The 2020 Mac Mini Unleashed: Putting Apple Silicon M1 To The Test
by Andrei Frumusanu on November 17, 2020 9:00 AM ESTRosetta2: x86-64 Translation Performance
The new Apple Silicon Macs being based on a new ISA means that the hardware isn’t capable of running existing x86-based software that has been developed over the past 15 years. At least, not without help.
Apple’s new Rosetta2 is a new ahead-of-time binary translation system which is able to translate old x86-64 software to AArch64, and then run that code on the new Apple Silicon CPUs.
So, what do you have to do to run Rosetta2 and x86 apps? The answer is pretty much nothing. As long as a given application has a x86-64 code-path with at most SSE4.2 instructions, Rosetta2 and the new macOS Big Sur will take care of everything in the background, without you noticing any difference to a native application beyond its performance.
Actually, Apple’s transparent handling of things are maybe a little too transparent, as currently there’s no way to even tell if an application on the App Store actually supports the new Apple Silicon or not. Hopefully this is something that we’ll see improved in future updates, serving also as an incentive for developers to port their applications to native code. Of course, it’s now possible for developers to target both x86-64 and AArch64 applications via “universal binaries”, essentially just glued together variants of the respective architecture binaries.
We didn’t have time to investigate what software runs well and what doesn’t, I’m sure other publications out there will do a much better job and variety of workloads out there, but I did want to post some more concrete numbers as to how the performance scales across different time of workloads by running SPEC both in native, and in x86-64 binary form through Rosetta2:
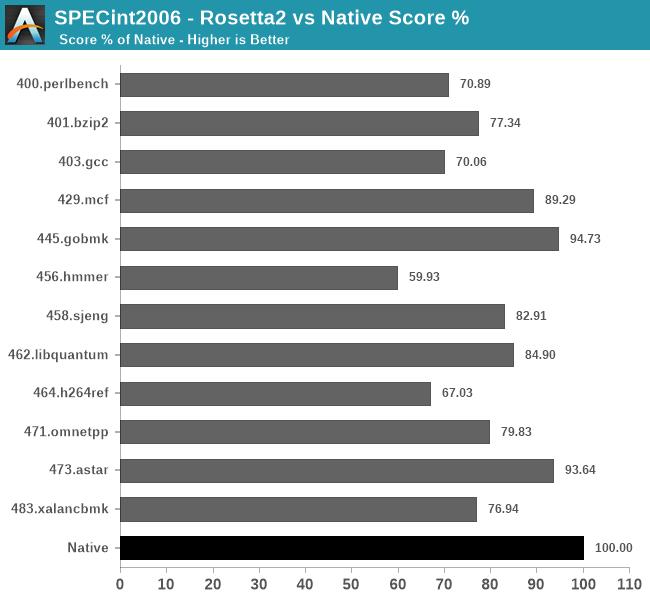
In SPECint2006, there’s a wide range of performance scaling depending on the workloads, some doing quite well, while other not so much.
The workloads that do best with Rosetta2 primarily look to be those which have a more important memory footprint and interact more with memory, scaling perf even above 90% compared to the native AArch64 binaries.
The workloads that do the worst are execution and compute heavy workloads, with the absolute worst scaling in the L1 resident 456.hmmer test, followed by 464.h264ref.
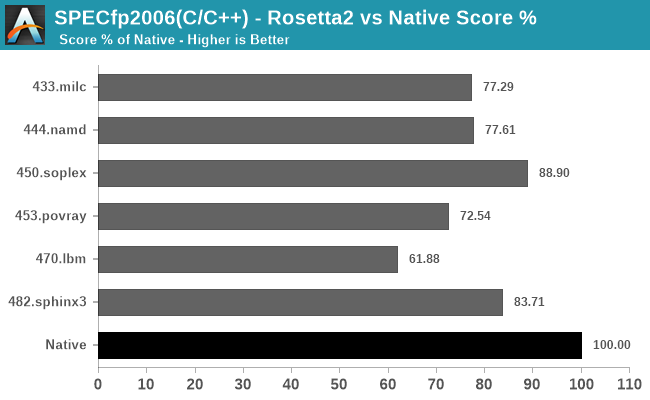
In the fp2006 workloads, things are doing relatively well except for 470.lbm which has a tight instruction loop.
