Marvell Refocuses Thunder Server Platforms Towards Custom Silicon Business
by Andrei Frumusanu on August 28, 2020 4:00 PM EST- Posted in
- Servers
- CPUs
- Marvell
- Arm
- Enterprise
- Enterprise CPUs
- ThunderX3

Yesterday during Marvell’s quarterly earnings call, the company had made a surprise announcement that they are planning to restructure their server processor development team towards fully custom solutions, abandoning plans for “off-the-shelf” product designs.
The relevant earning call statements are as follows:
"Very much aligned with our growing emphasis on custom solutions, we are evolving our ARM-based server processor efforts toward a custom engagement model.
[…]
Having worked with them for multiple generations, it has become apparent that the long-term opportunity is for ARM server processors customized to their specific use cases rather than the standard off-the-shelf products. The power of the ARM architecture has always been in its ability to be integrated into highly customized designs optimized for specific use cases, and we see hyperscale data center applications is no different. With our breadth of processor know-how and now our custom ASIC capability, Marvell is uniquely positioned to address this opportunity. The significant amount of unique ARM server processor IP and technology we have developed over the last few years is ideal to create the custom processors hyperscalers are requesting.
Therefore, we have decided to target future investments in the ARM server market exclusively on custom solutions. The business model will be similar to our ASIC and custom programs where customers contribute engineering and mask expenses through NRE for us to develop and produce products specifically for them. We believe that this is the best way for us to continue to drive the growing adoption of ARM-based compute within the server market."
We’ve had the opportunity to make a follow-up call with the teams at Marvell to get a little more background on the reasoning for such a move, given that only 6 months ago during the launch of the ThunderX3, the company had stated they were planning to ship products by the end of this year.
Effectively, as we’ve come to understand it, is that Marvell views the Arm server market at this moment in time to be purely concentrated around the big hyperscaler customers which have specific requirements in terms of their workloads, which require specific architecture optimisations.
Marvell sees the market beyond these hyperscaler customers to not be significant enough to be of sufficient value to engage in, and thus the company prefers to refocus their efforts in towards closer collaborations with hyperscaler costumers and fulfilling their needs.
The statement paints a relatively bleak view of the open Arm server market right now; in Marvell’s words, they do not rule out off-the-shelf products and designs in several years’ time when and if Arm servers become ubiquitous, but that currently is not the best financial strategy for the current ecoysystem. That’s quite a harsh view of the market and puts into question the ambitions of other Arm server vendors such as Ampere.
The company seemed very upbeat about the custom semicon design business, and they’re seemingly seeing large amounts of interest in the latest generation 5nm custom solutions they’re able to offer.
The company stated during the earning call that it still plans to ship the ThunderX3 by the end of this year, however it will only be available through customer specific engangements. Beyond that, it’s looking for custom opportunities for their hyperscaler customers.
