Intel Rocket Lake (14nm) Review: Core i9-11900K, Core i7-11700K, and Core i5-11600K
by Dr. Ian Cutress on March 30, 2021 10:03 AM EST- Posted in
- CPUs
- Intel
- LGA1200
- 11th Gen
- Rocket Lake
- Z590
- B560
- Core i9-11900K
CPU Tests: Encoding
One of the interesting elements on modern processors is encoding performance. This covers two main areas: encryption/decryption for secure data transfer, and video transcoding from one video format to another.
In the encrypt/decrypt scenario, how data is transferred and by what mechanism is pertinent to on-the-fly encryption of sensitive data - a process by which more modern devices are leaning to for software security.
Video transcoding as a tool to adjust the quality, file size and resolution of a video file has boomed in recent years, such as providing the optimum video for devices before consumption, or for game streamers who are wanting to upload the output from their video camera in real-time. As we move into live 3D video, this task will only get more strenuous, and it turns out that the performance of certain algorithms is a function of the input/output of the content.
HandBrake 1.32: Link
Video transcoding (both encode and decode) is a hot topic in performance metrics as more and more content is being created. First consideration is the standard in which the video is encoded, which can be lossless or lossy, trade performance for file-size, trade quality for file-size, or all of the above can increase encoding rates to help accelerate decoding rates. Alongside Google's favorite codecs, VP9 and AV1, there are others that are prominent: H264, the older codec, is practically everywhere and is designed to be optimized for 1080p video, and HEVC (or H.265) that is aimed to provide the same quality as H264 but at a lower file-size (or better quality for the same size). HEVC is important as 4K is streamed over the air, meaning less bits need to be transferred for the same quality content. There are other codecs coming to market designed for specific use cases all the time.
Handbrake is a favored tool for transcoding, with the later versions using copious amounts of newer APIs to take advantage of co-processors, like GPUs. It is available on Windows via an interface or can be accessed through the command-line, with the latter making our testing easier, with a redirection operator for the console output.
We take the compiled version of this 16-minute YouTube video about Russian CPUs at 1080p30 h264 and convert into three different files: (1) 480p30 ‘Discord’, (2) 720p30 ‘YouTube’, and (3) 4K60 HEVC.
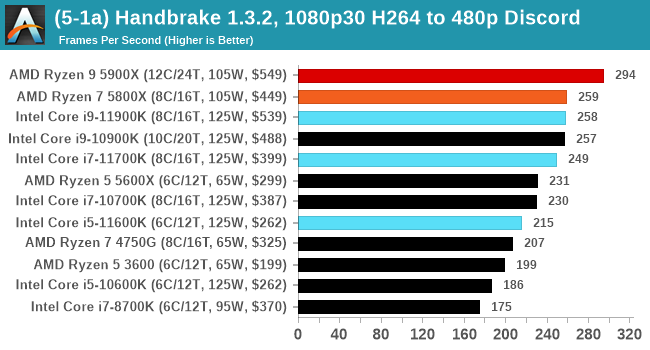
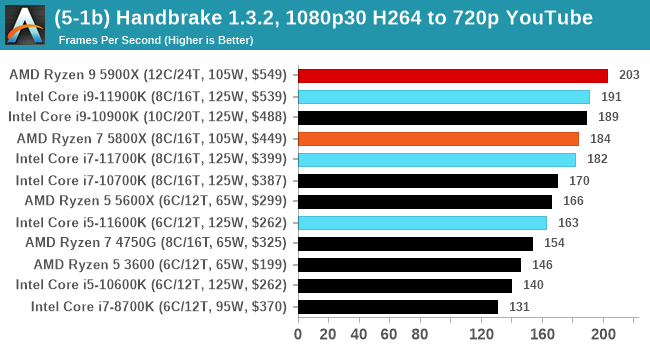
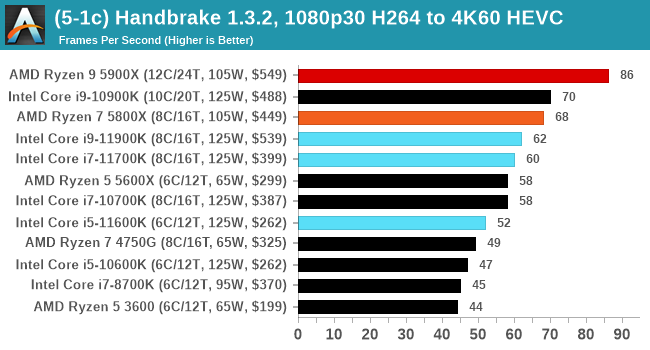
Up to the final 4K60 HEVC, in CPU-only mode, the Intel CPU puts up some good gen-on-gen numbers.
