Intel Rocket Lake (14nm) Review: Core i9-11900K, Core i7-11700K, and Core i5-11600K
by Dr. Ian Cutress on March 30, 2021 10:03 AM EST- Posted in
- CPUs
- Intel
- LGA1200
- 11th Gen
- Rocket Lake
- Z590
- B560
- Core i9-11900K
CPU Tests: Microbenchmarks
Core-to-Core Latency
As the core count of modern CPUs is growing, we are reaching a time when the time to access each core from a different core is no longer a constant. Even before the advent of heterogeneous SoC designs, processors built on large rings or meshes can have different latencies to access the nearest core compared to the furthest core. This rings true especially in multi-socket server environments.
But modern CPUs, even desktop and consumer CPUs, can have variable access latency to get to another core. For example, in the first generation Threadripper CPUs, we had four chips on the package, each with 8 threads, and each with a different core-to-core latency depending on if it was on-die or off-die. This gets more complex with products like Lakefield, which has two different communication buses depending on which core is talking to which.
If you are a regular reader of AnandTech’s CPU reviews, you will recognize our Core-to-Core latency test. It’s a great way to show exactly how groups of cores are laid out on the silicon. This is a custom in-house test built by Andrei, and we know there are competing tests out there, but we feel ours is the most accurate to how quick an access between two cores can happen.
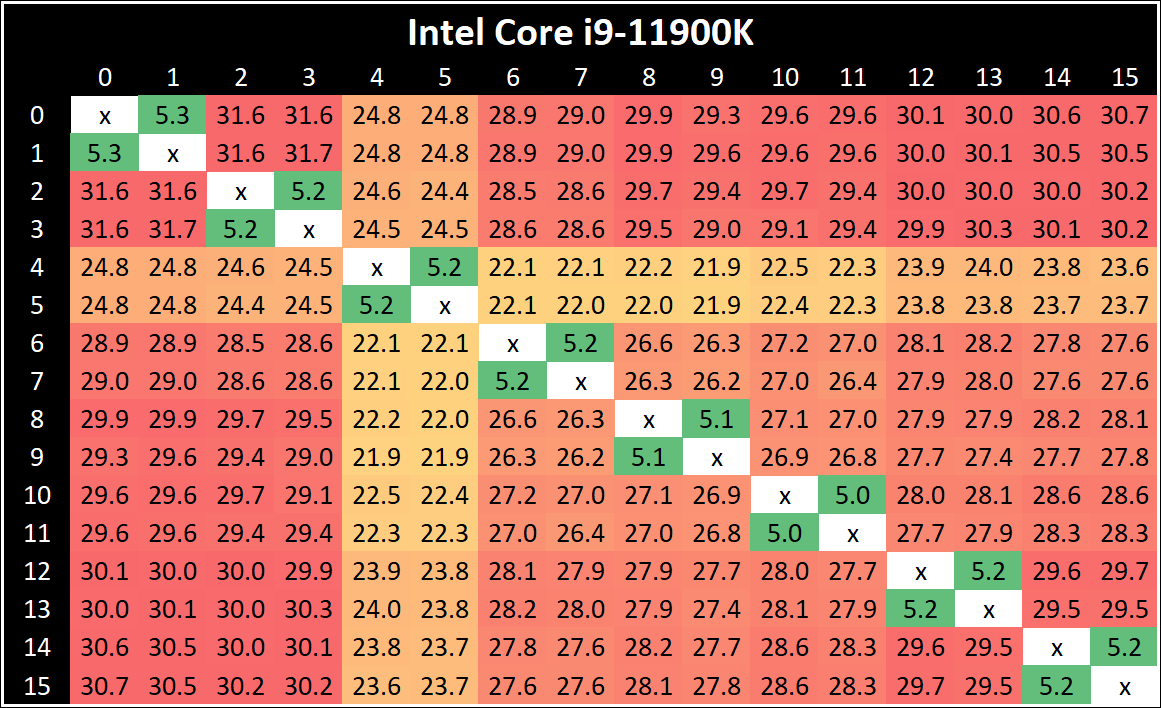
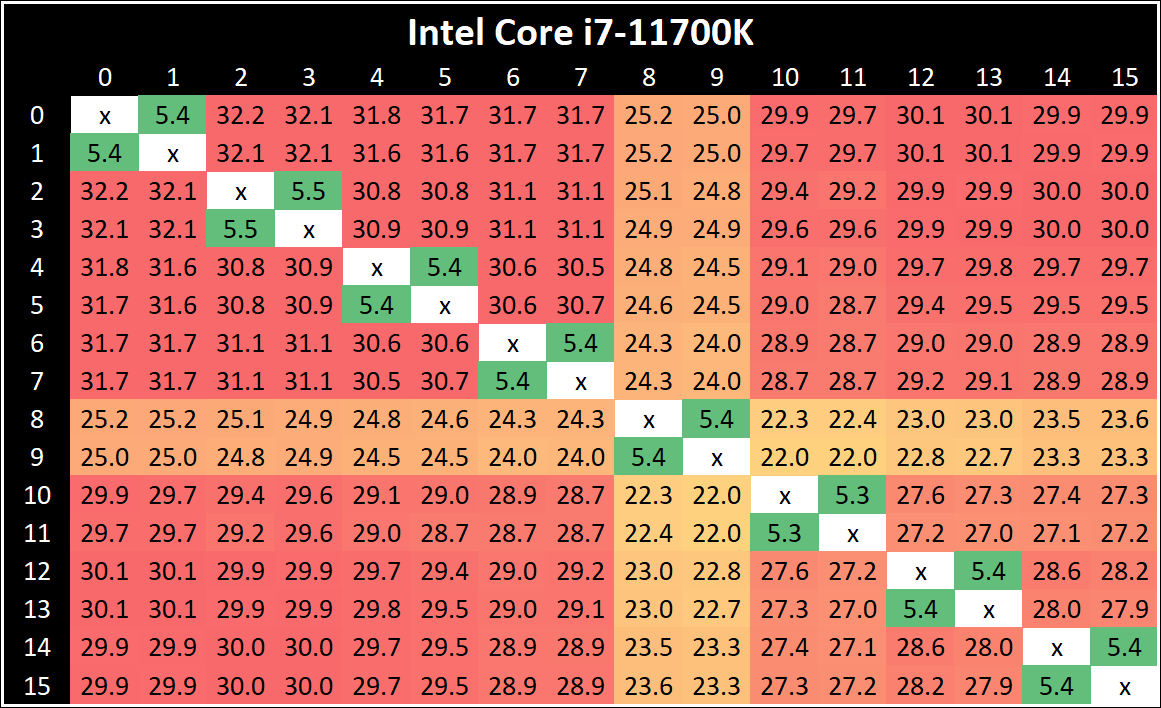

All three CPUs exhibit the same behaviour - one core seems to be given high priority, while the rest are not.
