Imagination Announces B-Series GPU IP: Scaling up with Multi-GPU
by Andrei Frumusanu on October 13, 2020 4:00 AM EST- Posted in
- GPUs
- Imagination Technologies
- SoCs
- IP
Performance, Efficiency, and a Raytracing Teaser
Overall, today’s announcement of the B-Series has been actually quite exciting. Although the actual GPU microarchitecture has seen only somewhat minor advancements compared to last year’s A-Series, Imagination’s take on multi-GPU is quite innovative and unlike what we’ve seen in past multi-GPU attempts.
The new “pull” decentralised GPU design is certainly something that offers tremendous flexibility. It won’t be something that has absolutely perfect scaling, as there might be some edge-cases where things might get bottlenecked, however Imagination expects extremely good scaling on average.
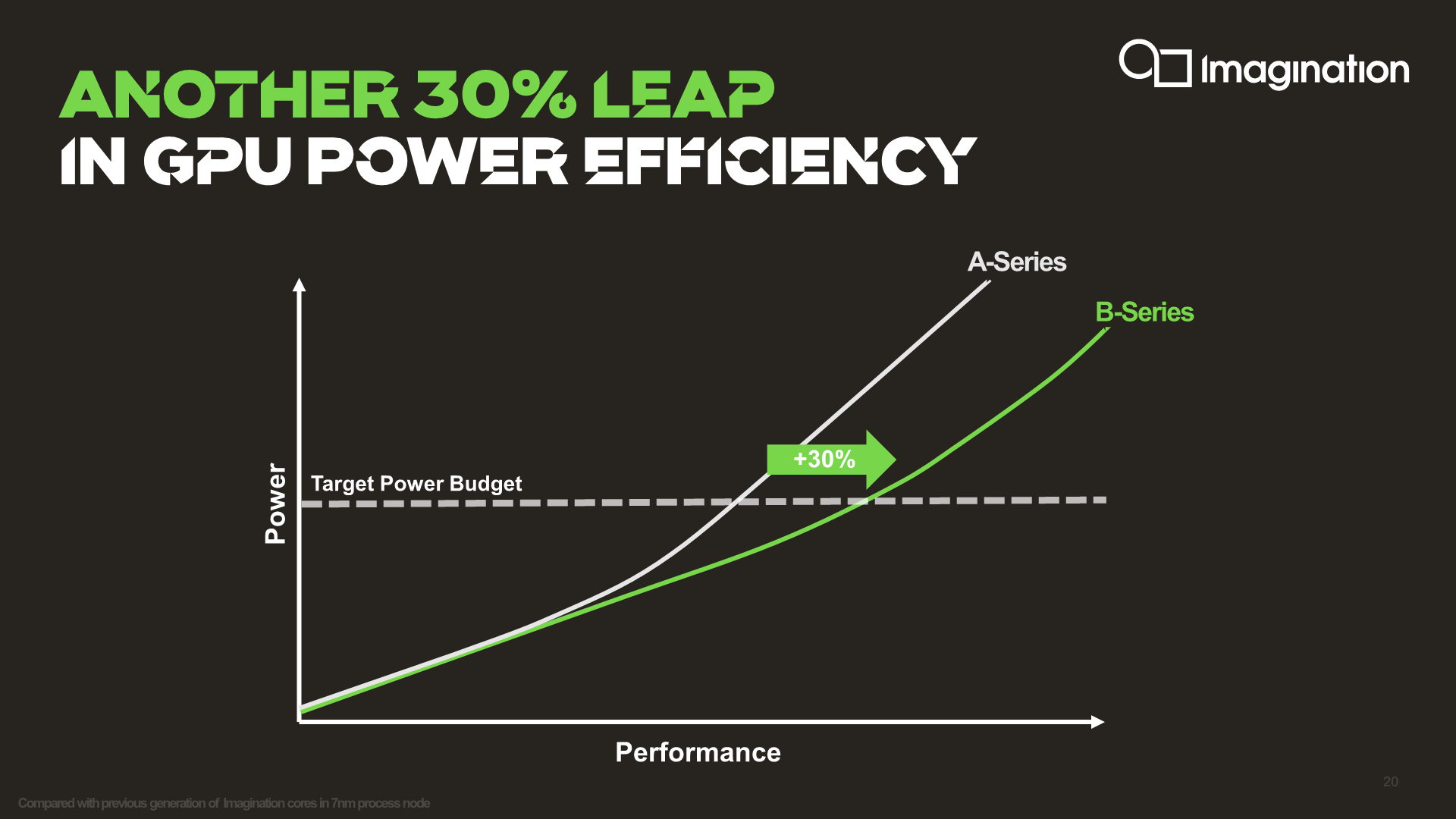
The B-Series’ roadmapped +30% performance improvement is said to have been achieved through both microarchitectural and physical design improvements (around 15%), with the rest being achieved through the PPA advantage of choosing a multi-core GPU configuration.

