Hot Chips 2020: Marvell Details ThunderX3 CPUs - Up to 60 Cores Per Die, 96 Dual-Die in 2021
by Andrei Frumusanu on August 17, 2020 4:30 PM EST- Posted in
- Servers
- CPUs
- Marvell
- Arm
- Enterprise
- Enterprise CPUs
- ThunderX3
The Triton CPU Core - Evolution From Vulcan
Moving on onto the core level, we see the first disclosures on Marvell’s new Triton CPU microarchitecture. The design is an evolution of the ThunderX2’s Vulcan cores with the company widening a lot of the aspects of the core, both in the front-end and on the back-end.
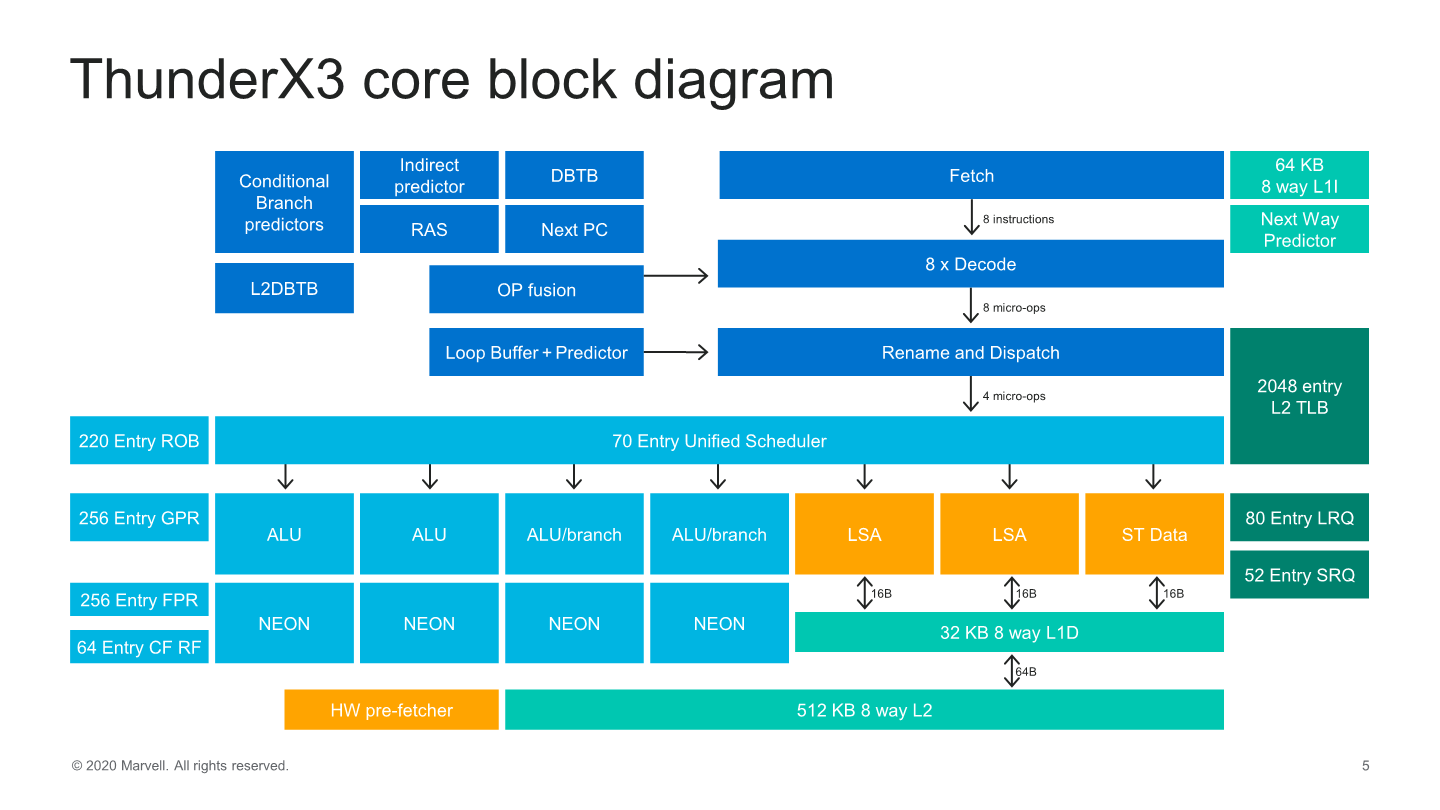
Starting off with the front-end side of the core, we see some very significant changes as we’ve almost seen a literal doubling of most structures and bandwidth in the core. The instruction cache has been doubled up from 32KB to 64KB, which now feeds into an 8-wife fetch unit, also double the previous generation.
