Imagination Announces B-Series GPU IP: Scaling up with Multi-GPU
by Andrei Frumusanu on October 13, 2020 4:00 AM EST- Posted in
- GPUs
- Imagination Technologies
- SoCs
- IP
Performance, Efficiency, and a Raytracing Teaser
Overall, today’s announcement of the B-Series has been actually quite exciting. Although the actual GPU microarchitecture has seen only somewhat minor advancements compared to last year’s A-Series, Imagination’s take on multi-GPU is quite innovative and unlike what we’ve seen in past multi-GPU attempts.
The new “pull” decentralised GPU design is certainly something that offers tremendous flexibility. It won’t be something that has absolutely perfect scaling, as there might be some edge-cases where things might get bottlenecked, however Imagination expects extremely good scaling on average.
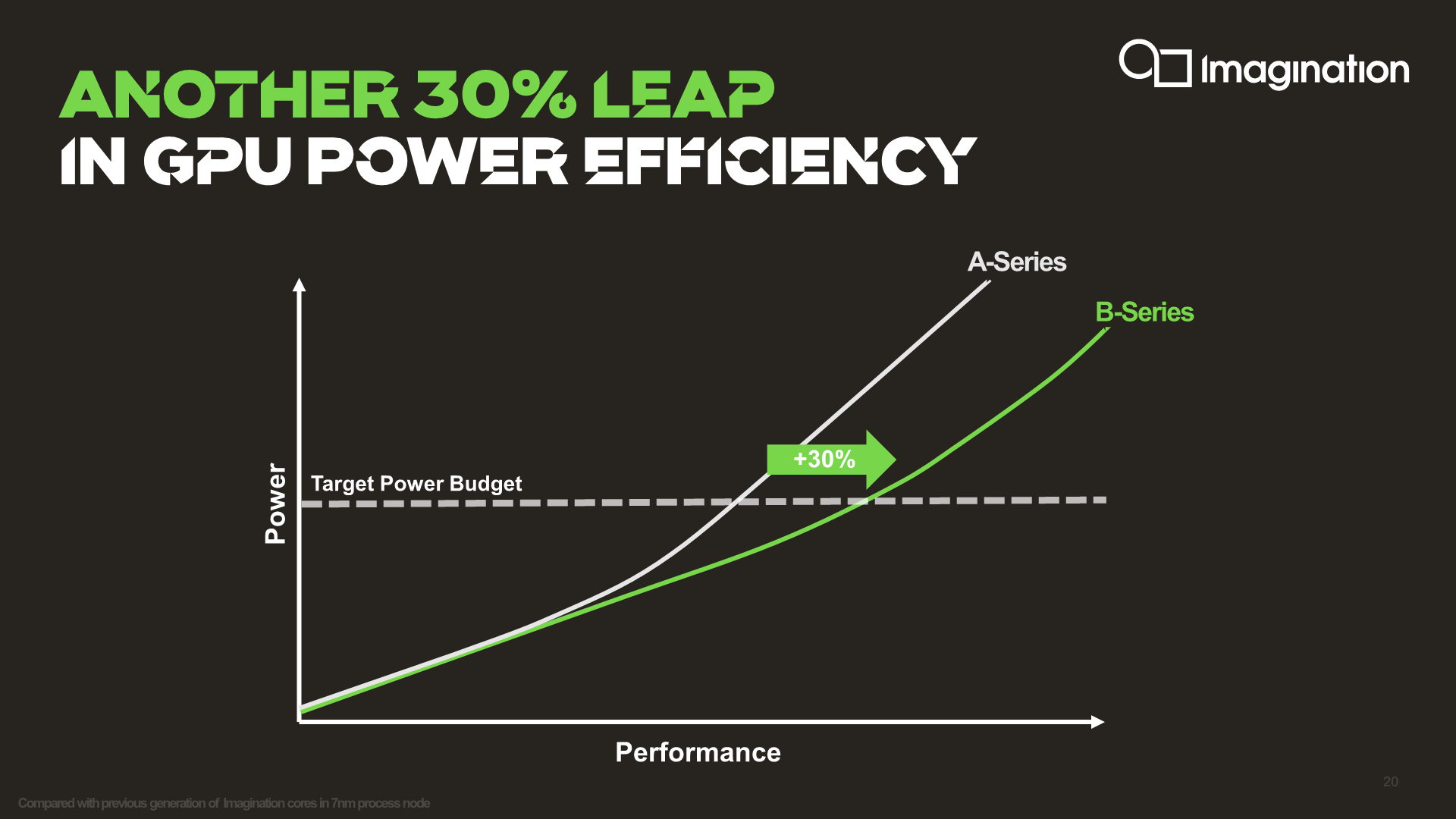
The B-Series’ roadmapped +30% performance improvement is said to have been achieved through both microarchitectural and physical design improvements (around 15%), with the rest being achieved through the PPA advantage of choosing a multi-core GPU configuration.