Probably what’s more important than the GPU IP itself, is that Imagination says they have actually licensed out and delivered the IP customers already – which is a contrast to past generation Imagination GPU IP announcements where things were publicised ahead of not only the IP being delivered, but ahead of it even being completed.
We still haven not seen or heard of any A-Series design wins, so we do hope there will be more news on that in regards to the B-Series.
Industry sources say that the major demand-driver for Imagination GPU IP right now is the high-performance GPU market in China, where there’s apparently a major hunger and need for domestic designs that are disconnected from US suppliers such as AMD and Nvidia.

Innosilicon Fantasy GPU Series
One such design win is Innosilicon’s recently announced “Fantasy” graphics cards series. Innosilicon to date was known as an ASIC IP design house for various miscellaneous IP blocks, such as providing Nivdia’s GDDR6’s memory controllers.
Roger Mao, Vice President of Engineering, Innosilicon, says;
“Imagination’s BXT multi-core GPU IP delivers the level of performance and power efficiency we had been looking for. Innosilicon has a solid track record in delivering first class high-speed and high-bandwidth computing solutions in advanced FinFET process nodes. Building on this success and strong customer demand, we are announcing our upcoming product which is a standalone high-performance 4K/8K PCI-E Gen4 GPU card, set to hit the market very soon, that will power 5G cloud gaming and data centre applications. With a solid foundation in GDDR6 high-speed memory, cache coherent chiplet innovation and high-performance multimedia processor optimisation, a move into a standalone PCI-E form-factor GPU is natural for us. Thanks to BXT’s multi-core scalable architecture, we are able to build a customised solution to meet the high-end data centre demand with fantastic cloud and computing performance.”
If this pivot towards higher-performance computing works out for Imagination remains to be seen. It certainly seems that at least having a tangible design win such as the above would certainly be a big improvement given that we’ve never seen publicly acknowledged 8XT, 9XT, 9XTP or even A-Series silicon.
Level 4 Raytracing for C-Series
Lastly, Imagination is also teasing their future C-Series architecture, confirming that it’ll be a full raytracing capable design. Although Imagination has had Raytracing IP and capable GPUs for the better part of the decade, it took Nvidia’s RTX series as well as AMD’s inclusion of Raytracing in the new generation consoles as well as RDNA2 series to seriously kick-start the RT ecosystem into gear. Imagination is taking full advantage of this revival as it dusted off its RT IP that previously had been shelved a few years ago.
