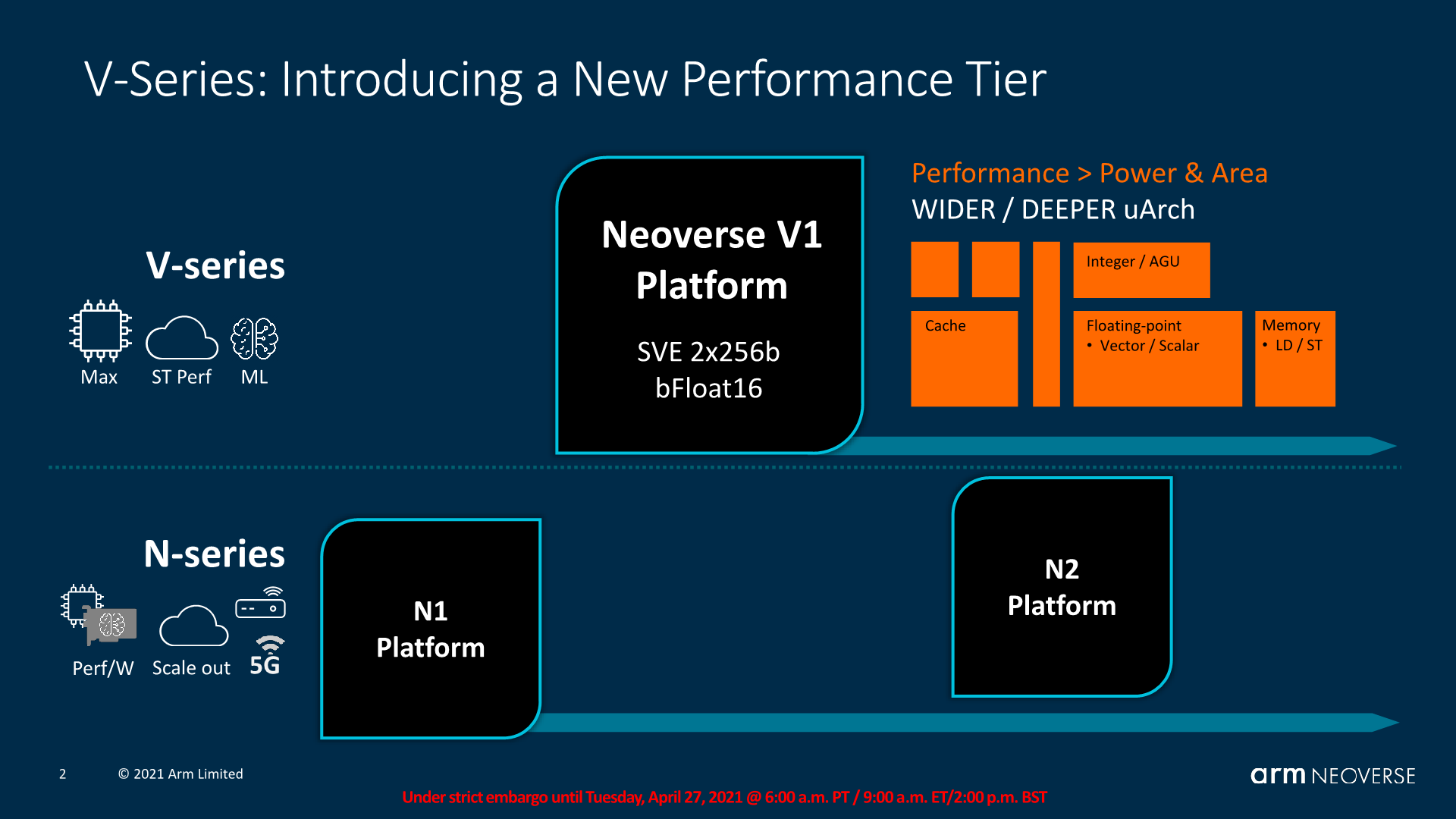

What’s notable about the V1, in comparison to the X1 and of course the predecessor N1, is the fact that this is now an SVE capable processor, with two native 256b SIMD pipelines, and also introducing server-only features such as coherent L1I caches, bFloat16 execution capabilities, and a slew of distinct characteristics we’ll cover in just a bit.