7-Zip 1900: Link
The first compression benchmark tool we use is the open-source 7-zip, which typically offers good scaling across multiple cores. 7-zip is the compression tool most cited by readers as one they would rather see benchmarks on, and the program includes a built-in benchmark tool for both compression and decompression.
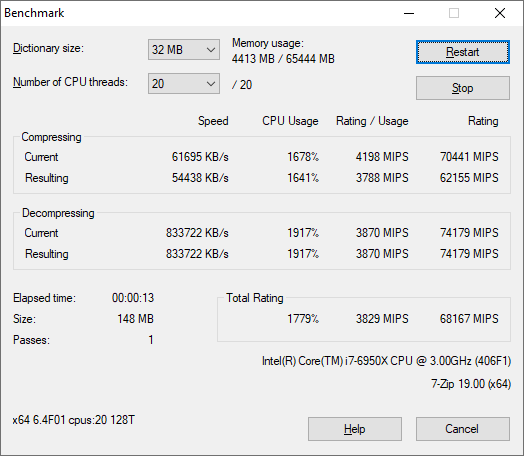
The tool can either be run from inside the software or through the command line. We take the latter route as it is easier to automate, obtain results, and put through our process. The command line flags available offer an option for repeated runs, and the output provides the average automatically through the console. We direct this output into a text file and regex the required values for compression, decompression, and a combined score.
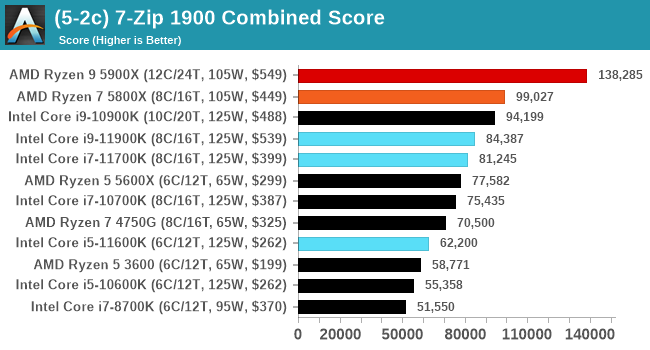
AES Encoding
Algorithms using AES coding have spread far and wide as a ubiquitous tool for encryption. Again, this is another CPU limited test, and modern CPUs have special AES pathways to accelerate their performance. We often see scaling in both frequency and cores with this benchmark. We use the latest version of TrueCrypt and run its benchmark mode over 1GB of in-DRAM data. Results shown are the GB/s average of encryption and decryption.
WinRAR 5.90: Link
For the 2020 test suite, we move to the latest version of WinRAR in our compression test. WinRAR in some quarters is more user friendly that 7-Zip, hence its inclusion. Rather than use a benchmark mode as we did with 7-Zip, here we take a set of files representative of a generic stack
- 33 video files , each 30 seconds, in 1.37 GB,
- 2834 smaller website files in 370 folders in 150 MB,
- 100 Beat Saber music tracks and input files, for 451 MB
This is a mixture of compressible and incompressible formats. The results shown are the time taken to encode the file. Due to DRAM caching, we run the test for 20 minutes times and take the average of the last five runs when the benchmark is in a steady state.
For automation, we use AHK’s internal timing tools from initiating the workload until the window closes signifying the end. This means the results are contained within AHK, with an average of the last 5 results being easy enough to calculate.

CPU Tests: Synthetic
Most of the people in our industry have a love/hate relationship when it comes to synthetic tests. On the one hand, they’re often good for quick summaries of performance and are easy to use, but most of the time the tests aren’t related to any real software. Synthetic tests are often very good at burrowing down to a specific set of instructions and maximizing the performance out of those. Due to requests from a number of our readers, we have the following synthetic tests.
Linux OpenSSL Speed: SHA256
One of our readers reached out in early 2020 and stated that he was interested in looking at OpenSSL hashing rates in Linux. Luckily OpenSSL in Linux has a function called ‘speed’ that allows the user to determine how fast the system is for any given hashing algorithm, as well as signing and verifying messages.
OpenSSL offers a lot of algorithms to choose from, and based on a quick Twitter poll, we narrowed it down to the following:
- rsa2048 sign and rsa2048 verify
- sha256 at 8K block size
- md5 at 8K block size
For each of these tests, we run them in single thread and multithreaded mode. All the graphs are in our benchmark database, Bench, and we use the sha256 results in published reviews.


Intel comes back into the game in our OpenSSL sha256 test as the AVX512 helps accelerate SHA instructions. It still isn't enough to overcome the dedicated sha256 units inside AMD.