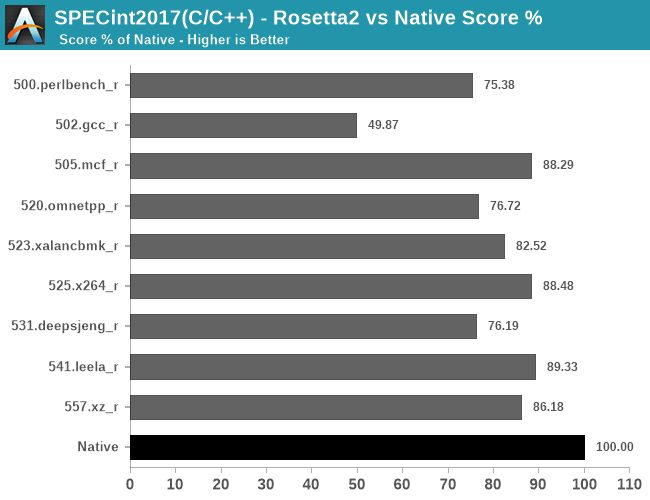
In the int2017 tests, what stands out is the horrible performance of 502.gcc_r which only showcases 49.87% performance of the native workload – probably due to high code complexity and just overall uncommon code patterns.
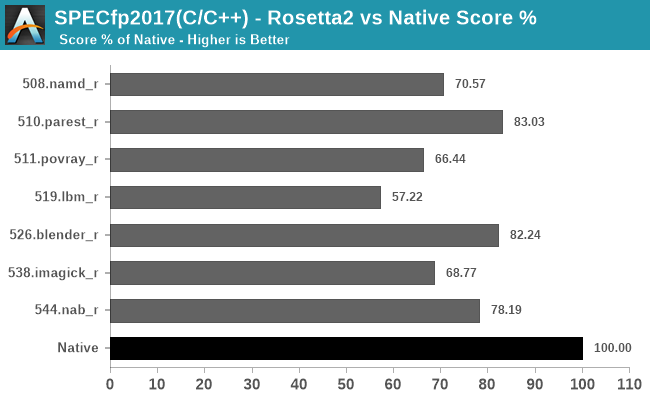
Finally, in fp2017, it looks like we’re again averaging in the 70-80% performance scale, depending on the workload’s code.
Generally, all of these results should be considered outstanding just given the feat that Apple is achieving here in terms of code translation technology. This is not a lacklustre emulator, but a full-fledged compatibility layer that when combined with the outstanding performance of the Apple M1, allows for very real and usable performance of the existing software application repertoire in Apple’s existing macOS ecosystem.








682 Comments
View All Comments
RedGreenBlue - Tuesday, November 17, 2020 - link
Obviously their new designs are way off the beaten path in their improvements than the canned designs by now.dotjaz - Wednesday, November 18, 2020 - link
You must be smoking something really good. A7 was a 6-wide design while CA57 was only 3-wide. Cyclone also has 4/2/2/3 (Int/Branch/LS/NEON) units while A57 only had (2+1)/1/2/2. That's completerly different design.RedGreenBlue - Wednesday, November 18, 2020 - link
I was thinking of the A6 that was the first modification of ARM’s architecture and before that they were fundamentally copies. It’s not easy to remember which article of Anand Shimpi’s commentary I read 7 or 8 years ago. https://www.anandtech.com/show/6330/the-iphone-5-r...danbob999 - Thursday, November 19, 2020 - link
They are dumb if they pay for designs which they do not use. The instruction set must be cheaper, otherwise ARM got it the wrong way.It's like saying that the cost of food at a groceries store is higher than the complete meal at the restaurant.
michael2k - Thursday, November 19, 2020 - link
It's actually more accurate to say, "Paying for the time of the restaurant's menu designer costs more than either the groceries or the meal"With an architectural license, they get access to to a specification, which is closer to a menu, recipes, and a shopping list, than a meal or groceries.
dotjaz - Wednesday, November 18, 2020 - link
No helios24 is INCORRECT. It's the top of the licensing for sure, but it also doesn't include any hard IP. It's the broadest in use case as you can do ANYTHING with it as long as you are ISA compliant. But it's also the narrowest in terms of ARM IP portfolio. For example Huwwei still hold ARM architectural license and can design their own ARM cores, but they don't have access to anything newer than CA77 because that's a different license.Architectual license is also the cheapest *once you have certain volume*. The initial licensing fee is high, BUT you don't pay much royalty on a per-core basis becase you don't use ARM IP other than ISA.
dotjaz - Wednesday, November 18, 2020 - link
Maybe this will help you understand more. The top of the pyrimid actually don't have access to ARM's standard IP portfolio at all.https://semiaccurate.com/2013/08/07/a-long-look-at...
michael2k - Thursday, November 19, 2020 - link
The article here contradicts you: https://semiaccurate.com/2013/08/07/a-long-look-at...On top of the pyramid is both the highest cost and lowest licensee count option, but those two factors are probably not directly related. The reason is this one is called an architectural license and you don’t actually get a core, you get a set of specs for a core and a compatibility test suite.
mjkpolo - Thursday, November 19, 2020 - link
Actaully nVidia purchased ARM lolHenry 3 Dogg - Friday, November 27, 2020 - link
"ARM was founded as a joint venture between Apple and Acorn."No. ARM was founded by Acorn spinning out its inhouse developed ARM chip as a separate company. Apple bought in later as an investment, and to prevent take overs that might threaten its Newton product.