Intel 3rd Gen Xeon Scalable (Ice Lake SP) Review: Generationally Big, Competitively Small
by Andrei Frumusanu on April 6, 2021 11:00 AM EST- Posted in
- Servers
- CPUs
- Intel
- Xeon
- Enterprise
- Xeon Scalable
- Ice Lake-SP
Conclusion & End Remarks
Today’s launch of the new 3rd gen Xeon Scalable processors is a major step forward for Intel and the company’s roadmap. Ice Lake SP had been baking in the oven for a very long time: originally planned for a 2020 release, Intel had only started production recently this January, so finally seeing the chips in silicon and in hand has been a relief.
Generationally Impressive
Technically, Ice Lake SP is an impressive and major generation leap for Intel’s enterprise line-up. Manufactured on a new 10nm process, node, employing a new core microarchitecture, faster memory with more memory channels, PCIe 4.0, new accelerator capabilities and VNNI instructions, security improvements – these are all just the tip of the iceberg that Ice Lake SP brings to the table.
In terms of generational performance uplifts, we saw some major progress today with the new Xeon 8380. With 40 cores at a higher TDP of 270W, the new flagship chip is a veritable beast with large increases in performance in almost all workloads. Major architectural improvements such as the new memory bandwidth optimisations are amongst what I found to be most impressive for the new parts, showcasing that Intel still has a few tricks up its sleeve in terms of design.
This being the first super-large 10nm chip design from Intel, the question of how efficiency would end up was a big question to the whole puzzle to the new generation line-up. On the Xeon 8380, a 40-core part at 270W, we saw a +18% increase in performance / W compared to the 28-core 205W Xeon 8280. This grew to a +36% perf/W advantage when limiting the ICX part to 205 as well. On the other hand, our mid-stack Xeon 6330 sample showed very little advantages to the Xeon 8280, even both are 28-core 205W designs. Due to the mix of good and bad results here, it seems we’ll have to delay a definitive verdict on the process node improvements to the future until we can get more SKUs, as the current variations are quite large.
Per-core performance, as well as single-thread performance of the new parts don’t quite achieve what I imagine Intel would have hoped through just the IPC gains of the design. The IPC gains are there and they’re notable, however the new parts also lose out on frequency, meaning the actual performance doesn’t move too much, although we did see smaller increases. Interestingly enough, this is roughly the same conclusion we came to when we tested Intel's Ice Lake notebook platform back in August 2019.

The Competitive Hurdle Still Stands
As impressive as the new Xeon 8380 is from a generational and technical stand-point, what really matters at the end of the day is how it fares up to the competition. I’ll be blunt here; nobody really expected the new ICL-SP parts to beat AMD or the new Arm competition – and it didn’t. The competitive gap had been so gigantic, with silly scenarios such as where competing 1-socket systems would outperform Intel’s 2-socket solutions. Ice Lake SP gets rid of those more embarrassing situations, and narrows the performance gap significantly, however the gap still remains, and is still undeniable.
We’ve only had access limited to the flagship Xeon 8380 and the mid-stack Xeon 6330 for the review today, however in a competitive landscape, both those chips lose out in both absolute performance as well as price/performance compared to AMD’s line-up.
Intel had been pushing very hard the software optimisation side of things, trying to differentiate themselves as well as novel technologies such as PMem (Optane DC persistent memory, essentially Optane memory modules), which unfortunately didn’t have enough time to cover for this piece. Indeed, we saw a larger focus on “whole system solutions” which take advantage of Intel’s broader product portfolio strengths in the enterprise market. The push for the new accelerator technologies means Intel needs to be working closely with partners and optimising public codebases to take advantage of these non-standard solutions, which might be a hurdle for deployments such as cloud services where interoperability might be important. While the theoretical gains can be large, anyone rolling a custom local software stack might see a limited benefit however, unless they are already experts with Intel's accelerator portfolio.
