Intel Core i7-11700K Review: Blasting Off with Rocket Lake
by Dr. Ian Cutress on March 5, 2021 4:30 PM EST- Posted in
- CPUs
- Intel
- 14nm
- Xe-LP
- Rocket Lake
- Cypress Cove
- i7-11700K
CPU Tests: Microbenchmarks
Core-to-Core Latency
As the core count of modern CPUs is growing, we are reaching a time when the time to access each core from a different core is no longer a constant. Even before the advent of heterogeneous SoC designs, processors built on large rings or meshes can have different latencies to access the nearest core compared to the furthest core. This rings true especially in multi-socket server environments.
But modern CPUs, even desktop and consumer CPUs, can have variable access latency to get to another core. For example, in the first generation Threadripper CPUs, we had four chips on the package, each with 8 threads, and each with a different core-to-core latency depending on if it was on-die or off-die. This gets more complex with products like Lakefield, which has two different communication buses depending on which core is talking to which.
If you are a regular reader of AnandTech’s CPU reviews, you will recognize our Core-to-Core latency test. It’s a great way to show exactly how groups of cores are laid out on the silicon. This is a custom in-house test built by Andrei, and we know there are competing tests out there, but we feel ours is the most accurate to how quick an access between two cores can happen.
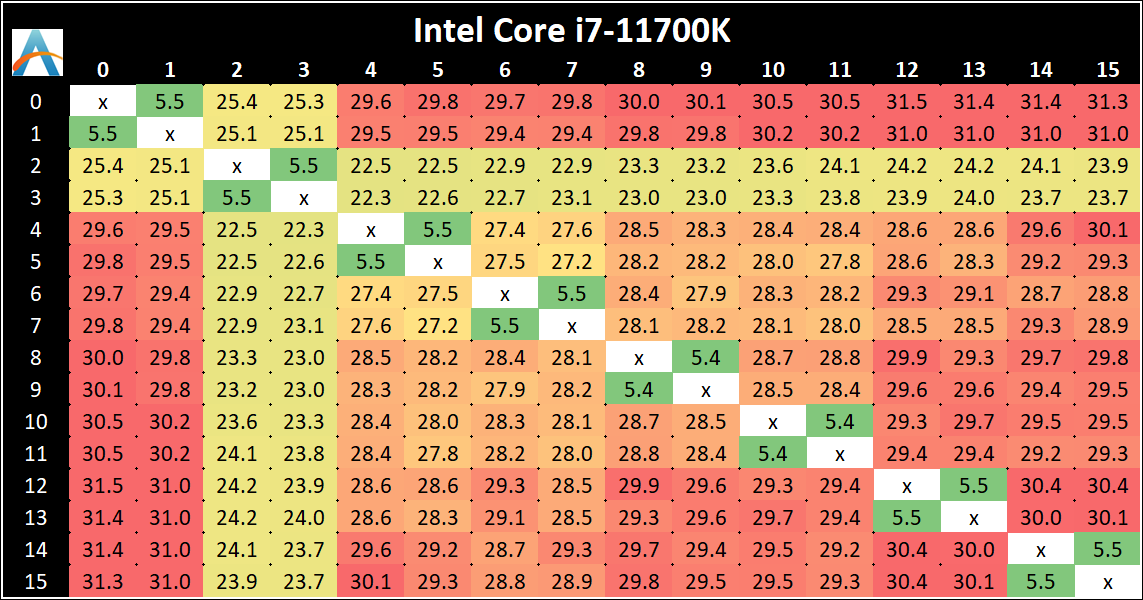
The core-to-core numbers are interesting, being worse (higher) than the previous generation across the board. Here we are seeing, mostly, 28-30 nanoseconds, compared to 18-24 nanoseconds with the 10700K. This is part of the L3 latency regression, as shown in our next tests.
One pair of threads here are very fast to access all cores, some 5 ns faster than any others, which again makes the layout more puzzling.
Update 1: With microcode 0x34, we saw no update to the core-to-core latencies.
