Imagination Announces B-Series GPU IP: Scaling up with Multi-GPU
by Andrei Frumusanu on October 13, 2020 4:00 AM EST- Posted in
- GPUs
- Imagination Technologies
- SoCs
- IP
Introducing IMGIC - A better frame-buffer compression
Besides the multi-GPU scalability, another big feature introduction to the B-Series is the addition of a completely new image compression algorithm, simply dubbed IMGIC, or Imagination Image Compression.
Compression is an integral part of modern GPUs as otherwise the designs would simply be memory bandwidth starved. To date, Imagination has been using PVRIC to achieve this. The problem with PVRIC was that it was a relatively uncompetitive compression format, falling behind in data compression ratio compared to other competitor techniques such as Arm’s AFBC (Arm Frame-Buffer Compression). This resulted in IMG GPUs using up more bandwidth than a comparable Arm GPU.


IMGIC is a completely new and redesigned compression algorithm that replaces PVRIC. Imagination touts this as the most advanced image compression technology, offering extreme bandwidth savings and a lot more flexibility compared to previous PVRIC designs. Amongst the flexibility aspect of things, IMGIC can now work on individual pixels instead of just smaller tiles or pixel groups.
Furthermore, the new algorithm is said to be 8x simpler than PVRIC, meaning the hardware implementation is also much simplified and achieves a significant are area reduction.
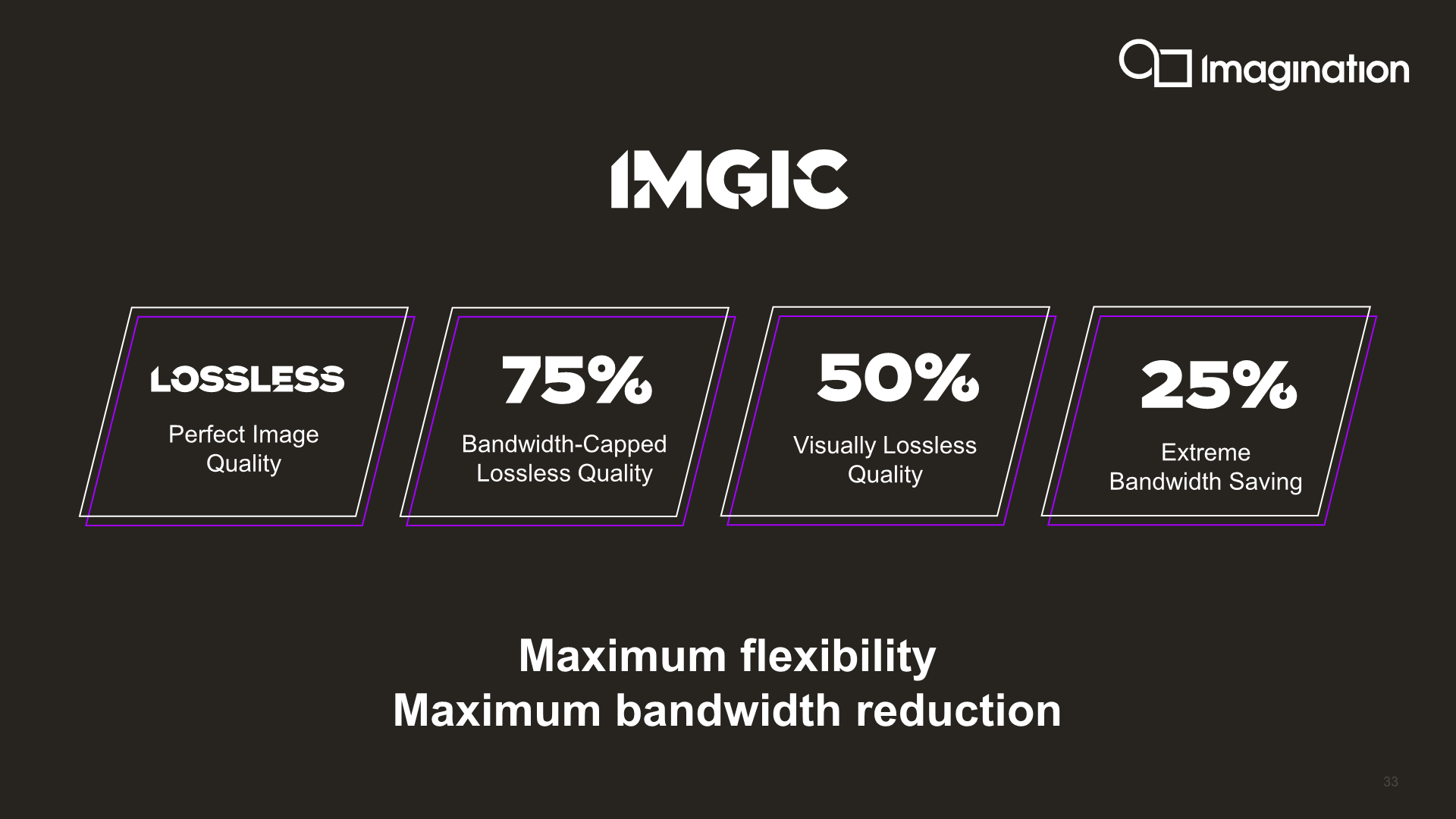
The new implementation gives vendors more scaling options, adding compression ratios down to a lossy 25% for extreme bandwidth savings. SoC vendors can use this to alleviate bandwidth starved scenarios or QoS scenarios where other IPs on the SoC should take priority.