Probably what’s more important than the GPU IP itself, is that Imagination says they have actually licensed out and delivered the IP customers already – which is a contrast to past generation Imagination GPU IP announcements where things were publicised ahead of not only the IP being delivered, but ahead of it even being completed.
We still haven not seen or heard of any A-Series design wins, so we do hope there will be more news on that in regards to the B-Series.
Industry sources say that the major demand-driver for Imagination GPU IP right now is the high-performance GPU market in China, where there’s apparently a major hunger and need for domestic designs that are disconnected from US suppliers such as AMD and Nvidia.

Innosilicon Fantasy GPU Series
One such design win is Innosilicon’s recently announced “Fantasy” graphics cards series. Innosilicon to date was known as an ASIC IP design house for various miscellaneous IP blocks, such as providing Nivdia’s GDDR6’s memory controllers.
Roger Mao, Vice President of Engineering, Innosilicon, says;
“Imagination’s BXT multi-core GPU IP delivers the level of performance and power efficiency we had been looking for. Innosilicon has a solid track record in delivering first class high-speed and high-bandwidth computing solutions in advanced FinFET process nodes. Building on this success and strong customer demand, we are announcing our upcoming product which is a standalone high-performance 4K/8K PCI-E Gen4 GPU card, set to hit the market very soon, that will power 5G cloud gaming and data centre applications. With a solid foundation in GDDR6 high-speed memory, cache coherent chiplet innovation and