The Samsung 980 PRO PCIe 4.0 SSD Review: A Spirit of Hope
by Billy Tallis on September 22, 2020 11:20 AM ESTWhole-Drive Fill
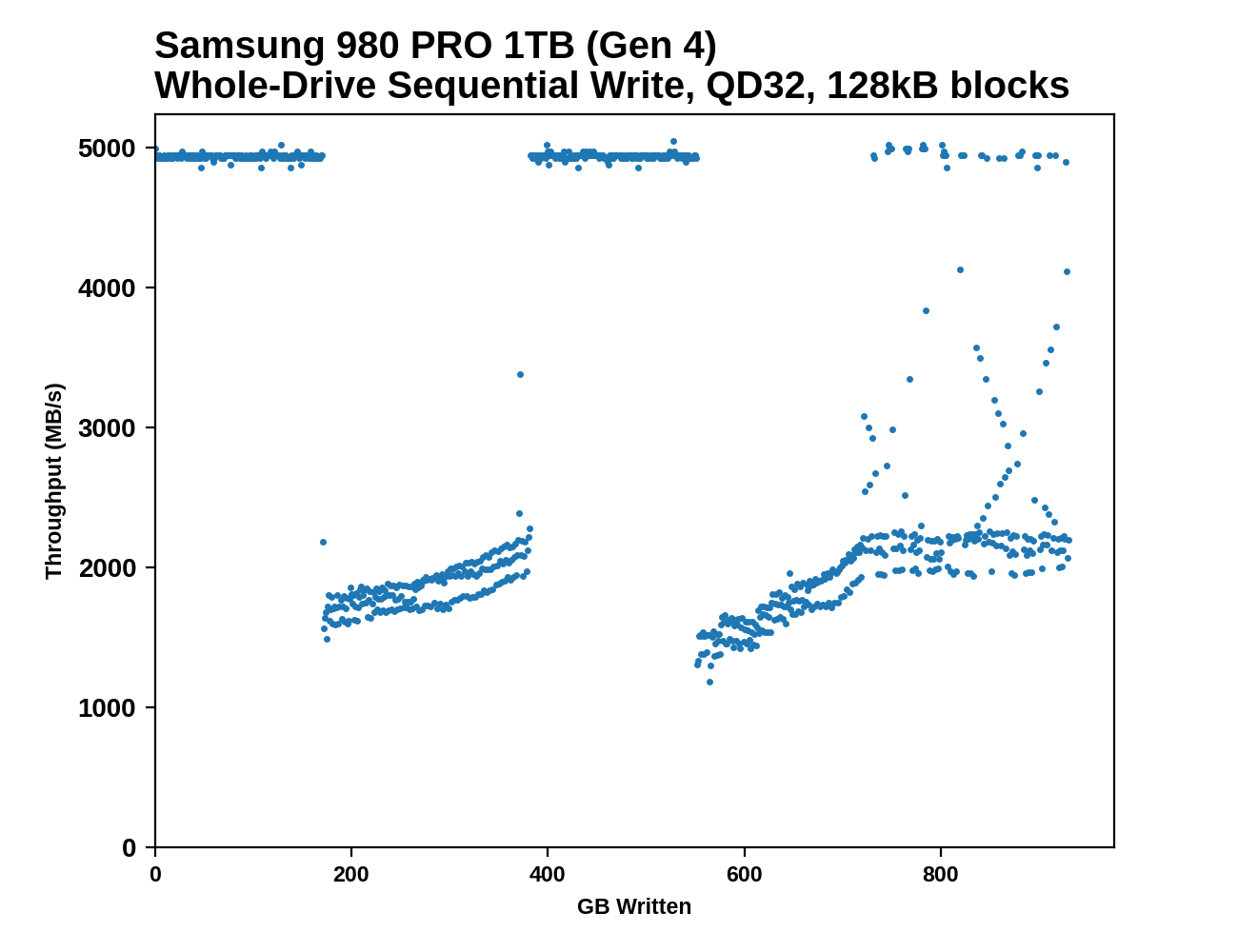
This test starts with a freshly-erased drive and fills it with 128kB sequential writes at queue depth 32, recording the write speed for each 1GB segment. This test is not representative of any ordinary client/consumer usage pattern, but it does allow us to observe transitions in the drive's behavior as it fills up. This can allow us to estimate the size of any SLC write cache, and get a sense for how much performance remains on the rare occasions where real-world usage keeps writing data after filling the cache.