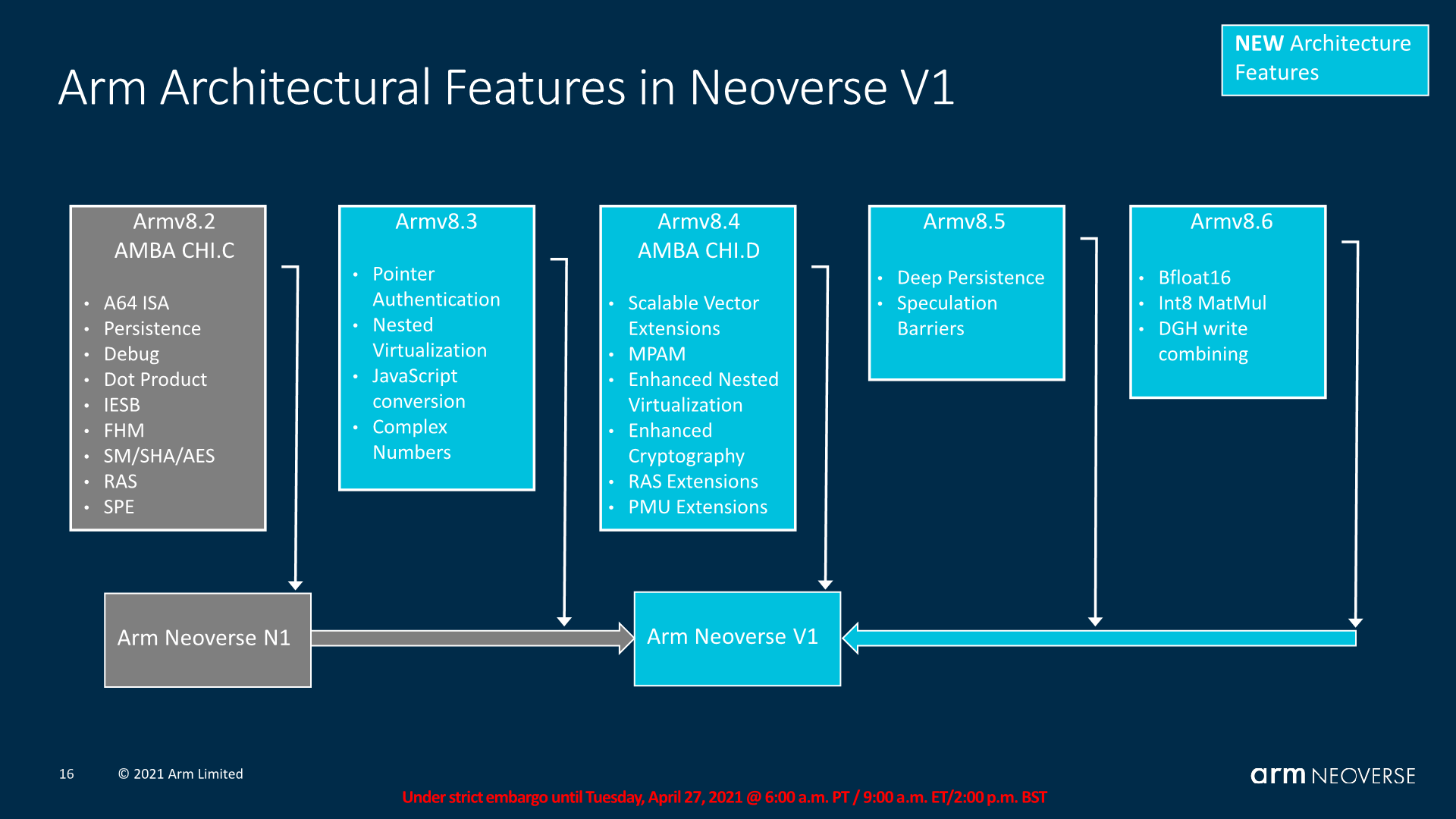
The architectural features of the Neoverse V1 are probably the most complicated in terms of describing – essentially, it’s a v8.4 baseline architecture which also pulls v8.5 and v8.6 features in for the HPC oriented workloads the design is aimed for. Given that we talked about Armv9 only a month ago, this may seem a bit odd, but again we have to remember that the V1 has been designed some time ago and that customers have had the IP for quite a while now, taping in or having already taped out V1 processors.
