2023 Interposers: TSMC Hints at 3400mm2 + 12x HBM in one Package
by Andrei Frumusanu on August 25, 2020 4:00 PM EST- Posted in
- TSMC
- HBM
- CoWoS
- TSMC Tech Day 2020

High-performance computing chip designs have been pushing the ultra-high-end packaging technologies to their limits in the recent years. A solution to the need for extreme bandwidth requirements in the industry has been the shifts towards large designs integrated into silicon interposers, directly connected to high-bandwidth-memory (HBM) stacks.
TSMC has been evolving their CoWoS-S packaging technology over the years, enabling designers to create bigger and beefier designs with bigger logic dies, and more and more HBM stacks. One limitation for such complex designs has been the reticle limit of lithography tools.
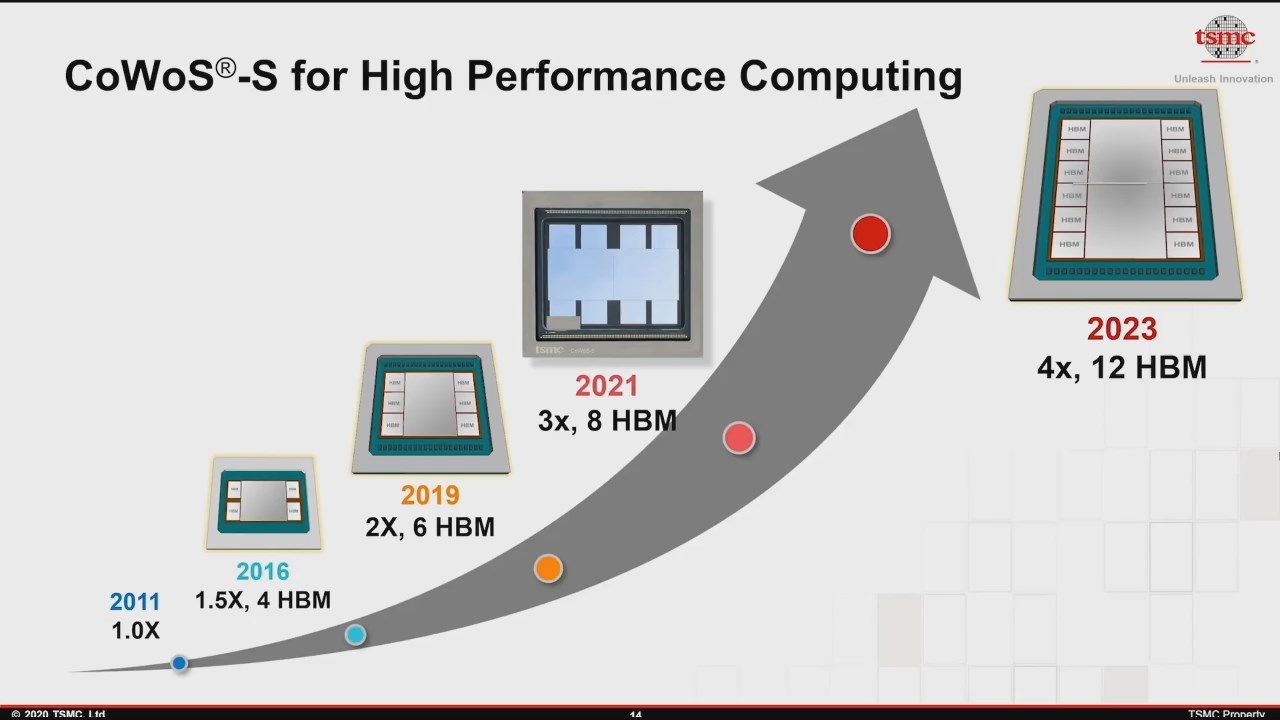
Recently, TSMC has been increasing their interpose size limitation, going from 1.5x to 2x to even projected 3x reticle sizes with up to 8 HBM stacks for 2021 products.
As part of TSMC’s 2020 Technology Symposium, the company has now teased further evolution of the technology, projecting 4x reticle size interposers in 2023, housing a total of up to 12 HBM stacks.
Although by 2023 we’re sure to have much faster HBM memory, a 12-stack implementation with the currently fastest HBM2E such Samsung's Flashbolt 3200MT/s or even SKHynix's newest 3600MT/s modules would represent at least 4.92TB/s to 5.5TB/s of memory bandwidth, which is multitudes faster than even the most complex designs today.
Carousel image credit: NEC SX-Aurora TSUBASA with 6 HBM2 Stacks
Related Reading
- TSMC Details 3nm Process Technology: Full Node Scaling for 2H22 Volume Production
- TSMC To Build 5nm Fab In Arizona, Set To Come Online In 2024
- TSMC & Broadcom Develop 1,700 mm2 CoWoS Interposer: 2X Larger Than Reticles
- TSMC Boosts CapEx by $1 Billion, Expects N5 Node to Be Major Success
- Early TSMC 5nm Test Chip Yields 80%, HVM Coming in H1 2020
- TSMC: 5nm on Track for Q2 2020 HVM, Will Ramp Faster Than 7nm
- TSMC: N7+ EUV Process Technology in High Volume, 6nm (N6) Coming Soon








34 Comments
View All Comments
Santoval - Wednesday, August 26, 2020 - link
"Processing speed and scads of memory aren’t enough. Even neural networks aren’t close to being enough."Er, have you ever heard of neuromorphic computing? This is computer *hardware* by the way, not yet another software based neural-xxx or xxx-learning approach. To sum it up : it is completely unrelated to Von Neumann computing, since it merges logic and memory as tightly as they can be merged, completely eliminating the Von Neumann bottleneck : all the memory is not just very close to the logic (say L1 or even L0 cache close); rather, memory and logic are the *same* thing, just like in a human brain. Thus there is zero transfer of instructions and data between the logic and memory, which raises the energy efficiency significantly.
