The Intel Xe-LP GPU Architecture Deep Dive: Building Up The Next Generation
by Ryan Smith on August 13, 2020 9:00 AM EST- Posted in
- GPUs
- Intel
- Tiger Lake
- Xe
- Xe-LP
- DG1
- Intel Arch Day 2020
- SG1
Xe-LP Execution Units: It Takes Two
Diving down a level deeper, we have the smallest thread-level building block of the Xe-LP GPU architecture, the venerable Execution Unit. Intel has tweaked these a few times over the years, and for Xe-LP they are getting tweaked once again.
As a quick refresher, as of Intel’s Gen11 GPU architecture, an EU is comprised of a single thread control unit and two sets of 4-wide SIMDs. One block handles floating point and integer math, while the other block can handle floating point and special functions, which Intel refers to as “extended math”. Despite this, Gen11’s smallest wavefront width is 8 threads wide (SIMD8), so it can take multiple clock cycles to execute a single wavefront, with Intel interleaving multiple wavefronts as a form of latency hiding.
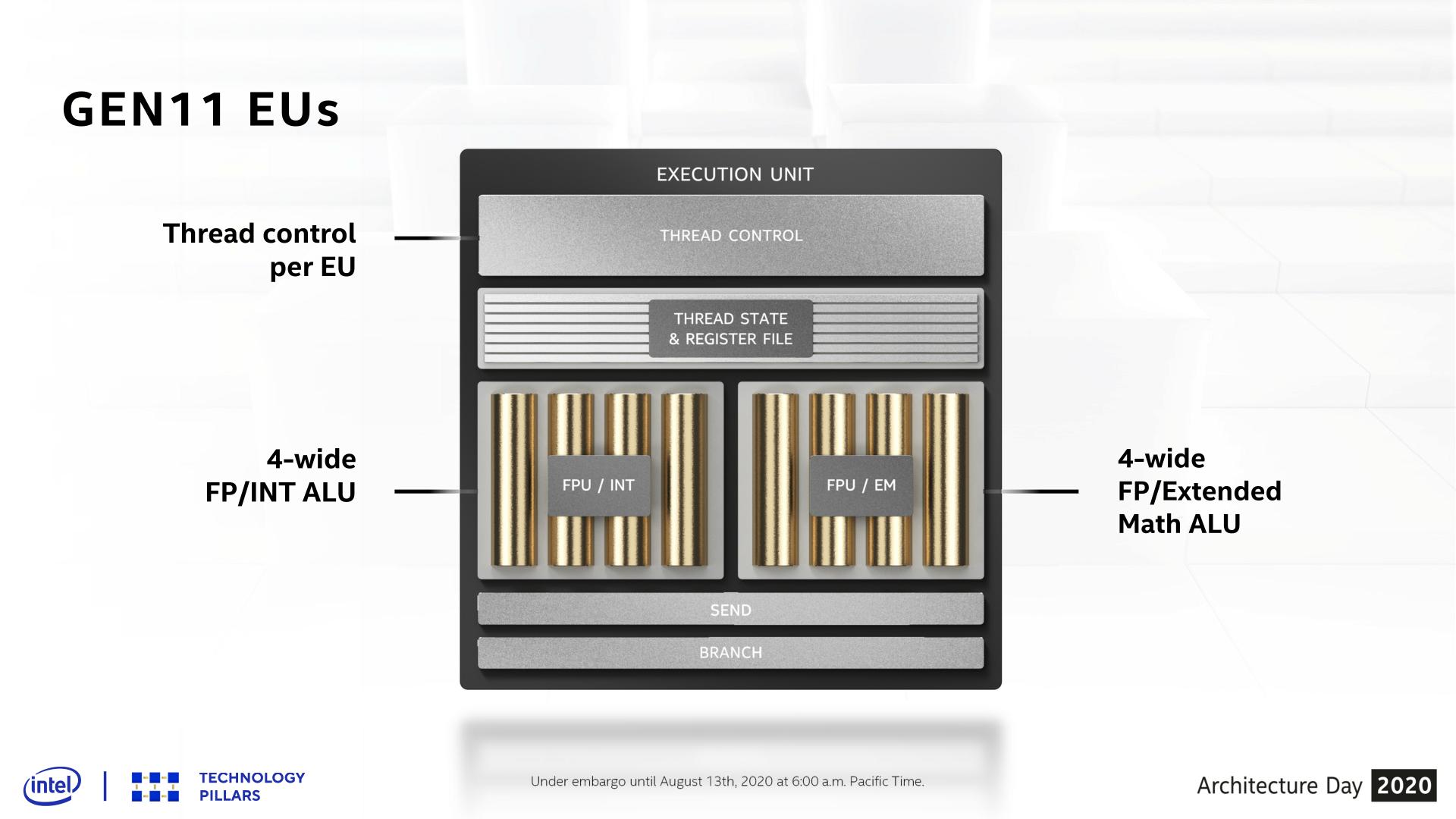
Xe-LP, meanwhile, brings several important changes to the design of the EUs. First and foremost, a single EU is no longer a stand-alone block; instead two EUs now share a single thread control unit. As a result, a thread control unit now gets the combined resource of two EUs to spread work over, instead of the one. And while the SIMD arrays themselves have also changed – further complicating matters – the impact here is that there are now fewer thread control units in a GPU, which should reduce the number of wavefronts that are in-flight at any given moment.