Frequency Ramping
Both AMD and Intel over the past few years have introduced features to their processors that speed up the time from when a CPU moves from idle into a high powered state. The effect of this means that users can get peak performance quicker, but the biggest knock-on effect for this is with battery life in mobile devices, especially if a system can turbo up quick and turbo down quick, ensuring that it stays in the lowest and most efficient power state for as long as possible.
Intel’s technology is called SpeedShift, although SpeedShift was not enabled until Skylake.
One of the issues though with this technology is that sometimes the adjustments in frequency can be so fast, software cannot detect them. If the frequency is changing on the order of microseconds, but your software is only probing frequency in milliseconds (or seconds), then quick changes will be missed. Not only that, as an observer probing the frequency, you could be affecting the actual turbo performance. When the CPU is changing frequency, it essentially has to pause all compute while it aligns the frequency rate of the whole core.
We wrote an extensive review analysis piece on this, called ‘Reaching for Turbo: Aligning Perception with AMD’s Frequency Metrics’, due to an issue where users were not observing the peak turbo speeds for AMD’s processors.
We got around the issue by making the frequency probing the workload causing the turbo. The software is able to detect frequency adjustments on a microsecond scale, so we can see how well a system can get to those boost frequencies. Our Frequency Ramp tool has already been in use in a number of reviews.
