Arm Announces Neoverse V1, N2 Platforms & CPUs, CMN-700 Mesh: More Performance, More Cores, More Flexibility
by Andrei Frumusanu on April 27, 2021 9:00 AM EST- Posted in
- CPUs
- Arm
- Servers
- Infrastructure
- Neoverse N1
- Neoverse V1
- Neoverse N2
- CMN-700
The SVE Factor - More Than Just Vector Size
We’ve talked a lot about SVE (Scalable Vector Extensions) over the past few years, and the new Arm ISA feature has been most known as being employed for the first time in Fujitsu’s A64FX processor core, which now powers the world’s most performance supercomputer.
Traditionally, employing CPU microarchitectures with wider SIMD vector capabilities always came with the caveat that you needed to use a new instruction set to make use of these wider vectors. For example, in the x86 world, we’ve seen the move from 128b (SSE-SSE4.2 & AVX) to 256b (AVX & AVX2) to 512b (AVX512) vectors always be coupled with a need for software to be redesigned and recompiled to make use of newer wider execution capabilities.
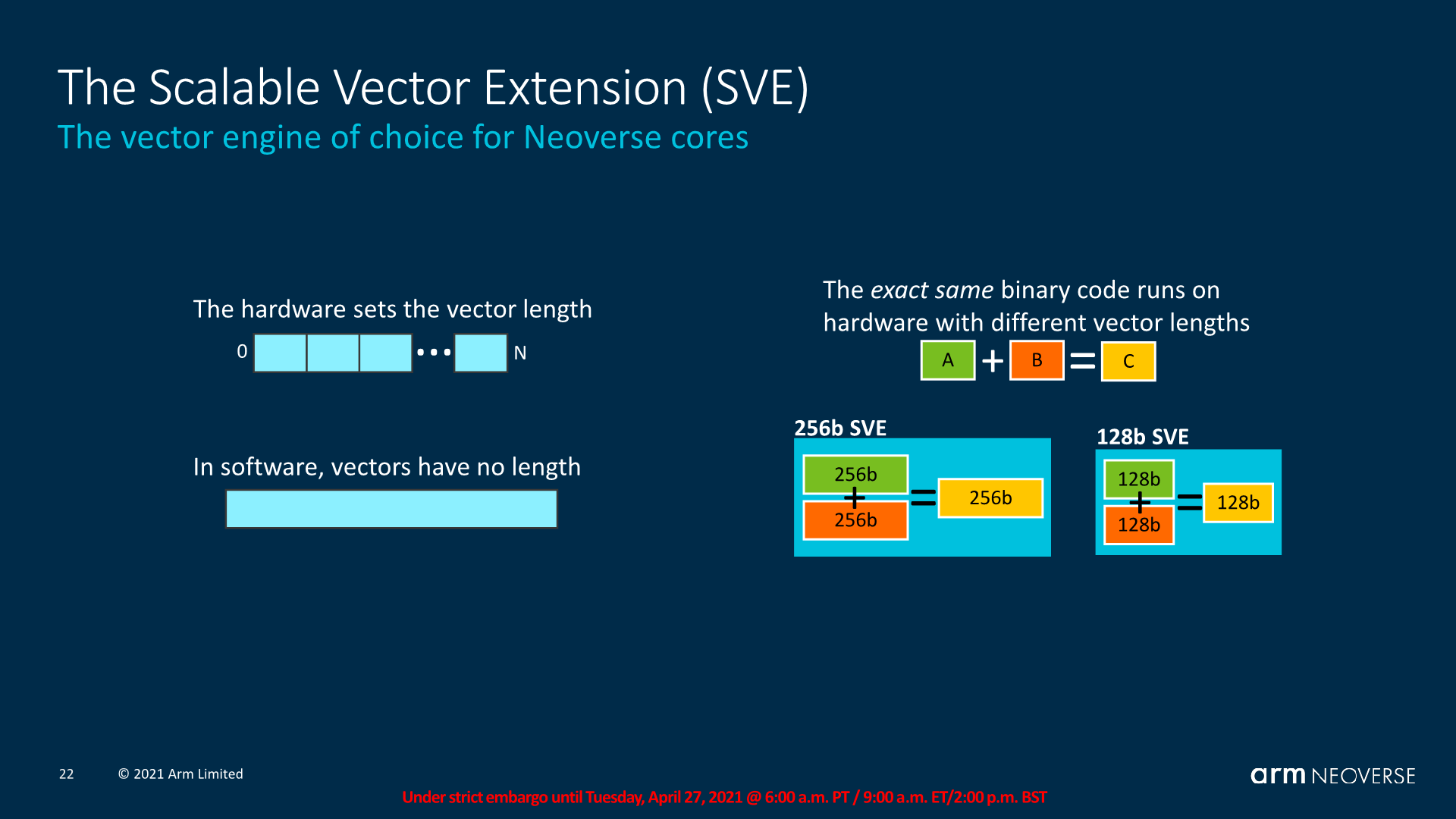
SVE on the other hand is hardware vector execution unit width agnostic, meaning that from a software perspective, the programmer doesn’t actually know the length of the vector that the software will end up running at. On the hardware side, CPU designers can implement execution units in 128b increments from 128b to 2048b in width. As noted earlier, the Neoverse N2 uses this smaller implementation of 128b units, while the Neoverse V1 uses 256b implementations.
