Understanding the Cell Microprocessor
by Anand Lal Shimpi on March 17, 2005 12:05 AM EST- Posted in
- CPUs
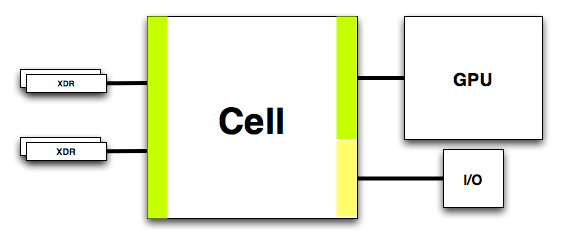
Cell’s On-Die Memory Controller
For years, we’ve known that Rambus’ memory and interface technology is well ahead of the competition. The problem is that it has never been implemented well on a PC before. The Rambus brand received a fairly negative connotation during the early days of RDRAM on the PC, and things worsened even more for the company’s brand with the Rambus vs. the DDR world lawsuits.Rambus has had success in a lot of consumer electronics devices, such as HDTVs and the Playstation 2, so when Cell was announced to make heavy use of Rambus technologies, it wasn’t too surprising. As we’ve reported before, Rambus technology is used in about 90% of the signaling pins on Cell. The remaining 10% are mostly test pins, so basically, Rambus handles all data going in and out of the Cell processor. They do so in two ways:
First off, Cell includes an on-die dual channel XDR memory controller, each channel being 36-bits wide (32-bits with ECC). Cell’s XDR memory bus runs at 400MHz, but XDR memory transfers data at 8 times the memory bus clock - meaning that you get 3.2GHz data signaling rates. The end result is GPU-like memory bandwidth of 25.6GB/s. As we’ve mentioned in our coverage of this year’s Spring IDF, memory bandwidth requirements increase tremendously as you increase the number of processor cores - with 9 total in Cell, XDR is the perfect fit. Note that the GeForce 6800GT offers 32GB/s of memory bandwidth just to its GPU, so it would not be too surprising to see the Playstation 3’s GPU paired up with its own local memory as well as being able to share system memory and bandwidth.

The block labeled MIC is the XDR memory controller, and the XIO block is the physical layer - all of the input receivers and output drivers are in the XIO block. Data pipelines are also present in the XIO block.
Cell’s On-Die FlexIO Interface
The other important I/O aspect of Cell is also controlled by Rambus - the FlexIO interface. Cell features two configurable FlexIO interfaces, each being 48-bits wide with 6.4GHz data signaling rates.
The BEI block is effectively the North Bridge interface, while the FlexIO block is the physical FlexIO layer.
One potential implementation of Cell’s configurable FlexIO interface.
In Playstation 3, you can pretty much expect a good hunk of this bandwidth to be between NVIDIA’s GPU and the Cell processor, but it also can be used for some pretty heavy I/O interfaces.
One of the major requirements in any high performance game console is bandwidth, and thanks to Rambus, Cell has plenty of it.








70 Comments
View All Comments
scrotemaninov - Thursday, March 17, 2005 - link
#23: True, but I believe that when the SPE's access the outside memory they go through the cache. Sure it's a lower coherancy than we're used to but it's not much worse.Houdani - Thursday, March 17, 2005 - link
18: Top Drawer Post.20: Thanks for the links!
fitten - Thursday, March 17, 2005 - link
"Given the speed of the interconnect and the fact that it is cache-coherant,"Only the PPC core has cache. The individual SPEs don't have cache - they have scratchpad RAM.
#22: I believe the PPC core is a dual issue core that just happens to be 2xSMT.
AndyKH - Thursday, March 17, 2005 - link
Great article.Anand, Could you please clarify something:
I had the impression that the PPE was a SMT processor in the sense that it had to be executing 2 threads in order to issue 2 instructions per clock. In other words: I didn't think the PPE control logic could decide to issue 2 instructions from the same thread at any given clock tick, but rather that it absolutely needed an instruction from each thread to issue two instructions.
After reading the article, I don't assume my impression is right, but a comment from you would be nice.
As I come to think about it, my impression is rather identical to 2 seperate single thread in-order cores. :-)
Koing - Thursday, March 17, 2005 - link
Cell looks VERY interesting.Any of you guys seen Devil May Cry 3 on the PS2? Looks great imo same with T5 and GT4.