high-performance multimedia processor optimisation, a move into a standalone PCI-E form-factor GPU is natural for us. Thanks to BXT’s multi-core scalable architecture, we are able to build a customised solution to meet the high-end data centre demand with fantastic cloud and computing performance.”
If this pivot towards higher-performance computing works out for Imagination remains to be seen. It certainly seems that at least having a tangible design win such as the above would certainly be a big improvement given that we’ve never seen publicly acknowledged 8XT, 9XT, 9XTP or even A-Series silicon.
Level 4 Raytracing for C-Series
Lastly, Imagination is also teasing their future C-Series architecture, confirming that it’ll be a full raytracing capable design. Although Imagination has had Raytracing IP and capable GPUs for the better part of the decade, it took Nvidia’s RTX series as well as AMD’s inclusion of Raytracing in the new generation consoles as well as RDNA2 series to seriously kick-start the RT ecosystem into gear. Imagination is taking full advantage of this revival as it dusted off its RT IP that previously had been shelved a few years ago.
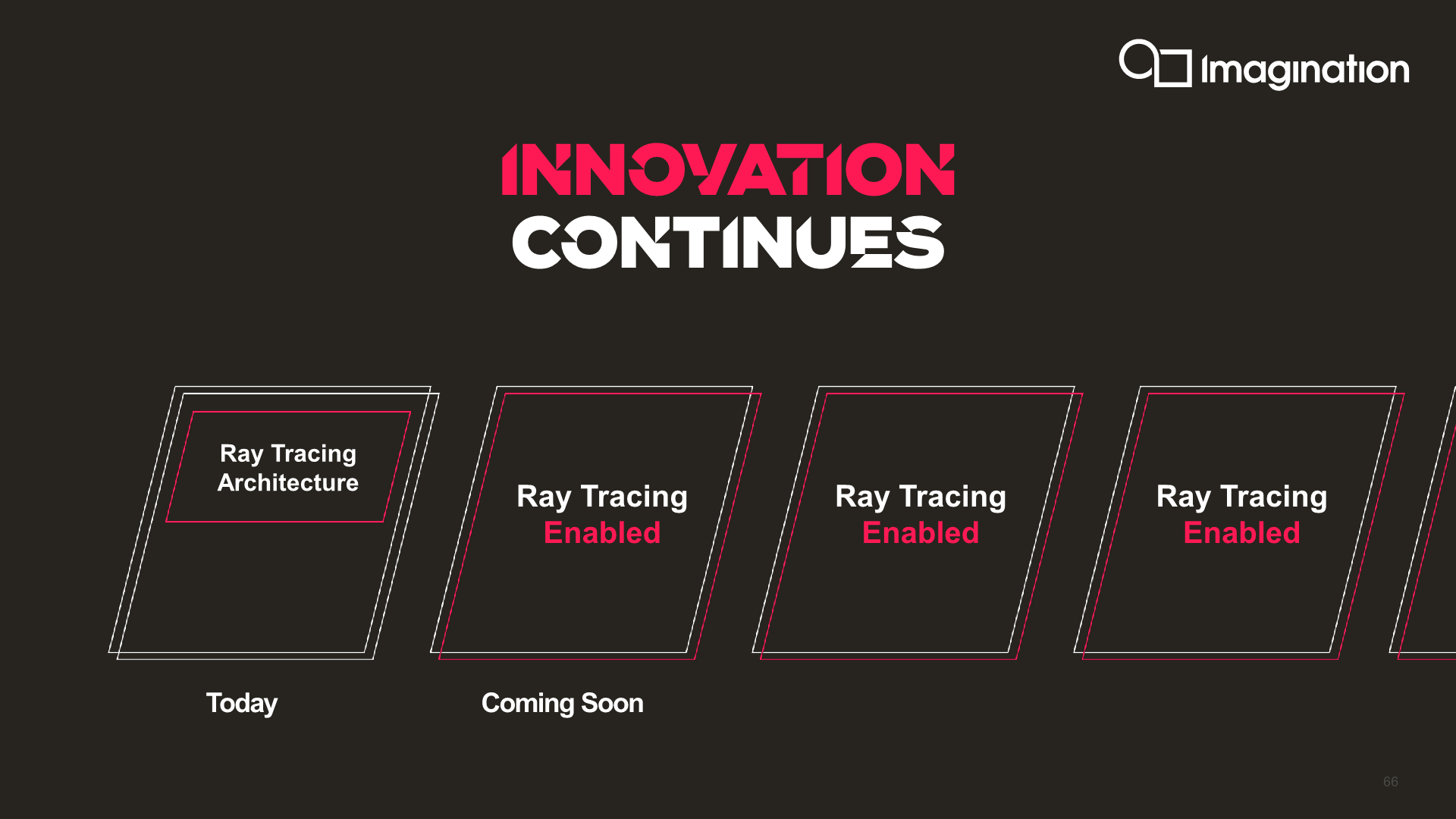
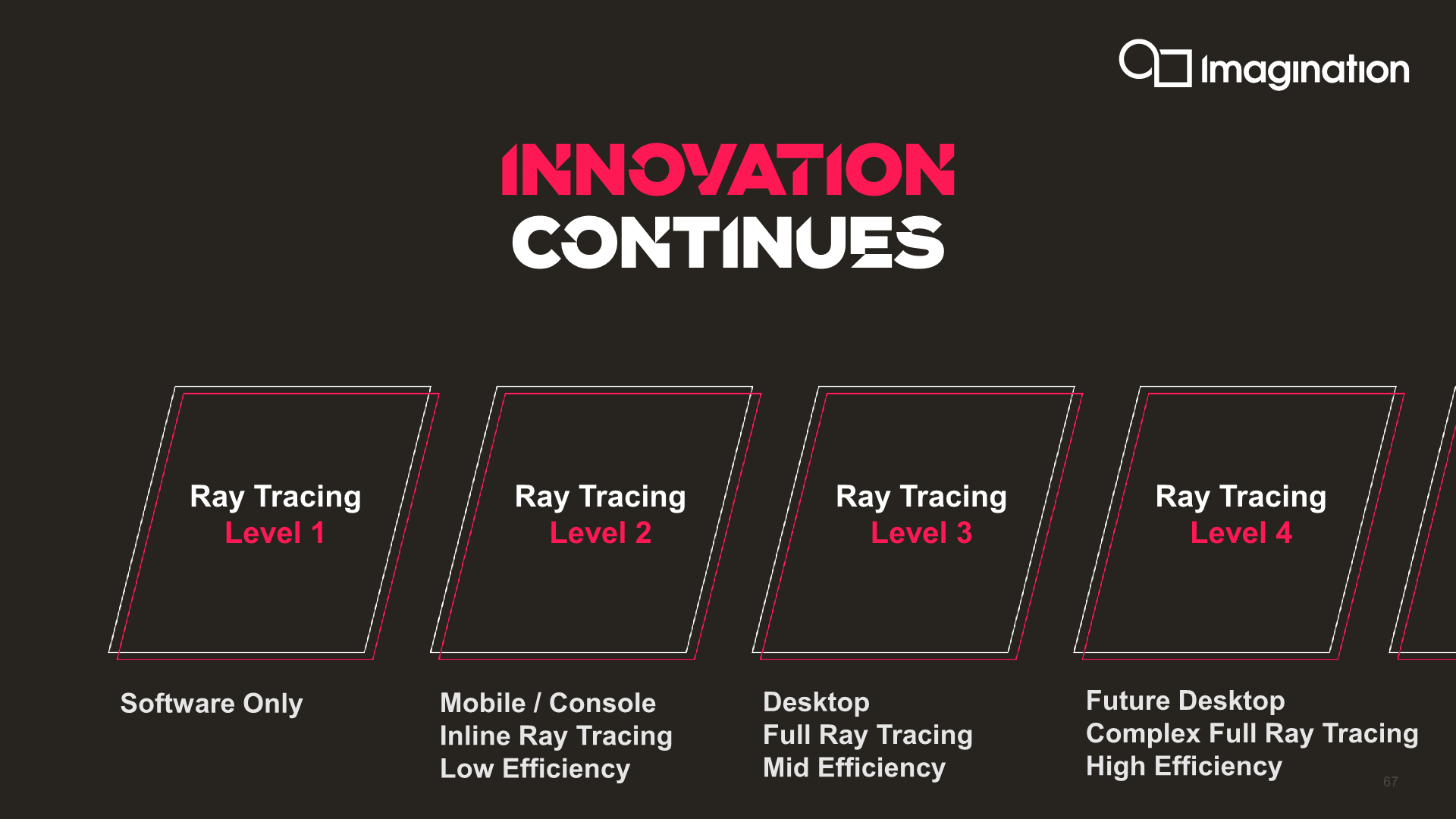
Beyond confirming that the new C-Series will have ray tracing capabilities, Imagination further confirms that this will be an implementation using the company’s fullest of capabilities, including BVH processing and Coherency Sorting in hardware, a capability the company denotes as a “Level 4” ray tracing implementation, which would be more advanced than what current generation Nvidia and AMD GPUs are able to achieve at a “Level 3”.
