AMD 3rd Gen EPYC Milan Review: A Peak vs Per Core Performance Balance
by Dr. Ian Cutress & Andrei Frumusanu on March 15, 2021 11:00 AM ESTDisclaimer June 25th: The benchmark figures in this review have been superseded by our second follow-up Milan review article, where we observe improved performance figures on a production platform compared to AMD’s reference system in this piece.
SPECjbb MultiJVM - Java Performance
Moving on from SPECCPU, we shift over to SPECjbb2015. SPECjbb is a from ground-up developed benchmark that aims to cover both Java performance and server-like workloads, from the SPEC website:
“The SPECjbb2015 benchmark is based on the usage model of a worldwide supermarket company with an IT infrastructure that handles a mix of point-of-sale requests, online purchases, and data-mining operations. It exercises Java 7 and higher features, using the latest data formats (XML), communication using compression, and secure messaging.
Performance metrics are provided for both pure throughput and critical throughput under service-level agreements (SLAs), with response times ranging from 10 to 100 milliseconds.”
The important thing to note here is that the workload is of a transactional nature that mostly works on the data-plane, between different Java virtual machines, and thus threads.
We’re using the MultiJVM test method where as all the benchmark components, meaning controller, server and client virtual machines are running on the same physical machine.
The JVM runtime we’re using is OpenJDK 15 on both x86 and Arm platforms, although not exactly the same sub-version, but closest we could get:
EPYC & Xeon systems:
openjdk 15 2020-09-15
OpenJDK Runtime Environment (build 15+36-Ubuntu-1)
OpenJDK 64-Bit Server VM (build 15+36-Ubuntu-1, mixed mode, sharing)
Altra system:
openjdk 15.0.1 2020-10-20
OpenJDK Runtime Environment 20.9 (build 15.0.1+9)
OpenJDK 64-Bit Server VM 20.9 (build 15.0.1+9, mixed mode, sharing)
Furthermore, we’re configuring SPECjbb’s runtime settings with the following configurables:
SPEC_OPTS_C="-Dspecjbb.group.count=$GROUP_COUNT -Dspecjbb.txi.pergroup.count=$TI_JVM_COUNT -Dspecjbb.forkjoin.workers=N -Dspecjbb.forkjoin.workers.Tier1=N -Dspecjbb.forkjoin.workers.Tier2=1 -Dspecjbb.forkjoin.workers.Tier3=16"
Where N=160 for 2S Altra test runs, N=80 for 1S Altra test runs, N=112 for 2S Xeon, N=56 for 1S Xeon, and N=128 for 2S and 1S on the EPYC system. The 75F3 system had the worker count reduced to 64 and 32 for 2S/1S runs.
In terms of JVM options, we’re limiting ourselves to bare-bone options to keep things simple and straightforward:
EPYC & Altra systems:
JAVA_OPTS_C="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC "
JAVA_OPTS_TI="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_BE="-server -Xms48g -Xmx48g -Xmn42g -XX:+UseParallelGC -XX:+AlwaysPreTouch"
Xeon system:
JAVA_OPTS_C="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_TI="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_BE="-server -Xms172g -Xmx172g -Xmn156g -XX:+UseParallelGC -XX:+AlwaysPreTouch"
The reason the Xeon system is running a larger back-end heap is because we’re running a single NUMA node per socket, while for the Altra and EPYC we’re running four NUMA nodes per socket for maximised throughput, meaning for the 2S figures we have 8 backends running for the Altra and EPYC and 2 for the Xeon, and naturally half of those numbers for the 1S benchmarks. The back-ends and transaction injectors are affinitised to their local NUMA node with numactl –cpunodebind and –membind, while the controller is called with –interleave=all.
The max-jOPS and critical-jOPS result figures are defined as follows:
"The max-jOPS is the last successful injection rate before the first failing injection rate where the reattempt also fails. For example, if during the RT-curve phase the injection rate of 80000 passes, but the next injection rate of 90000 fails on two successive attempts, then the max-jOPS would be 80000."