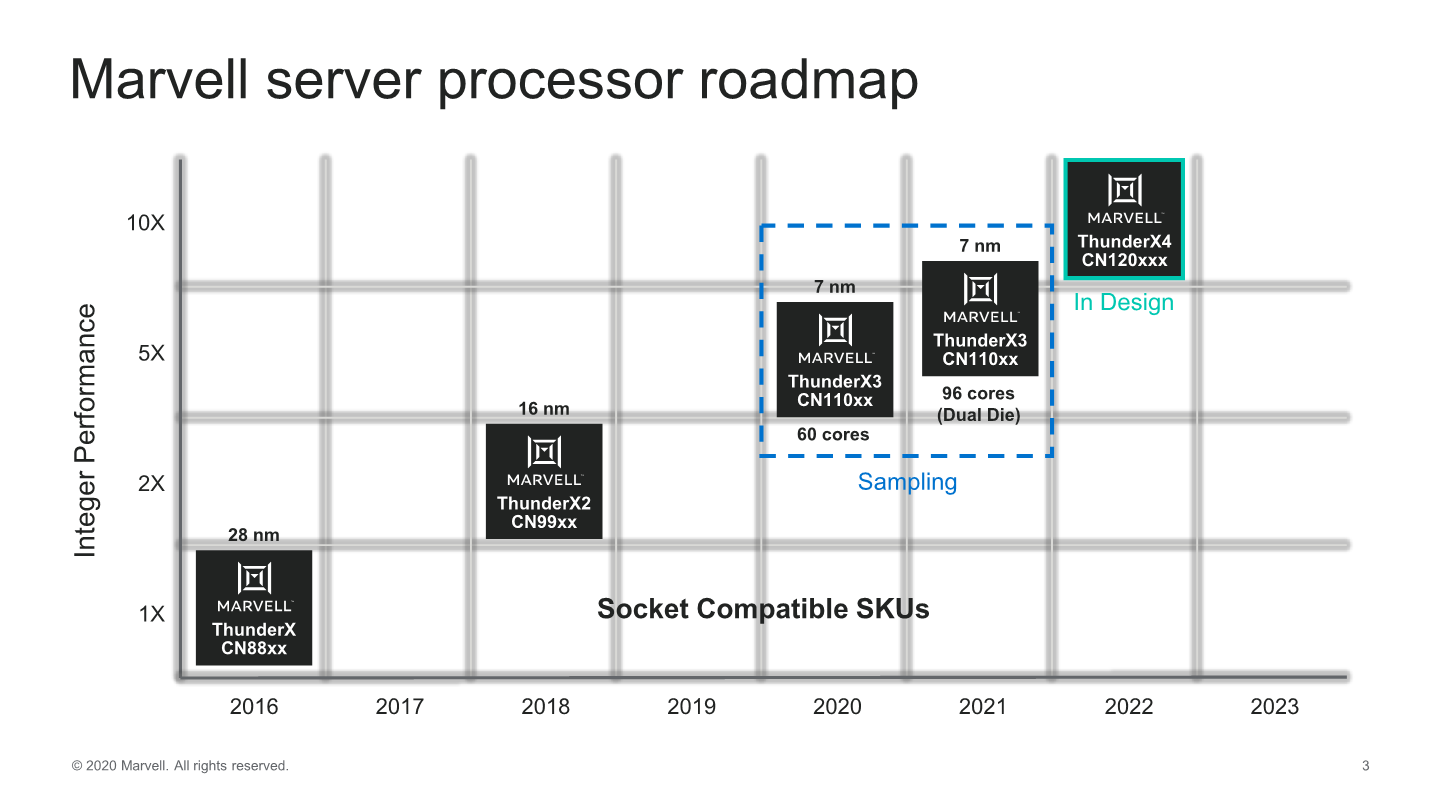
That also means we won't be seeing public availability for the dual-die TX3 product, and neither the in-design TX4 chip, which is unfortunate given that the company had presented their chip roadmap through 2022 only a few weeks ago at HotChips, which is now out of date / defunkt.
Although the company states that it’ll continue to leverage its custom IP for the future, I do wonder if the move has anything to do with Arm’s recent rise in the datacentre, and their very competitive Neoverse CPU microarchitectures and custom interconnects, essentially allowing anybody to design highly customizable products in-house, creating significant competition in the market.
From Marvell’s perspective, this all seems to make perfect sense as the company is simply readjusting towards where the money and maximum revenue growth opportunities lie. Having a hyperscaler win and keeping it is already a significant pie of the total market, and I think that’s what Marvell’s goal is here in the next several years.
Related Reading:
- Hot Chips 2020: Marvell Details ThunderX3 CPUs - Up to 60 Cores Per Die, 96 Dual-Die in 2021
- Hot Chips 2020 Live Blog: Marvell ThunderX3 (10:30am PT)
- Marvell Announces ThunderX3: 96 Cores & 384 Thread 3rd Gen Arm Server Processor
- Assessing Cavium's ThunderX2: The Arm Server Dream Realized At Last
- Marvell Unveils its Comprehensive Custom ASIC Offering
- Next Generation Arm Server: Ampere’s Altra 80-core N1 SoC for Hyperscalers against Rome and Xeon
- Ampere’s Product List: 80 Cores, up to 3.3 GHz at 250 W; 128 Core in Q4
- Amazon's Arm-based Graviton2 Against AMD and Intel: Comparing Cloud Compute








42 Comments
View All Comments
Industry_veteran - Thursday, September 3, 2020 - link
Wilco1,Your statement says,
"Previous attempts used older processes and the microarchitectures were not as advanced"
What is the basis of this claim?
Are you suggesting Marvell's ThunderX2 and 3 didn't have good microarchitecture so Marvell decided to pull the plug?
As far as your claim about Graviton 2 goes, all I will say is that even Amazon is not claiming this chip to be a general purpose server CPU SoC.
Wilco1 - Friday, September 4, 2020 - link
The AnandTech article says the 16nm TX2 is great on multithreaded code, however Centriq offered 50% more cores at much lower power by using 10nm. So which got most of the attention? TX3 is 7nm and looks like a huge improvement over TX2. But how does it compare with EPYC 2 or the 80-core Ampere Altra? We don't have reviews but I bet it's a similar situation.In terms of microarchitecture, I'm saying that previous generations Arm cores didn't get close enough to x86 on single-threaded performance. On SPECINT2017 Graviton 2 is within 6% of a 3.5GHz Xeon Platinum. Ampere Altra runs its Neoverse N1 cores at 3.3GHz (rather than 2.5), so its performance is equivalent to 4.3GHz Skylake. That's the kind of result that gets people excited.
Wilco1 - Saturday, September 5, 2020 - link
"As far as your claim about Graviton 2 goes, all I will say is that even Amazon is not claiming this chip to be a general purpose server CPU SoC."See https://aws.amazon.com/ec2/graviton/
"M6g
General Purpose
Best price performance for general purpose workloads with balanced compute, memory, and networking"
Built for: General-purpose workloads such as application servers, mid-size data stores, microservices, and cluster computing."