In fact there’s an argument to be had whether calling these dual EU setups two EUs is even the most accurate way to describe them; it might be better to instead bundle them together as a single fat EU, since neither half is truly independent. But absent further low-level details, and what I’m sure is a desire by Intel to be semi-consistent in counting EUs, they are going with 96 thin EUs.
Meanwhile regardless of how you bundle the EUs, there’s also the matter of what’s in the EUs themselves. For Xe-LP, Intel has reorganized the SIMD blocks. Gone are the pair of feature-differentiated SIMD4 blocks in favor of a SIMD8 block and a SIMD2 block. The larger SIMD8 essentially combines all of the floating point and integer ALUs that previously were split between Gen11’s two SIMD4 blocks, and makes a single SIMD8 out of them. The net result is that the number of FPU ALUs hasn’t changed – it’s still 8 ALUs per EU – however the number of pipes that can process integers has changed from 4 to 8. Meanwhile, although not made clear in Intel's slides, the number of ALUs that can process extended math is staying constant: Gen11 had two EM-capable pipes, and Xe-LP does as well.

Speaking of which, extended math has now been moved to its own SIMD2, and every EU gets one. This means that executing extended math functions no longer directly blocks the execution of floating point arithmetic, as was the case for Gen11 – the EU doesn’t have to give up FP pipes to do this. Further underscoring this point, the EU can co-issue instructions to both the FP/INT SIMD8 and the EM SIMD2 at the same time, meaning that under at least some circumstances, doing extended math also won’t indirectly block FP/INT arithmetic.

As always with co-issuing, the devil is in the details – at this point it’s not clear to us just what the co-issuing limitations are – but it’s still very likely to be a better fit to the kind of workloads Intel is actually seeing. AMD and NVIDIA also use dedicated EM/SFU units, and in similarly small ratios, all of which seems to work out well for those two companies. So in that respect Intel’s ALU setup is looking a lot more like its contemporary competitors’. And this, I suspect, is also one of the forms of bottleneck optimization that Intel has gone through to get more work out of the same number of FLOPs on Xe-LP.
These ALU changes also impact how wavefronts will move through the GPU. With a SIMD8 being the smallest ALU array for normal arithmetic, Intel’s minimum wavefront size is now the same size as the underlying hardware. This means that Xe-LP no longer needs multiple cycles to execute a single instruction from a wavefront in a single cycle, at least for the smallest wavefront size. In Gen11 Intel also allowed SIMD16 and SIMD32 wavefronts, and I’m waiting on the Xe-LP whitepaper to confirm whether those have been retained – in which case they’d still need multiple cycles – or if Intel is forcing everything to be SIMD8.
It’s worth noting that this change is fairly similar to what AMD did last year with its RDNA (1) architecture, eliminating the multi-cycle execution of a wavefront by increasing their SIMD size and returning their wavefront size. In AMD’s case this was done to help keep their SIMD slots occupied more often and reduce instruction latency, and I wouldn’t be surprised if it’s a similar story for Intel.

A further benefit of this reorganization is that Intel has been able to simplify their thread scheduling hardware overall. As recently as Gen11, Intel was still using hardware score boarding to determine when to run threads and when threads’ data would be ready. But with Xe-LP, score boarding has been moved into software, becoming a responsibility of Intel’s compiler.