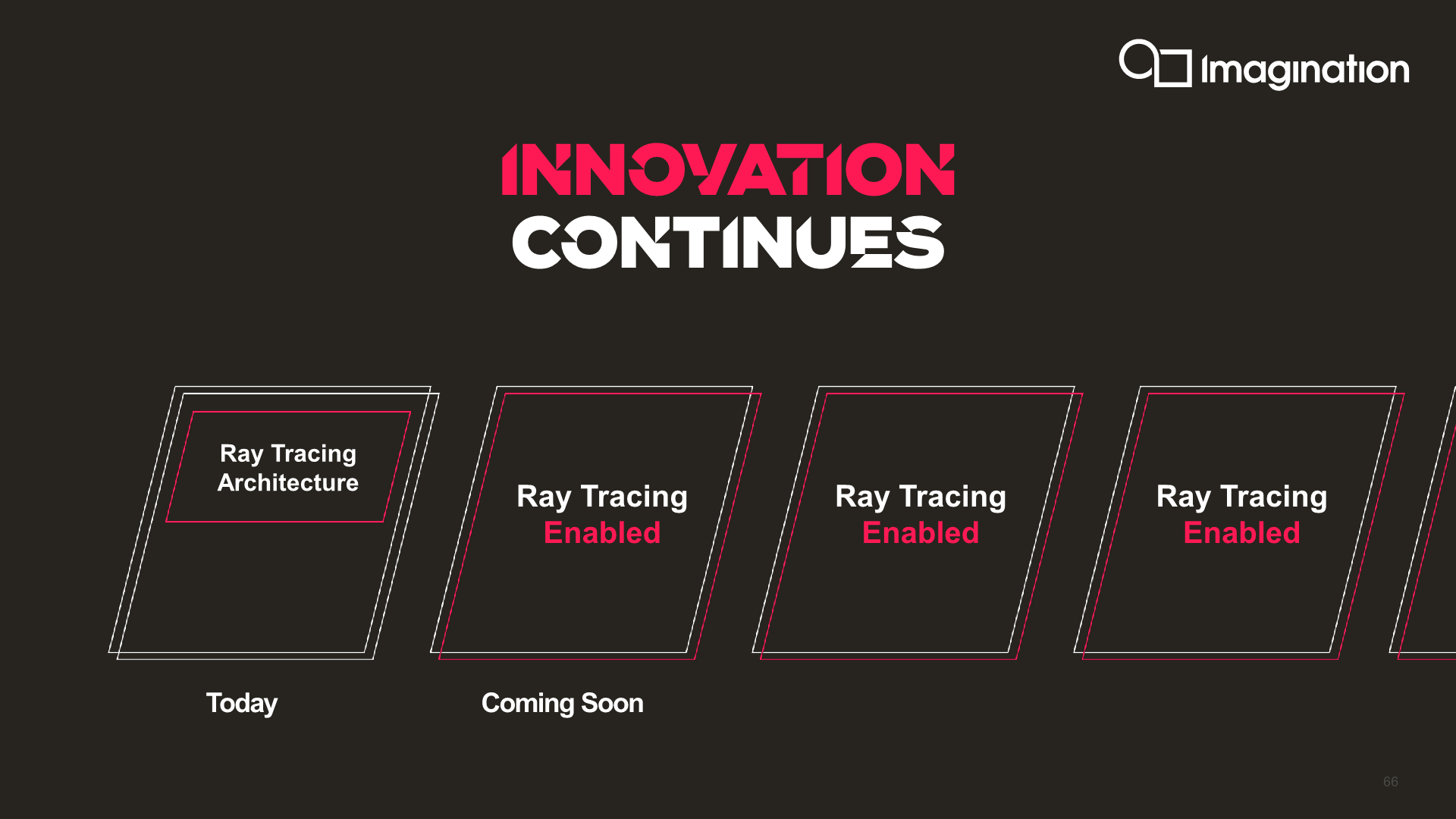
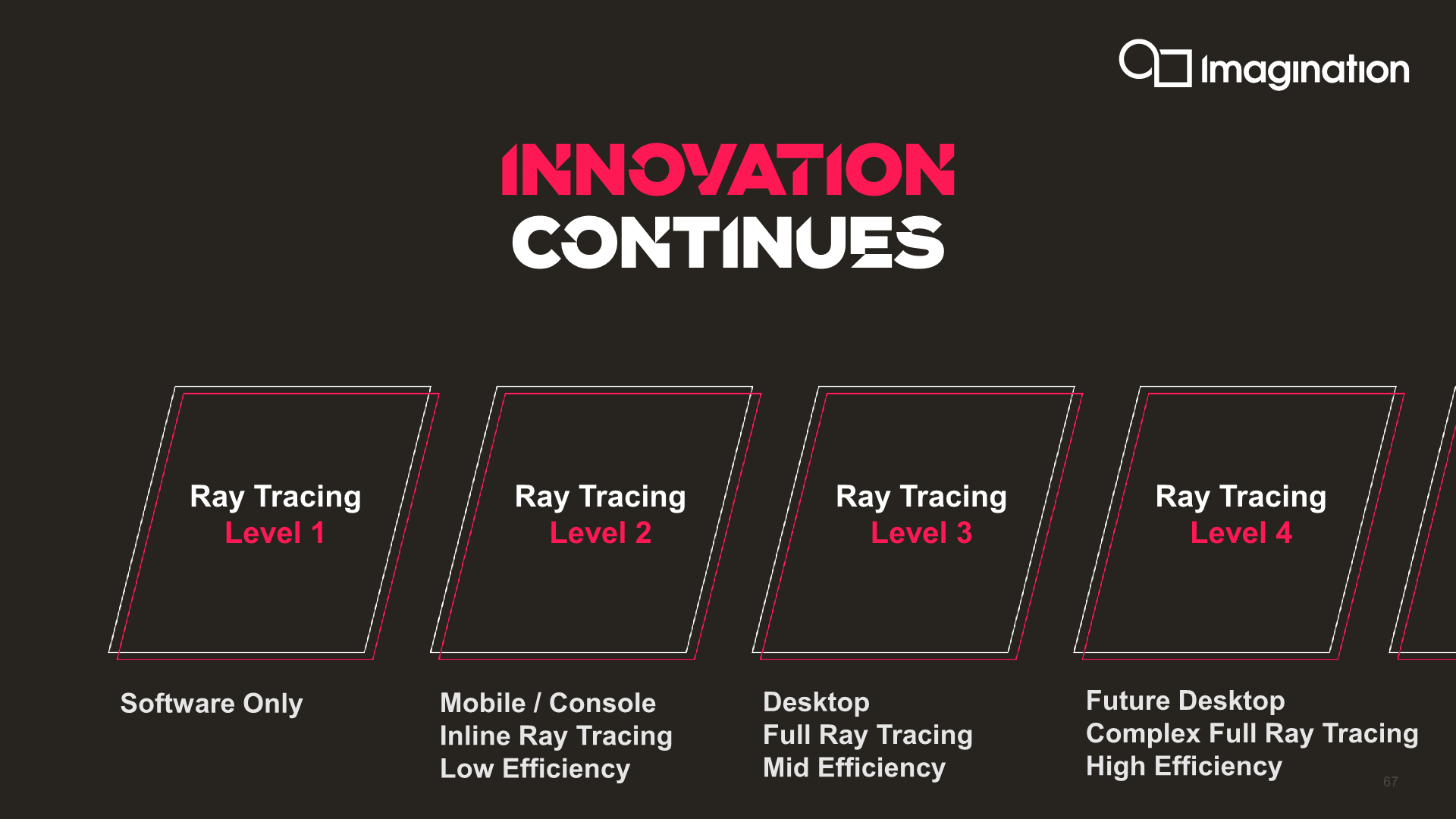
Beyond confirming that the new C-Series will have ray tracing capabilities, Imagination further confirms that this will be an implementation using the company’s fullest of capabilities, including BVH processing and Coherency Sorting in hardware, a capability the company denotes as a “Level 4” ray tracing implementation, which would be more advanced than what current generation Nvidia and AMD GPUs are able to achieve at a “Level 3”.
Imagination explains that they’ve had these capabilities for a long time, and when discussing with customers as to what kind of capabilities they would like to see in future IP, they had chosen to go for the full-blown implementation as this was the better future-proof design choice.
Overall, it seems like Imagination is on a path where it tries to diversify itself to markets other than the typical low-power GPU use-cases. The next few years will definitely be interesting for the company, and particularly the new distributed multi-GPU approach will be something to pay attention to.