"The overall critical-jOPS is computed by taking the geomean of the individual critical-jOPS computed at these five SLA points, namely:
• Critical-jOPSoverall = Geo-mean of (critical-jOPS@ 10ms, 25ms, 50ms, 75ms and 100ms response time SLAs)
During the RT curve building phase the Transaction Injector measures the 99th percentile response times at each step level for all the requests (see section 9) that are considered in the metrics computations. It then computes the Critical-jOPS for each of the above five SLA points using the following formula:
(first * nOver + last * nUnder) / (nOver + nUnder) "
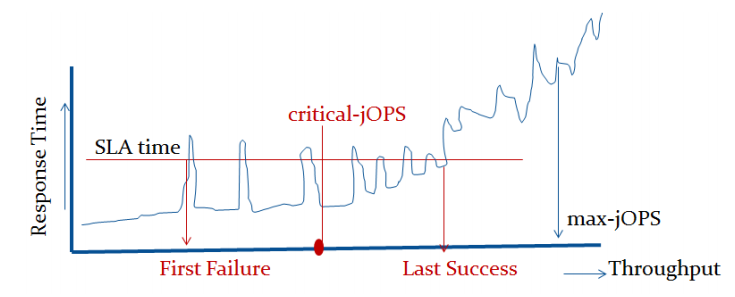
That’s a lot of technicalities to explain an admittedly complex benchmark, but the gist of it is that max-jOPS represents the maximum transaction throughput of a system until further requests fail, and critical-jOPS is an aggregate geomean transaction throughput within several levels of guaranteed response times, essentially different levels of quality of service.
Beyond the result figures, the benchmark keeps detailed track of timings of responses and tracks a few important statistical data-points across a response-time curve, as follows:

2S EPYC 7763 THP Enabled
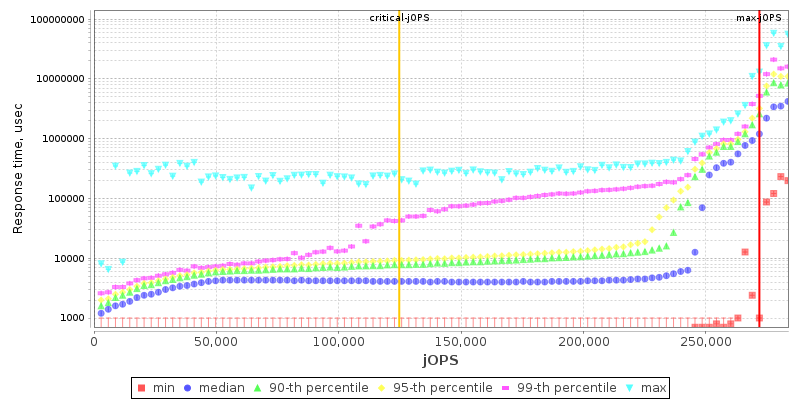
2S EPYC 7742 THP Enabled
In terms of the response curves of the new Milan 7763 part, the general behaviour doesn’t look that much different to the 7742 other than a weird discrepancy at low load.
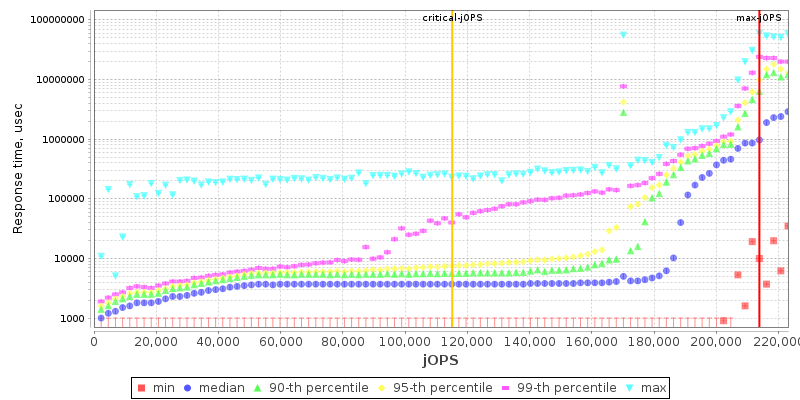
2S EPYC 75F3 THP Enabled
The 75F3 part is interesting as due to it focusing more on per-core performance, it tightens the response curve with the -critical performance score being closer to the -max capacity of the system.

2S Xeon 8280 THP Enabled
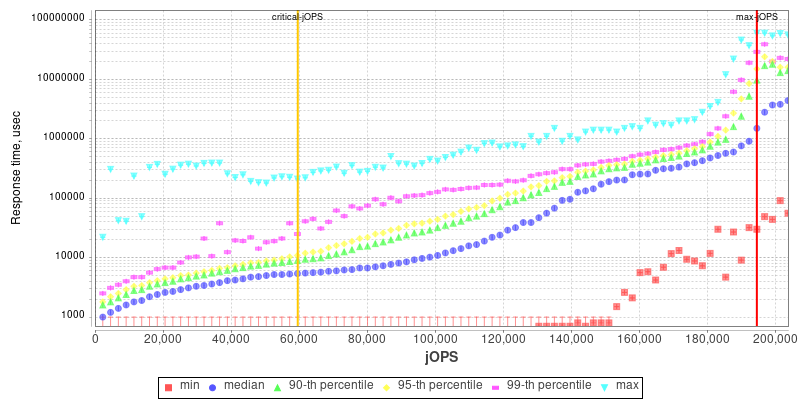
2S Altra Q80-33 THP Enabled
I included the Intel and Altra graphs for context.