While the move to software score boarding means that scheduling has to be determined in advance by the software – and thus becomes static and potentially results in less-than-optimal scheduling – the payoff is that hardware score boarding is fairly expensive from a die area and power standpoint. So moving to software score boarding allows for smaller and more power efficient EUs, which feeds back into Intel’s ability to build a larger number of EUs, and to improve their overall energy efficiency. Overall, this mirrors changes NVIDIA made to their architecture almost a decade ago with Kepler, where they similarly switched to software score boarding to the great benefit of their energy efficiency (and while retaining their high performance).
EU Throughput: By the Numbers
Now that we’ve had a chance to see all the changes made at the EU level, let’s talk about what this means for the actual throughput rates of the EUs.
| Intel GPU Compute Throughput Rates (FMA, Ops/clock/EU) |
||||
| Xe-LP | Gen11 | |||
| FP32 | 16 | 16 | ||
| FP16 | 32 | 32 | ||
| INT32 | 8 | 4 | ||
| INT16 | 32 | 16 | ||
| INT8 | 64 (DP4A) |
N/A | ||
Starting with floating point, things are simple here. Despite the ALU reorganization, the number of FP ALUs per EU is still 8. And as a result, FP throughput per EU remains at 16 FP32 ops/clock and 32 FP16 ops/clock, just like Gen11.
For integer throughput on the other hand, the number of integer-capable ALUs has been doubled from 4 to 8 relative to the Gen11 architecture. As a result, integer throughput has also doubled: Xe-LP can put away 8 INT32 ops or 32 INT16 ops per clock cycle, up from 4 and 16 respectively on Gen11. This does mean, however, that Xe-LP retains Gen11’s unusual INT32 handicap; the INT32 rate is only half the FP32 rate, whereas the INT16 rate is equal to the FP16 rate.
Finally, it’s worth nothing that Xe-LP doesn’t have anything equivalent to a tensor core or other systolic array of ALUs for doing dense math, which has become all the rage for neural networking training an inference. This hardware will be coming to the Xe family in later parts as the Xe Matrix eXtensions (XMX), but for now Xe-LP has to make do with its regular EUs.
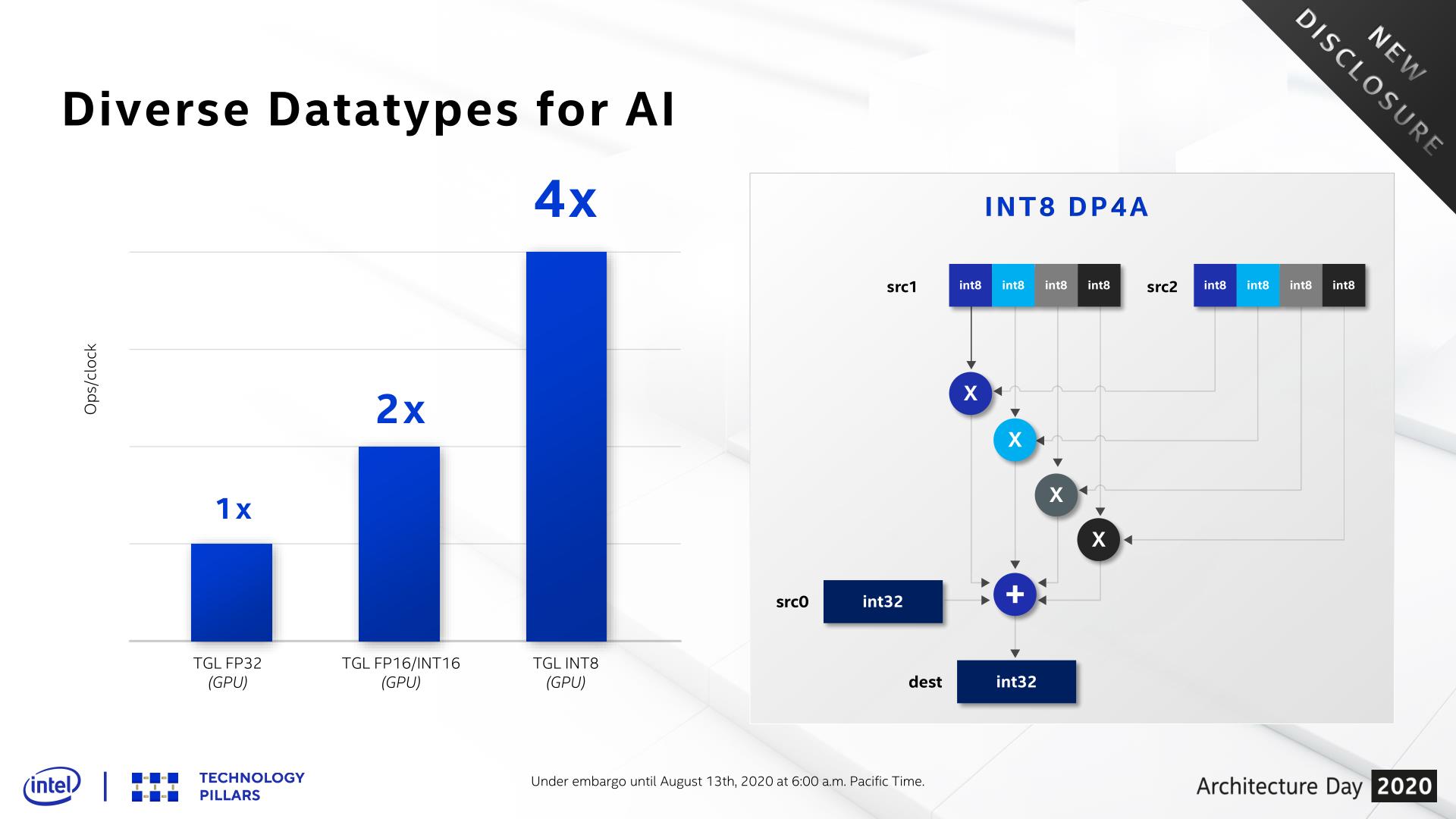