Generally speaking, the actual execution width of the vector isn’t as important as the total execution width of a microarchitecture, 2x256b isn’t necessarily faster than 4x128b, however it does play a larger role on the software side of things where the same binary and code path can now be deployed to very different target products, which is also very important for Arm and their mobile processor designs.
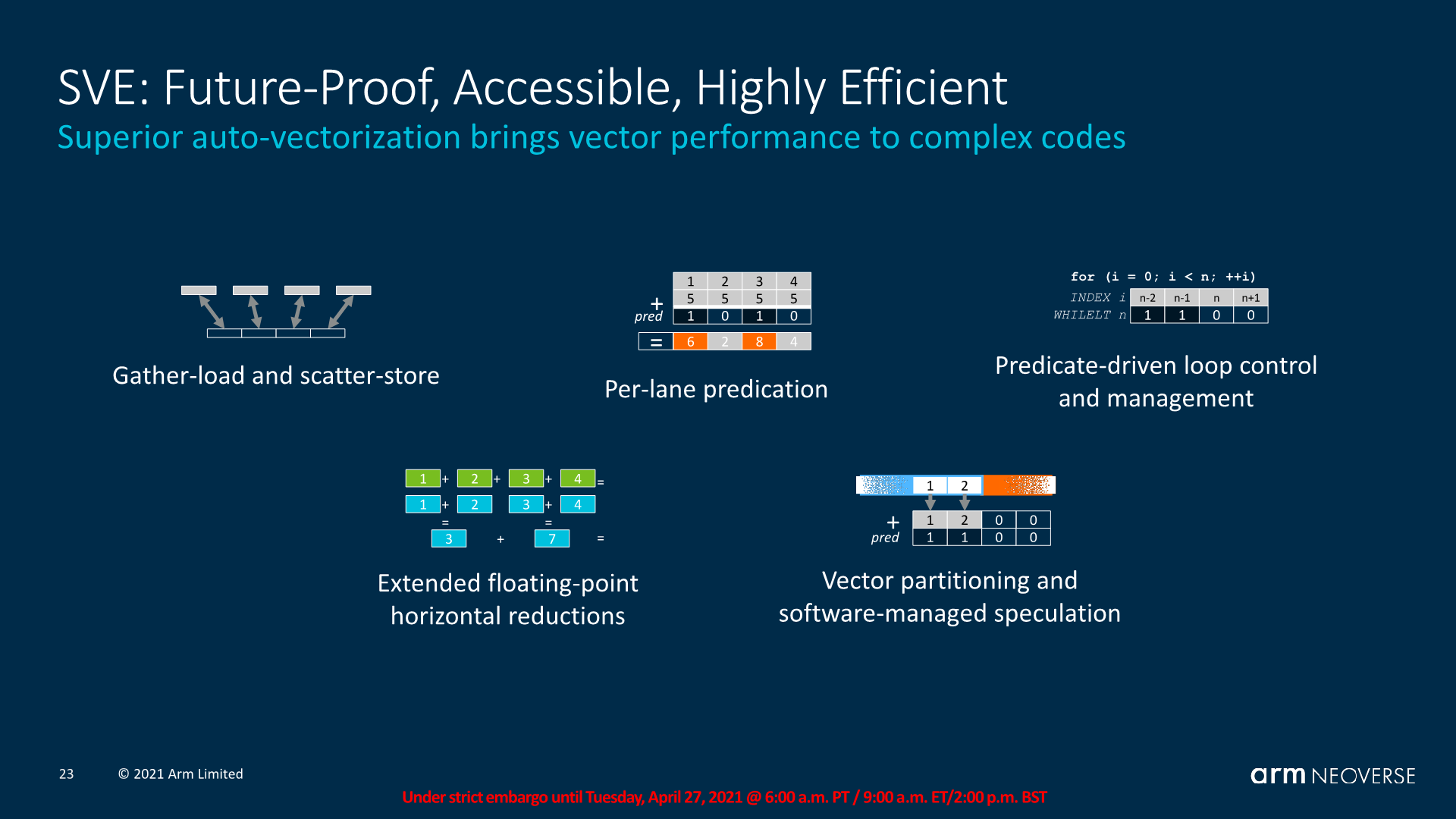
More important than the actual scalable nature of the vectors in SVE, is the new addition of helper instructions and features such as gather-loads, scatter-stores, per-lane predication, predicate-driven loop control (conditional execution depending on SIMD data), and many other features.