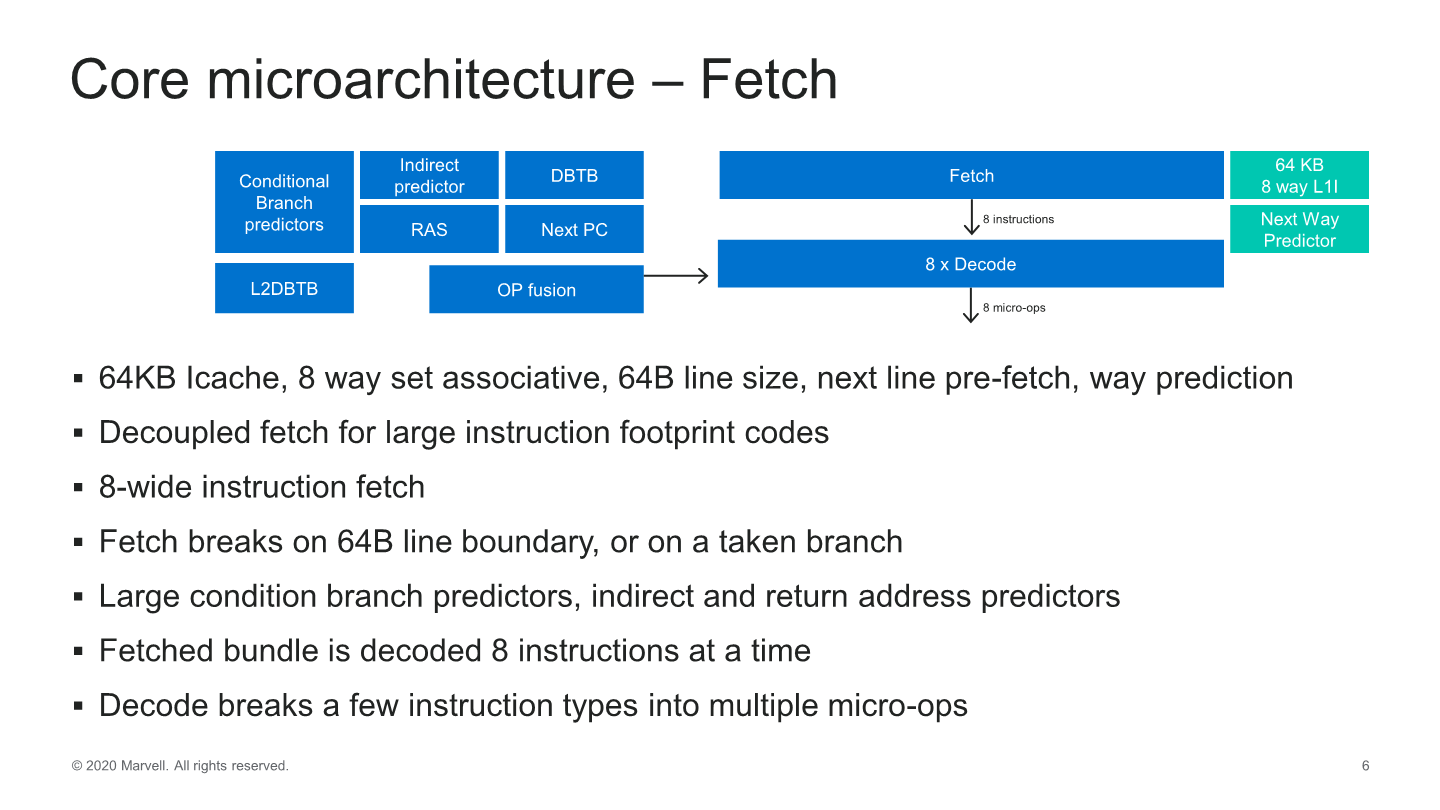
Much like Arm’s recent microarchitectures, this is a new decoupled fetch unit that allows for better power savings. The decode unit matches the fetch bandwidth at 8 instructions wide – which actually along with the Power10 core from IBM now represents the widest decoders in the industry right now, which is quite surprising.
