The Snapdragon 888 vs The Exynos 2100: Cortex-X1 & 5nm - Who Does It Better?
by Andrei Frumusanu on February 8, 2021 3:00 AM EST- Posted in
- Mobile
- Samsung
- Qualcomm
- Smartphones
- SoCs
- Snapdragon 888
- Exynos 2100
Memory Subsystem & Latency: Quite Different
The memory subsystem comparisons for the Snapdragon 888 and Exynos 2100 are very interesting for a few couple of reasons. First of all – these new SoCs are the first to use new higher-frequency LPDDR5-6400 memory, which is 16% faster than that of last year’s LPDRR5-5500 DRAM used in flagship devices.
On the Snapdragon 888 side of things, Qualcomm this generation has said that they have made significant progress in improving memory latency – a point of contention that’s generally been a weak point of the previous few generations, although they always did keep improving things gen-on-gen.
On the Exynos 2100 side, Samsung’s abandonment of their custom cores also means that the SoC is now very different to the Exynos 990. The M5 used to have a fast-path connection between the cores and the memory controllers – exactly how Samsung reimplemented this in the Exynos 2100 will be interesting.
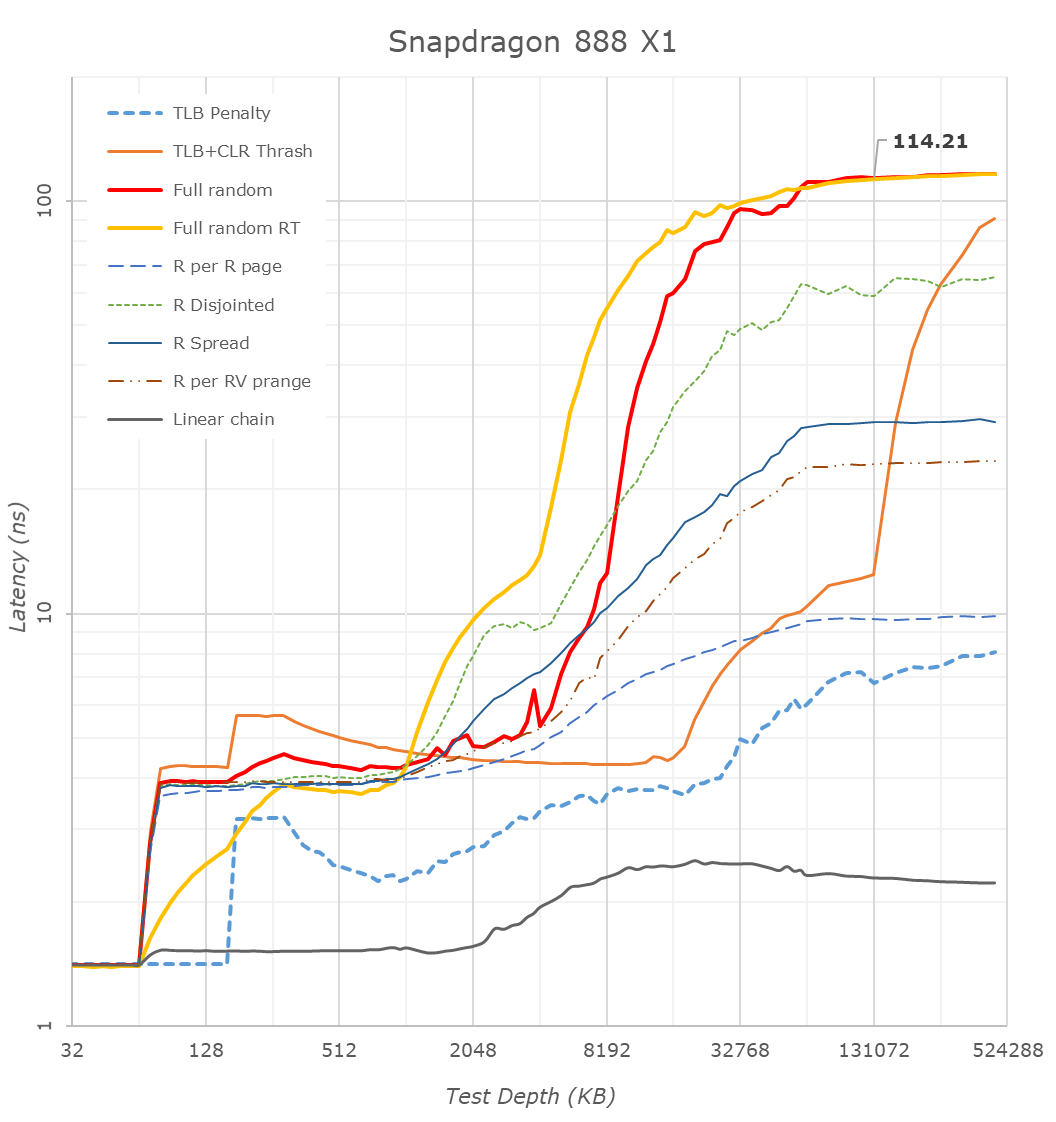
Starting things off with the new Snapdragon 888, we are seeing some very significant changes compared to the Snapdragon 865 last year. Full random memory latency went down from 138ns to 114ns, which is a massive generation gain given that Arm always quotes that 4ns of latency equals 1% of performance.