Cache-to-DRAM Latency
This is another in-house test built by Andrei, which showcases the access latency at all the points in the cache hierarchy for a single core. We start at 2 KiB, and probe the latency all the way through to 256 MB, which for most CPUs sits inside the DRAM (before you start saying 64-core TR has 256 MB of L3, it’s only 16 MB per core, so at 20 MB you are in DRAM).
Part of this test helps us understand the range of latencies for accessing a given level of cache, but also the transition between the cache levels gives insight into how different parts of the cache microarchitecture work, such as TLBs. As CPU microarchitects look at interesting and novel ways to design caches upon caches inside caches, this basic test proves to be very valuable.
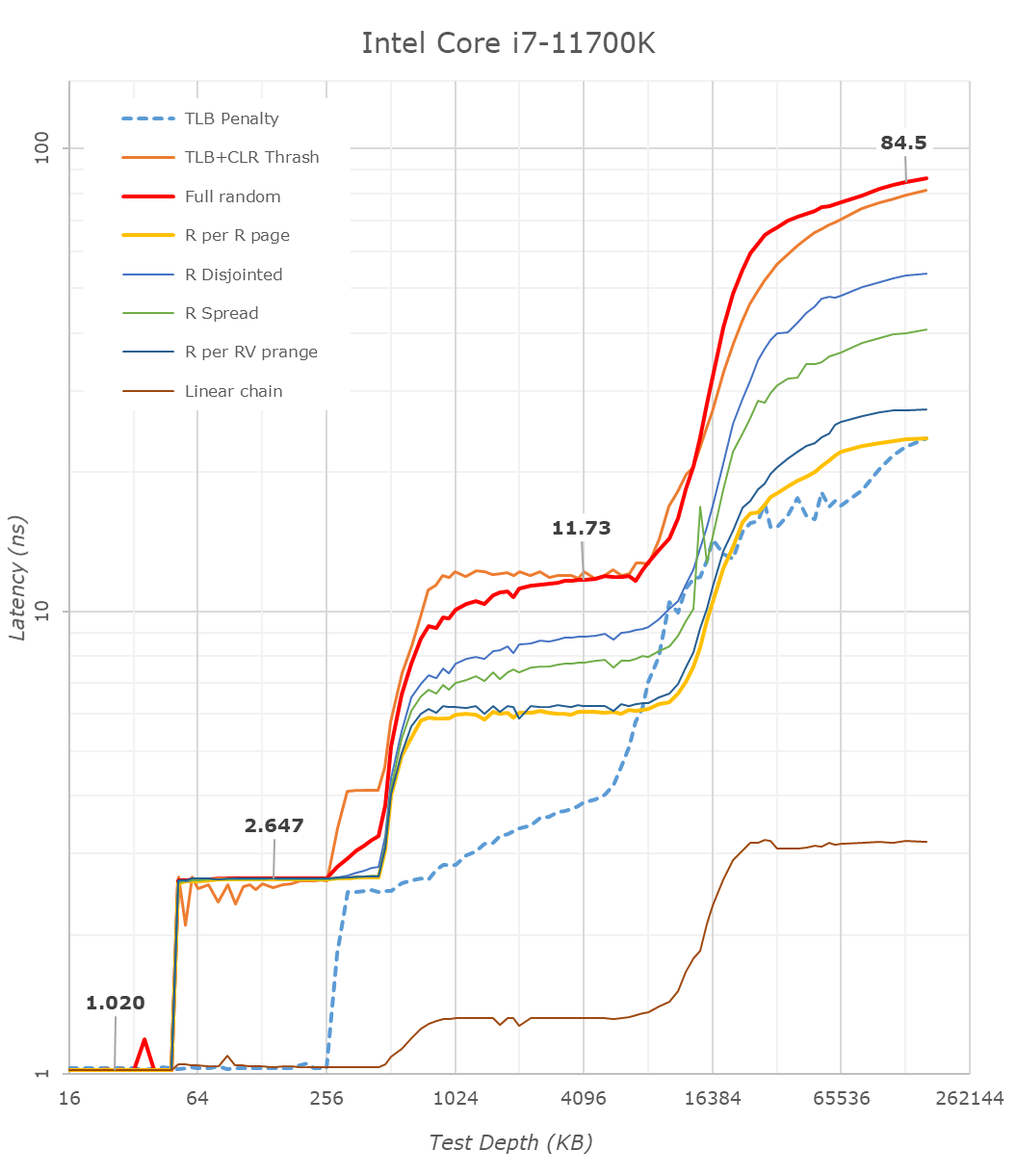
Looking at the rough graph of the 11700K and the general boundaries of the cache hierarchies, we again see the changes of the microarchitecture that had first debuted in Intel’s Sunny Cove cores, such as the move from an L1D cache from 32KB to 48KB, as well as the doubling of the L2 cache from 256KB to 512KB.