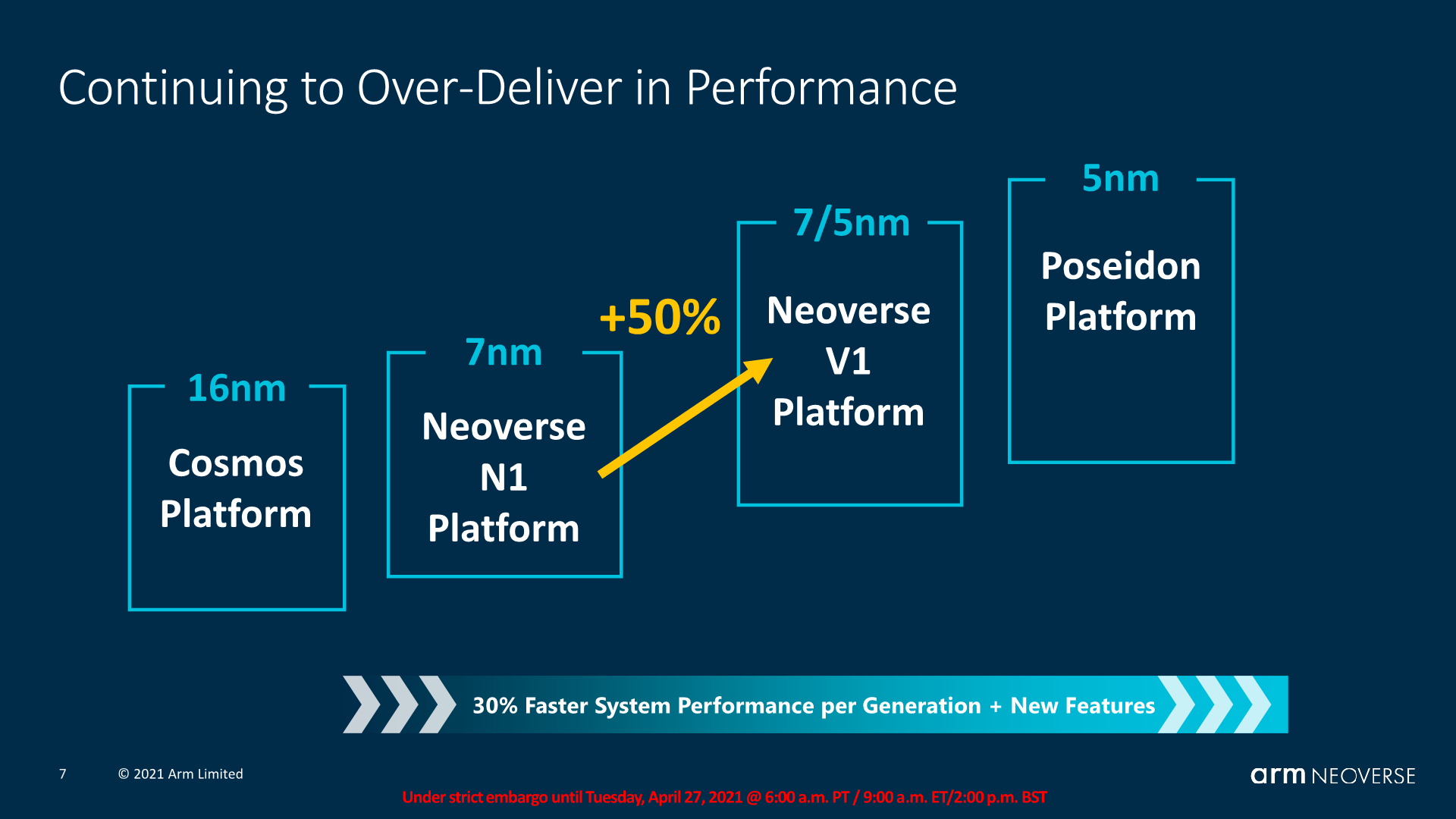
The big promise of the V1 is its extremely large performance jump over the N1, coming in at an IPC increase of +50%. This sounds large, and it is, but it’s also not all that surprising given that the microarchitecture essentially is 2 microarchitecture design generations newer than the N1, even through from a infrastructure product standpoint it’s only one generation newer.

