The Ampere Altra Review: 2x 80 Cores Arm Server Performance Monster
by Andrei Frumusanu on December 18, 2020 6:00 AM EST- Posted in
- Servers
- Neoverse N1
- Ampere
- Altra
SPEC - Single-Threaded Performance
Starting off with SPECint2017, we’re using the single-instance runs of the rate variants of the benchmarks.
As usual, because there are not officially submitted scores to SPEC, we’re labelling the results as “estimates” as per the SPEC rules and license.
We compile the binaries with GCC 10.2 on their respective platforms, with simple -Ofast optimisation flags and relevant architecture and machine tuning flags (-march/-mtune=Neoverse-n1 ; -march/-mtune=skylake-avx512 ; -march/-mtune=znver2).
While single-threaded performance in such large enterprise systems isn’t a very meaningful or relevant measure, given that the sockets will rarely ever be used with just 1 thread being loaded on them, it’s still an interesting figure academically, and for the few use-cases which would have such performance bottlenecks. It’s to be remembered that the EPYC and Xeon systems will clock up to respectively 3.4GHz and 4GHz under such situations, while the Ampere Altra still maintains its 3.3GHz maximum speed.
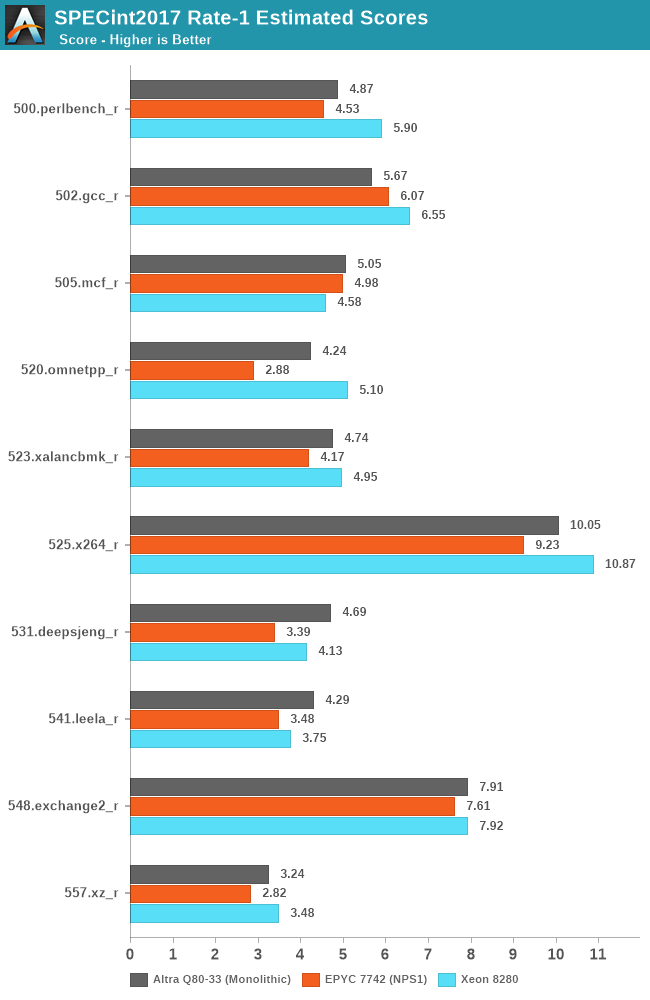
In SPECint2017, the Altra system is performing admirably and is able to generally match the performance of its counterparts, winning some workloads, while losing some others.