The L3 cache on these parts look to be unchanged from a capacity perspective, featuring the same 16MB which is shared amongst the 8 cores of the chip.
On the DRAM side of things, we’re not seeing much change, albeit there is a small 2.1ns generational regression at the full random 128MB measurement point. We’re using identical RAM sticks at the same timings between the measurements here.
It’s to be noted that these slight regressions are also found across the cache hierarchies, with the new CPU, although it’s clocked slightly higher here, shows worse absolute latency than its predecessor, it’s also to be noted that AMD’s newest Zen3 based designs showcase also lower latency across the board.
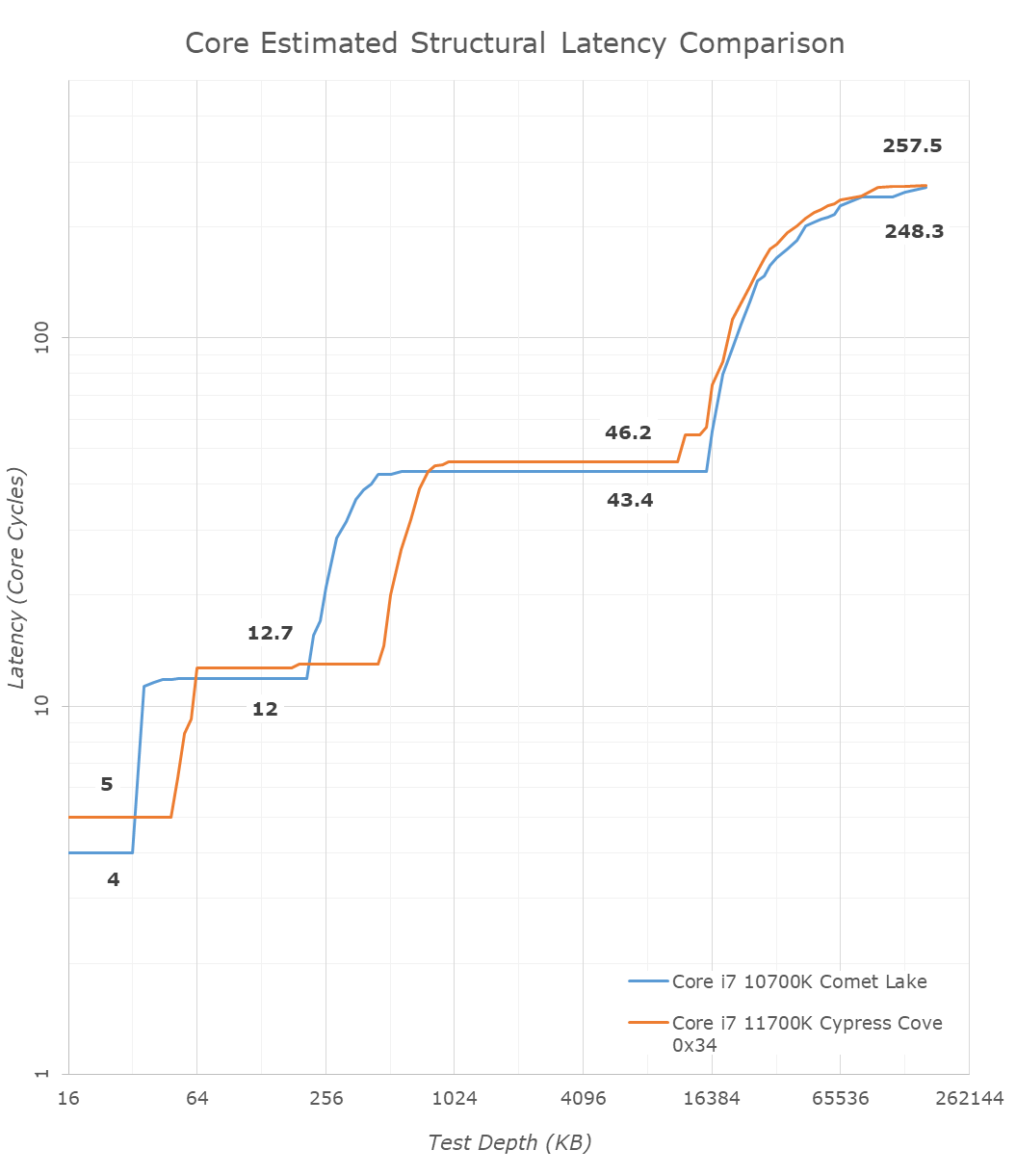
With the new graph of the Core i7-11700K with microcode 0x34, the same cache structures are observed, however we are seeing better performance with L3.
The L1 cache structure is the same, and the L2 is of a similar latency. In our previous test, the L3 latency was 50.9 cycles, but with the new microcode is now at 45.1 cycles, and is now more in line with the L3 cache on Comet Lake.
Out at DRAM, our 128 MB point reduced from 82.4 nanoseconds to 72.8 nanoseconds, which is a 12% reduction, but not the +40% reduction that other media outlets are reporting as we feel our tools are more accurate. Similarly, for DRAM bandwidth, we are seeing a +12% memory bandwidth increase between 0x2C and 0x34, not the +50% bandwidth others are claiming. (BIOS 0x1B however, was significantly lower than this, resulting in a +50% bandwidth increase from 0x1B to 0x34.)
In the previous edition of our article, we questioned the previous L3 cycle being a larger than estimated regression. With the updated microcode, the smaller difference is still a regression, but more in line with our expectations. We are waiting to hear back from Intel what differences in the microcode encouraged this change.