 |
|||||||||
Both tested capacities of the 980 PRO perform more or less as advertised at the start of the test: 5GB/s writing to the SLC cache on the 1TB model and 2.6GB/s writing to the cache on the 250GB model - the 1 TB model only hits 3.3 GB/s when in PCIe 3.0 mode. Surprisingly, the apparent size of the SLC caches is larger than advertised, and larger when testing on PCIe 4 than on PCIe 3: the 1TB model's cache (rated for 114GB) lasts about 170GB @ Gen4 speeeds and about 128GB @ Gen3 speeds, and the 250GB model's cache (rated for 49GB) lasts for about 60GB on Gen4 and about 49GB on Gen3. If anything it seems that these SLC cache areas are quoted more for PCIe 3.0 than PCIe 4.0 - under PCIe 4.0 however, there might be a chance to free up some of the SLC as the drive writes to other SLC, hence the increase.
An extra twist for the 1TB model is that partway through the drive fill process, performance returns to SLC speeds and stays there just as long as it did initially: another 170GB written at 5GB/s (124GB written at 3.3GB/s on Gen3). Looking back at the 970 EVO Plus and 970 EVO we can see similar behavior, but it's impressive Samsung was able to continue this with the 980 PRO while providing much larger SLC caches—in total, over a third of the drive fill process ran at the 5GB/s SLC speed, and performance in the TLC writing phases was still good in spite of the background work to flush the SLC cache.
 |
|||||||||
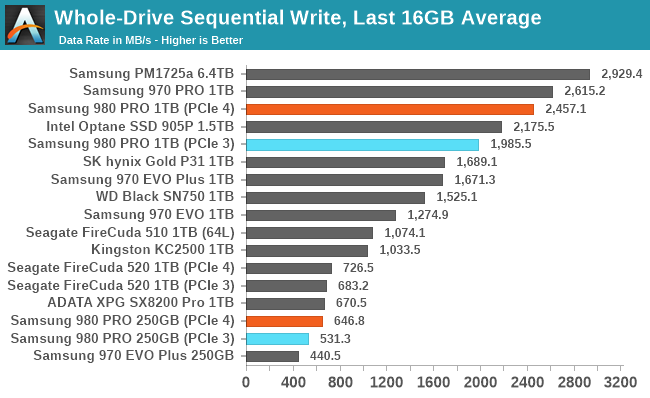
| Average Throughput for last 16 GB | Overall Average Throughput | ||||||||
On the Gen4 testbed, the overall average throughput of filling the 1TB 980 PRO is only slightly slower than filling the MLC-based 970 PRO, and far faster than the other 1TB TLC drives. Even when limited by PCIe Gen3, the 980 Pro's throughput remains in the lead. The smaller 250GB model doesn't make good use of PCIe Gen4 bandwidth during this sequential write test, but it is a clear improvement over the same capacity of the 970 EVO Plus.
Working Set Size
Most mainstream SSDs have enough DRAM to store the entire mapping table that translates logical block addresses into physical flash memory addresses. DRAMless drives only have small buffers to cache a portion of this mapping information. Some NVMe SSDs support the Host Memory Buffer feature and can borrow a piece of the host system's DRAM for this cache rather needing lots of on-controller memory.
When accessing a logical block whose mapping is not cached, the drive needs to read the mapping from the full table stored on the flash memory before it can read the user data stored at that logical block. This adds extra latency to read operations and in the worst case may double random read latency.