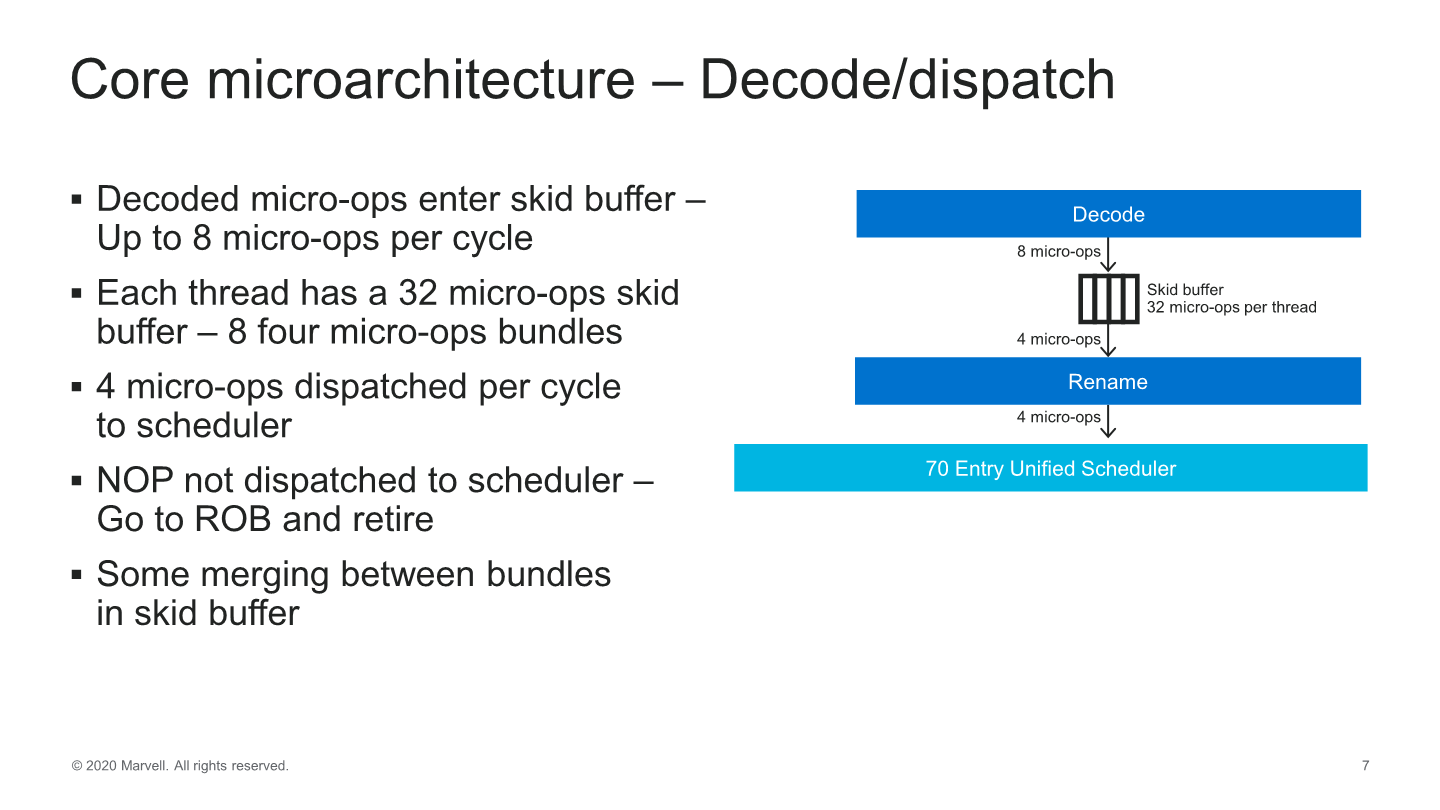
In the mid-core we see the decode unit feed into what Marvell calls a “Skid buffer”, which is essentially a loop buffer, which is segmented into 32 micro-ops per thread, further divided into eight four-wide micro-op bundles. It’s one of the rare structures in the core which is statically partitioned between threads, and it represents the boundary between the front-end and the mid-core of the microarchitecture.
The most interesting and confusing part of the Trition microarchitecture is at this part of the core, as even though the fetch and decode units of the core are 8-wide, micro-ops out of the Skid-buffer and into the rename unit and dispatched to the backend of the core only happens at 4 micro-ops per clock. So what seems to be happening here is that Marvell is taking advantage of a very wide front-end design not to actually feed a large back-end, but rather to better hide pipeline bubbles working in wider “bursts”.