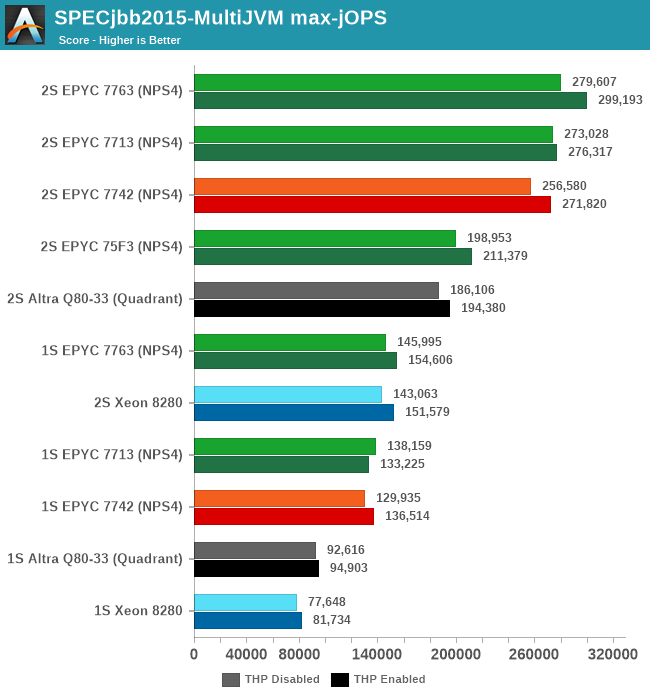
In terms of the -max-jOPS achieved by each system in our settings configuration, the new Zen3 parts fare quite well. The 7763 outperforms the 7742 by +9%, while the 7713 also outperforms the 7742 by +6.4%.
Again, very interesting is to see the 75F3’s maximum throughput reaching 71% of the top SKU’s performance in such scale-out workloads even though it’s only got half the cores available.
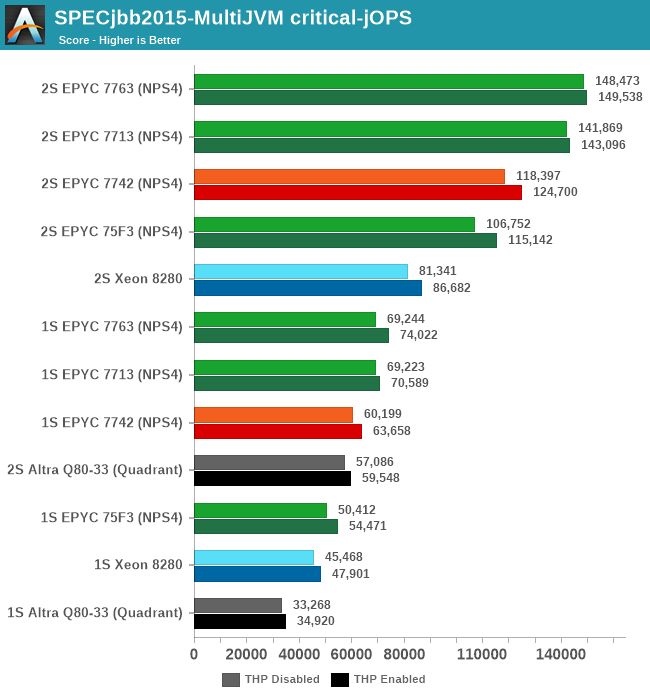
The -critical-jOPS figure is probably the more important metric for SPECjbb given that it covers SLA scenarios, and here the new Milan parts are faring extremely well. The 7763 outperforms the 7742 by +25%, and the 7713 is also not far behind with +19.7%.
The 75F3 is also doing amazingly well, keeping up with the higher core-count parts.
