Imagination Announces B-Series GPU IP: Scaling up with Multi-GPU
by Andrei Frumusanu on October 13, 2020 4:00 AM EST- Posted in
- GPUs
- Imagination Technologies
- SoCs
- IP
Introducing BXS Series: Functional Safety for Autonomy
Besides targeting higher performance design targets, an area where Imagination is putting a higher level of focus on is the automotive and industrial markets. To cover these use-cases, Imagination is today also launching the new “BXS” series of GPU IP – where the S stands for safety.

The new GPU IP line-up mirrors the standard BXT, BXM and BXE configurations, but adds support for ISO 26262 / ASIL-B functional safety features.

Imagination is introducing a new feature called “Tile Region Protection” in which a configurable region of render tiles on the render frame can be marked as safety critical, and for which the GPU can check for correct execution and rendering, allowing it to be ISO 26262 certified.

TRP is implemented from the smallest BXE-equivalent BXS GPU (Frankly Imagination could have done better here than calling the whole safety line-up BXS), allowing for work repletion to achieve fault detection. Furthermore, Imagination allows for end-to-end data integrity protection via CRC checking of all data going in and out of the GPU, further helping the IP achieve safety requirements.

TRP require a single GPU to repeat work, which in turn would mean reduced performance in a system. A more performance-oriented way of scaling things would be a multi-GPU implementation.
A multi-GPU configuration in an automotive design would also server the purpose of partitioning the GPUs for multiple independent workloads; whilst in a consumer implementation you would expect the GPUs to mostly act and appear as a single large unit to a host, automotive use-cases could also have the multiple GPUs act completely independently from each other. It’s also possible to mix- and match GPUs, for example a 4-core implementation could have 3 partitions, with two GPUs working together to pool up resources for a more demanding task such as the infotainment system, while two other GPUs would be handling other independent workloads.
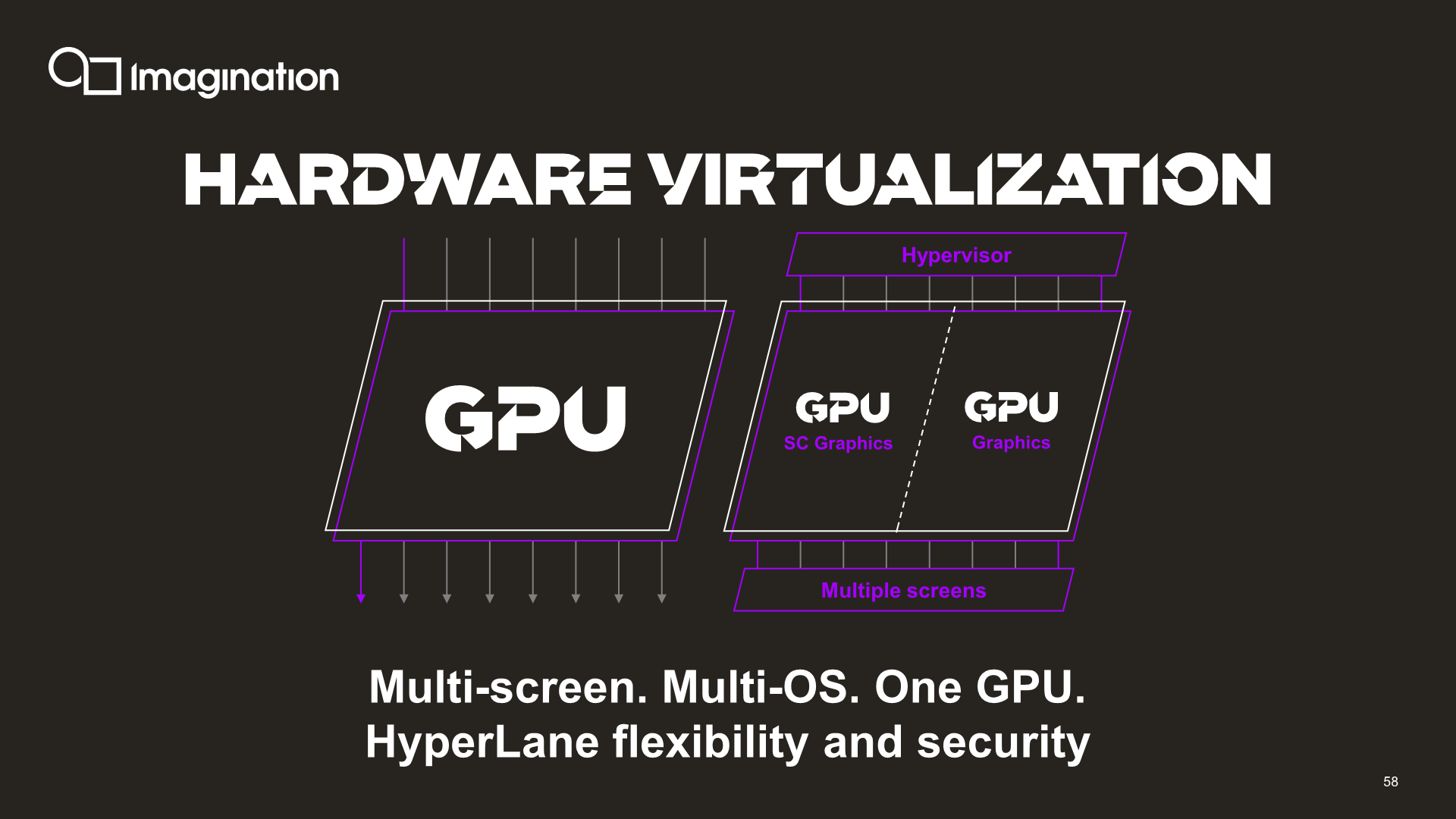
Imagination naturally also continues to support hardware virtualisation within one single GPU with up to 8 “hyperlanes” (guests). So, you could split up a 2-core design into 3 partitions, such as depicted above.