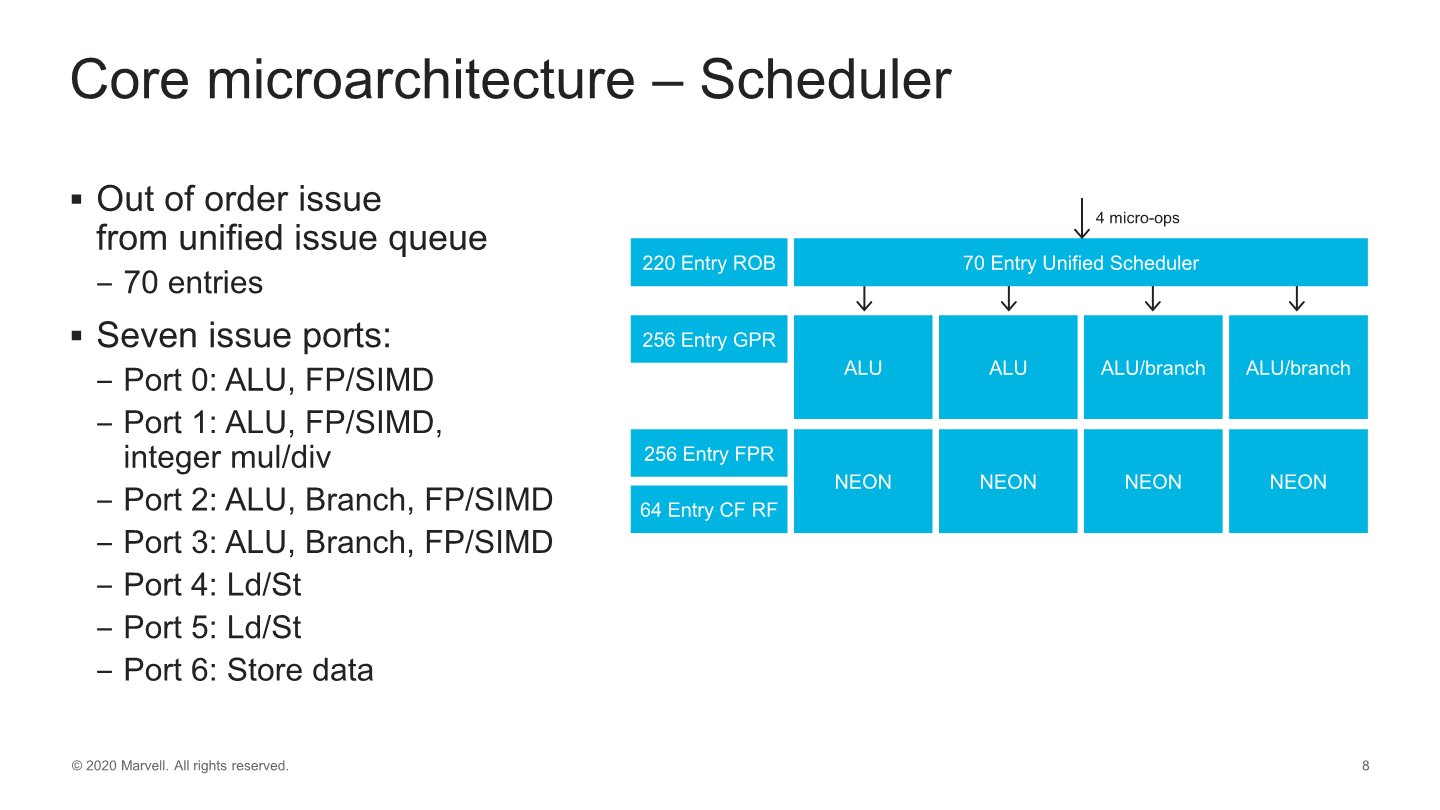
Dispatch into the backend of the core we see continued usage of a global unified scheduler that feeds into 7 execution ports. At the scheduler-level, we’ve seen a slight increase from 60 to 70 entries.
The out-of-order window of the core has increased slightly, such as the re-order buffer (ROB) growing from 180 to 220 entries.
