The Snapdragon 888 vs The Exynos 2100: Cortex-X1 & 5nm - Who Does It Better?
by Andrei Frumusanu on February 8, 2021 3:00 AM EST- Posted in
- Mobile
- Samsung
- Qualcomm
- Smartphones
- SoCs
- Snapdragon 888
- Exynos 2100
SPEC - Single Threaded Performance & Power
Moving onto performance of the new CPU cores, something I’ve actually been quite excited about this generation, particularly because this year we hadn’t been able to do a proper in-depth performance preview of the Snapdragon 888 like we usually do on previous years.
Before we go into the results, I wanted to point out some discrepancies between the Exynos 2100 and Snapdragon 888 Galaxy S21 Ultra devices, particularly regarding clock frequencies under load: I’ve noted that the Exynos 2100 CPUs are extremely prone to throttling, in a quite drastic fashion compared my Snapdragon 888 unit. When tracking the average frequencies under SPEC, benchmarking the Exynos 2100 S21 Ultra under my typical peak performance conditions where I place the phone over a 140mm fan to keep it cool, the X1 cores were still throttling quite significantly even though the phone was only luke-warm.
The following are precise mean frequencies for the SPEC workloads, both under my usual fan-cooled conditions, as well as putting the S21 Ultra in my freezer:
| Cortex-X1 Average Workload Frequency | ||||
| S21 Ultra (Exynos 2100) Fan |
S21 Ultra (Exynos 2100) Freezer |
S21 Ultra (Snapdragon 888) Fan |
||
| 400.perlbench | 2613 | 2845 | 2826 | |
| 401.bzip2 | 2690 | 2904 | 2841 | |
| 403.gcc | 2688 | 2905 | 2839 | |
| 429.mcf | 2744 | 2912 | 2841 | |
| 445.gobmk | 2701 | 2908 | 2841 | |
| 456.hmmer | 2534 | 2752 | 2841 | |
| 458.sjeng | 2684 | 2912 | 2841 | |
| 462.libquantum | 2469 | 2857 | 2841 | |
| 464.h264ref | 2602 | 2901 | 2841 | |
| 471.omnetpp | 2756 | 2912 | 2842 | |
| 473.astar | 2667 | 2909 | 2841 | |
| 483.xalancbmk | 2668 | 2909 | 2841 | |
| 433.milc | 2369 | 2759 | 2842 | |
| 444.namd | 2603 | 2912 | 2841 | |
| 447.dealII | 2721 | 2889 | 2841 | |
| 450.soplex | 2573 | 2883 | 2841 | |
| 453.povray | 2544 | 2769 | 2841 | |
| 470.lbm | 2273 | 2628 | 2812 | |
| 482.sphinx3 | 2437 | 2709 | 2747 | |
The fan-cooled results are quite horrible, with the chip not sustaining the full 2.91GHz for any of the workloads. In this situation, in fact most of the tests barely run at 2912MHz, with most of the time the X1 cores being resident at 2600 or 2496MHz, with many tests going down to 2184MHz for periods of time.
Putting the device in the freezer (with a sock around the bottom part of the phone as to not damage the battery from it getting too cold), resulted in skin temperature hot-spots of around 6 to 10°C. Even under such unrealistic test conditions, the phone wasn’t able to sustain its peak frequency for many workloads, which is quite puzzling and worrying.
This Exynos S21 Ultra unit was quite unlucky in terms of its chip bin as the CPUs received ASV bins of 2, 2, 2 across the little, middle, and big cores. I’ve got another regular Galaxy S21 with another Exynos chip, which had slightly better bins of 4, 4, 3. While this device performed better and was slightly more efficient than the S21 Ultra, it was still significantly worse than the Snapdragon 888 Galaxy S21 Ultra, which had no issues to sustain near its 2841MHz peak frequency for the vast majority of workloads.
The following results are from the freezer-run Exynos S21 Ultra, as we’re attempting to analyse peak performance and the X1 cores themselves as well.
We use SPEC2006 for mobile devices still as it’s still relevant and we have a good understanding of the workloads. The benchmark is deprecated in favour of SPEC2017, which we hope to move to in the coming months. For the Android devices, this data-set is on a new NDK 22 compile as it resolves some performance discrepancies in our past data. We run simple and straightforward -Ofast flags.