Cell at first will be tough like most consoles. BUT eventually THE developers will get around it and make some very solidly good looking games.
Lets hope they are innovative and not just rehashed graphics and nothing else.
Thanks for the great article.
Koing
scrotemaninov - Thursday, March 17, 2005 - link
I really hate just dumping loads of links, but this basically is the available content on the CELL.http://arstechnica.com/articles/paedia/cpu/cell-1....
http://arstechnica.com/articles/paedia/cpu/cell-2....
http://realworldtech.com/page.cfm?ArticleID=RWT021...
http://www.blachford.info/computer/Cells/Cell0.htm...
http://www.realworldtech.com/page.cfm?ArticleID=RW...
http://www.hpcaconf.org/hpca11/papers/25_hofstee-c...
http://www.hpcaconf.org/hpca11/slides/Cell_Public_... (slides)
mrmorris - Thursday, March 17, 2005 - link
Brilliant article, there are few places for in-depth hardcore technology presentations but Anandtech never fails.scrotemaninov - Thursday, March 17, 2005 - link
Real concurrency is hard to do for the programmers. It's a real pain to get it right and it's hard to debug. Systematic analysis just gets too complex as there are just too many states, you end up with a huge graph/markov-model and it's just impossible to solve it tractably.Superscalar and SMT just try to increase ILP at the CPU level without burdening the programmer or compiler-writer. However, we've pretty much come to the end of getting a CPU to go faster - at 5GHz, LIGHT travels 6cm between clocks, and an electic PD will travel slower. As it is, in the P4 pipeline, there are at least 2 stages which are simply there to allow signals to propogate across the chip. Clearly, going faster in Hz isn't going to make the pipeline go faster.
So the ONLY thing that they can do now is to put lots of cores on the same chip and then we're going to have to deal with real concurrency. IBM/Sony are doing it now with CELL and Intel will do it in a few years. It's going to happen regardless. What we need is languages which can support real concurrency. The Java Memory Model is an almost ideal fit for the CELL, but other aspects don't work out so well, maybe. We need Pi-calculus/Join-calculus constructs in languages to be able to really deal with these cpus efficiently.
Your comments about CELL not being general purpose enough are a little wrong. IBM /already/ has the CELL in workstations and are evaluating applications that will work well. Given the speed of the interconnect and the fact that it is cache-coherant, I think we'll be seeing super-computers based on many CELLs, it's an almost ideal fit (as it is, you've almost got ccNUMA on a single chip). Also, bear in mind that this is IBM's 5th (or 6th?) generation of SMT in the PPE - they've been at it MUCH longer than Intel - IBM started it in the mid-90s around the same time that the Alpha crew were working on the EV8 which was going to have 8-way thread-level parallelism (got canned sadly).
Also, if you look at IBMs heavy CPUs - the POWER5, that has SMT and dispatches in groups of 8 instructions, not the 3/4 that AMD/Intel manage.
What I'm saying here, is that sure, the SPEs don't have BPTs of BTBs, they're all 2-way dispatch and not greater, but, they all run REALLY fast, they have short pipelines (so the pain of the branch misprediction won't be so bad), and, IBM have had software branch prediction available since the POWER4, so they've been at it a few years and must have decided that compilers really can successfully predict branch directions.
Backwards compatibility doesn't matter. Sure, Microsoft took several years to support AMD64 but that didn't stop take up of the platform - everyone just ran Linux on it (well, everyone who wanted to use the 64bit CPU they'd bought). It'll only be a few months after the CELL is out that we'll have to wait until Linux can be built on it. 100quid says Microsoft will never support it.
Frankly, considering that it's far more likely to go into super-computer or workstation environments, no one there gives a damn about backwards compatibility or Windows support. No one in those environments /wants/ a damn paper clip.
Reflex - Thursday, March 17, 2005 - link
#14: Replace 'lazy developers' with 'developers on a budget' and you will have a true statement. Its not an issue of laziness, its an issue of having the budget to optimize fully for a platform.GhandiInstinct - Thursday, March 17, 2005 - link
Wow Super CPU and SUPER RAMBUS? AHHHH!This will replace my computer. PS3 that is.