The Ampere Altra Review: 2x 80 Cores Arm Server Performance Monster
by Andrei Frumusanu on December 18, 2020 6:00 AM EST- Posted in
- Servers
- Neoverse N1
- Ampere
- Altra
SPEC - Single-Threaded Performance
Starting off with SPECint2017, we’re using the single-instance runs of the rate variants of the benchmarks.
As usual, because there are not officially submitted scores to SPEC, we’re labelling the results as “estimates” as per the SPEC rules and license.
We compile the binaries with GCC 10.2 on their respective platforms, with simple -Ofast optimisation flags and relevant architecture and machine tuning flags (-march/-mtune=Neoverse-n1 ; -march/-mtune=skylake-avx512 ; -march/-mtune=znver2).
While single-threaded performance in such large enterprise systems isn’t a very meaningful or relevant measure, given that the sockets will rarely ever be used with just 1 thread being loaded on them, it’s still an interesting figure academically, and for the few use-cases which would have such performance bottlenecks. It’s to be remembered that the EPYC and Xeon systems will clock up to respectively 3.4GHz and 4GHz under such situations, while the Ampere Altra still maintains its 3.3GHz maximum speed.
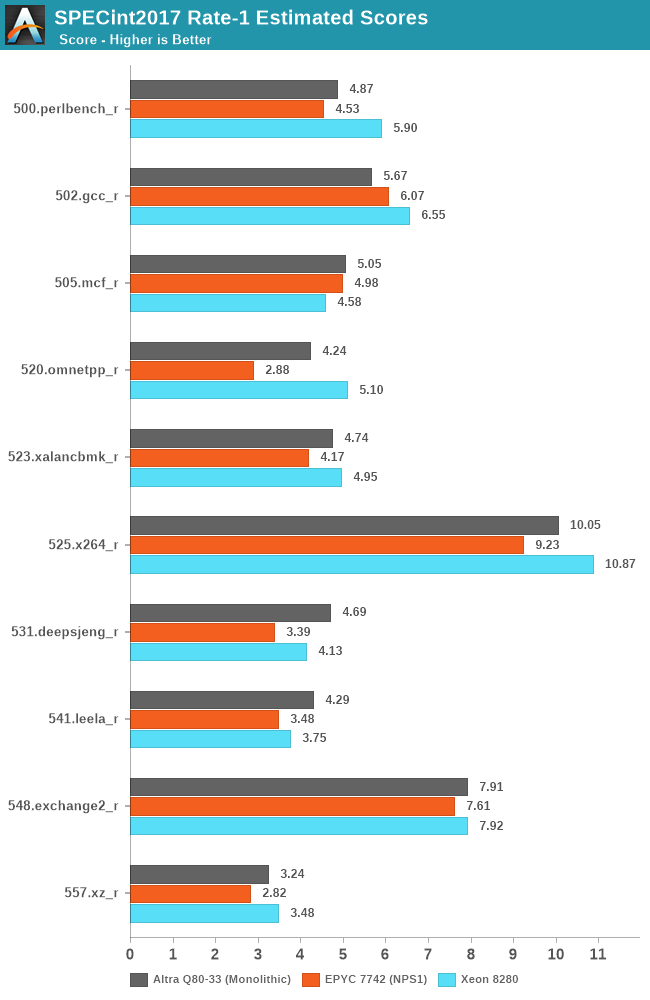
In SPECint2017, the Altra system is performing admirably and is able to generally match the performance of its counterparts, winning some workloads, while losing some others.