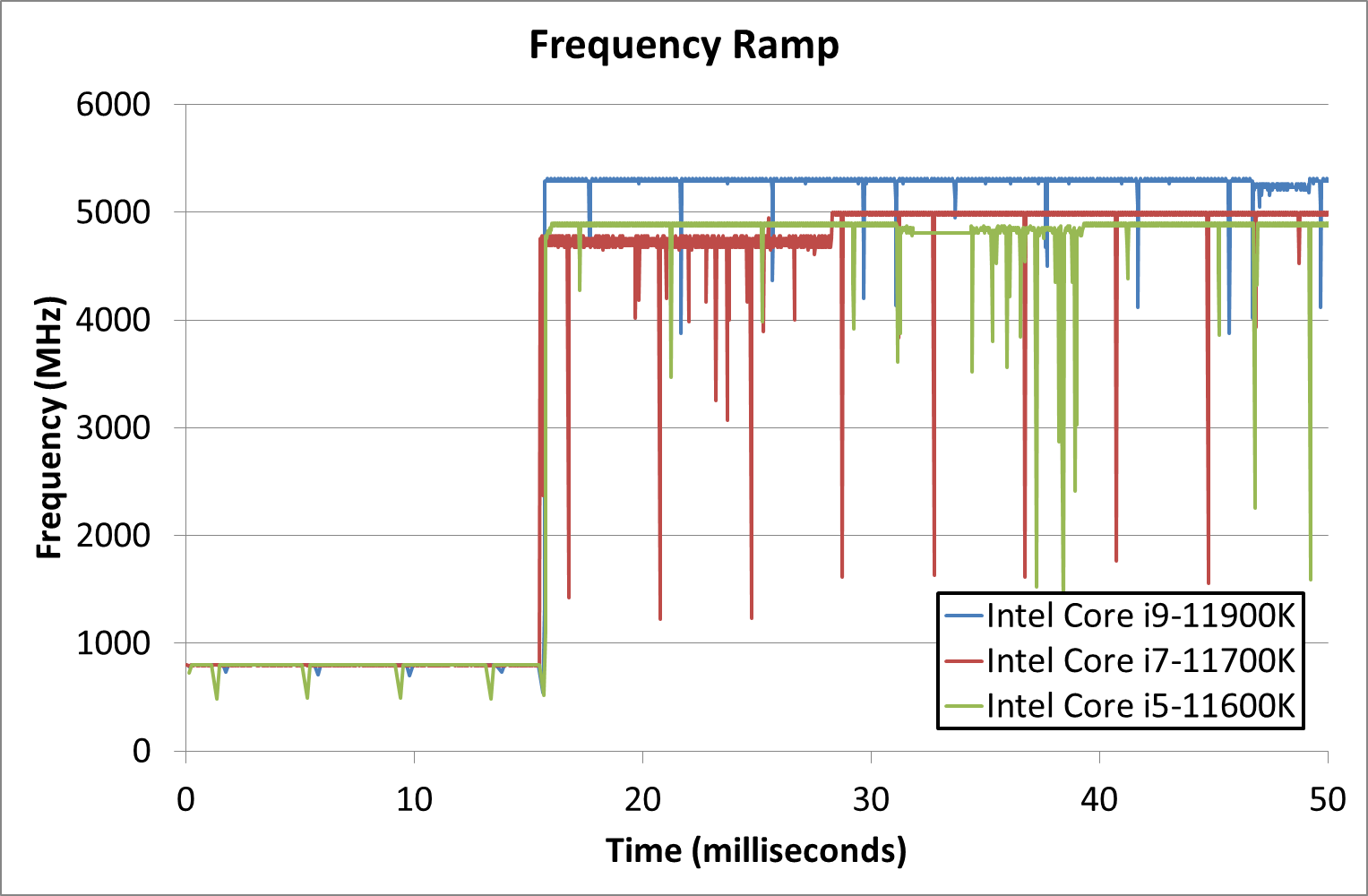
From an idle frequency of 800 MHz, It takes ~16 ms for Intel to boost to the top frequency for both the i9 and the i5. The i7 was most of the way there, but took an addition 10 ms or so.