Imagination explains that they’ve had these capabilities for a long time, and when discussing with customers as to what kind of capabilities they would like to see in future IP, they had chosen to go for the full-blown implementation as this was the better future-proof design choice.
Overall, it seems like Imagination is on a path where it tries to diversify itself to markets other than the typical low-power GPU use-cases. The next few years will definitely be interesting for the company, and particularly the new distributed multi-GPU approach will be something to pay attention to.








74 Comments
View All Comments
Yojimbo - Tuesday, October 13, 2020 - link
I didn't know Xi JinPing was an engineer...EthiaW - Wednesday, October 14, 2020 - link
Those chinese have only managed to outcast the former corporate leaders recently. The shift from engeneer culture will take time, if not reverted by the UK government.Yojimbo - Wednesday, October 14, 2020 - link
They had the stubbornness to not be bought by Apple in order to be bought by the Chinese government. And through what will or method is the UK government going to change the culture of the company?Yojimbo - Tuesday, October 13, 2020 - link
Hey, you're right. He studied chemical engineering. I knew that, but forgot.melgross - Tuesday, October 13, 2020 - link
With Apple being 60% of their sales, and 80% of their profits, they demanded $1 billion from Apple, which refused that ridiculous price.The company is likely worth no more than $100 million, if that, considering their sales are now just about $20 million a year.
colinisation - Tuesday, October 13, 2020 - link
Well if not Apple why not ARM, I know ARM tried to buy them at some point in the past.But once Apple left their valuation would have taken a pretty substantial hit and ARM's GPU IP is successful but I don't think it is the most Area/Power efficient so it looked to me to be something they would have explored both would have been in the same country, maybe it would have spurred ARM into providing a more viable alternative to Qualcomm in the smartphone GPU space.
CiccioB - Tuesday, October 13, 2020 - link
"Whereas current monolithic GPU designs have trouble being broken up into chiplets in the same way CPUs can be, Imagination’s decentralised multi-GPU approach would have no issues in being implemented across multiple chiplets, and still appear as a single GPU to software."There's not problem in splitting today desktop monolithic GPUs into chiplets.
What is done here is to create small chiplets that have all the needed pieces as a monolithic one. The main one is the memory controller.
Splitting a GPU over chiplets all having their own MC is technically simple but makes a mess when trying to use them due to the NUMA configuration. Being connected with a slow bus makes data sharing between chiplets almost impossible and so needs the programmer/driver to split the needed data over the single chiplet memory space and not make algorithms that share data between them.
The real problem with MCM configuration is data sharing = bandwidth.
You have to allow for data to flow from one core to another independently of its physical location on which chiplet it is. That's the only way you can obtain really efficient MCM GPUs.
And that requires high power+wide buses and complex data management with most probably very big caches (= silicon and power again) to mask memory latency and natural bandwidth restriction as it is impossible to have buses as fast as actual ones that connect 1TB/s to a GPU for each chiplet.
As you can see to make their GPUs work in parallel in HCP market Nvidia made a very fast point-to-point connection and created very fast switches to connect them together.
hehatemeXX - Tuesday, October 13, 2020 - link
That's why Infinity Cache is big. The bandwidth limitation is removed.Yojimbo - Tuesday, October 13, 2020 - link
Anything Infinity is big, except compared to a bigger Infinity.CiccioB - Tuesday, October 13, 2020 - link
It is removed just for the size of the cache.If you need more than that amount of data you'll still be limited to bandwidth limitation.
With the big cache latency now added.
If it were so easy to reduce the bandwidth limitations anyone would just add a big enough cache... the fact is that there's no a big enough cache for the immense quantity of data GPUs work with, unless you want all your VRAM as a cache (but then you won't be connected with such a limited bus).