CPU Tests: Legacy and Web
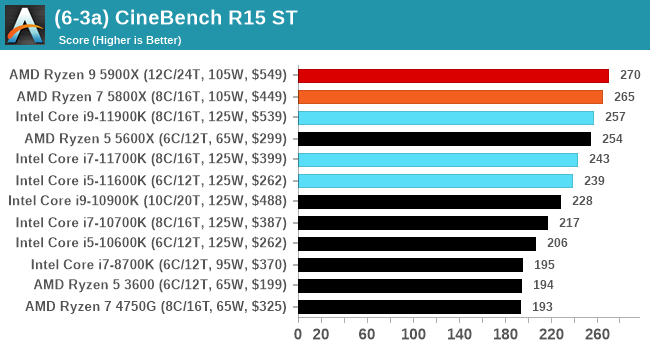
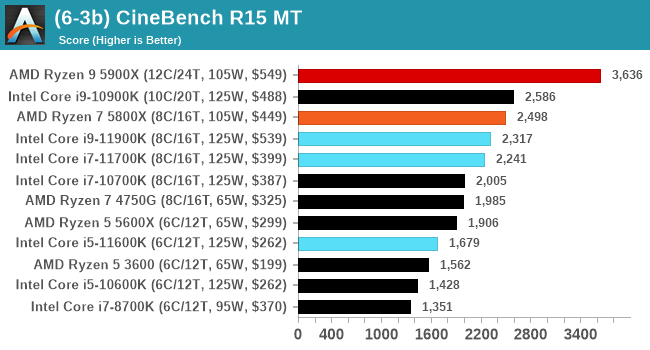
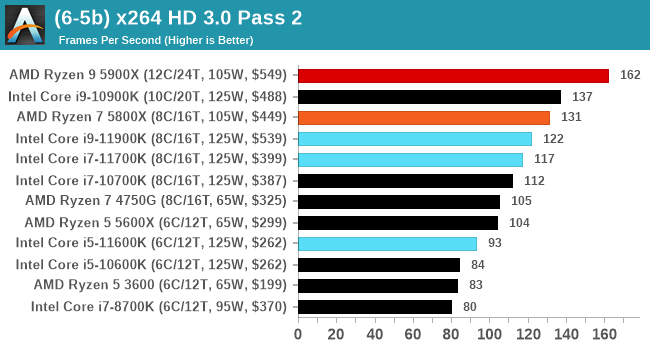
In order to gather data to compare with older benchmarks, we are still keeping a number of tests under our ‘legacy’ section. This includes all the former major versions of CineBench (R15, R11.5, R10) as well as x264 HD 3.0 and the first very naïve version of 3DPM v2.1. We won’t be transferring the data over from the old testing into Bench, otherwise it would be populated with 200 CPUs with only one data point, so it will fill up as we test more CPUs like the others.
The other section here is our web tests.
Web Tests: Kraken, Octane, and Speedometer
Benchmarking using web tools is always a bit difficult. Browsers change almost daily, and the way the web is used changes even quicker. While there is some scope for advanced computational based benchmarks, most users care about responsiveness, which requires a strong back-end to work quickly to provide on the front-end. The benchmarks we chose for our web tests are essentially industry standards – at least once upon a time.
It should be noted that for each test, the browser is closed and re-opened a new with a fresh cache. We use a fixed Chromium version for our tests with the update capabilities removed to ensure consistency.
Mozilla Kraken 1.1
Kraken is a 2010 benchmark from Mozilla and does a series of JavaScript tests. These tests are a little more involved than previous tests, looking at artificial intelligence, audio manipulation, image manipulation, json parsing, and cryptographic functions. The benchmark starts with an initial download of data for the audio and imaging, and then runs through 10 times giving a timed result.

We loop through the 10-run test four times (so that’s a total of 40 runs), and average the four end-results. The result is given as time to complete the test, and we’re reaching a slow asymptotic limit with regards the highest IPC processors.
Google Octane 2.0
Our second test is also JavaScript based, but uses a lot more variation of newer JS techniques, such as object-oriented programming, kernel simulation, object creation/destruction, garbage collection, array manipulations, compiler latency and code execution.
Octane was developed after the discontinuation of other tests, with the goal of being more web-like than previous tests. It has been a popular benchmark, making it an obvious target for optimizations in the JavaScript engines. Ultimately it was retired in early 2017 due to this, although it is still widely used as a tool to determine general CPU performance in a number of web tasks.

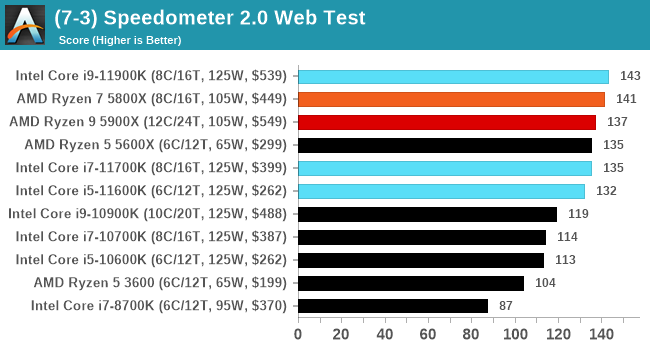
Speedometer 2: JavaScript Frameworks
Our newest web test is Speedometer 2, which is a test over a series of JavaScript frameworks to do three simple things: built a list, enable each item in the list, and remove the list. All the frameworks implement the same visual cues, but obviously apply them from different coding angles.