Where these things particularly come into play is for allowing compilers to generate better auto-vectorised code, meaning the compiler would now be capable of emitting SIMD instructions on SVE where previously it wasn’t possible with NEON – regardless of the vector length changes.

Arm here discloses that the performance advantages on auto-vectorizable code can be quite significant. In a 2x128b comparison between the N1 and the N2, we can see around 40th-percentile gains of at least 20% of performance, with some code reaching even much higher gains of up to +90%.
The V1 versus N1 increase being higher comes natural from the fact that the core has double the vector execution capabilities over the N1.

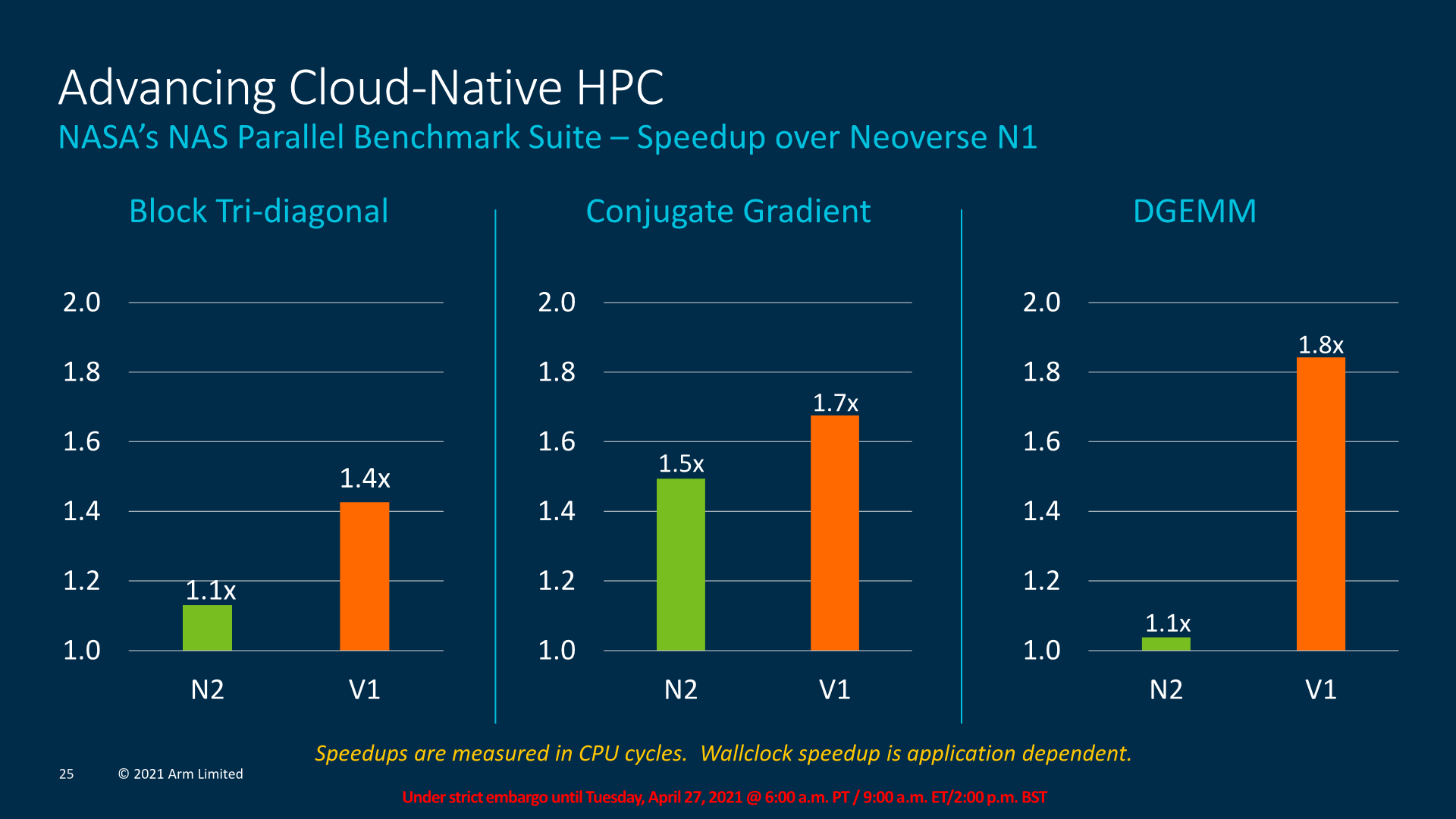
In general, both the N2, but particularly the V1, promise quite large increase in HPC workloads with vector heavy compute characteristics. It’ll definitely be interesting to see how these future designs play out and how SVE auto-vectorisation plays out in more general purpose workloads.