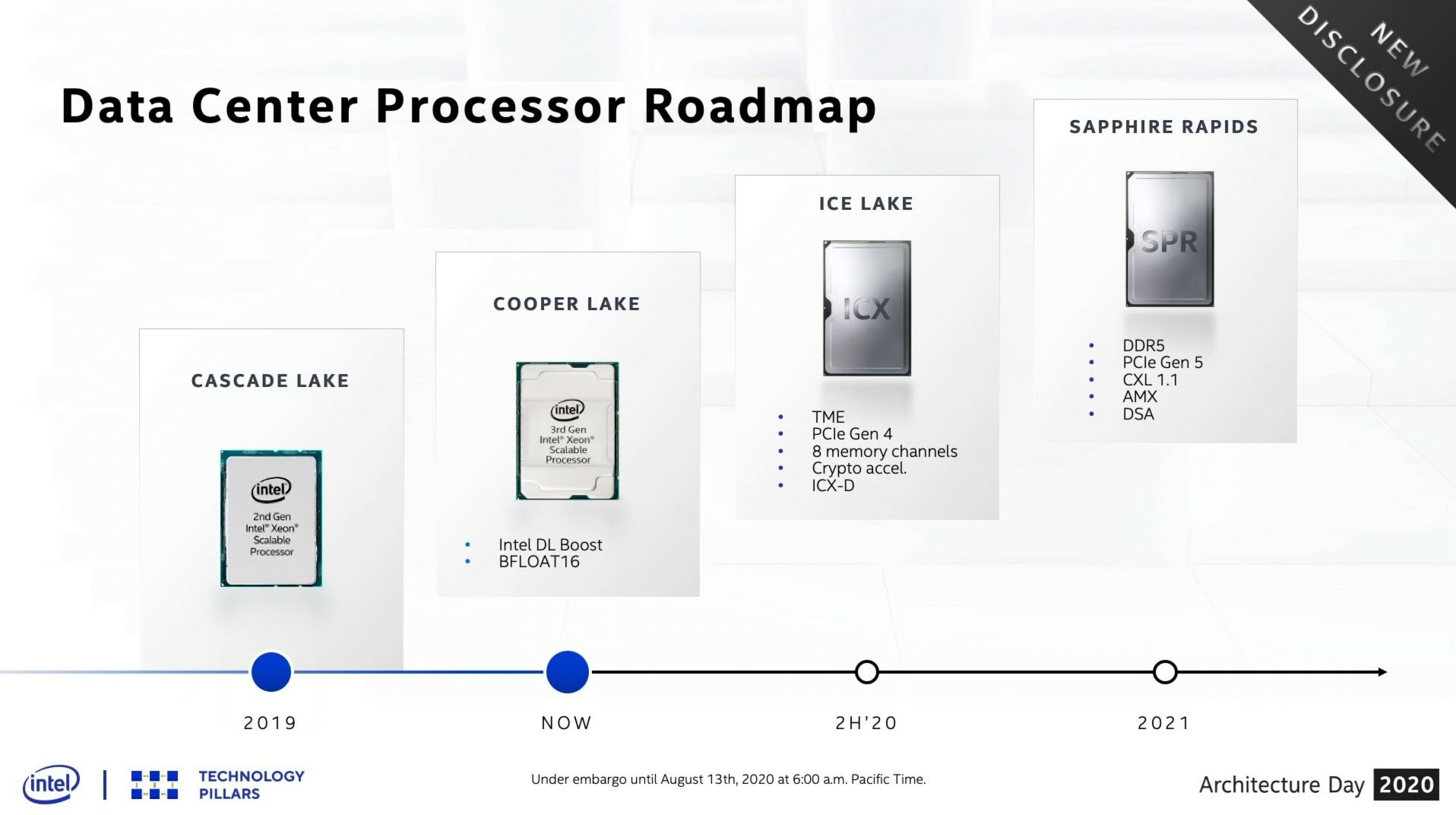
There’s also the looming Intel roadmap. While we are exulted to finally see Ice lake SP reach the market, Intel is promising the upcoming Sapphire Rapids chips for later this year, on a new platform with DDR5 and PCIe 5. Intel is set to have Ice Lake Xeon and Sapphire Rapids Xeon in the market concurrently, with the idea to manage both, especially for customers that apply the leading edge hardware as soon as it is available. It will be interesting to see the scale of the roll out of Ice Lake with this in mind.
At the end of the day, Ice Lake SP is a success. Performance is up, and performance per watt is up. I'm sure if we were able to test Intel's acceleration enhancements more thoroughly, we would be able to corroborate some of the results and hype that Intel wants to generate around its product. But even as a success, it’s not a traditional competitive success. The generational improvements are there and they are large, and as long as Intel is the market share leader, this should translate into upgraded systems and deployments throughout the enterprise industry. Intel is still in a tough competitive situation overall with the high quality the rest of the market is enabling.