Overall, the B-Series now offers a 35% reduction in bandwidth compared to the A-Series and previous generation Imagination GPU architectures, which is a rather large improvement given that memory bandwidth is a costly matter, both in terms of actual silicon cost as well as energy usage.








74 Comments
View All Comments
myownfriend - Tuesday, October 13, 2020 - link
Yea like if the back buffer were drawn with on-chip memory... like a tile-based GPU.anonomouse - Tuesday, October 13, 2020 - link
Probably works out-ish a bit better with a tile-based deferred renderer, since the active data for a given time will be more localized and more predictable.myownfriend - Tuesday, October 13, 2020 - link
The thing with tile-based GPUs is that they have less data to share between cores since the depth, stencil, and color buffers for each tile are stored on-chip. Since screen-space triangles are split into tiles and one triangle can potentially turn into thousands of fragments, it becomes less bandwidth intensive to distribute work like that. All the work that Imagination in particular has put into HSR to reduce texture bandwidth as well as texture pre-fetch stuff would also benefit them in multi-GPU configurations.SolarBear28 - Tuesday, October 13, 2020 - link
This tech seems very applicable to ARM Macs although Apple is probably using in-house designs.Luke212 - Tuesday, October 13, 2020 - link
why would i want to see 2 gpus as 1 gpu? its a terrible idea. its NUMA x 100myownfriend - Tuesday, October 13, 2020 - link
On an SOC or even in a chiplet design, they wouldn't necessarily have separate memory controllers. We're talking about GPUs as blocks on an SOC.CiccioB - Tuesday, October 13, 2020 - link
It simplify things better than see them as 2 separate GPUsmyownfriend - Sunday, June 6, 2021 - link
I'm gonna be a weirdo and add to something like half a year later. I'm not sure why seeing two or, in this case, four GPUs is preferable to seeing one in situations where all the GPUs are tile-based and on the same chip.Let me think out loud here.
At the vertex processing stage, you could toss triangles at each GPU and they'll transform them to screen-space then clip, project, and cull them. Their respective tiling engines then determine which tiles each triangle is in and appends that to the parameter and geometry buffer in memory. I can't think of many reasons why they would really need to communicate with each other when making this buffer. After that's done, the fragment shading stage would consist of each GPU requesting tiles and textures from memory, shading and blending them in their own tile memory, and writing out the finished pixels in memory. I can't really find much in that example that makes all four GPUs work differently than one larger one.
I can see why that might be preferable with IMR GPUs though. If we were to just toss triangles at each GPU they would transform them to screen-space and clip, project, and cull them just like a TBDR. After this, a single IMR GPU would do an early-z test, if it passes then procedes with the fragment pipeline. This is where the first big issue comes up in a multi-GPU configuration though: overlapping geometry. Each GPU will be transforming different triangles and some of these triangles may overlap. It would be really useful for GPU0 to know if GPU1 is going to write over the pixels it's about to work on. This would require sharing the z-value of the current pixels between both GPUs. They could just compare z-values at the same stages, but unless they were synced with each other, that wouldn't prevent GPU0 from working on pixels that already passed GPU1's early z-test and are about to be written to memory. Obviously, that would result in a lot of unnecessary on-chip traffic, very un-ideal scaling, and possibly pixels being drawn to buffers than shouldn't have.
What might help is to do typical dual-GPU stuff like alternate frame or split-frame rendering so those z-comparisons would only have to happen between the pixels on each chip. The latter raises another problem though. Neither GPU can know what a triangles final screen space coordinates are until AFTER they transform it. This means if GPU0 is supposed to be rendering the top slice of the screen and it gets a triangle from the bottom of the screen or across the divide then it has to know how to deal with that. It could just send that triangle to GPU1 to render. Since they both share the same memory, it has a second option which is to do the z-comparison thing from before and GPU0 could render the pixels to bottom of the screen anyway.
Obviously you could also bin the triangles like TBDR or give each GPU a completely separate task like having one work on the G-buffer while the other creates shadow maps or have each rendering a different program. Because there's so many ways to use two or more IMRs together and each has it's drawbacks, it makes sense to expose them as two separate GPUs. It puts the burden on parrallizing them in someone elses hands. TBDRs don't need to do that because they work more like they normally would. That's why PowerVR Series 5 GPUs pretty much just scaled by putting more full GPUs on the SOC.
Obviously, these both become a lot more complicated when they're chiplets, especially if they have their own memory controllers but I won't get into that.
brucethemoose - Tuesday, October 13, 2020 - link
Andrei, could you ask Innosilicon for one of those PCIe GPUs?Even if it only works for compute workloads, another competitor in the desktop space would be fascinating.
Also, that is a *conspicuously* flashy and desktop-oriented shroud for something thats ostensibly a cloud GPU.
myownfriend - Tuesday, October 13, 2020 - link
I was thinking the same thing about the shroud.