The 2020 Mac Mini Unleashed: Putting Apple Silicon M1 To The Test
by Andrei Frumusanu on November 17, 2020 9:00 AM ESTRosetta2: x86-64 Translation Performance
The new Apple Silicon Macs being based on a new ISA means that the hardware isn’t capable of running existing x86-based software that has been developed over the past 15 years. At least, not without help.
Apple’s new Rosetta2 is a new ahead-of-time binary translation system which is able to translate old x86-64 software to AArch64, and then run that code on the new Apple Silicon CPUs.
So, what do you have to do to run Rosetta2 and x86 apps? The answer is pretty much nothing. As long as a given application has a x86-64 code-path with at most SSE4.2 instructions, Rosetta2 and the new macOS Big Sur will take care of everything in the background, without you noticing any difference to a native application beyond its performance.
Actually, Apple’s transparent handling of things are maybe a little too transparent, as currently there’s no way to even tell if an application on the App Store actually supports the new Apple Silicon or not. Hopefully this is something that we’ll see improved in future updates, serving also as an incentive for developers to port their applications to native code. Of course, it’s now possible for developers to target both x86-64 and AArch64 applications via “universal binaries”, essentially just glued together variants of the respective architecture binaries.
We didn’t have time to investigate what software runs well and what doesn’t, I’m sure other publications out there will do a much better job and variety of workloads out there, but I did want to post some more concrete numbers as to how the performance scales across different time of workloads by running SPEC both in native, and in x86-64 binary form through Rosetta2:
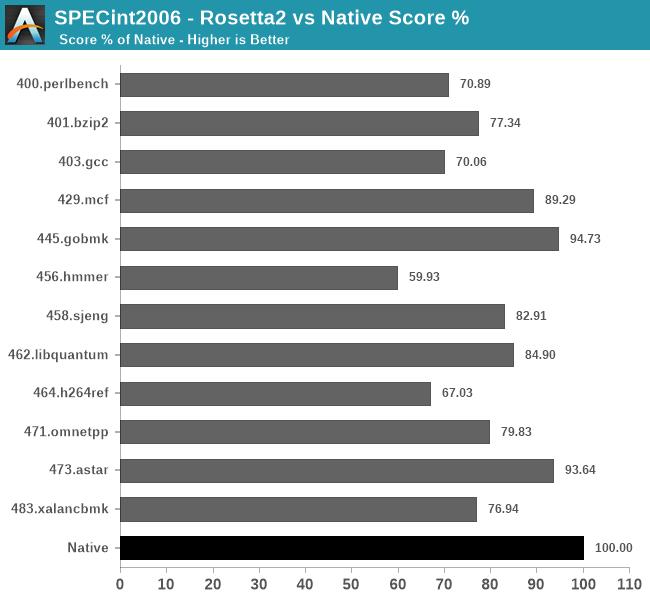
In SPECint2006, there’s a wide range of performance scaling depending on the workloads, some doing quite well, while other not so much.
The workloads that do best with Rosetta2 primarily look to be those which have a more important memory footprint and interact more with memory, scaling perf even above 90% compared to the native AArch64 binaries.
The workloads that do the worst are execution and compute heavy workloads, with the absolute worst scaling in the L1 resident 456.hmmer test, followed by 464.h264ref.
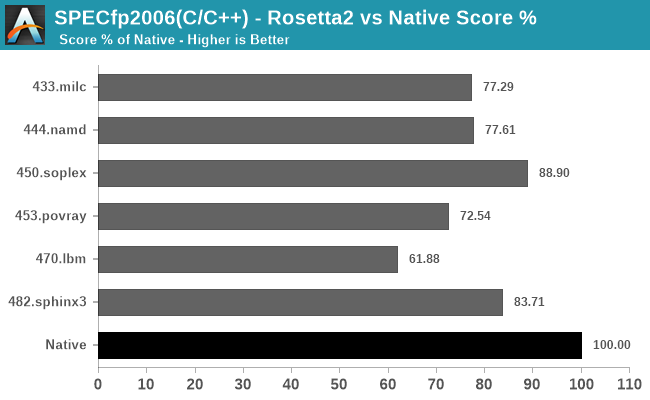
In the fp2006 workloads, things are doing relatively well except for 470.lbm which has a tight instruction loop.
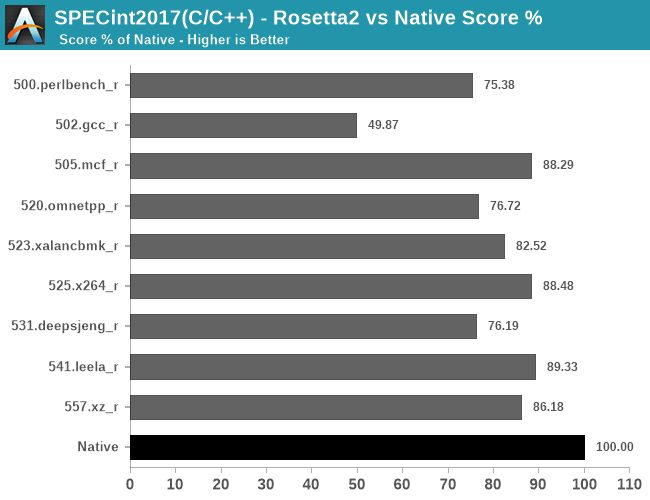
In the int2017 tests, what stands out is the horrible performance of 502.gcc_r which only showcases 49.87% performance of the native workload – probably due to high code complexity and just overall uncommon code patterns.