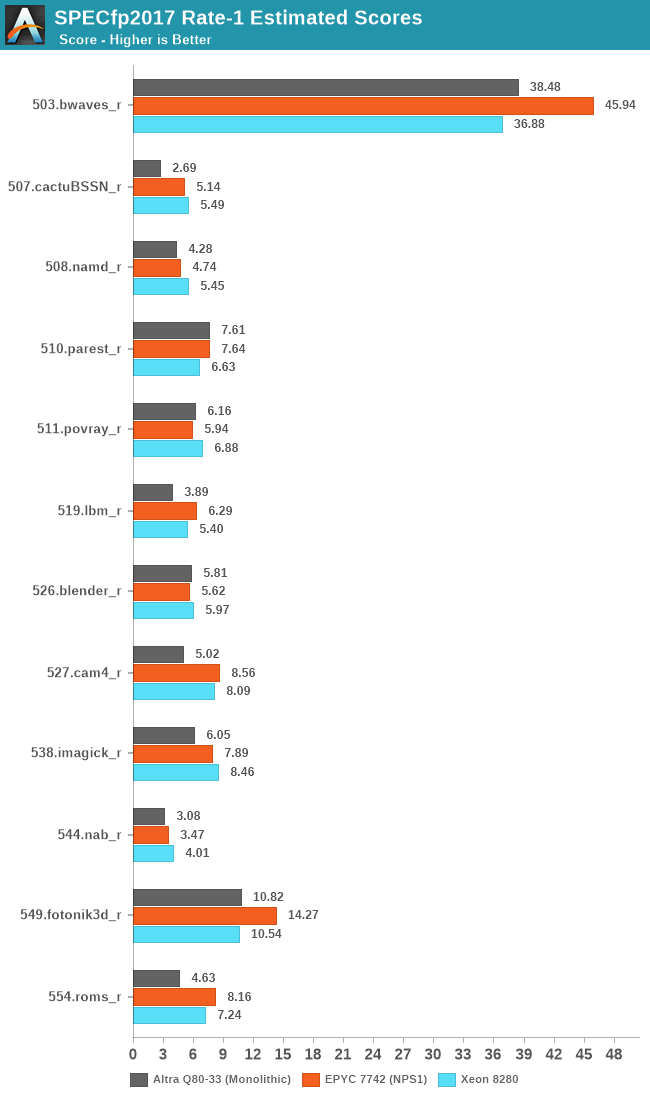
In SPECfp2017 the Neoverse-N1 cores seem to more generally fall behind their x86 counterparts. Particularly what’s odd to see is the vast discrepancy in 507.cactuBSSN_r where the Altra posts less than half the performance of the x86 cores. This is actually quite odd as the Graviton2 had scored 3.81 in the test. The workload has the highest L1D miss rate amongst the SPEC suite, so it’s possible that the neutered prefetchers on the Altra system might in some way play a more substantial role in this workload.
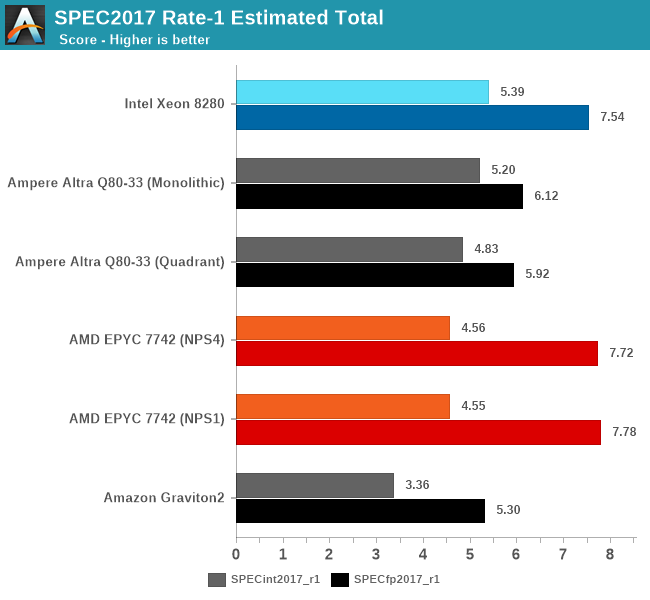
The Altra Q80-33 ends up performing extremely well and competitively against the AMD EPYC 7742 and Intel Xeon 8280, actually beating the EPYC in SPECint, although it loses by a larger margin in SPECfp. The Xeon 8280 still holds the crown here in this test due to its ability to boost up to 4GHz across two cores, clocking down to 3.8, 3.7, 3.5 and 3.3GHz beyond 2, 4, 8 and 20 cores active.