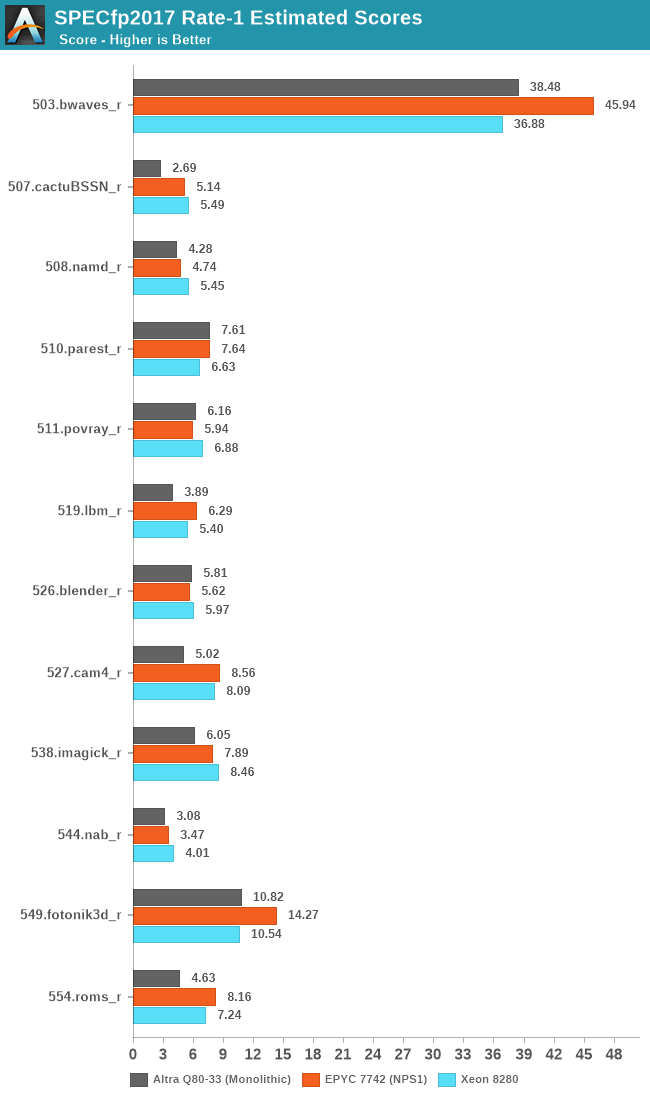
In SPECfp2017 the Neoverse-N1 cores seem to more generally fall behind their x86 counterparts. Particularly what’s odd to see is the vast discrepancy in 507.cactuBSSN_r where the Altra posts less than half the performance of the x86 cores. This is actually quite odd as the Graviton2 had scored 3.81 in the test. The workload has the highest L1D miss rate amongst the SPEC suite, so it’s possible that the neutered prefetchers on the Altra system might in some way play a more substantial role in this workload.
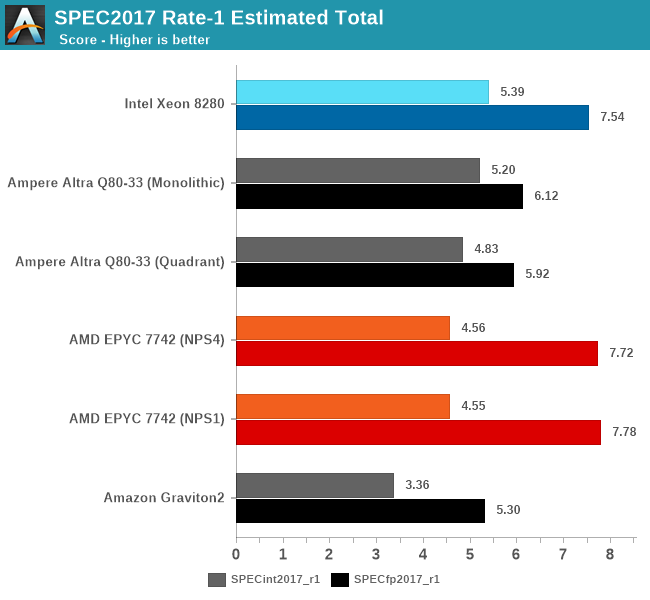
The Altra Q80-33 ends up performing extremely well and competitively against the AMD EPYC 7742 and Intel Xeon 8280, actually beating the EPYC in SPECint, although it loses by a larger margin in SPECfp. The Xeon 8280 still holds the crown here in this test due to its ability to boost up to 4GHz across two cores, clocking down to 3.8, 3.7, 3.5 and 3.3GHz beyond 2, 4, 8 and 20 cores active.
The Altra showcases a massive 52% performance lead over the Graviton2 in SPECint, which is actually beyond the expected 32% difference due to clock frequencies being at 3.3GHz versus 2.5GHz. On the other hand, the SPECfp figures are only ahead of 15% for the Altra. The prefetchers are really amongst the only thing that come to mind in regards to these differences, as the only other difference being that the Graviton2 figures were from earlier in the year on GCC 9.3. The Altra figures are definitely more reliable as we actually have our hands on the system here.