169 Comments
View All Comments
mode_13h - Wednesday, April 7, 2021 - link
Intel, AMD, and ARM all contribute loads of patches to both GCC and LLVM. There's no way either of these compilers can be seen as "underdeveloped".And Intel is usually doing compiler work a couple YEARS ahead of each CPU & GPU generation. If anyone is behind, it's AMD.
Oxford Guy - Wednesday, April 7, 2021 - link
It's not cheating if the CPU can do that work art that speed.It's only cheating if you don't make it clear to readers what kind of benchmark it is (hand-tuned assembly).
mode_13h - Thursday, April 8, 2021 - link
Benchmarks, in articles like this, should strive to be *relevant*. And for that, they ought to focus on representing the performance of the CPUs as the bulk of readers are likely to experience it.So, even if using some vendor-supplied compiler with trick settings might not fit your definition of "cheating", that doesn't mean it's a service to the readers. Maybe save that sort of thing for articles that specifically focus on some aspect of the CPU, rather than the *main* review.
Oxford Guy - Sunday, April 11, 2021 - link
There is nothing more relevant than being able to see all facets of a part's performance. This makes it possible to discern its actual performance capability.Some think all a CPU comparison needs are gaming benchmarks. There is more to look at than subsets of commercial software. Synthetic benchmarks also are valid data points.
mode_13h - Monday, April 12, 2021 - link
It's kind of like whether an automobile reviewer tests a car with racing tyres and 100-octane fuel. That would show you its maximum capabilities, but it's not how most people are going to experience it. While a racing enthusiast might be interested in knowing this, it's not a good proxy for the experience most people are likely to have with it.All I'm proposing is to prioritize accordingly. Yes, we want to know how many lateral g's it can pull on a skid pad, once you remove the limiting factor of the all-season tyres, but that's secondary.
Wilco1 - Thursday, April 8, 2021 - link
It's still cheating if you compare highly tuned benchmark scores with untuned scores. If you use it to trick users into believing CPU A is faster than CPU B eventhough CPU A is really slower, you are basically doing deceptive marketing. Mentioning it in the small print (which nobody reads) does not make it any less cheating.Oxford Guy - Sunday, April 11, 2021 - link
It's cheating to use software that's very unoptimized to claim that that's as much performance as CPU has.For example... let's say we'll just skip all software that has AVX-512 support — on the basis that it's just not worth testing because so many CPUs don't support it.
Wilco1 - Sunday, April 11, 2021 - link
Running not fully optimized software is what we do all the time, so that's exactly what we should be benchmarking. The -Ofast option used here is actually too optimized since most code is built with -O2. Some browsers use -Os/-Oz for much of their code!AVX-512 and software optimized for AVX-512 is quite rare today, and the results are pretty awful on the latest cores: https://www.phoronix.com/scan.php?page=article&...
Btw Andrei ran ICC vs GCC: https://twitter.com/andreif7/status/13808945639975...
ICC is 5% slower than GCC on SPECINT. So there we go.
mode_13h - Monday, April 12, 2021 - link
Not to disagree with you, but always take Phoronix' benchmarks with a grain of salt.First, he tested one 14 nm CPU model that only has one AVX-512 unit per core. Ice Lake has 2, and therefore might've shown more benefit.
Second, PTS is enormous (more than 1 month typical runtime) and I haven't seen Michael being very transparent about his criteria for selecting which benchmarks to feature in his articles. He can easily bias perception through picking benchmarks that respond well or poorly to the feature or product in question.
There are also some questions raised about his methodology, such as whether he effectively controlled for AVX-512 usage in some packages that contain hand-written asm. However, by looking at the power utilization graphs, I doubt that's an issue in this case. But, if he excluded such packages for that very reason, then it could unintentionally bias the results.
Wilco1 - Monday, April 12, 2021 - link
Completely agree that Phoronix benchmarks are dubious - it's not only the selection but also the lack of analysis of odd results and the incorrect way he does cross-ISA comparisons. It's far better to show a few standard benchmarks with well-known characteristics than a random sample of unknown microbenchmarks.Ignoring all that, there are sometimes useful results in all the noise. The power results show that for the selected benchmarks there is really use of AVX-512. Whether this is typical across a wider range of code is indeed the question...