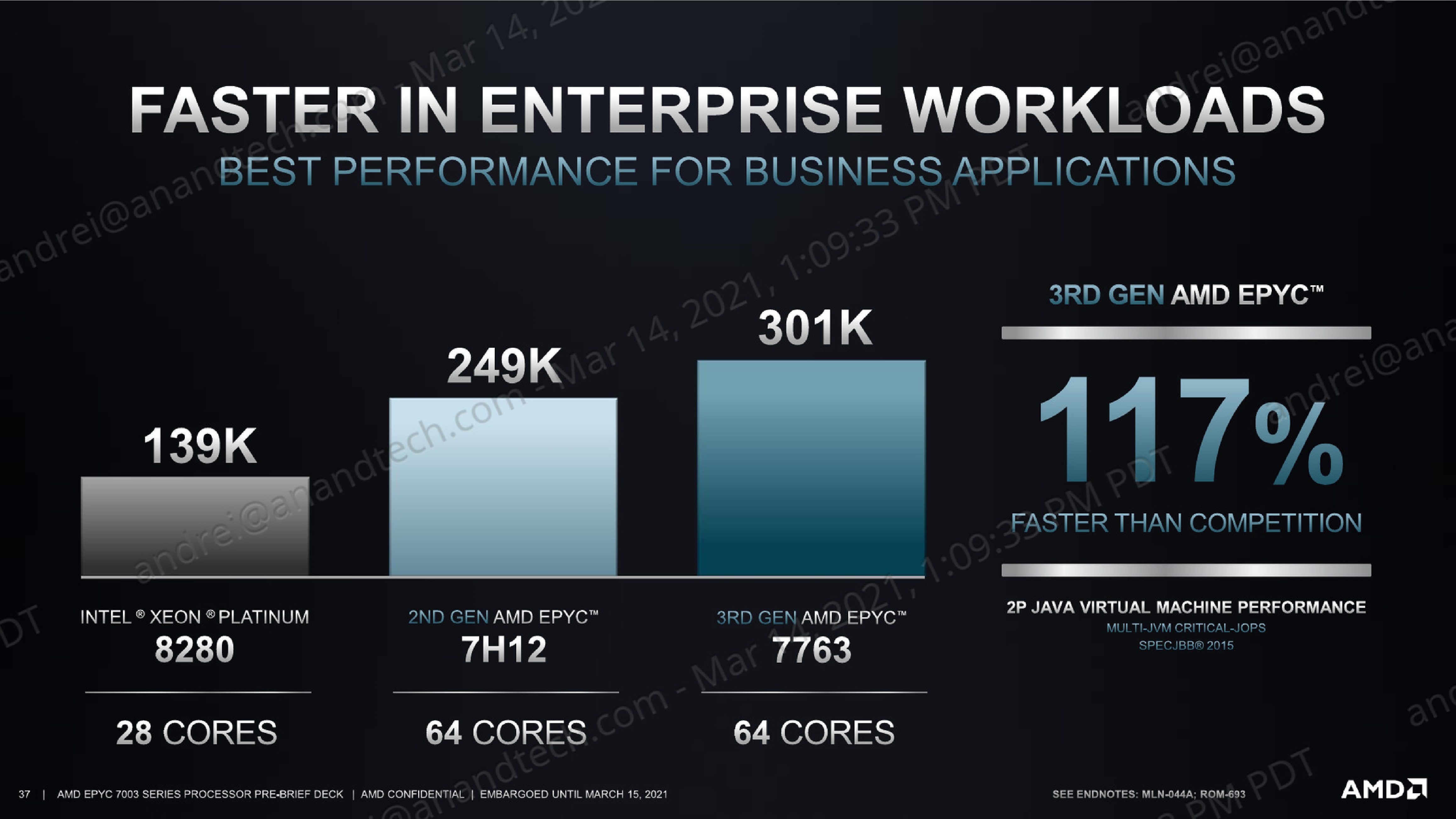
Against the competition, our own and AMD figures differ a bit due to different settings, however we’re still seeing the new Milan top-SKU outperform the 8280 by +82 in performance.
Generally speaking, the generational improvements over Rome in -critical-jOPS figure of SPECjbb are a more reassuring result compared to the other peak full load performance metrics we’ve seen on SPEC CPU. This actually corresponds to the power behaviour of the new chips, with the new Zen3 cores offering notably better per-core performance compared to the Rome predecessor, at least up until the new parts hit a power envelope wall where performance improvements become more limited.