Our test goes through the list of frameworks, and produces a final score indicative of ‘rpm’, one of the benchmarks internal metrics.
We repeat over the benchmark for a dozen loops, taking the average of the last five.
Legacy Tests









279 Comments
View All Comments
SystemsBuilder - Wednesday, March 31, 2021 - link
and you are a Computer Science graduate? What Linus T. is saying is that AVX-512 is a power hog and he is right about that. Linus T. is not saying that "a couple dozen or so people" are able to program it. Power requirements and programing hardness are 2 different things.On the second point, I 100% stand by that any decent Computer Science/Engineering graduate should be able to program AVX-512 effectively (overcoming hardness not power requirements).
Also, I do program AVX-512 and I 100% stand by what I said. You just need to know what you are doing and vectorize algorithms. If you use the good old sequential algorithms you will not archive anything with AVX-512, but it you vectorize you're classical algorithms you will also achieve >100% benefits in many inner loops in so called mainstream programming. AVX-512 can give you 2x uplift if you know how to utilize both FMA units on port 0+1 and 5 and it's not hard.
Lastly, with decent negative AVX-512 offsets in BIOS, you can bring down the power utilization to ok levels AND still get 2x improvements in the inner loops (because of vectorized algorithmic improvement).
Hifihedgehog - Wednesday, March 31, 2021 - link
> and you are a Computer Science graduate?No, I am a Computer Engineering graduate. Sorry, but you are grasping at straws. Plus you are overcomplicating the obvious to try to be an Intel apologist. Just see this and this. Read it and weep. Intel flopped big time this release:
https://i.imgur.com/HZVC03T.png
https://i.imgflip.com/53vqce.jpg
SystemsBuilder - Wednesday, March 31, 2021 - link
So fellow CS/CE grad. I'm not arguing that AVX-512 is a power hog (it is) or that the AVX-512 offsets slows down the rest of the CPU (they do). I am arguing the premise that AVX-512 is supposed to be so incredibly hard to do that only "couple dozen or so people" can do is wrong today - Skylake-X with AVX-512 was launched 2017 for heaven's sake. Surely, I can't be the only CS/CE guy how figured it out by now. I mean really? When Ian wrote what Keller said (and keep on writing it) that that this AVX-512 is sooo hard to do that only a few guys on the planet can do it well, my reaction was "let's see about that". I mean come on guys, really!SystemsBuilder - Wednesday, March 31, 2021 - link
More specifically Linus is concerned that because you need to use negative offsets to keep the power utilization down when engaging AVX-512 it slows down everything else going on. i.e. AVX-512 power requirements overall CPU impact. The new cores designs (already Cypress Cove maybe? but Sapphire Rapids definitely!) will allow AVX-512 workloads to run at one frequency (with lower negative offsets that for instance Skylake-X) and non AVX-512 workloads at a different frequency on various cores and keep within the power budget. this is ideal.arashi - Wednesday, March 31, 2021 - link
This belongs in r/ConfidentlyIncorrect and r/IAmVerySmart, anyone who thinks coding for AVX512 PROPERLY is doable by "any CS/CE major graduate worth their salt" would be laughed out of the industry.Hifihedgehog - Wednesday, March 31, 2021 - link
Exactly. The real reason for the nonsensical wall of text is SystemsBuilder is trying desperately to overexplain things to put lipstick on a pig. And he repeats himself too like I am listening to an automated bot caught in a recursive loop which is quite funny actually.SystemsBuilder - Wednesday, March 31, 2021 - link
So you are a CE major, have you actually tried to program in AVX 512? If not, try to do a matrix by matrix multiplication of 16x16 FP32 matrices for instance and come back. You'll notice incredible performed increase. It's not lipstick on a pig, it actually is very powerful, especially computing through large volumes of related data SIMD style.Meteor2 - Saturday, April 17, 2021 - link
Disappointing response. You throw insults but not rebuttals.Me thinks SB has a point.
SystemsBuilder - Wednesday, March 31, 2021 - link
really? any you are one CS graduate? have you tried?MS - Tuesday, March 30, 2021 - link
What the he'll is that supposed to mean that you can't you can't get the frequency at 10 nm and therefore you have to stick with the 14 nm node? That's pure nonsense, AND is at 7 nm and they are getting the target frequencies. Maybe stop spreading the Coolaid and call a spade a spade....