The Intel Xe-LP GPU Architecture Deep Dive: Building Up The Next Generation
by Ryan Smith on August 13, 2020 9:00 AM EST- Posted in
- GPUs
- Intel
- Tiger Lake
- Xe
- Xe-LP
- DG1
- Intel Arch Day 2020
- SG1
Xe-LP Media & Display Controllers
Our final stop on our deep dive through the Xe-LP architecture are the non-rendering aspects of the GPU: its media and display controllers. Changes here aren’t quite as eye-catching as changes to the core architecture, but the improvements made in these blocks help to keep the overall GPU current by supporting new media formats as well as new display connectivity protocols.
First off, let’s talk about the media engine. There are no crazy overhauls to speak of here, but for Xe-LP Intel has made some sensible additions to the engine. The marquee feature here is easily support for AV1 decode acceleration, making Intel the first vendor out of the Big 3 to add hardware decode support for the new codec.
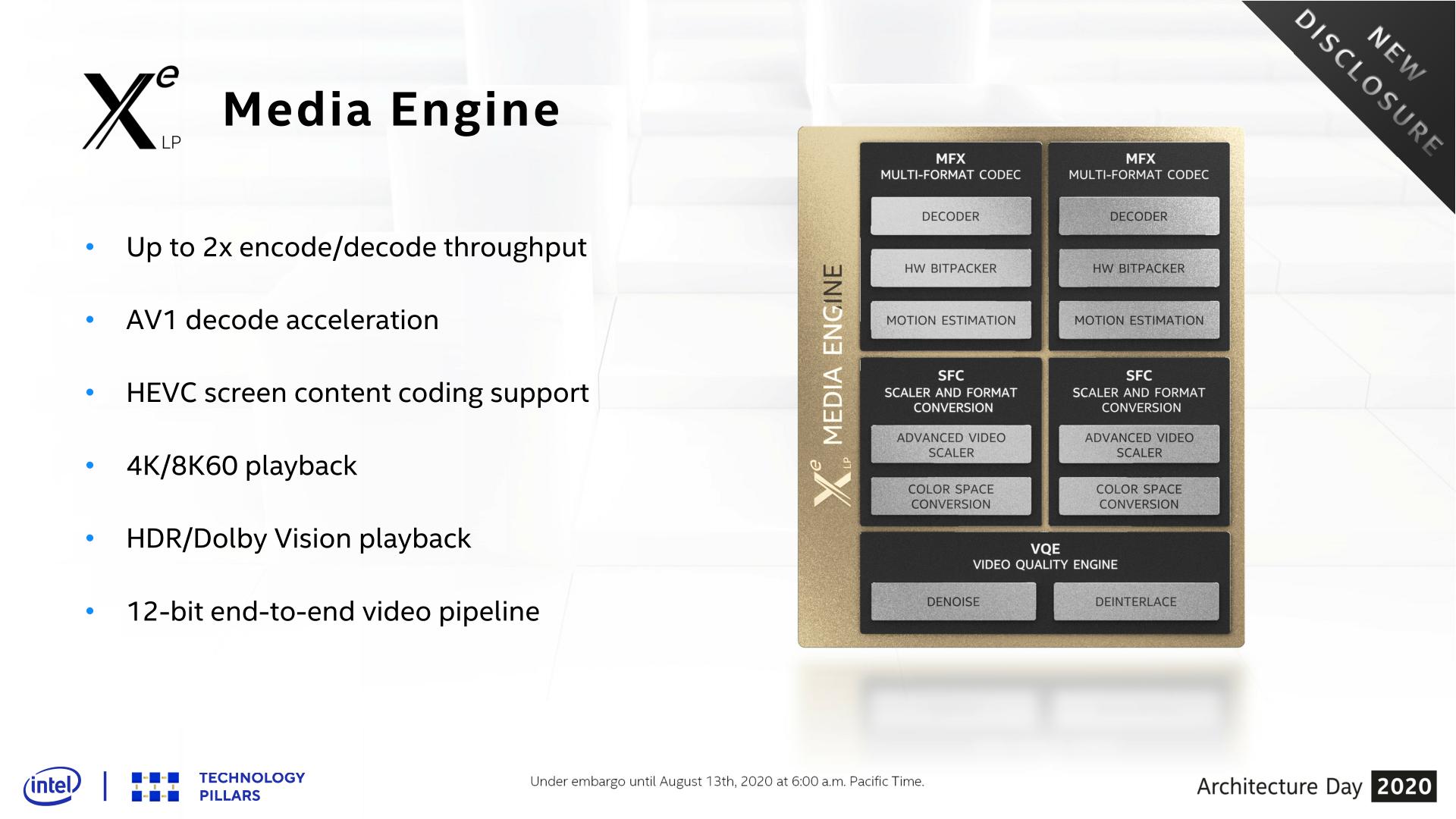
The up-and-coming royalty free codec is widely expected to become the de facto successor to H.264/AVC, as while HEVC has been on the market for a number of years (and is already supported in all recent GPUs), the madcap royalty situation around the codec has discouraged its adoption. By contrast, AV1 should deliver similar or slightly better quality than HEVC without royalties for its use in distribution, which makes it a lot more palatable to content vendors. The one downside to AV1 thus far is that it’s pretty CPU heavy, which makes hardware decode support all the more important not only for battery life reasons, but even ensuring smooth, glitch-free playback.
Meanwhile, similar to Intel’s rendering performance goals, the company has worked to improve the encoding and decoding throughput of the media engine. According to the company the updated block is now capable of up to 2x the encode and decode throughput. For consumer machines this is unlikely to matter too much, but it’s something that will be particularly important for the SG1 server product, which will focus on bulk encoding.