Frequency Ramping
Both AMD and Intel over the past few years have introduced features to their processors that speed up the time from when a CPU moves from idle into a high powered state. The effect of this means that users can get peak performance quicker, but the biggest knock-on effect for this is with battery life in mobile devices, especially if a system can turbo up quick and turbo down quick, ensuring that it stays in the lowest and most efficient power state for as long as possible.
Intel’s technology is called SpeedShift, although SpeedShift was not enabled until Skylake.
One of the issues though with this technology is that sometimes the adjustments in frequency can be so fast, software cannot detect them. If the frequency is changing on the order of microseconds, but your software is only probing frequency in milliseconds (or seconds), then quick changes will be missed. Not only that, as an observer probing the frequency, you could be affecting the actual turbo performance. When the CPU is changing frequency, it essentially has to pause all compute while it aligns the frequency rate of the whole core.
We wrote an extensive review analysis piece on this, called ‘Reaching for Turbo: Aligning Perception with AMD’s Frequency Metrics’, due to an issue where users were not observing the peak turbo speeds for AMD’s processors.
We got around the issue by making the frequency probing the workload causing the turbo. The software is able to detect frequency adjustments on a microsecond scale, so we can see how well a system can get to those boost frequencies. Our Frequency Ramp tool has already been in use in a number of reviews.