The Altra showcases a massive 52% performance lead over the Graviton2 in SPECint, which is actually beyond the expected 32% difference due to clock frequencies being at 3.3GHz versus 2.5GHz. On the other hand, the SPECfp figures are only ahead of 15% for the Altra. The prefetchers are really amongst the only thing that come to mind in regards to these differences, as the only other difference being that the Graviton2 figures were from earlier in the year on GCC 9.3. The Altra figures are definitely more reliable as we actually have our hands on the system here.
While on the AMD system the move from NPS1 to NPS4 hardly changes performance, limiting the Altra Q80-33 from a monolithic setup to a quadrant setup does incur a small performance penalty, which is unsurprising as we’re cutting the L3 into a quarter of its size for single-threaded workloads. That in itself is actually a very interesting experiment as we haven’t been able to do such a change on any prior system before.








148 Comments
View All Comments
Josh128 - Friday, December 18, 2020 - link
Did you see the chip package? Its the size of an EPYC package. Im extremely doubtful its only 350mm^2.mode_13h - Sunday, December 20, 2020 - link
Look at where they show the bottom of the heatsink and it's small contact area. That shows the actual die is much smaller.Spunjji - Monday, December 21, 2020 - link
Doubt all you want - they have to put the pins for the interfaces somewhere, and that doesn't change much regardless of die size.Gondalf - Friday, December 18, 2020 - link
Obviousy it is a cpu of niche, not high volume like Intel or AMD. With a so large die we will not see many of these around. As usual only volume matter in Server worldSo no worries for X86.
eastcoast_pete - Friday, December 18, 2020 - link
Actually, those are a bigger threat to x86 than ARM chips like the M1 in Personal Computers. Server x86/x64 CPUs ist where AMD and Intel make a lot of their money. The key question for this and similar Neoverse chips is software support. If you can run your database or whatever natively on an ARM-native OS like Linux, these are tempting. Now, if MS would release Exchange Server in native for ARM, the threat would be even bigger.Gondalf - Friday, December 18, 2020 - link
Agreed about software, but i don't see problems for x86 dominance.Major sin of this design is die size, around 800mm2 looking photos in the article. On 7nm it means a very low cpu output; this issue will become even worse on 5nm.
So it is not a matter how good is a SKU but who have the real volume in server world. In past decades we have seen a lot of better cpus than x86 puppies, but in spite of this they all have lost their way.
The winner scheme is "volume". This is the only parameter that gives the dominance of a solution over another ones, expecially today with several and several millions/year of server SKUs absorbed by the market.
Altra is not born to beat x86, at least not in this crazy, old style, incarnation. They need to follow AMD (and shortly Intel) path instead of they will never be relevant.
Actual and upcoming advanced processes are not done for these massive things.
scineram - Saturday, December 19, 2020 - link
It's less than half that, you absolute retard moron.Wilco1 - Friday, December 18, 2020 - link
Apple's move to Arm does hit Intel's bottom line by many billions. A large percentage of AWS is already Graviton as more big customers are moving to it (latest is Twitter). Oracle is going to use Ampere Altra, and Microsoft is claimed to develop their own Arm servers.As Goldalf said, volume matters in the server world, and they are moving to Arm.
Spunjji - Monday, December 21, 2020 - link
I love Gondalf posts. Minimum-effort confirmation bias ramblings.eastcoast_pete - Friday, December 18, 2020 - link
That was my question also! Who fabs it, and what is their yield. This thing is quite big. Does anyone know if they overprovision cores so they can use those with small, very partial defects? At that size and those numbers of transistors, even a tiny probability of a defect can mean that the great majority of chips ends up in the circular bin (garbage).