On the execution ports, the big change has been the addition of a fourth execution pipeline capable of ALU instructions and a second branch port, meaning we’re seeing a 33% increase in simple integer ALU execution throughput and a doubling of the branch forwarding of the core. Alongside of these improvements, all four execution pipelines have been expanded with FP/SIMD capabilities which means there’s now a generational doubling of throughput for these instructions, making the Triton core one of the rare 4x128b machines out there.
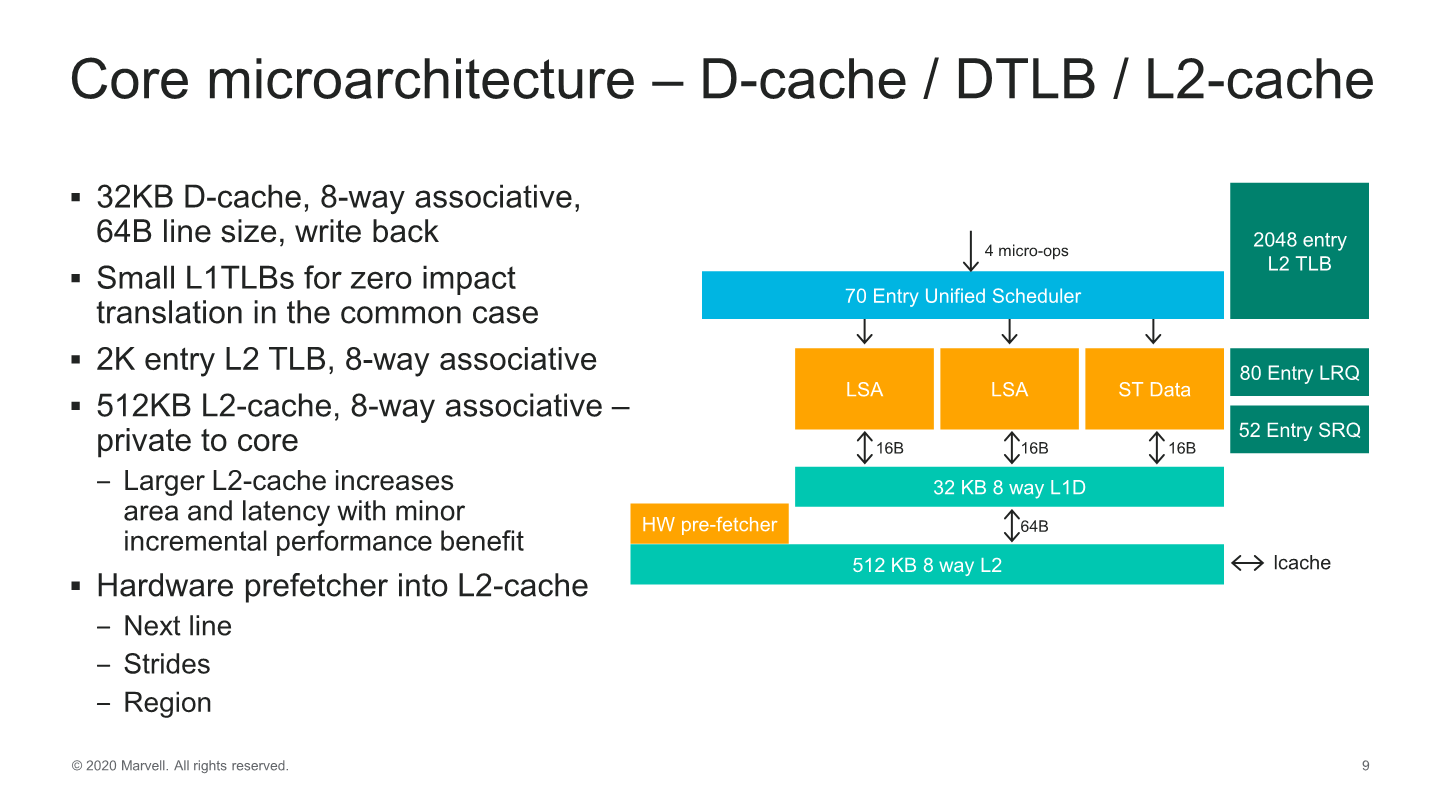
On the memory subsystem part of the core, improvements have been relatively small as we don’t seem to have major high-level changes of the microarchitecture. We still see two load-store units and a store data unit with bandwidths of 16 Bytes/cycle per unit feeding and fetching data from a 32KB L1 data cache. The load and store queues have been increased in their depth and have increased respectively from 64 to 80 entries for loads, and 36 to 48 entries for stores.