From a high-level pipeline standpoint and microarchitecture view, the Neoverse V1 is very similar to the X1. It’s still an extremely short pipeline design that has a minimum of 11 stages, with Arm putting a lot of focus on this aspect of their microarchitectures to reduce branch misprediction penalties as much as possible. This aspect of the microarchitecture has remained relatively static over the last few iterations of the Austin family of designs starting with the A76, so Arm notes that the frequency capabilities of the V1 is essentially unchanged when compared to the N1, with performance boosts coming solely from increased IPC.

The V1 sees a lot of the front-end improvements we’ve seen with the Cortex-A77 and Cortex-X1 generations, which saw larger front-end branch improvements such as a doubled up bandwidth for the decoupled fetch unit, much larger L2 BTB to up to 8K entries, and a rearranging and resizing of the lower level BTBs, with the L0 (nanoBTB) growing to 96 entries, and the L1 BTB (microBTB) no longer being present when compared to the Neoverse N1.

The V1 one when compared to the N1 also adds in new structures that hadn’t been present in the design, such as the introduction of a macro-Op cache of up to 3K decoded instructions. The dispatch bandwidth from the Mop cache is 8-wide, while the actual instruction decoder this generation is 5-wide, much the same as on the X1.
The out-of-order windows size is essentially doubled when compared to the Neoverse N1, with the ROB growing to 256 entries. This is actually a tad larger than what Arm was willing to disclose for the Cortex-X1 where the company had only talked about a “OoO window size of 224”, so in this regard this seems to be a differentiation to what we’ve seen in the X1.
On the back-end integer execution pipelines, the design also pulls in the many changes we’ve seen with the A77 generations, which amongst others include a doubling of the branch execution ports, and a new complex ALU capable of simple instructions such as additions as well as more complex operations such as multiplications and divisions.

Obviously enough, the new SIMD pipelines are very different on the V1 given that this is Arm’s first ever SVE capable microarchitecture. The design has two pipelines with seemingly two dedicated schedulers, with native capability for 256b wide SVE vectors. The design is fully backwards compatible for 128b NEON/FP operations in which the pipelines then essentially act as 4x128b units, meaning it has the same execution width as the X1 in that regard.
Compared to the N1, the new design also supports new bFloat16 and Int8 data formats which greatly increase the AI and ML inferencing performance capabilities of the core.

On the memory subsystem side, we also see the increased unit count found on the Cortex-X1, including 2 load/store units and one load unit, meaning the core is capable of up to 3 loads per cycle and 2 stores per cycle maximum. SVE vector bandwidth is 2x32B per cycle for loads, and 32B per cycle for stores.
The core naturally includes the data parallelism improvements seen on the X1 in order to increase MLP (Memory-level parallelism) capabilities.