Beyond the addition of safety critical features on the BXS series, the automotive IP also features some specific enhancements in the microarchitecture that allows for better performance scaling for workloads that are more unique to the automotive space. One such aspect is geometry, where automotive vendors have the tendency to use absurd amounts of triangles. Imagination says they’ve tweaked their designs to cover these more demanding use-cases, and together with some MSAA specific optimisations they can reach up to a 60% greater performance for these automotive edge-cases, compared to the regular non-automotive IP.








74 Comments
View All Comments
myownfriend - Tuesday, October 13, 2020 - link
Yea like if the back buffer were drawn with on-chip memory... like a tile-based GPU.anonomouse - Tuesday, October 13, 2020 - link
Probably works out-ish a bit better with a tile-based deferred renderer, since the active data for a given time will be more localized and more predictable.myownfriend - Tuesday, October 13, 2020 - link
The thing with tile-based GPUs is that they have less data to share between cores since the depth, stencil, and color buffers for each tile are stored on-chip. Since screen-space triangles are split into tiles and one triangle can potentially turn into thousands of fragments, it becomes less bandwidth intensive to distribute work like that. All the work that Imagination in particular has put into HSR to reduce texture bandwidth as well as texture pre-fetch stuff would also benefit them in multi-GPU configurations.SolarBear28 - Tuesday, October 13, 2020 - link
This tech seems very applicable to ARM Macs although Apple is probably using in-house designs.Luke212 - Tuesday, October 13, 2020 - link
why would i want to see 2 gpus as 1 gpu? its a terrible idea. its NUMA x 100myownfriend - Tuesday, October 13, 2020 - link
On an SOC or even in a chiplet design, they wouldn't necessarily have separate memory controllers. We're talking about GPUs as blocks on an SOC.CiccioB - Tuesday, October 13, 2020 - link
It simplify things better than see them as 2 separate GPUsmyownfriend - Sunday, June 6, 2021 - link
I'm gonna be a weirdo and add to something like half a year later. I'm not sure why seeing two or, in this case, four GPUs is preferable to seeing one in situations where all the GPUs are tile-based and on the same chip.Let me think out loud here.
At the vertex processing stage, you could toss triangles at each GPU and they'll transform them to screen-space then clip, project, and cull them. Their respective tiling engines then determine which tiles each triangle is in and appends that to the parameter and geometry buffer in memory. I can't think of many reasons why they would really need to communicate with each other when making this buffer. After that's done, the fragment shading stage would consist of each GPU requesting tiles and textures from memory, shading and blending them in their own tile memory, and writing out the finished pixels in memory. I can't really find much in that example that makes all four GPUs work differently than one larger one.
I can see why that might be preferable with IMR GPUs though. If we were to just toss triangles at each GPU they would transform them to screen-space and clip, project, and cull them just like a TBDR. After this, a single IMR GPU would do an early-z test, if it passes then procedes with the fragment pipeline. This is where the first big issue comes up in a multi-GPU configuration though: overlapping geometry. Each GPU will be transforming different triangles and some of these triangles may overlap. It would be really useful for GPU0 to know if GPU1 is going to write over the pixels it's about to work on. This would require sharing the z-value of the current pixels between both GPUs. They could just compare z-values at the same stages, but unless they were synced with each other, that wouldn't prevent GPU0 from working on pixels that already passed GPU1's early z-test and are about to be written to memory. Obviously, that would result in a lot of unnecessary on-chip traffic, very un-ideal scaling, and possibly pixels being drawn to buffers than shouldn't have.
What might help is to do typical dual-GPU stuff like alternate frame or split-frame rendering so those z-comparisons would only have to happen between the pixels on each chip. The latter raises another problem though. Neither GPU can know what a triangles final screen space coordinates are until AFTER they transform it. This means if GPU0 is supposed to be rendering the top slice of the screen and it gets a triangle from the bottom of the screen or across the divide then it has to know how to deal with that. It could just send that triangle to GPU1 to render. Since they both share the same memory, it has a second option which is to do the z-comparison thing from before and GPU0 could render the pixels to bottom of the screen anyway.
Obviously you could also bin the triangles like TBDR or give each GPU a completely separate task like having one work on the G-buffer while the other creates shadow maps or have each rendering a different program. Because there's so many ways to use two or more IMRs together and each has it's drawbacks, it makes sense to expose them as two separate GPUs. It puts the burden on parrallizing them in someone elses hands. TBDRs don't need to do that because they work more like they normally would. That's why PowerVR Series 5 GPUs pretty much just scaled by putting more full GPUs on the SOC.
Obviously, these both become a lot more complicated when they're chiplets, especially if they have their own memory controllers but I won't get into that.
brucethemoose - Tuesday, October 13, 2020 - link
Andrei, could you ask Innosilicon for one of those PCIe GPUs?Even if it only works for compute workloads, another competitor in the desktop space would be fascinating.
Also, that is a *conspicuously* flashy and desktop-oriented shroud for something thats ostensibly a cloud GPU.
myownfriend - Tuesday, October 13, 2020 - link
I was thinking the same thing about the shroud.