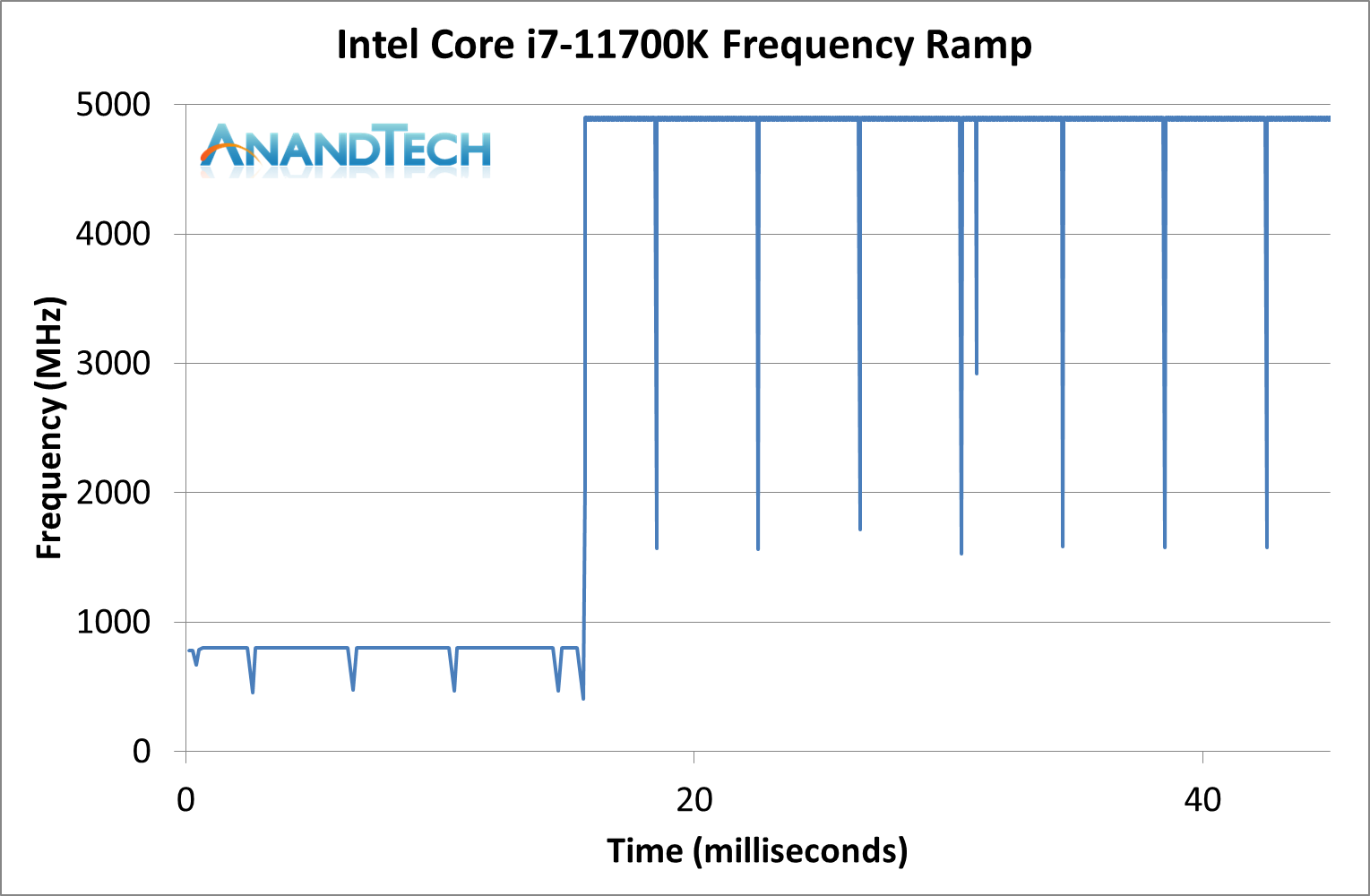
Our ramp test shows a jump straight from 800 MHz up to 4900 MHz in around 17 milliseconds, or a frame at 60 Hz.