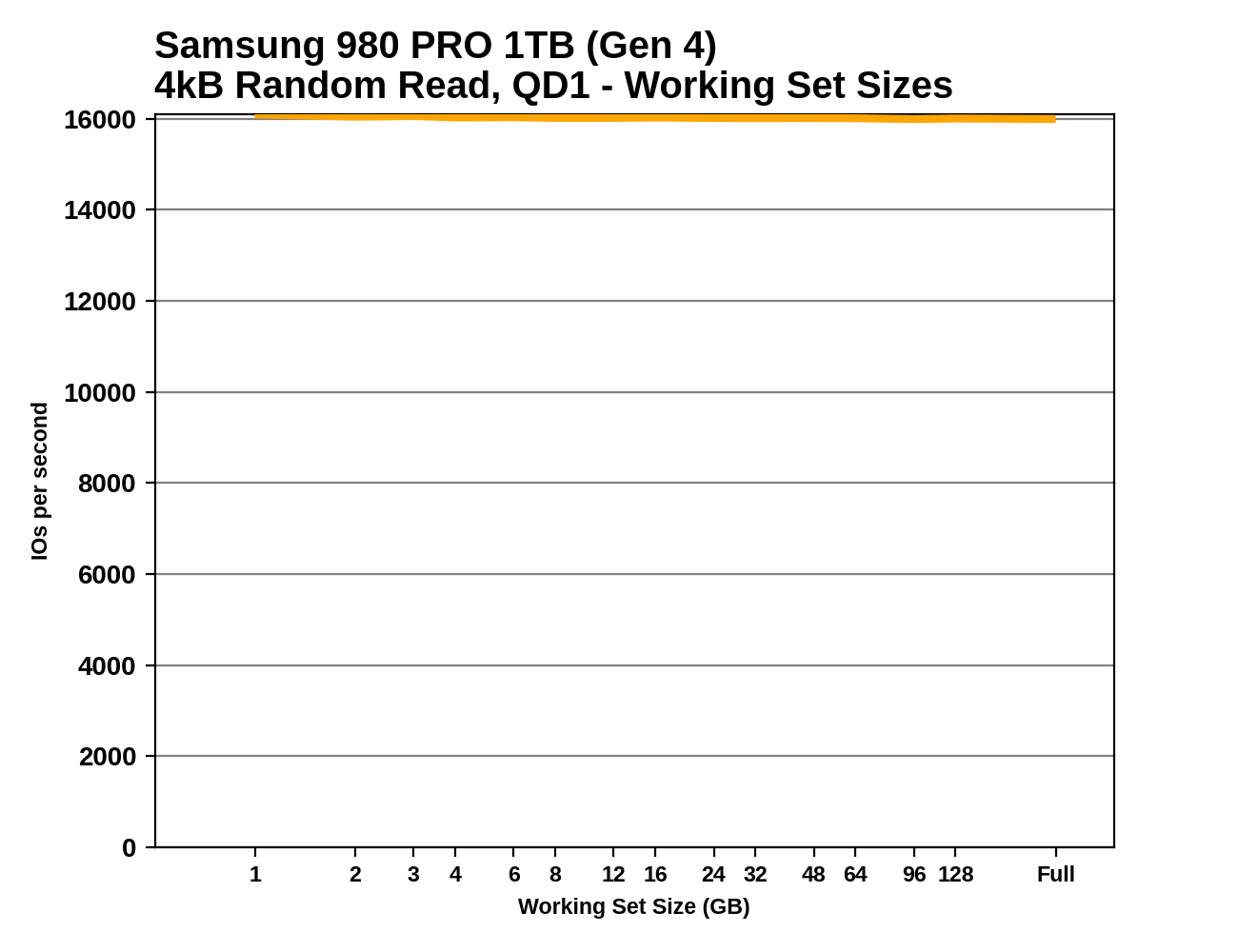
We can see the effects of the size of any mapping buffer by performing random reads from different sized portions of the drive. When performing random reads from a small slice of the drive, we expect the mappings to all fit in the cache, and when performing random reads from the entire drive, we expect mostly cache misses.
When performing this test on mainstream drives with a full-sized DRAM cache, we expect performance to be generally constant regardless of the working set size, or for performance to drop only slightly as the working set size increases.
 |
|||||||||
Since these are all high-end drives, we don't see any of the read performance drop-off we expect from SSDs with limited or no DRAM buffers. The two drives using Silicon Motion controllers show a little bit of variation depending on the working set size, but ultimately are just as fast when performing random reads across the whole drive as they are reading from a narrow range. The read latency measured here for the 980 PRO is an improvement of about 15% over the 970 EVO Plus, but is not as fast as the MLC-based 970 PRO.