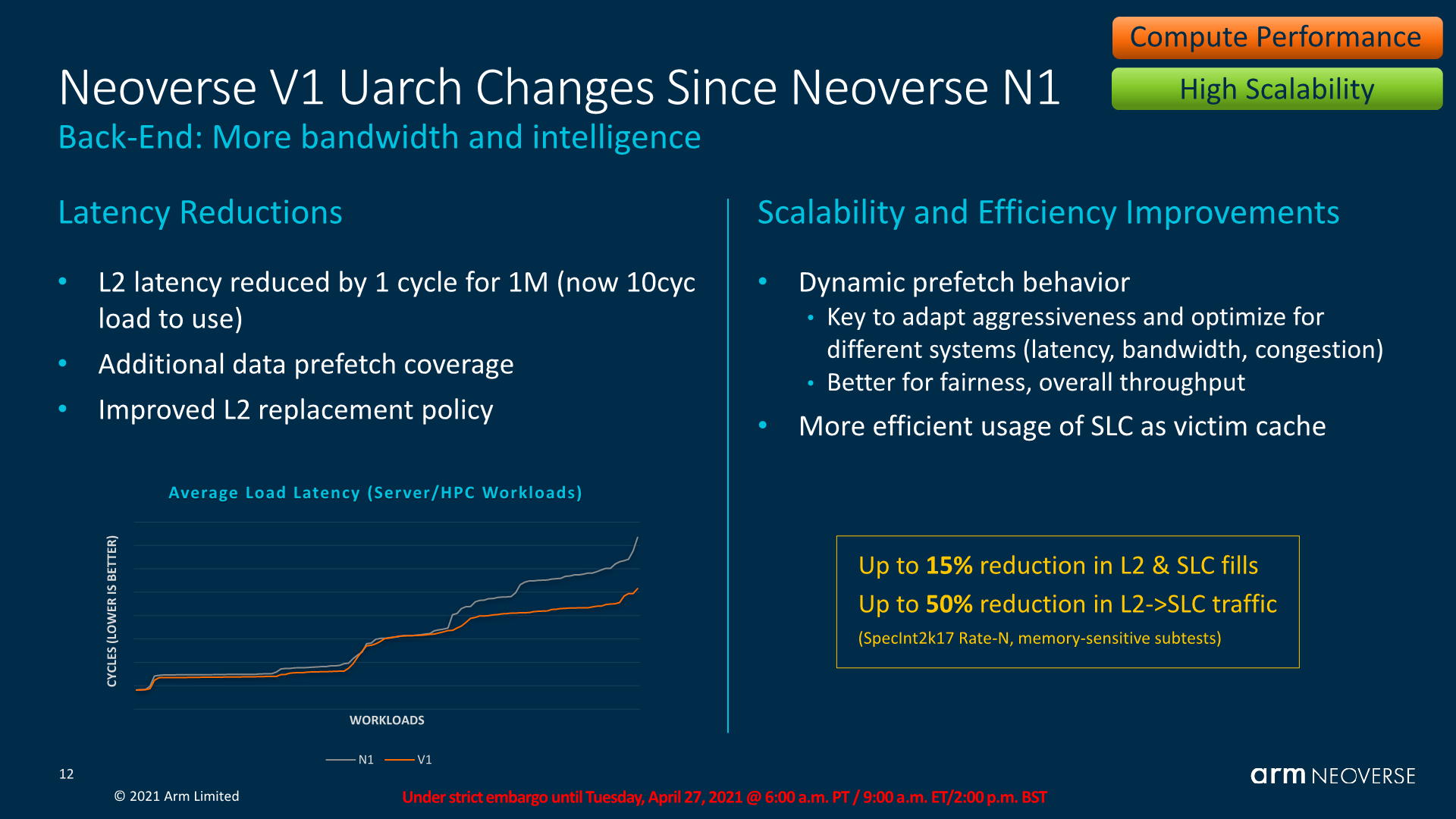
The L2 cache has also adopted a similar design to that of the X1, which is now 1 cycle faster at the same 1MB size, and has double the number of banks in order for increased access parallelism.