Samsung’s Exynos 2100 on the other hand doesn’t look as good: At around 136ns at 128MB test depth, this is quite worse than the Snapdragon 888, and actually a regression compared to the Exynos 990 at 131ns.
Looking closer at the cache hierarchies, we’re seeing 64KB of L1 caches for both X1 designs – as expected.
What’s really weird though is the memory patterns of the X1 and A78 cores as they transition from the L2 caches to the L3 caches. Usually, you’d expect a larger latency hump into the 10’s of nanoseconds, however on both the Cortex-X1 and Cortex-A78 on both the Snapdragon and Exynos we’re seeing L3 latencies between 4-6ns which is far faster than any previous generation L3 and DSU design we’ve seen from Arm.
After experimenting a bit with my patterns, the answer to this weird behaviour is quite amazing: Arm is prefetching all these patterns, including the “full random” memory access pattern. My tests here consist of pointer-chasing loops across a given depth of memory, with the pointer-loop being closed and always repeated. Arm seems to have a new temporal prefetcher that recognizes arbitrary memory patterns and will latch onto them and prefetch them in further iterations.
I re-added an alternative full random access pattern test (“Full random RT”) into the graph as alternative data-points. This variant instead of being pointer-chase based, will compute a random target address at runtime before accessing it, meaning it’ll be always a different access pattern on repeated loops of a given memory depth. The curves here aren’t as nice and they aren’t as tight as the pointer-chase variant because it currently doesn’t guarantee that it’ll visit every cache line at a given depth and it also doesn’t guarantee not revisiting a cache line within a test depth loop, which is why some of the latencies are lower than that of the “Full random” pattern – just ignore these parts.
This alternative patterns also more clearly reveals the 512KB versus 1MB L2 cache differences between the Exynos’ X1 core and the Snapdragon X1 core. Both chips have 4MB of L3, which is pretty straightforward to identify.
What’s odd about the Exynos is the linear access latencies. Unlike the Snapdragon whose latency grows at 4MB and remains relatively the same, the Exynos sees a second latency hump around the 10MB depth mark. It’s hard to see here in the other patterns, but it’s also actually present there.
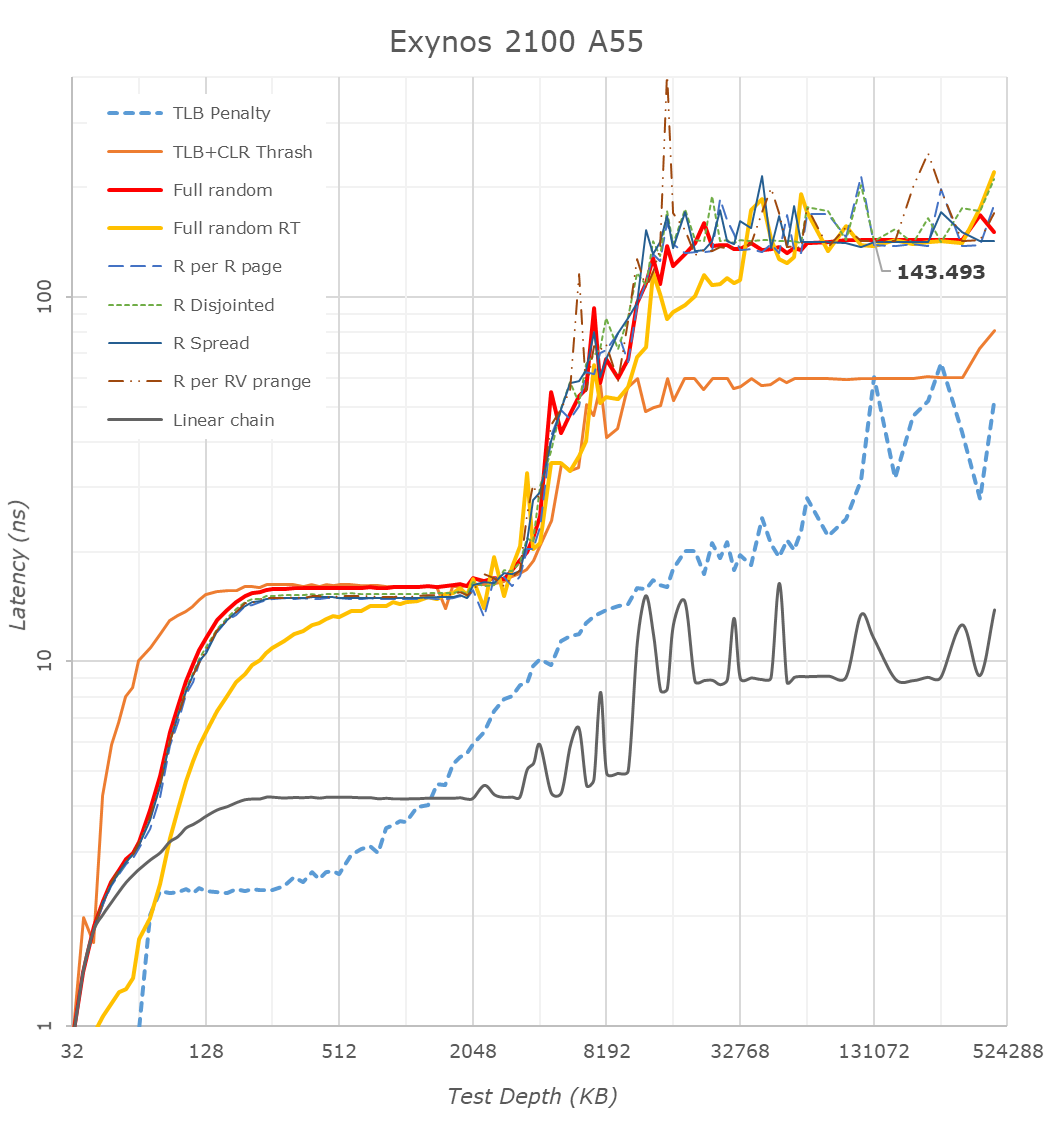
This post-4MB L3 cache hierarchy is actually easier to identify from the perspective of the Cortex-A55 cores. We see a very different pattern between the Exynos 2100 and the Snapdragon 888 here, and again confirms that there’s lowered latencies up until around 10MB depth.