In SPECint2006, we can see the new Cortex-X1 cores in both the Snapdragon 888 and Exynos 2100 perform a notch above the previous generation A77-cores, with particularly some larger jumps in tests such as 403.gcc and 464.h264ref.
The Snapdragon 888 in the majority of tests is able to take the lead, even though for the integer benchmarks the Exynos 2100 was mostly able to retain frequencies near 2.9GHz.
Qualcomm’s lower latency memory subsystem, as well as the advantage of the 1MB L2 cache are quite obvious here as it’s able to overcome, and outpace the clock frequency differences.
It’s to be noted that HiSilicon’s Kirin 9000 is still able to keep up with the new chips in quite a few of the workloads – the Kirin’s 3.13GHz clock frequency as well as an outstanding memory subsystem fall in its favour.
In terms of power and efficiency, it’s very obvious that the Exynos 2100 falls behind the Snapdragon 888. The chip uses more power, and it being slower, means it’s also taking up more energy to complete the tasks.
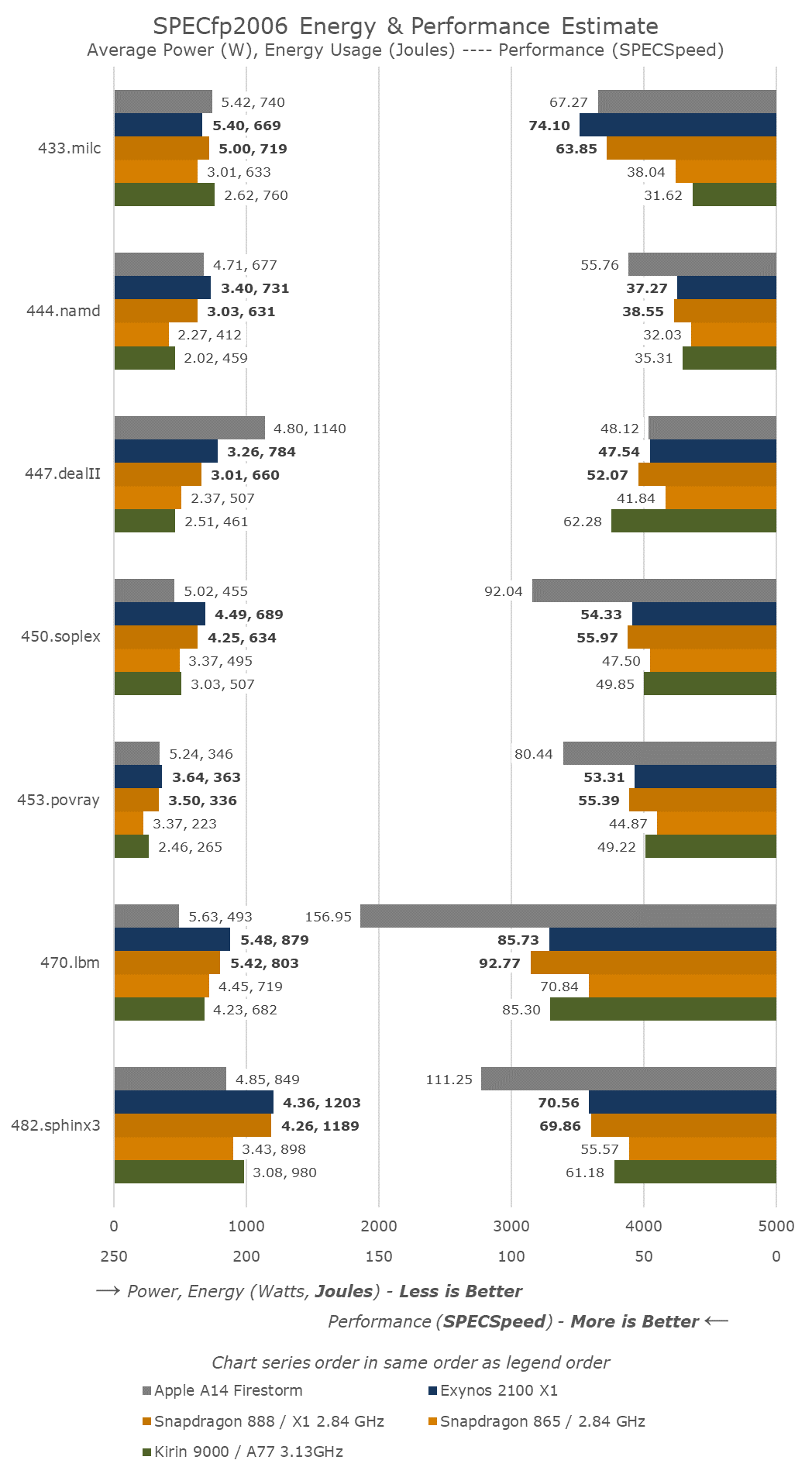
In SPECfp2006, the Exynos 2100 actually manages to score a few wins against the Snapdragon 888, but again falls behind in others as it has to throttle.