120 Comments
View All Comments
mkbosmans - Tuesday, March 23, 2021 - link
Even if you have a nice two-tiered approach implemented in your software, let's say MPI for the distributed memory parallelization on top of OpenMP for the shared memory parallelization, it often turns out to be faster to limit the shared memory threads to a single socket of NUMA domain. So in case of an 2P EPYC configured as NPS4 you would have 8 MPI ranks per compute node.But of course there's plenty of software that has parallelization implemented using MPI only, so you would need a separate process for each core. This is often because of legacy reasons, with software that was originally targetting only a couple of cores. But with the MPI 3.0 shared memory extension, this can even today be a valid approach to great performing hybrid (shared/distributed mem) code.
mode_13h - Tuesday, March 23, 2021 - link
Nice explanation. Thanks for following up!Andrei Frumusanu - Saturday, March 20, 2021 - link
This is vastly incorrect and misleading.The fact that I'm using a cache line spawned on a third main thread which does nothing with it is irrelevant to the real-world comparison because from the hardware perspective the CPU doesn't know which thread owns it - in the test the hardware just sees two cores using that cache line, the third main thread becomes completely irrelevant in the discussion.
The thing that is guaranteed with the main starter thread allocating the synchronisation cache line is that it remains static across the measurements. One doesn't actually have control where this cache line ends up within the coherent domain of the whole CPU, it's going to end up in a specific L3 cache slice depended on the CPU's address hash positioning. The method here simply maintains that positioning to be always the same.
There is no such thing as core-core latency because cores do not snoop each other directly, they go over the coherency domain which is the L3 or the interconnect. It's always core-to-cacheline-to-core, as anything else doesn't even exist from the hardware perspective.
mkbosmans - Saturday, March 20, 2021 - link
The original thread may have nothing to do with it, but the NUMA domain where the cache line was originally allocated certainly does. How would you otherwise explain the difference between the first quadrant for socket 1 to socket 1 communication and the fourth quadrant for socket 2 to socket 2 communication?Your explanation about address hashing to determine the L3 cache slice may be makes sense when talking about fixing the inital thread within a L3 domain, but not why you want that that L3 domain fixed to the first one in the system, regardless of the placement of the two threads doing the ping-ponging.
And about core-core latency, you are of course right, that is sloppy wording on my part. What I meant to convey is that roundtrip latency between core-cacheline-core and back is more relevant (at least for HPC applications) when the cacheline is local to one of the cores and not remote, possibly even on another socket than the two thread.
Andrei Frumusanu - Saturday, March 20, 2021 - link
I don't get your point - don't look at the intra-remote socket figures then if that doesn't interest you - these systems are still able to work in a single NUMA node across both sockets, so it's still pretty valid in terms of how things work.I'm not fixing it to a given L3 in the system (except for that socket), binding a thread doesn't tell the hardware to somehow stick that cacheline there forever, software has zero say in that. As you see in the results it's able to move around between the different L3's and CCXs. Intel moves (or mirrors it) it around between sockets and NUMA domains, so your premise there also isn't correct in that case, AMD currently can't because probably they don't have a way to decide most recent ownership between two remote CCXs.
People may want to just look at the local socket numbers if they prioritise that, the test method here merely just exposes further more complicated scenarios which I find interesting as they showcase fundamental cache coherency differences between the platforms.
mkbosmans - Tuesday, March 23, 2021 - link
For a quick overview of how cores are related to each other (with an allocation local to one of the cores), I like this way of visualizing it more:http://bosmans.ch/share/naples-core-latency.png
Here you can for example clearly see how the four dies of the two sockets are connected pairwise.
The plots from the article are interesting in that they show the vast difference between the cc protocols of AMD and Intel. And the numbers from the Naples plot I've linked can be mostly gotten from the more elaborate plots from the article, although it is not entirely clear to me how to exactly extend the data to form my style of plots. That's why I prefer to measure the data I'm interested in directly and plot that.
imaskar - Monday, March 29, 2021 - link
Looking at the shares sinking, this pricing was a miss...mode_13h - Tuesday, March 30, 2021 - link
Prices are a lot easier to lower than to raise. And as long as they can sell all their production allocation, the price won't have been too high.Zone98 - Friday, April 23, 2021 - link
Great work! However I'm not getting why in the c2c matrix cores 62 and 74 wouldn't have a ~90ns latency as in the NW socket. Could you clarify how the test works?node55 - Tuesday, April 27, 2021 - link
Why are the cpus not consistent?Why do you switch between 7713 and 7763 on Milan and 7662 and 7742 on Rome?
Why do you not have results for all the server CPUs? This confuses the comparison of e.g. 7662 vs 7713. (My current buying decision )