During the announcement of the Exynos 2100, Samsung had mentioned they had improved and included “better cache memory”, which in context of these results seems to be pointing out that they’ve now increased their system level cache from 2MB to 6MB. I’m not 100% sure if it’s 6 or 8MB, but 6 seems to be a safe bet for now.
In these A55 graphs, we also see that Samsung continues to use 64KB L2 caches, while Qualcomm makes use of 128KB implementations. Furthermore, it looks like the Exynos 2100 makes available to the A55 cores the full speed of the memory controllers, while the Snapdragon 888 puts a hard limit on them, and hence the very bad memory latency, similarly to how Apple does the same in their SoCs when just the small cores are active.
Qualcomm seems to have completely removed access of the CPU cluster to the SoC’s system cache, as even the Cortex-A55 cores don’t look to have access to it. This might explain why the CPU memory latency this generation has been greatly improved – as after all, memory traffic had to do one whole hop less this generation. This also in theory would put less pressure on the SLC, and allow the GPU and other blocks to more effectively use its 3MB size.








123 Comments
View All Comments
iphonebestgamephone - Monday, February 15, 2021 - link
If its like you said and tsmc outsourced indians too, they are just better because they paid for the better workers.Wereweeb - Monday, February 8, 2021 - link
Process node performance has nothing to do with the nationality of the employees. It's just natural for different teams, fabs, equipment, techniques, etc... to show different results.And I doubt they would abandon investments into their silicon fabrication R&D, as they're basically the only other serious player for 3nm as of this moment (Others being stuck at 7nm).
They're behind the curve, but at least they're delivering new nodes (Differently from Intel and Global Foundries, two american fabs.)
Wereweeb - Monday, February 8, 2021 - link
Foundries*reuthermonkey1 - Monday, February 8, 2021 - link
This is becoming a very big issue for Android.With Qualcomm owning the US market for Android, and with Samsung's continued Exynos woes, Apple's SoC R&D will return big dividends in the next few years.
Toss3 - Monday, February 8, 2021 - link
How do you check the bin of the exynos chip? Is it the three numbers you see when booting into download mode?Monty1401 - Tuesday, February 9, 2021 - link
They no longer show in download mode, they can be accessed via the recovery>kernel logs, but I'm struggling to find it on device as the logs are massive and doesn't seem like it's possible to extract them without root to do a searchMonty1401 - Tuesday, February 9, 2021 - link
If you find them, let me know, pulled my hair out scrolling through logs and trying various adb commands1Silver5urfer - Monday, February 8, 2021 - link
Marketing runs the show as always. More power consumption at the expense of battery destruction like Apple battery issue. Which will force people to buy new shit again another year of $1000+ as long as people do not stop buying this shit for Fartnite and others, this will continue forever. Utter shame.About the Bootloader unlock, does S20 Exynos2100 have it still or the greedy pig samsung yanked that off too ?
I'm in the market right now to buy a phone with No hole / notch and SD card slot I have even forgone 3.5mm jack since I would get my LG service or something for the ESS anyways guess what ? None of them exist. Except Sony and ASUS which the latter is not in US market. Fucking bullshit really.
5j3rul3 - Monday, February 8, 2021 - link
Can I mention that "TSMC N7+ and TSMC N6 are BETTER than SAMSUNG 5LPE and SAMSUNG 4LPE"?Spunjji - Monday, February 8, 2021 - link
Thanks for the great research and write-up, Andrei. Looks like I still won't be looking to Samsung for my next upgrade, as I'm stuck with Exynos here in the UK. Shame!