279 Comments
View All Comments
SystemsBuilder - Wednesday, March 31, 2021 - link
and you are a Computer Science graduate? What Linus T. is saying is that AVX-512 is a power hog and he is right about that. Linus T. is not saying that "a couple dozen or so people" are able to program it. Power requirements and programing hardness are 2 different things.On the second point, I 100% stand by that any decent Computer Science/Engineering graduate should be able to program AVX-512 effectively (overcoming hardness not power requirements).
Also, I do program AVX-512 and I 100% stand by what I said. You just need to know what you are doing and vectorize algorithms. If you use the good old sequential algorithms you will not archive anything with AVX-512, but it you vectorize you're classical algorithms you will also achieve >100% benefits in many inner loops in so called mainstream programming. AVX-512 can give you 2x uplift if you know how to utilize both FMA units on port 0+1 and 5 and it's not hard.
Lastly, with decent negative AVX-512 offsets in BIOS, you can bring down the power utilization to ok levels AND still get 2x improvements in the inner loops (because of vectorized algorithmic improvement).
Hifihedgehog - Wednesday, March 31, 2021 - link
> and you are a Computer Science graduate?No, I am a Computer Engineering graduate. Sorry, but you are grasping at straws. Plus you are overcomplicating the obvious to try to be an Intel apologist. Just see this and this. Read it and weep. Intel flopped big time this release:
https://i.imgur.com/HZVC03T.png
https://i.imgflip.com/53vqce.jpg
SystemsBuilder - Wednesday, March 31, 2021 - link
So fellow CS/CE grad. I'm not arguing that AVX-512 is a power hog (it is) or that the AVX-512 offsets slows down the rest of the CPU (they do). I am arguing the premise that AVX-512 is supposed to be so incredibly hard to do that only "couple dozen or so people" can do is wrong today - Skylake-X with AVX-512 was launched 2017 for heaven's sake. Surely, I can't be the only CS/CE guy how figured it out by now. I mean really? When Ian wrote what Keller said (and keep on writing it) that that this AVX-512 is sooo hard to do that only a few guys on the planet can do it well, my reaction was "let's see about that". I mean come on guys, really!SystemsBuilder - Wednesday, March 31, 2021 - link
More specifically Linus is concerned that because you need to use negative offsets to keep the power utilization down when engaging AVX-512 it slows down everything else going on. i.e. AVX-512 power requirements overall CPU impact. The new cores designs (already Cypress Cove maybe? but Sapphire Rapids definitely!) will allow AVX-512 workloads to run at one frequency (with lower negative offsets that for instance Skylake-X) and non AVX-512 workloads at a different frequency on various cores and keep within the power budget. this is ideal.arashi - Wednesday, March 31, 2021 - link
This belongs in r/ConfidentlyIncorrect and r/IAmVerySmart, anyone who thinks coding for AVX512 PROPERLY is doable by "any CS/CE major graduate worth their salt" would be laughed out of the industry.Hifihedgehog - Wednesday, March 31, 2021 - link
Exactly. The real reason for the nonsensical wall of text is SystemsBuilder is trying desperately to overexplain things to put lipstick on a pig. And he repeats himself too like I am listening to an automated bot caught in a recursive loop which is quite funny actually.SystemsBuilder - Wednesday, March 31, 2021 - link
So you are a CE major, have you actually tried to program in AVX 512? If not, try to do a matrix by matrix multiplication of 16x16 FP32 matrices for instance and come back. You'll notice incredible performed increase. It's not lipstick on a pig, it actually is very powerful, especially computing through large volumes of related data SIMD style.Meteor2 - Saturday, April 17, 2021 - link
Disappointing response. You throw insults but not rebuttals.Me thinks SB has a point.
SystemsBuilder - Wednesday, March 31, 2021 - link
really? any you are one CS graduate? have you tried?MS - Tuesday, March 30, 2021 - link
What the he'll is that supposed to mean that you can't you can't get the frequency at 10 nm and therefore you have to stick with the 14 nm node? That's pure nonsense, AND is at 7 nm and they are getting the target frequencies. Maybe stop spreading the Coolaid and call a spade a spade....