In 433.milc, the new X1 chips are posting gargantuan generational performance bumps, but which comes at a cost of power consumption in excess of 5W – whatever Arm did here this generation, it caught up and surpassed Apple in this one test.

For more extensive performance comparisons to past SoCs, such as the Exynos 990 I’ve updated our historical SPEC mobile data-set in the above large graph.
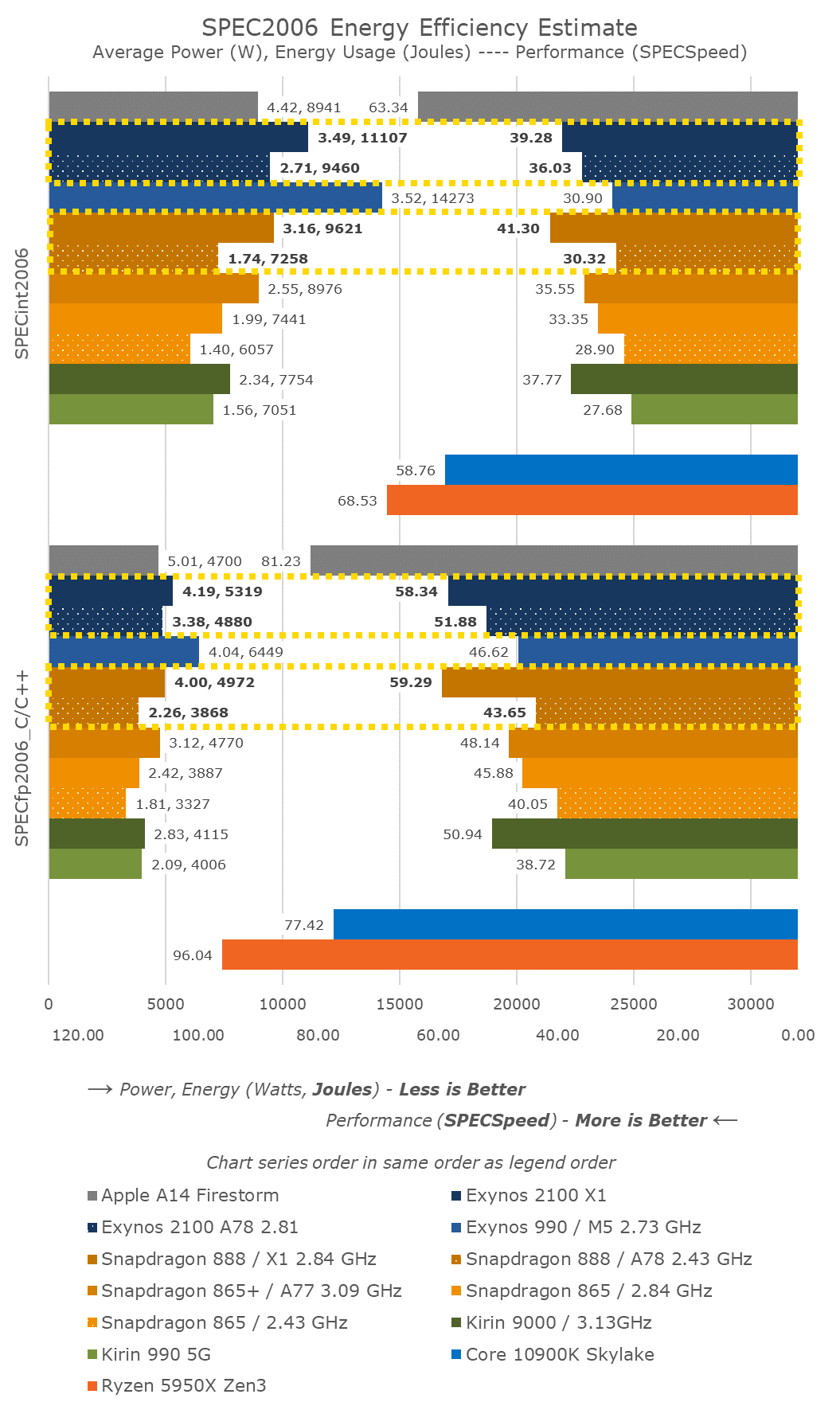
In the aggregate results scores, there’s a multitude of points we need to analyse.