While on the AMD system the move from NPS1 to NPS4 hardly changes performance, limiting the Altra Q80-33 from a monolithic setup to a quadrant setup does incur a small performance penalty, which is unsurprising as we’re cutting the L3 into a quarter of its size for single-threaded workloads. That in itself is actually a very interesting experiment as we haven’t been able to do such a change on any prior system before.








148 Comments
View All Comments
mostlyfishy - Friday, December 18, 2020 - link
Interesting article thanks. One thing I missed, what process is this on? 7nm?It's also interesting that the M1 has demonstrated that with the right sizings, a very wide backend can give you significant single threaded performance. Not really that useful for a server processor where you're likely to be running many threads and want to trade for more cores though.
Josh128 - Friday, December 18, 2020 - link
Yes, 7nm and monolithic, which seems fairly incredible as this thing is huge. Dont have the die size numbers though. Wonder what the yield is on these...Calin - Friday, December 18, 2020 - link
Maybe there are quite a few more than 80 cores on this beast - in which case you can "eat" some die errors by deactivating cores/complexes/...Wilco1 - Friday, December 18, 2020 - link
Each Neoverse N1 core with 1MB L2 is just 1.4mm^2, so 80 of them add up to 112mm^2. The die size is estimated at about 350mm^2, so tiny compared to the total ~1100mm^2 in EPYC 7742.So performance/area is >3x that of EPYC. Now that is efficiency!
andrewaggb - Friday, December 18, 2020 - link
Timing of this article is awkward. We're comparing to the 18 month old 7742 vs the soon to be released Zen 3 Milan parts which based on the already launched Zen 3 desktop parts (and Milan leaks) will be 9-27% faster in the same power envelope.Cache is a big part of the die size for the AMD chip and the N1 has much less of it which makes the die size smaller. AMD's Desktop IGP parts with way less cache perform very similarly in many workloads to those with the extra cache and the same has been true for intel parts over the years. Some workloads don't benefit much at all from the extra cache and some do which makes choosing the benchmarks more important.
That's not to say the N1 isn't more efficient, but rather that it's hard to make a fair comparison, particularly around die size. They may have similar core counts but have made very different design decisions around cache.
Wilco1 - Friday, December 18, 2020 - link
I don't see how it matters, but Altra is about 9 months old and Neoverse N1 is a sibling of Cortex-A76 which has been available in phones for 2 years. As for Milan, I expect the gain on SPECrate to be about 10-15%. And Milan will be competing with the Altra Max which has 60% more cores which should give ~40% speedup.Yes the design decisions are quite different, and it is interesting that they end up with similar performance despite the disparity in L3 cache. I suspect that 8 memory channels is becoming a limit, and a future generation with DDR5 will enable more throughput (and even more cores).
Gondalf - Friday, December 18, 2020 - link
I am sorry but looking carefully the heatsink and the application of the thermal paste, we are facing a limit of the reticle thing on 7nm.We are in front of a 700/800 mm2 thing. On 7nm this means very few units sold and nearly zero market penetration. Same thing on 5nm given the higher core numbers.
In pratics we have nothing in our hands. Another failure in Server market
Andrei Frumusanu - Friday, December 18, 2020 - link
Ampere is doing Altra Max with 128 cores still on 7nm, so this one certainly isn't near hitting reticle limits.Wilco1 - Friday, December 18, 2020 - link
No it is not anywhere near the reticle limit. You can't estimate the die size from the heatsink, but you estimate it based on similar designs for which we do have numbers. Graviton 2 is a similar design at 30B transistors. This has another 16 cores which adds another 16X1.4 = 22.4mm^2. So around 350mm^2 in N7.milli - Monday, December 21, 2020 - link
This is just a ridiculous statement. 350mm^2 ... no way.Firstly, the die size of Graviton 2 is not known.
A realistic comparison would be AMD's Zen2 chiplet which has 3.9b transistors and is 72mm^2.
One would deduce from that, that Graviton 2 is > 550mm^2. Also your napkin calculation to add 22mm2 is flawed. Firstly, you don't know if a N1 core is actually taking 1.4mm^2 in this CPU. Secondly, you're forgetting to add 64 PCI-E lanes.
Let's say, 25mm2 for the CPU and 25mm2 for the lanes. That would bring the total to 600mm^2. Quite a bit bigger to your 350mm^2.