The power and very high efficiency of this computing paradigm is derived from its massive parallelism rather than a conventional reliance on raw power, big cores, lots of fat memory etc etc Due to the massive parallelism the clocks are actually very low. Much of the processing happens at the level of the "synapses" between the "neurons" rather than at the neurons themselves, again I believe like in a human brain. Of course, the parallelism and complexity of a neuromorphic processor is *far* lower than those of a human brain (at least tens of thousands of times lower), but that's largely a technological limitation; it is not due to lack of knowledge or understanding. And technological limitations have a tendency to be dealt with in the future.
Besides, you do not really need to fully understand the human brain and how it functions because a neuromorphic processor is not a human brain copy; it is just inspired by a human brain. In other words, neural networks and all their deep, shallow, convoluted, back/forward propagated, generative, adversarial etc etc variants do not really need to run on "fast but dumb" Von Neuman computers. There exists a computing paradigm that is more suitable, one even might call "more native" to them. And this computing paradigm just began, only a few years ago.
Dolda2000 - Wednesday, August 26, 2020 - link
>'Deep Learning' is very dumb, in vast parallel.It's not like you couldn't make a similar argument around neurons.
melgross - Wednesday, August 26, 2020 - link
Calm down. We have no idea how to do that. Back in the early 1950s, it was thought that human level intelligence would be reached in a few years. Yeah, that didn't happen. We don’t understand how our own minds work, much less how to do that with AI.Even if we’re able to make hardware that is powerful enough in a couple of decades, because that’s how long it will take, we have no idea how to code it.
Santoval - Wednesday, August 26, 2020 - link
An even more "could have been" scary thing is that if Dennard scaling had not collapsed in ~2005, the related Koomey's law had not started slowing down right after that as a result, and Moore's law had also not slowed down since then, our personal computers today would have single or dual (tops) core CPUs with a few hundreds of billions of transistors and a clock frequency in the 3 to 5 THz range (at the same TDP levels), i.e. roughly a thousand times faster than when clocks froze due to the end of Dennard scaling.Hence our personal computers would have had no need to move to parallel computing, but that would not have applied to supercomputers. These would have had the same THz clock range CPUs but thousands of them, so they would have been *far* faster. Maybe fast enough for a general AI or even a super-intelligent AI to spontaneously emerge in them.
I am half joking. I strongly doubt raw speed alone would be enough for that. If our computers were a thousand times faster but otherwise identical they would still be equally "dumb" machines that just processed stuff a thousand times faster. On the other hand though, computing approaches like neuromorphic computing are distinctly different. They explicitly mimic how brains work, embracing *massive* parallelism at a very high efficiency and very low clocks. These *might* provide the required hardware for a potential Skynet-ish general AI to run on in the future, or the combination of their hardware and a matching AI software might serve as the catalyst for the spontaneous emergence of a general AI (out of, perhaps, many specialized AIs). Our dumb computers, in contrast, are almost certainly harmless - at the moment anyway..
Things will become less clear though if neuromorphic computing starts showing up in our computers, either in the form of distinct "accelerators" or as IP blocks in the main processor... As far as I know this has not yet happened. The "neural network accelerators" that started to be included in some SoCs (mostly mobile ones) and in GPUs relatively recently are something entirely different.
If I was a betting man and was asked to bet on which of these three computing paradigms a Skynet-like event might emerge from in the future : classical (Von Neumann) computing, quantum computing and neuromorphic computing, I would certainly bet on the last one. If you look up how they work their similarities to a human brain are frankly scary.
deil - Wednesday, August 26, 2020 - link
you guys are unaware that that most of human procesing power goes for making our input and output interpreted and memorized.we use our count for shared compute and storage so in a way current xeons/epyc are already smarter than humans. Thing is that all they can do is what we send, as their systems are not and will not be self-adjusting. Unless software will have an option to adjust (grow) hardware for itself, we are safe.
melgross - Wednesday, August 26, 2020 - link
No, they’re not “smarter”. They are incredibly dumb. We’re safe because as you also said, it’s software. We need to have an entirely new paradigm for AI before it make a serious advance over what it is now.quorm - Tuesday, August 25, 2020 - link
Please don't listen to Elon Musk. He's a salesman, not a scientist.ads295 - Wednesday, August 26, 2020 - link
He may not be a scientist but he's a brilliant engineer...rscsr90 - Wednesday, August 26, 2020 - link
in what way? He always disregards engineering challenges and feeds the hype train. Sounds like a salesman to me.psychobriggsy - Wednesday, August 26, 2020 - link
No, he is a good project manager, and he just has the money to fund the creation of his near-future science fiction ideas.