541 Comments
View All Comments
ottonis - Saturday, March 6, 2021 - link
How is Ryzen 5800x AMD's "best of the best"?It clearly is not but just about somewhere in the middle. If you want AMD's best consumer CPU, you gonna look at the 5950x.
From the perspective of AMD, completely outsourcing manufacturing was the only way to reap the benefits of latest and greatest process nodes.
Now, that everybody else, incl. the automobile industry, the consoles, Apple, and even Intel are booking production capacities at TMSC, has certainly contributed to Reaching capacity limits and thus to AMD CPU shortages.
It is predicted that shortages will be mostly (hopefully) sorted out by this summer.
But yes, now that AMD are earning quite a lot of money they should buy some TSMC stock and try to partner up, getting more production capacity in the future.
Fulljack - Saturday, March 6, 2021 - link
did you just forgetting why AMD spin-off it's fab on the first place?we don't know exactly how much AMD put out their desktop chips from TSMC plant, and as far as we know, the market are still growing in size. while AMD market share are still a long way from reaching 50%, they still have their processor sold out all over the place.
honestly I don't get what you're trying to say here.
shady28 - Saturday, March 6, 2021 - link
Actually we do know, they made ~1M Zen 3 chips in Q4. 140M PCs were shipped. Based on their market share, about 3% of the chips AMD shipped in Q4 were Zen 3.Source:https://wccftech.com/amd-shipped-nearly-1-million-...
inighthawki - Monday, March 8, 2021 - link
5800X = "Best of the best"11700K = "medium level SKU"
Your bias is showing.
Bluetooth - Saturday, March 6, 2021 - link
Does any one know the details of Intels 10 nm node problems. Any article discussing that in technical details?dihartnell - Thursday, March 11, 2021 - link
I think adored tv did a few articles, videos on this. As I understand it thier main issues are they use a monolithic die (everything on on a single die) that gets harder to make as the process shrinks, IE more dies have defects... AMD got around this by going chiplet, lots of small dies which meant more of them are good. Until Intel chnages to chiplet or they find a way to improve the manufacturing process to lower the defect rate then they will struggle.Santoval - Saturday, March 6, 2021 - link
Class action for what, excessive power bills? :) Imagine using this during a heatwave in an airless room. Since it doubles as a heater you would need to have the AC on all the time. If you have no AC there will be a competition between who dies first, you or the processor? ^.^sabot00 - Friday, March 5, 2021 - link
Indeed! I have been reading nothing but wccftech and Tom's leaks. Absolutely amazing surprise this Friday night while searching Rocket LakeBeaver M. - Saturday, March 6, 2021 - link
I would be very cautious testing or believing results with the Z590 platforms long before Rocket Lakes official release.Ive tested 3 of those boards with my Comet Lake (Asus, MSI and ASRock) and they all had pretty bad BIOS versions still, with PCIe/IO performance being low in SSD 4K benchmarks and getting weird frame time stutters from time to time (only noticeable when actually playing or looking at a realtime graph). Not to mention Intels drivers are still bad as well.
On none of them even very basic features like the sleep state worked!
Comparing this review with user benchmarks in German forums shows huge differences, so theres not much to add to this.
That said, I have to laugh when Americans or people from other countries with cheap power complain about the power draw.
And seeing fanboys downplay the performance of AVX and ignoring that it was always power hungry, even 6 years ago, is another obvious thing. Without it RKL actually runs pretty cool for being ancient 14nm.
And of course I love the geniuses who still think that you cant use the iGPU without it being connected to a monitor, or dont know about the new power saving/GPU switching feature. Not that this article didnt fail at pretty much everything, incl. explaining things like that.
Gigaplex - Saturday, March 6, 2021 - link
"That said, I have to laugh when Americans or people from other countries with cheap power complain about the power draw."Electricity is expensive where I live, but that's not why I want low power consumption. The more power it consumes, the louder the cooling solution will be. That's why my last system was Intel (Ivy Bridge) and my current system is AMD (Zen 3).