The core’s L2 has also doubled from 256KB to 512KB, but Marvell’s wording here on this change is interesting as they say it increases area and latency with only “minor incremental performance benefits”, which sounds quite disappointing in tone. We’ll see in the next slide this means 2.5%.
The hardware prefetchers are quite simplistic, with your traditional next-line, stride, and region-based designs pulling data into the L2.
Overall, generational IPC improvements of the new core sum up to 30% in SPECint, and Marvell was generous enough to give us an overview of the new core’s features and how each is accounts for the total improvement:
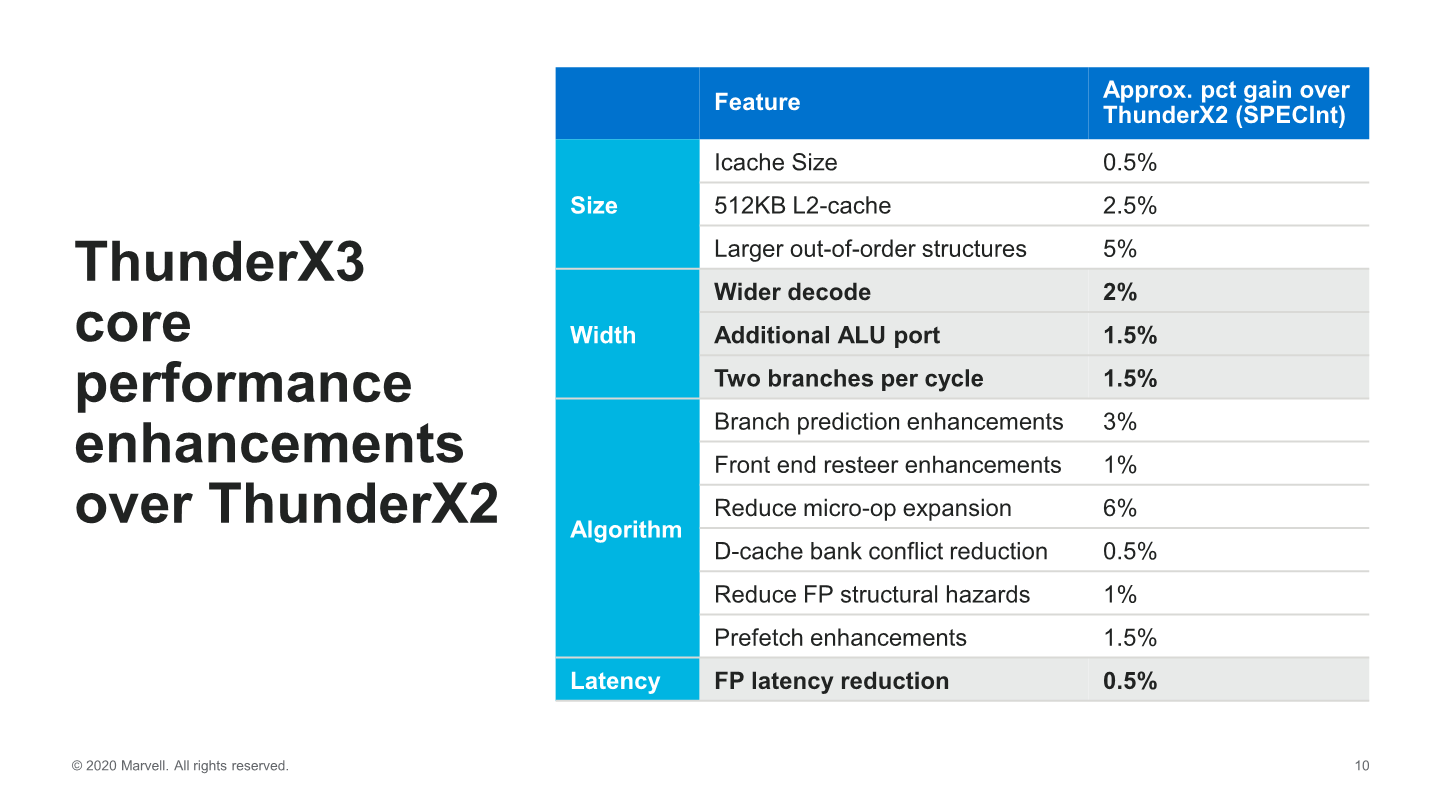
On the structure side increases of things, the biggest improvements were due to the larger OoO increases in the mid-core which, although the increases weren’t all that big, represent a 5% IPC improvement. This seems a quite good trade-off versus some other doubling of structures such as the L1I and the L2 cache increases which only got a 0.5% and 2.5% benefit.