Finally, among smaller changes made to the media engine, Intel has added official support for HDR and Dolby Vision playback. HDR support continues to roll out to PCs, if only slowly, so this is a notable step in ensuring that newer PCs can handle HDR content encoded in those formats. Also notable is an improvement to Intel’s HEVC encoding block, which now supports the HEVC Screen Content Coding (SCC) extension, which is designed to improve HEVC compression rates on content with static or nearly-static images.
Xe-LP Display Controller: DisplayPort 1.4, HDMI 2.0, & 8K Displays
Last but certainly not least, we have Xe-LP’s display engine. Like the media block there are no radical changes here, but there are some welcome improvements throughout.
Perhaps the biggest change here is that after several years, Intel has finally added a fourth display pipeline, meaning that the GPU can now drive four independent displays. Prior to this, Gen11 and earlier designs could only handle three displays, and though even that is more than most people will use, 4 displays has become the magic number for other GPU designs. Complicating matters is the recent push for dual screen laptops and other mobile devices with multiple displays, which would then eat up two of those three outputs.

On which note, Intel has also added a second embedded DisplayPort output, which would be extremely useful for those dual screen devices.
Otherwise, the basic display output choices are unchanged from Gen11. Xe-LP supports DisplayPort 1.4 as well as HDMI 2.0. The latter is a bit disappointing since HDMI 2.1 televisions are now shipping, but it’s admittedly not unusual for Intel to take an extra generation to adopt newer HDMI standards. These display outputs can also be fed into a USB4/Thunderbolt 4 port, where DisplayPort data is a first-class citizen and can be muxed in the signal, or the port reconfigured via alt modes.
Not evident on Intel’s block diagrams, the company has made some plumbing changes to better feed the display controllers. Specifically, the company has increased the bandwidth available to the display engine so that it can handle the kind of extreme, high-resolution displays that DisplayPort 1.4 was designed to feed. As a result the controller now has enough bandwidth and internal processing power to drive 8K UHD displays, as well as the recent generation of 360Hz displays.








33 Comments
View All Comments
mode_13h - Thursday, August 13, 2020 - link
As always, thanks for the deep coverage.Not finished reading, but I already have one complaint:
> Gen11’s smallest wavefront width is 8 threads wide (SIMD8), so it can take multiple clock cycles to execute a single wavefront, with Intel interleaving multiple threads as a form of latency hiding.
Wow. Mixing 2 different definitions of "thread" in the same sentence? Please don't.
Last I checked Nvidia is the only one talking about SIMD lanes as if they're threads. In Intel's Gen 9 whitepaper, it uses "threads" in a manner equivalent to CPU threads, and they talk about SIMD lanes as SIMD lanes.
And speaking of Gen 9, they claim it has 7-way SMT. Did they ever specify this, for Gen 11? I don't recall seeing it in their Gen 11 whitepaper, which went into significantly less detail on the EUs than previous whitepapers.
mode_13h - Thursday, August 13, 2020 - link
I guess your article could be self-consistent by replacing the second use of "thread" in that quoted sentence with "wavefront"?Although, "wavefront" is an AMD term (Nvidia calls them "Warps"). However, Intel's slides suggest they still call them "threads".
Ryan Smith - Thursday, August 13, 2020 - link
"I guess your article could be self-consistent by replacing the second use of "thread" in that quoted sentence with "wavefront"?"You are correct sir! That was supposed to be "wavefront".
And Intel tends to use "wave" in its literature, though I prefer to collapse it down to just wavefront to keep things reasonably consistent. We don't need 2 nearly-identical terms for the same thing.
mode_13h - Thursday, August 13, 2020 - link
Cool. Thanks for the reply!BTW, I don't mind the term "wavefront" - I said that more to point it out to those who might not know.
mode_13h - Thursday, August 13, 2020 - link
IMO, the reason Nvidia has long called their Warp elements "threads" is so they can claim that each SIMD lane is a "core", to make their GPUs *sound* more impressive.Since Volta finally fixed their per-lane IP register (which is basically just a fancy form of branch predication), there's almost a touch of truth in that characterization, and I'd finally agree that their ISA is more than just a straight-forward combination of SIMD + SMT.
xenol - Thursday, August 13, 2020 - link
AMD feels more confusing. Their base unit is a "stream processor" which seems to suggest something larger than it really is. But a group of stream processors is called a Compute Unit, which that seems to suggest something smaller than it really is.Though looking at some of the programming literature for GPUs, I can see where the "thread" terminology comes from. So this looks more like a problem of someone coming up with their own language instead of the industry coming together to standardize on it. However, given that NVIDIA, AMD, and Intel have their own way of doing things, it may not be possible to do that and for the sake of clarity, having their own terminology is more or less correct.
mode_13h - Thursday, August 13, 2020 - link
Since Nvidia's Fermi and AMD's GCN, their architectures basically amount to SIMD + SMT. I'm not sure exactly when Intel added SMT.Anyway, I wouldn't characterize their architectures as fundamentally different. Intel is traditionally the most distinct, among the three.
jim bone - Friday, August 14, 2020 - link
recent editions of Hennessy and Patterson have a nice table mapping the CPU terminology to nvidia’s GPU terminology:https://books.google.ca/books?id=cM8mDwAAQBAJ&...
jim bone - Friday, August 14, 2020 - link
and yes for reasons nvidia calls a vertical slice of simd instructions a threadkpx86 - Thursday, August 13, 2020 - link
I believe the SW libraries like DirectX and OpenGL use threads this way.From MSFT website: The maximum number of threads is limited to D3D11_CS_4_X_THREAD_GROUP_MAX_THREADS_PER_GROUP (768) per group.