74 Comments
View All Comments
myownfriend - Tuesday, October 13, 2020 - link
Yea like if the back buffer were drawn with on-chip memory... like a tile-based GPU.anonomouse - Tuesday, October 13, 2020 - link
Probably works out-ish a bit better with a tile-based deferred renderer, since the active data for a given time will be more localized and more predictable.myownfriend - Tuesday, October 13, 2020 - link
The thing with tile-based GPUs is that they have less data to share between cores since the depth, stencil, and color buffers for each tile are stored on-chip. Since screen-space triangles are split into tiles and one triangle can potentially turn into thousands of fragments, it becomes less bandwidth intensive to distribute work like that. All the work that Imagination in particular has put into HSR to reduce texture bandwidth as well as texture pre-fetch stuff would also benefit them in multi-GPU configurations.SolarBear28 - Tuesday, October 13, 2020 - link
This tech seems very applicable to ARM Macs although Apple is probably using in-house designs.Luke212 - Tuesday, October 13, 2020 - link
why would i want to see 2 gpus as 1 gpu? its a terrible idea. its NUMA x 100myownfriend - Tuesday, October 13, 2020 - link
On an SOC or even in a chiplet design, they wouldn't necessarily have separate memory controllers. We're talking about GPUs as blocks on an SOC.CiccioB - Tuesday, October 13, 2020 - link
It simplify things better than see them as 2 separate GPUsmyownfriend - Sunday, June 6, 2021 - link
I'm gonna be a weirdo and add to something like half a year later. I'm not sure why seeing two or, in this case, four GPUs is preferable to seeing one in situations where all the GPUs are tile-based and on the same chip.Let me think out loud here.
At the vertex processing stage, you could toss triangles at each GPU and they'll transform them to screen-space then clip, project, and cull them. Their respective tiling engines then determine which tiles each triangle is in and appends that to the parameter and geometry buffer in memory. I can't think of many reasons why they would really need to communicate with each other when making this buffer. After that's done, the fragment shading stage would consist of each GPU requesting tiles and textures from memory, shading and blending them in their own tile memory, and writing out the finished pixels in memory. I can't really find much in that example that makes all four GPUs work differently than one larger one.
I can see why that might be preferable with IMR GPUs though. If we were to just toss triangles at each GPU they would transform them to screen-space and clip, project, and cull them just like a TBDR. After this, a single IMR GPU would do an early-z test, if it passes then procedes with the fragment pipeline. This is where the first big issue comes up in a multi-GPU configuration though: overlapping geometry. Each GPU will be transforming different triangles and some of these triangles may overlap. It would be really useful for GPU0 to know if GPU1 is going to write over the pixels it's about to work on. This would require sharing the z-value of the current pixels between both GPUs. They could just compare z-values at the same stages, but unless they were synced with each other, that wouldn't prevent GPU0 from working on pixels that already passed GPU1's early z-test and are about to be written to memory. Obviously, that would result in a lot of unnecessary on-chip traffic, very un-ideal scaling, and possibly pixels being drawn to buffers than shouldn't have.
What might help is to do typical dual-GPU stuff like alternate frame or split-frame rendering so those z-comparisons would only have to happen between the pixels on each chip. The latter raises another problem though. Neither GPU can know what a triangles final screen space coordinates are until AFTER they transform it. This means if GPU0 is supposed to be rendering the top slice of the screen and it gets a triangle from the bottom of the screen or across the divide then it has to know how to deal with that. It could just send that triangle to GPU1 to render. Since they both share the same memory, it has a second option which is to do the z-comparison thing from before and GPU0 could render the pixels to bottom of the screen anyway.
Obviously you could also bin the triangles like TBDR or give each GPU a completely separate task like having one work on the G-buffer while the other creates shadow maps or have each rendering a different program. Because there's so many ways to use two or more IMRs together and each has it's drawbacks, it makes sense to expose them as two separate GPUs. It puts the burden on parrallizing them in someone elses hands. TBDRs don't need to do that because they work more like they normally would. That's why PowerVR Series 5 GPUs pretty much just scaled by putting more full GPUs on the SOC.
Obviously, these both become a lot more complicated when they're chiplets, especially if they have their own memory controllers but I won't get into that.
brucethemoose - Tuesday, October 13, 2020 - link
Andrei, could you ask Innosilicon for one of those PCIe GPUs?Even if it only works for compute workloads, another competitor in the desktop space would be fascinating.
Also, that is a *conspicuously* flashy and desktop-oriented shroud for something thats ostensibly a cloud GPU.
myownfriend - Tuesday, October 13, 2020 - link
I was thinking the same thing about the shroud.