The front-end’s doubling and wider decode from 4 to 8 only accounted for only 2% improvement in performance which is extremely tame, but is likely bottlenecked given the narrow mid-core dispatch and comparatively narrow execution back-end.
The biggest improvement in IPC was due to reduced micro-op expansion from the decoder – Marvell here stated that they had been too aggressive in this regard on the ThunderX2 Vulcan cores in expanding instructions into multiple micro-ops, so they’ve reduced this significantly, and this probably alleviating the bottleneck on the mid-core and resulting into better back-end utilisation per actual instruction.
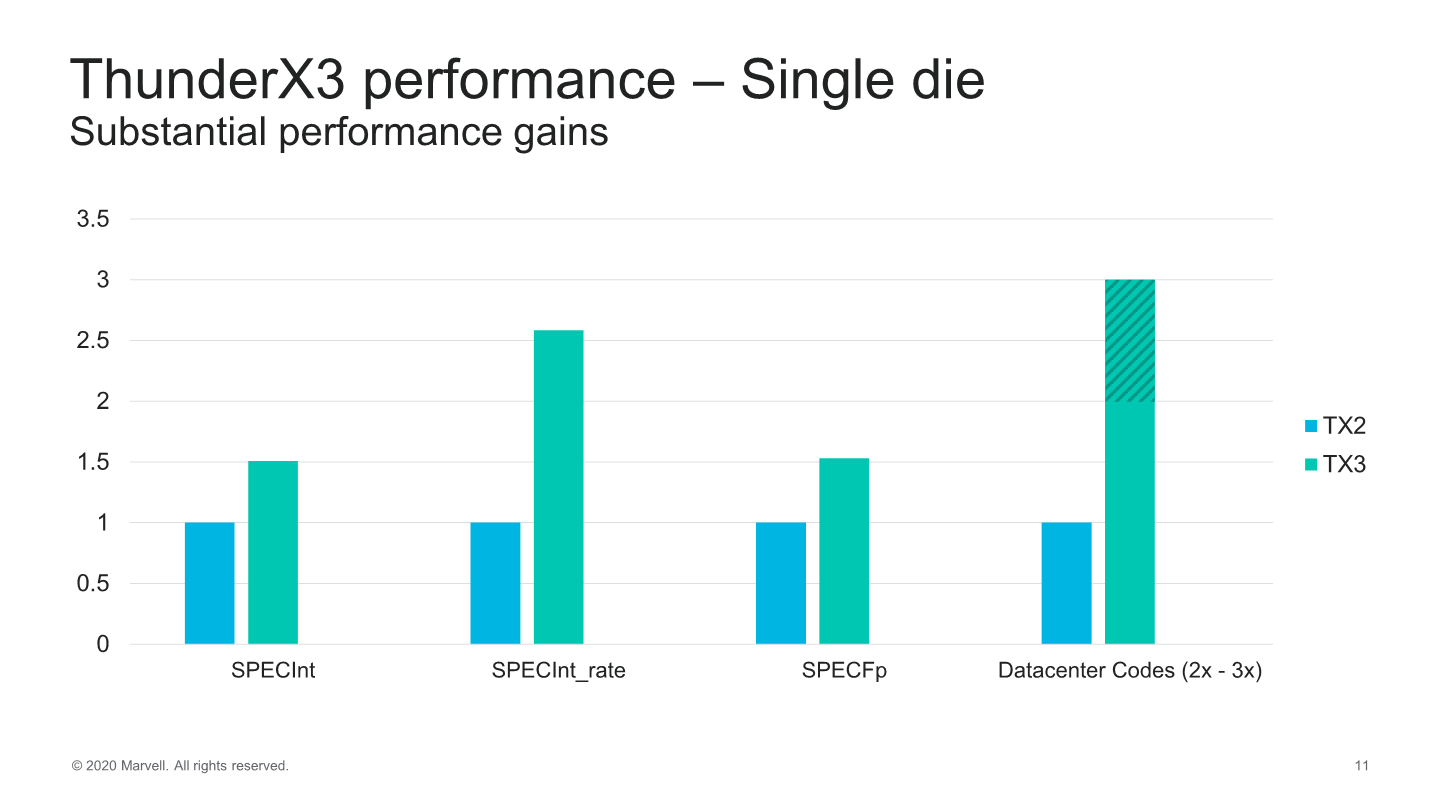
Generational performance improvements accounting for the IPC gains as well as frequency gains, we’re expected to see a 1.5x gain in SPECint. Given our historical numbers on the TX2, by these projections we should thus expect the TX3 to outperform the Graviton2 by around 10%.