95 Comments
View All Comments
Oxford Guy - Tuesday, April 27, 2021 - link
‘Fast-forward to 2021, the Neoverse N1 design today employed in designs such as the Ampere Altra is still competitive, or beating the newest generation AMD or Intel designs – a situation that which a few years ago seemed anything but farfetched.’Hmm... That last bit is odd. Either it’s just ‘farfetched’ or it’s ‘expected’.
eastcoast_pete - Tuesday, April 27, 2021 - link
Yes, those slides look very promising; now eagerly awaiting an eventual test of one or two of these in a actual silicone. I guess then we'll see how they measure up.mode_13h - Tuesday, April 27, 2021 - link
Silicone - From Wikipedia, the free encyclopediaNot to be confused with the chemical element silicon.
A silicone or polysiloxane is a polymer made up of siloxane (−R2Si−O−SiR2−, where R = organic group). They are typically colorless, oils or rubber-like substances. Silicones are used in sealants, adhesives, lubricants, medicine, cooking utensils, and thermal and electrical insulation.
eastcoast_pete - Thursday, April 29, 2021 - link
I'll have to take this up with auto-correct. It keeps changing silicon to silicone. Now that I forced it again to leave silicon alone (for the umpteenth time), maybe it will stop (:Mondozai - Tuesday, April 27, 2021 - link
Fantastic overview by Andrew. AT's most underrated reporter. Hopefully he gets more responsibility to cover more things in the future.Linustechtips12#6900xt - Tuesday, April 27, 2021 - link
AGREEDdotjaz - Tuesday, April 27, 2021 - link
Good, finally confirmed N2 is in fact ARMv9 as suspected. Now we'll just have to wait and see how the new mobile counterparts are. Hopefully we'll see some real improvements.It'll be interesting to see how small the new low power v9 core is given that it has to have a 128b SVE2 pipeline instead of 2x64b NEON.
mode_13h - Wednesday, April 28, 2021 - link
> finally confirmed N2 is in fact ARMv9 as suspected.> Now we'll just have to wait and see how the new mobile counterparts are.
> Hopefully we'll see some real improvements.
The data presented on N2 doesn't give me much hope that v9 changed much, besides the feature baseline. I was hoping for something slightly revolutionary, but it's certainly not that.
dotjaz - Thursday, April 29, 2021 - link
> hoping for something slightly revolutionaryWe've known for a couple of years ARMv9 is just ARMv8.x rebased. Your hopes weren't realistic to begin with. Besides, what "revolutionary" features would you expect ISAs to include? Can oyu name one? ARMv8.5a+SVE2 already has everything you need to design an excellent and efficient uarch. Why re-invent the wheel just for the sake of it?
mode_13h - Thursday, April 29, 2021 - link
> We've known for a couple of years ARMv9 is just ARMv8.x rebased.You knew this according to where? It's one thing to assume that, and clearly it wasn't an unreasonable assumption, but it's another thing to *know* it. So, how did you *know* it?
> Besides, what "revolutionary" features would you expect ISAs to include? Can oyu name one?
It's a fair question. Generally speaking, anything that would help improve efficiency. Maybe things like scheduling hints or maybe some kind of tags to indicate memory writes that are thread-private and terminal reads. Just some examples, off the top of my head.
> ARMv8.5a+SVE2 already has everything you need to design an excellent and efficient uarch.
The issue I see is that IPC and efficiency gains are going to become ever more hard-won, so there needs to be some more creativity in redefining the SW/HW interface to unlock further gains. ARMv9 is going to be with us for probably another decade and it could end up having to compete with yet-to-be-identified alternatives like maybe RISC VI or something completely out of left-field. So, I see it as a wasted opportunity. A pragmatic decision, for sure, but a little disappointing.