Starting off with the Exynos 2100 – generationally, the new X1 cores and the Exynos 2100 are able to beat the Exynos 990 and the M5 cores by 27% and 25% in the integer and floating-point results. Samsung had officially stated the new SoC would be 19% faster in single-threaded scenarios – which I immediately throught of as suspect, as the improvements should be larger than that. I’m glad that the marketing was overly conservative and that my initial instinct was correct here. Although the X1 cores don’t use much different power consumption compared to the M5 cores, because of their increased performance, they are more energy efficient, using 23% and 18% less energy than the M5.
Looking at those figures though, they seem quite a bit odd, as they’re not that great as we had expected from the X1 cores, especially since this is also on a process node upgrade. Wouldn’t the cancelled M6 cores still have been competitive here?
The Snapdragon 888 results put things into context – it’s 5.1% and 1.6% faster than the Exynos 2100, however it’s also less power hungry, using 10% less power, resulting in being 14% more energy efficient. That’s not a large difference, but still sizeable given it’s the same CPU IP on the same process node.
Against the Snapdragon 865, the Snapdragon 888’s X1 cores are 23.8% and 29.2% faster. Because the cores are clocked at the same frequency, that’s also the generational IPC improvement that we’ve seen out of the new X1 cores. On the floating-point side, that essentially matches Arm’s 30% projection, however on the integer side it’s a few percentage points short – which is reasonable given that Arm’s figures had been projected with an 8MB L3 cache implementations which we didn’t see this generation.
Energy efficiency of the Snapdragon 888 is only slightly worse than that of the Snapdragon 865+, which means that battery life should still be good this generation.
The Cortex-A78 cores of the Snapdragon 888 are 4.9% and 8.9% faster than the Cortex-A77 middle cores of the Snapdragon 865. The power consumption comparison here isn’t apples-to-apples due to the new cores doubling up on the L2 cache. Arm states the A78 has an +7% IPC improvement and a -4% power reduction versus the A77. The Snapdragon 888’s middle cores however use +24% more power. Excluding the theory that that doubled L2 cache significantly raises power, we’re probably still seeing a notable process node power efficiency difference between Samsung’s 5LPE node and TSMC’s N7P node, with the Samsung node still falling behind.
This power efficiency difference can also be seen in the Cortex-A78 cores of the Exynos 2100. At 2.81GHz, they’re near the 2.84GHz A77 cores of the Snapdragon 865 – both having 512KB L2 caches. The Exynos’ middle cores here actually outperform the previous Snapdragon’s performance cores by 8 and 13%, they however use 35% more power to do so, which is a whole damn lot. In fact, the throttling behaviour on the Exynos wasn’t just limited to the X1 cores, as under normal conditions even these middle A78 cores had to ramp down from their peak frequencies.
This behaviour of these new designs using quite large amounts of power at these higher frequencies, however being seemingly similar power to TSMC’s process nodes at lower frequencies, points out to me that the 5LPE node has lower performance than TSMC’s N7P node. The fact that the Kirin 9000 here is still competitive in terms of performance, but at significant lower power and better energy efficiency, also points out that the N5 node is well superior to Samsung’s offering.
Generally, we can’t do much about the process – especially if TSMC isn’t able to produce enough volume to satisfy both Apple as well as Qualcomm at the same time. Today’s performance and efficiency figures also fell below our projected targets of the X1 cores. Lower frequencies and smaller caches are primary reasons as to why. I find it weird from both Qualcomm as well as SLSI to have employed 4MB L3 caches. SLSI has in the last few years wasted a ton of silicon on their custom cores, so them skimping out even on the L2 cache here on the X1 is a really weird change of philosophy. Qualcomm did a better job, but also not as aggressive as you’d expect from a company which wants to acquire Nuvia in order to strengthen their CPU portfolio.