SPECrate gains are naturally higher at around 2.5x the performance, thanks to the new design’s higher core count further amplifying the microarchitectural improvements.








27 Comments
View All Comments
Spunjji - Wednesday, August 19, 2020 - link
Good to know your opinions on the future of the CPU market are just as balanced, nuanced and well-informed as your political ramblings...Quantumz0d - Wednesday, August 19, 2020 - link
Better go back to your twitter and reeesetera and put more pronouns.And you don't even have any argument, you are stuck on that political comment. And you will be stuck there forever.
Gomez Addams - Wednesday, August 19, 2020 - link
Your diatribe entirely missed the point of why people are moving to ARM-based processors for servers and other purposes. In can be summarized in two words : power consumption. Server farms can save a lot of money using ARM processors compared to the equivalent horsepower from just about any other processor available. They are not moving to them for any performance advantage.Wilco1 - Thursday, August 20, 2020 - link
Lower power also means less cooling, fewer power supplies and higher density. Additionally Arm servers need less silicon area to get the same performance, so upfront cost of server chips is lower too (you avoid paying extortionate prices like you do for many x86 server chips).eek2121 - Tuesday, August 18, 2020 - link
The x86 market is not shrinking. This server offers no benefits over a modern AMD or Intel server.name99 - Tuesday, August 18, 2020 - link
Two years ago you could reasonably have said "there is no plausible ARM server".A year ago you could legitimately have said "sure, there are ARM servers (TX2, Graviton) but they suck".
This year the best you can say is "they offer no benefit over a modern AMD or Intel server" (actually already not true if you're buying compute from AWS).
You want to bet against this trajectory?
Next year? This was the year of matching x86 along important dimensions. Next year will be the year of exceeding x86 along important dimensions. Not ALL dimensions, that might take till 2022 or so, (there's still a reasonable amount of foundational work to do by all parties, like implementing SVE/2) but, as I said, the trajectory is clear.
Spunjji - Wednesday, August 19, 2020 - link
I have to agree with this assessment. People keep counting ARM designs out because they've taken a long time to ramp up to this level, but every year they get closer to being a notable force in the market, and every year the naysayers find another, smaller reason to point to for they'll never be successful.The simple truth is that ARM designs don't even have to beat x86 to take a slice of the market - they just have to offer *something*, be it cost benefits, lower idle power, improved security, or even just being an in-house design (a-la Amazon).
Spunjji - Wednesday, August 19, 2020 - link
Your last statement doesn't follow from - or lead to - the first one.Spunjji - Wednesday, August 19, 2020 - link
Shrinking? Sure, eventually. Fast? Not so sure.AWS transitioning makes sense for their own use, but they'll more than likely need to continue offering x86 for customers. Same goes for Google and Microsoft. Hard to predict how that will shake out at this juncture.
Apple aren't even close to 10% of the total x86 market, either - they're between 7.5% and 8% of the global *PC* market, which obviously doesn't include the server / datacentre market. That's still going to be a bit of a dent for Intel when the transition completes, but it's not nearly as bad for x86 on the whole as you're implying.
Competition is heating up, though. That's a good thing.
Gomez Addams - Tuesday, August 18, 2020 - link
This illustrates why I think Nvidia wants to own Arm. They have already stated they are porting CUDA to the ARM instruction set. I think this is because they want to make a processor suited for HPC and it will be ARM-based and here's why. First, think of how their GPUs are organized. They use streaming multiprocessors with a whole bunch of little cores. These days they have 64 cores per SM so that is essentially 64-way SMT. The thing is these cores are very, very simple with many limitations. I think they want to use ARM-based cores with something like 16-way SMT. If they use AMD's multi-chip approach they could make an MCM with a thousand ARM cores in one package. There would be no CPU-GPU pairing as we often see today. One MCM could run the whole show. This would entirely eliminate the secondary data transfers to a co-processor and make for an incredibly fast super computer with relatively low power consumption. I think this architecture would be a huge improvement over what they have.