137 Comments
View All Comments
Luckz - Thursday, September 24, 2020 - link
At reasonable things like 4K random IOPS, the 1TB P31 seems to crush the 2TB Evo Plus.Notmyusualid - Tuesday, October 6, 2020 - link
@ Hifi.. - yes totally agree on the latency.That is why TODAY I just received my 1TB 970 Pro for my laptop. Even choosing it over the 980's... it was the Avg write latency table that sealed the deal for me. (See ATSB Heavy / Write)
My Toshiba X5GP 2TB (supposedly enterprise class ssd) is not able to keep up with the huge writes my system endures most days. My write performance drops by about 10x, and when I replay my data, there are clear drop-outs.
The loss of capacity will be a pain, but I'll push old data to the 2TB, as reads on that disk are normal, and if I need to work on a data set, I'll just have to pull it across to the 970 Pro again.
My 2c.
romrunning - Tuesday, September 22, 2020 - link
What this review has done for me is to whet my appetite for an Optane drive. I'm looking forward to seeing how the new AlderStream Optane drives perform!viktorp - Wednesday, September 23, 2020 - link
Right here with you. Goodbye Samsung, nice knowing you.Will advise all my clients to stay away form Samsung for mission critical storage.
Wish we had a choice of selecting SLC, MLC, TLC, trading capacity for reliability, if desired.
_Rain - Wednesday, September 23, 2020 - link
For the sake of your clients, please advice them to use enterprise drives for mission critical storage.Those Qvos, Evos and Pros are just client storage drives and not meant for anything critical.
and of course you can limit the drives capacity to lesser value in order to gain some spare endurance. For example quote 384GB on 512GB drive will definitely double your endurance.
FunBunny2 - Wednesday, September 23, 2020 - link
"please advice them to use enterprise drives for mission critical storage."does anyone, besides me of course, remember when STEC made 'the best enterprise' SSD? anybody even know about STEC? or any of the other niche 'enterprise' SSD vendors?
XabanakFanatik - Tuesday, September 22, 2020 - link
It's almost like my comment on the previous article about the anandtech bench showing the 970 Pro is still faster due to the move to TLC were accurate.On the random, when the 980 beats the 970 pro it's by the smallest margin.
Samsung has really let the professionals like myself that bought pro series drives exclusively down.
Not to mention over 2 years later than the 970 Pro and it's marginally faster sometimes outside raw burst sequential read/write.
Jorgp2 - Tuesday, September 22, 2020 - link
Don't all GPUs already decompress textures?And the consoles only have hardware compression to get the most out of their CPUs, same for their audio hardware, video decoders, and hardware scalers.
There's plenty of efficient software compression techniques, Windows 10 even added new ones that can be applied at the filesystem level. They have good compression, and very little overhead to decompress in real time.
Only downside is that it's a windows 10 feature, that means it's half baked. Setting the compression flag is ignored by windows, you have to compress manually every time.
Ryan Smith - Tuesday, September 22, 2020 - link
"Don't all GPUs already decompress textures?"Traditional lossy texture compression is closer to throwing data out at a fixed ratio than it is compression in the lossless sense. Compressed textures don't get compressed so much as texture units interpolate the missing data on the fly.
This is opposed to lossless compression, which is closer to ZIP file compression. No data is lost, but it has to be explicitly unpacked/decompressed before it can be used. Certain lossless algorithms work on compressed textures, so games store texture data with lossless compression to further keep the game install sizes down. The trade-off being that all of this data then needs uncompressed before the GPU can work on it, and that is a job traditionally done by the CPU.
jordanclock - Thursday, September 24, 2020 - link
This fast of a drive combined with DirectStorage has me very excited for this particular reason. Though, as I understand it, DirectStorage requires the game to explicitly call the API and thus needs to be built into the game, as opposed to a passive boost to every game.