So stop making up FUD about Graviton 2 not being general purpose.
demian_thorne - Monday, August 31, 2020 - link
Thank you industry_veteran perhaps you should add to the list of your qustions what percentage of the total BOM for the entire server are the monetary savings? Ok enough said here.Let me make some additional comments on the test links provided:
1. KeyDB - absolutely no reference to what size DB was tested – so how can I evaluate the results? Then I clicked another link just to see If I can find more info and I came across other test results where it seems the memory GB tested was in double digits. A very meager number.
2. PHP – Wordpress page serving. Sure – not a bad test case where Graviton2 is mostly applicable but I am sorry what exactly is the $$$ size of market for serving simple wordpress pages?
3. Treasure Data CDP – Benchmark spec “In each case our experiment performs five warm up queries and then measures the average runtime of five queries to determine the performance”
Do you have anything with 500 queries? Or maybe 100?
All in all we are back where we started. Wilco1 you are providing SPECint type of tests. I am not arguing against that. What I am looking for as an example is:
Sample 1: Memory Subsystem bandwidth – Anandtech article
Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
Servers with 385 – 256 GBs
(not sure if links open but doing my best to provide them)
https://www.anandtech.com/show/11544/intel-skylake...
Sample 2: SAP S&D 2-Tier – Anandtech article
The Intel Xeon E5 v4 Review: Testing Broadwell-EP With Demanding Server Workloads
https://www.anandtech.com/show/10158/the-intel-xeo...
Do you have meaningful practical stuff like that? I am all ears. The tests you provide do not cover what I think the market is – no point continuing this if you don’t have what I am asking.
I am going to let the hyperscalers give you their answer ….
Wilco1 - Tuesday, September 1, 2020 - link
AnandTech did measure memory latency and bandwidth on Graviton 2: https://www.anandtech.com/show/15578/cloud-clash-a...Latency is on par with EPYC1 and Xeon Platinum. The memory bandwidth results are incredible, Graviton is able to show an almost flat line across the memory hierarchy and 4 times the per-core store bandwidth into DRAM! Total memory bandwidth also beats the Intel and AMD chips by a huge margin.
So all the benchmarks are extremely competitive. If you want something more specific that isn't covered today, you can always run benchmarks yourself. Graviton 2 is easy to access and cheap. Also remember Graviton 2 is the lowest performance level you can expect from Arm servers. Ampere Altra is 30% faster per core and can offer 80-128 cores. Hyperscalers will love those, that's for sure!
Quantumz0d - Friday, August 28, 2020 - link
As always, ARM is custom and will be custom. On mobiles (Without the Qcomm CAF and their proprietary blobs it wont work and cannot do shiz to fix, we lost OMAP that was biggest shame), ultra portables (MS SQ1). People were beating their chests that Intel and x86 is dead, AMD is also dead. Bullshit peaking esp when Apple announced their own silicon (for less than 10% of global share, and same for their own revenue, paying Intel was meaningless when its generating so much less and on top they poured billions into their A series and TSMC), today they announced own search engine, why ? Apple wants to control everything vertically to lock their consumers more, if their base evaporates, they cannot survive unlike x86 and Windows, as they have mass reach and all DoD, Military and Govt as well.Qualcomm Centriq was top as per their advertising and look where did it go, they abandoned and chopped off the entire R&D. Graviton is also custom for AWS, this is not going to beat x86 nor overtake it.
x86 will be always superior because of the software, and adoption rate and its too much deep into the everyday world and hard to decouple for the time being on the Semi conductor technology based computing. And thankfully the world is not revolving around bs custom, consumers have choice and can mix and match along with DIY which is the major aspect for any personal computing space.
FunBunny2 - Saturday, August 29, 2020 - link
"Apple wants to control everything vertically to lock their consumers more"Henry Ford built a 'plant', really a whole town, that took in all the raw materials needed to build an auto at one end and spit out autos at the other. the problem with that approach is the one faced these days by CxO's: the more automated (read: capital intensive) the production process, the less flexible, from a finance point of view, it is to output. by eliminating all that labor, they're left with little way to cut costs if output must decrease. ya still gotta pay for the machines.
whether Apple is able to maintain output, at a profit, is the big question. yes, at full capacity, Apple or Ford got to reap the profit from making all those intermediate widgets that would otherwise accrue to suppliers. but only if output never flags.
rahvin - Saturday, August 29, 2020 - link
Qualcomm abandoning Centriq was because of an activist investor wanting quick payouts rather than investing in long term success. Qualcomm derives 80% of their revenue from cell phone chips, if something happens to that market the company is gone. The abandonment of Centriq was IMO a stupid move.Wilco1 - Sunday, August 30, 2020 - link
Agreed - they had a great server already, 2nd generation almost finished and several big customers willing to commit and then just cancelled it all. Now that is a huge waste of money and engineering...brucethemoose - Friday, August 28, 2020 - link
"I do wonder if the move has anything to do with Arm’s recent rise in the datacentre, and their very competitive Neoverse CPU microarchitectures and custom interconnects, essentially allowing anybody to design highly customizable products in-house, creating significant competition in the market."Sounds right to me.
As the Marvell reps would say, why go in house when Marvell can do more of the heavy lifting for you?