Arm here discloses a quite large reduction in the system level latency for the V1. Besides structural improvements, new generation prefetchers are a big part of this, such as the introduction of a new type of temporal prefetcher which is able to latch onto arbitrary access patterns over time and recognise subsequent iterations of the same pattern, and pull the data in.
Arm discloses that the core has new dynamic prefetching behaviour that plays a major role in reducing L2 to interconnect traffic, which is a critical metric in large core count systems where every byte of bandwidth needs to be of actual use and cannot be wasted for wrongly speculated prefetching.








95 Comments
View All Comments
Dug - Tuesday, April 27, 2021 - link
Now is when I wish ARM was publicly traded.mode_13h - Tuesday, April 27, 2021 - link
Well, you could buy NVDA, under the assumption the acquisition will go through.dotjaz - Thursday, April 29, 2021 - link
SoftBank is already publicly traded on the Tokyo Stock Exchange. Why rely on NVIDIA buyout which for all likelihood won't happen any time soon if at all.mode_13h - Thursday, April 29, 2021 - link
> SoftBank is already publicly traded on the Tokyo Stock Exchange.They also invested heavily in WeWork, when it was highly over-valued. I have no idea what other nutty positions they might've taken, but I think it's not a great proxy for ARM just due to its sheer size.
cjcoats - Tuesday, April 27, 2021 - link
As an environmental modeling (HPCC) developer: what is the chance of putting a V1 machine on my desk in the foreseeable future?Silver5urfer - Tuesday, April 27, 2021 - link
Never. Since there has to be an OEM for these chips to put in DIY and Consumer machines, so far except the HPE's A64FX ARM there's no way any consumer can buy these ARM processors and that is also highly expensive over 5 digit figure. And then the drivers / sw ecosystem comes into play, there's passion projects like Pi as we all know but they are nowhere near the Desktop class performance.ARM Graviton 2 was made because AWS wants to save money on their Infrastructure, that's why their Annapurna design team is working there. Simply because of that reason Amazon put more effort onto it AND the fact that ARM is custom helps them to tailor it to their workloads and spread their cost.
Altra is niche, Marvell is nowhere near as their plans was to make custom chips on order. And from the coverage above we see India, Korea, EU use custom design licensing for their HPC Supercomputer designs.
Then there's a rumor that MS is also making their own chips, again custom tailored for their Azure, Google also rumored esp their Whitechapel mobile processor (it won't beat any processor on the market that's my guess) and maybe their GCP oriented own design.
These numbers projection do look good vs x86 SMT machines finally to me after all these years, BUT have to see how they will compete once they are out vs 2021 HW is the big question, since if these CPUs outperform the EPYC Milan technically AWS should replace all of them right ? since you have Perf / Power improvements by a massive scale. Idk, gotta see. Then the upcoming AMD Genoa and Sapphire Rapids competition will also show how the landscape will be.
SarahKerrigan - Tuesday, April 27, 2021 - link
If they don't replace all the x86 systems in AWS with ARM, that *must* mean Neoverse is somehow secretly inferior, right??Or, you know, it could mean that x86 compatibility matters for a fair chunk of the EC2 installed base, especially on the Windows Server side (which is not small) but on Linux too (Oracle DB, for instance, which does not yet run on ARM.)
Silver5urfer - Tuesday, April 27, 2021 - link
That was a joke.Spunjji - Friday, April 30, 2021 - link
Was it, though? Schrodinger's Joke strikes again.Raqia - Tuesday, April 27, 2021 - link
Maybe not an V1 but you could probably get a more open high performance ARM core than the Apple MX series pretty soon:https://investor.qualcomm.com/news-events/press-re...
"The first Qualcomm® Snapdragon™ platforms to feature Qualcomm Technologies' new internally designed CPUs are expected to sample in the second half of 2022 and will be designed for high performance ultraportable laptops."