But for that reason, Intel has added one more feature to their EU SIMD: support for INT8 dot products. INT8 has become increasingly popular for neural networking inference over the past few years, and dot products in turn a very common operation in that process. So adding support for INT8 dot products gives Xe-LP a big boost in this form of AI execution. With the DP4A instruction, the INT8 throughput rate can get as high as 64 ops/clock, twice the INT16 rate.








33 Comments
View All Comments
Cooe - Saturday, August 15, 2020 - link
Soooooo much die space & transistors needed for just barely better performance than Renoir's absolutely freaking MINISCULE Vega 8 iGPU block.... Consider me seriously unimpressed. The suuuuuper early DDR5 support on the IMC is incredibly intriguing and I'm really curious to see what the performance gains from that will be like, but other than that.... epic yawn. Wake me up when it doesn't take Intel half the damn die for them to compete with absolutely teeny-tiny implementations of AMD's 2-3 year old GPU tech....Makes sense now why AMD's going for Vega again for Cézanne. Some extra frequency & arch tweaks are all they'd need to one-up Intel again, & going RDNA/2 would have had a SIGNIFICANTLY larger die space requirement (an RDNA dCU ["Dual Compute Unit"] is much, MUCH larger than 2x Vega II /"Enhanced" CU's), that just doesn't really make much sense to make until DDR5 shows up with Zen 4 and such a change can be properly taken advantage of.
(Current iGPU's are ALREADY ridiculously memory bandwidth bottlenecked. A beefy RDNA 2 iGPU block would bring even 3200MHz DDR4 to its absolute KNEES, & LPDDR4X is just too uncommon/expensive to bank on it being used widely enough for the huge die space cost vs iterating Vega again to make sense. Also, as we saw with Renoir; with some additional TLC, Vega has had a LOT more left in the tank than probably anyone of us would have thought).
Oxford Guy - Tuesday, August 18, 2020 - link
MadTV is back, with an episode called Anandtech Literally?Oxford Guy - Tuesday, August 18, 2020 - link
"t’s worth noting that this change is fairly similar to what AMD did last year with its RDNA (1) architecture, eliminating the multi-cycle execution of a wavefront by increasing their SIMD size and returning their wavefront size. In AMD’s case this was done to help keep their SIMD slots occupied more often and reduce instruction latency, and I wouldn’t be surprised if it’s a similar story for Intel."Retuning or returning to?