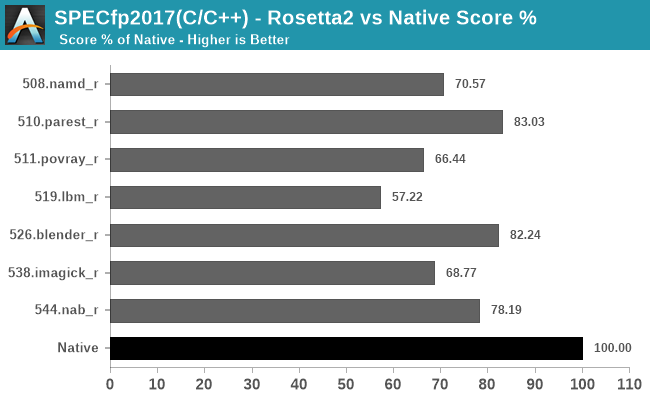
Finally, in fp2017, it looks like we’re again averaging in the 70-80% performance scale, depending on the workload’s code.
Generally, all of these results should be considered outstanding just given the feat that Apple is achieving here in terms of code translation technology. This is not a lacklustre emulator, but a full-fledged compatibility layer that when combined with the outstanding performance of the Apple M1, allows for very real and usable performance of the existing software application repertoire in Apple’s existing macOS ecosystem.








682 Comments
View All Comments
Eric S - Tuesday, November 17, 2020 - link
That cash is the reason Apple is getting so much of the 5 nm node production.varase - Wednesday, November 25, 2020 - link
You can pretty much forget Microsoft - there is no compelling ARM Microsoft software, and if ARM Windows does do x86 transcompiling it will almost certain be to the standard ARM instruction set, or worse to a Microsoft/Qualcomm mutated instruction set. In no case would it be the Apple SIlicon's AArch64 implantation.If they relied on interpretation instead of trans compilation, expect performance to be less than stellar.
Now Parallels seems to be working on something that they're keeping pretty mum about - my guess would be a hypervisor running x64 clients. Using Rosetta 2 like trans compilation, they could front end OS boot and segment loaders and read x64 code segments and return Apple Silicon AArch64 code to the client virtual machine. They'd probably have to front end code signing segments if those exist. To sustain performance, they'd also have to cache transcompiled code using a source/CRC/length key to prevent having to transcompile all the code all the time.
They wouldn't have Metal access to GPUs to lean back on, so unless Apple implements PCIe attached graphic cards I wouldn't expect gaming to ever be performant enough to be practical.
hlovatt - Tuesday, November 17, 2020 - link
Isn't the 22 W you quote for Apple for the whole system, whereas the 25 W you quote for AMD is just the processor? In't a 10 W Apple processor competitive with a 25 W AMD processor?halo37253 - Wednesday, November 18, 2020 - link
No thats full system power from the wall of AMD's 4800u in 15watt mode.whatthe123 - Tuesday, November 17, 2020 - link
By anandtech's standards these benchmarks are highly misleading, though. 5950x is capped off to its lowest possible package power. In MT testing they switch back to zen 2 chips also power limited. Everything is focusing on efficiency, which is admittedly very, very good, but the article frames it as though these are stock comparisons, when in reality most of these CPUs would be able to draw more power and dwarf the M1 in performance.If they are only looking at efficiency, why make such a misleading article? Just focus on efficiency and the results are stellar. Instead they went with this mess of an article, I'm honestly shocked considering this site normally tries to be unbiased as possible.
Spunjji - Thursday, November 19, 2020 - link
@whatthe123 - "5950x is capped off to its lowest possible package power" - where did you get that impression from?Spunjji - Thursday, November 19, 2020 - link
@whatthe123 - Regarding your complaint that they only compare the 5950X to the M1 in ST testing, of course they do, it's a 16-core 32-thread chip with a 105W TDP and ~140W power limit. It'll demolish the ~24W 4+4 M1 in MT. That's just... not a useful comparison.The point is to show AMD's peak Zen 3 performance against Apple's peak Firestorm performance. Once AMD have Zen 3 processors in the ~25W range, then a valid MT comparison in comparable designs can be made.
helpmeoutnow - Thursday, November 26, 2020 - link
@Spunjji but be fair we want to see the difference between this M1 and fully utilized 5950X just to see the real difference. Now it looks like m1 is a good cpu. but as it is said, they just cap everything else.Stephen_L - Tuesday, November 17, 2020 - link
Nah, no just listen to op, we HAVE to compare chips on the same node! Let’s wait for Intel 7nm also, hopefully in 2022 but god knows if they can do it before 2024, so we can have “Apples to apples comparison”. Let’s come back in 2-4 years guys. /smagreen - Tuesday, November 24, 2020 - link
Totally agree. The Cyrix M3 Jalapeno when it comes out on 5nm is going to crush this little M1.