123 Comments
View All Comments
mohamad.zand - Thursday, June 17, 2021 - link
Hi , thank you for your explanationDo you know how many transistors Snapdragon 888 and Exynos 2100 are?
It is not written anywhere
Spunjji - Thursday, February 11, 2021 - link
I'm not an expert by any means, but I think Samsung's biggest problem was always optimisation - they use lots of die area for computing resources but the memory interfaces aren't optimised well enough to feed the beast, and they kept trying to push clocks higher to compensate.The handy car analogy would be:
Samsung - Dodge Viper. More cubes! More noise! More fuel! Grrr.
Qualcomm / ARM - Honda Civic. Gets you there. Efficient and compact.
Apple - Bugatti Veyron. Big engine, but well-engineered. Everything absolutely *sings*.
Shorty_ - Monday, February 15, 2021 - link
you're right but you also don't really touch why Apple can do that and X86 designs can't. The issue is that uOP decoding on x86 is *awfully* slow and inefficient on power.This was explained to me as follows:
Variable-length instructions are an utter nightmare to work with. I'll try to explain with regular words how a decoder handles variable length. Here's all the instructions coming in:
x86: addmatrixdogchewspout
ARM: dogcatputnetgotfin
Now, ARM is fixed length (3-letters only), so if I'm decoding them, I just add a space between every 3 letters.
ARM: dogcatputnetgotfin
ARM decoded: dog cat put net got fin
done. Now I can re-order them in a huge buffer, avoid dependencies, and fill my execution ports on the backend.
x86 is variable length, This means I cannot reliably figure out where the spaces should go. so I have to try all of them and then throw out what doesn't work.
Look at how much more work there is to do.
x86: addmatrixdogchewspoutreading frame 1 (n=3): addmatrixdogchewspout
Partially decoded ops: add, , dog, , ,
reading frame 2 (n=4): matrixchewspout
Partially decoded ops: add, ,dog, chew, ,
reading frame 3 (n=5): matrixspout
Partially decoded ops: add, ,dog, chew, spout,
reading frame 4 (n=6): matrix
Partially decoded ops: add, matrix, dog, chew, spout,
Fully Expanded Micro Ops: add, ma1, ma2, ma3, ma4, dog, ch1, ch2, ch3, sp1, sp2, sp3
This is why most x86 cores only have a 3-4 wide frontend. Those decoders are massive, and extremely energy intensive. They cost a decent bit of transistor budget and a lot of thermal budget even at idle. And they have to process all the different lengths and then unpack them, like I showed above with "regular" words. They have excellent throughput because they expand instructions into a ton of micro-ops... BUT that expansion is inconsistent, and hilariously inefficient.
This is why x86/64 cores require SMT for the best overall throughput -- the timing differences create plenty of room for other stuff to be executed while waiting on large instructions to expand. And with this example... we only stepped up to 6-byte instructions. x86 is 1-15 bytes so imagine how much longer the example would have been.
Apple doesn't bother with SMT on their ARM core design, and instead goes for a massive reorder buffer, and only presents a single logical core to the programmer, because their 8-wide design can efficiently unpack instructions, and fit them in a massive 630μop reorder buffer, and fill the backend easily achieving high occupancy, even at low clock speeds. Effectively, a reorder buffer, if it's big enough, is better than SMT, because SMT requires programmer awareness / programmer effort, and not everything is parallelizable.
Karim Braija - Saturday, February 20, 2021 - link
Je suis pas sur si le benchmark SPENCint2006 est vraiment fiable, en plus je pense que ça fait longtemps que ce benchmark est là depuis un moment et je pense qu'il n'a plus bonne fiabilité, ce sont de nouveaux processeurs puissant. Donc je pense que ce n'est pas très fiable et qu'il ne dit pas des choses précises. Je pense que faut pas que vous croyez ce benchmark à 100%.serendip - Monday, February 8, 2021 - link
"Looking at all these results, it suddenly makes sense as to why Qualcomm launched another bin/refresh of the Snapdragon 865 in the form of the Snapdragon 870."So this means Qualcomm is hedging its bets by having two flagship chips on separate TSMC and Samsung processes? Hopefully the situation will improve once X1 cores get built on TSMC 5nm and there's more experience with integrating X1 + A78. All this also makes SD888 phones a bit pointless if you already have an SD865 device.
Bluetooth - Monday, February 8, 2021 - link
Why would they skimp on the cache. Was neural engine or something else with higher priority getting silicon?Kangal - Tuesday, February 9, 2021 - link
I think Samsung was rushing, and its usually easier to stamp out something that's smaller (cache takes alot of silicon estate). Why they rushed was due to a switch from their M-cores to the X-core, and also internalising the 5G-radio.Here's the weird part, I actually think this time their Mongoose Cores would be competitive. Unlike Andrei, I estimated the Cortex-X1 was going to be a load of crap, and seems I was right. Having node parity with Qualcomm, the immature implementation that is the X1, and the further refined Mongoose core... it would've meant they would be quite competitive (better/same/worse) but that's not saying much after looking at Apple.
How do I figure?
The Mongoose core was a Cortex A57 alternative which was competitive against Cortex A72 cores. So it started as midcore (Cortex A72) and evolved into a highcore implementation as early as 2019 with the S9 when they began to get really wide, really fast, really hot/thirsty. Those are great for a Large Tablet or Ultrabook, but not good properties for a smaller handheld.
There was a precedence for this, in the overclocked QSD 845 SoCs, 855+, and the subpar QSD 865 implementation. Heck, it goes all the way back to 2016 when MediaTek was designing 2+4+4 core chipsets (and they failed miserably as you would imagine). I think when consumers buy these, companies send orders, fabs design them, etc... they always forget about the software. This is what separates Apple from Qualcomm, and Qualcomm from the rest. You can either brute-force your way to the top, or try to do things more cost/thermal efficiently.
Andrei Frumusanu - Tuesday, February 9, 2021 - link
> Unlike Andrei, I estimated the Cortex-X1 was going to be a load of crap, and seems I was right.The X1 *is* great, and far better than Samsung's custom cores.
Kangal - Wednesday, February 10, 2021 - link
First of all, apologies for sounding crass.Also, you're a professional in this field, I'm merely an enthusiast (aka Armchair Expert) take what I say with a grain of salt. So if you correct me, I stand corrected.
Nevertheless, I'm very unimpressed by big cores: Mongoose M5, to a lesser extent the Cortex-X1, and to a much Much much lesser extent the Firestorm. I do not think the X1 is great. Remember, the "middle cores" still haven't hit their limits, so it makes little sense to go even thirstier/hotter. Even if the power and thermal issues weren't so dire with these big-cores, the performance difference between the middle cores vs big cores is negligible, also there is no applications that are optimised/demand the big cores. Apple's big-core implementation is much more optimised, they're smarter about thermals, and the performance delta between it and the middle-cores is substantial, hence why their implementation works and why it favours compared to the X1/M5.
I can see a future for big-cores. Yet, I think it might involve killing the little-cores (A53/A55), and replacing it with a general purpose cores that will be almost as efficient yet be able to perform much better to act as middle-cores. Otherwise latency is always going to be an issue when shifting work from one core to another then another. I suspect the Cortex-X2 will right many wrongs of the X1, combined with a node jump, it should hopefully be a solid platform. Maybe similar to the 20nm-Cortex A57 versus the 16nm-Cortex A72 evolution we saw back in 2016. The vendors have little freedom when it comes to implementing the X1 cores, and I suspect things will ease up for X2, which could mean operating at reasonable levels.
So even with the current (and future) drawbacks of big-cores, I think they could be a good addition for several reasons: application-specific optimisations, external dock. We might get a DeX implementation that's native to Android/AOSP, and combined that with an external dock that provides higher power delivery AND adequate active-cooling. I can see that as a boon for content creators and entertainment consumers alike. My eye is on emulation performance, perhaps this brute-force can help stabilise the weak Switch and PS2 emulation currently on Android (WiiU next?).
iphonebestgamephone - Monday, February 15, 2021 - link
The improvement with the 888 in damonps2 and eggns are quite good. Check some vids on youtube.