The Next Step in SSD Evolution: NVMe Zoned Namespaces Explained
by Billy Tallis on August 6, 2020 12:00 PM EST- Posted in
- SSDs
- Storage
- Western Digital
- NVMe
- SMR
- Radian Memory
The Software Model
Drivers (and other software) written for traditional block storage devices need several modifications to work with zoned storage devices. The most obvious is that the host software must obey the new constraints on only writing sequentially within a zone, but that's not the end of the story. Zoned storage also makes the host software responsible for more of the management of data placement. Handling that starts with keeping track of each zone's state. That is more complex than it might sound at first. ZNS adopts the same concept of possible zone states that are used for host-managed SMR hard drives. Technically, this is with ZBC and ZAC extensions to the SCSI and ATA command sets respectively:
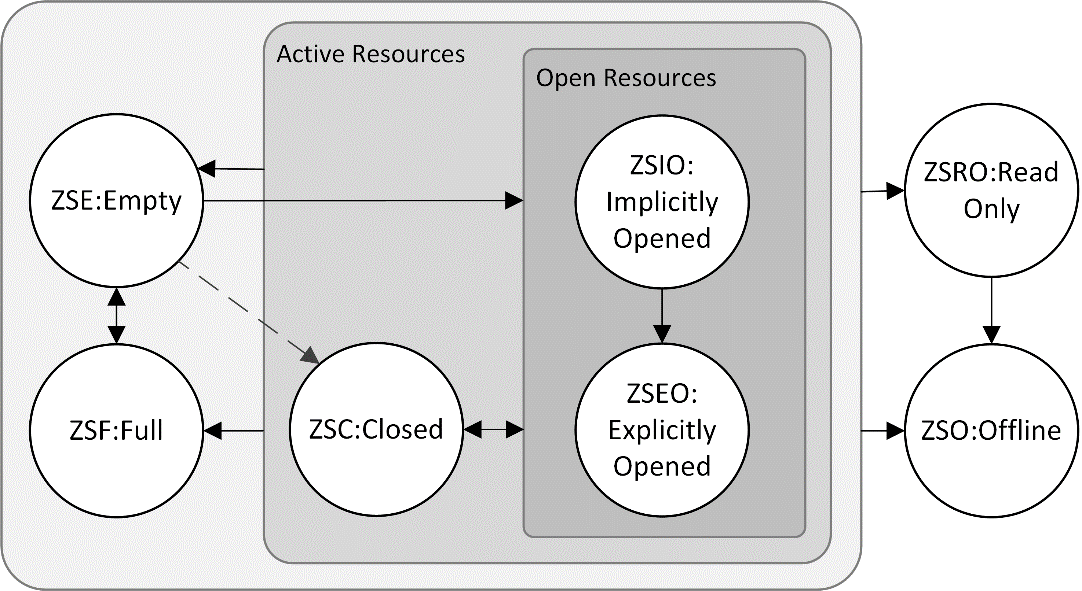
Each of these seven circles represents a possible state of one of the zones on a Zoned Namespace SSD. A few of these seven states have an obvious purpose: empty and full zones are pretty much self-explanatory.
(A zone may be put into the full state without actually storing as much data as its capacity allows. In those scenarios, putting a zone into the full state is like finalizing an optical disc after burning: nothing more can be written to the zone until it is reset (erased).)
The read-only and offline states are error states used when a drive's flash is failing. While ZNS SSDs reduce write amplification, they still have to perform wear leveling at the hardware level. The read-only and offline states are only expected to come into play when the drive as a whole is at the end of its life. Consequently, a lot of software targeting zoned storage won't do anything interesting with these states and will simply treat the entire device as dead once a zone fails into one of these states.
That still leaves three states: implicitly opened, explicitly opened, and closed.
A zone that is in any one of these three states is considered active. Drives will tend to have limits on the number of zones that can be opened (explicitly or implicitly) or active at any given time. These limitations arise because active or open zones require a bit of extra tracking information beyond just knowing what state the zone is in. For every active zone, the drive needs to keep track of the write pointer, which indicates how full the zone is and where the next write to the zone will go. A write pointer isn't needed for full or empty zones because full zones cannot accept more writes, and empty zones will be written to starting at the beginning of the zone.
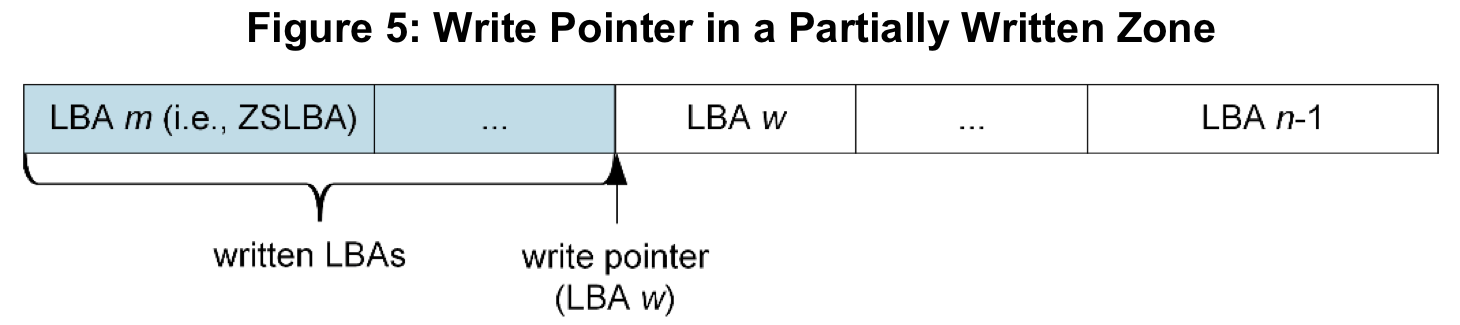
A zone must be opened in order to accept new writes. Zones can be implicitly opened by simply issuing a write command, or they can be explicitly opened using a zone management command to open (it doesn't actually write new data).
The distinction between implicitly and explicitly opened zones is that the SSD controller is free to automatically close a zone that was opened implicitly through a write command. An explicitly opened zone, one that was issued with an ‘open’ command, will only be put in the closed state when the host software commands it.
If a ZNS SSD is operating at its limit for the number of zones that can be open and they're all explicitly opened, then any attempt to open a new zone will fail. However, if some of the zones are only implicitly opened, then trying to open a new zone will cause the SSD to close one of those implicitly open zones.
The distinction between open and closed zones allows drives to keep a practical limit on the internal resources (eg. buffers) needed to handle new writes to zones. To some extent, this is just a holdover from SMR hard drives, but there is a relevant limitation in how flash memory works. These days, NAND flash memory typically has page sizes of about 16kB, but ZNS SSDs still support writes of individual LBAs that will typically be 4kB (or 512 bytes). That means writing to a zone can leave flash memory cells in a partially programmed state. Even when doing only page-sized and properly aligned writes, cells may be left in a partially programmed state until further writes arrive, due to how SSDs commonly map pages to physical memory cells.
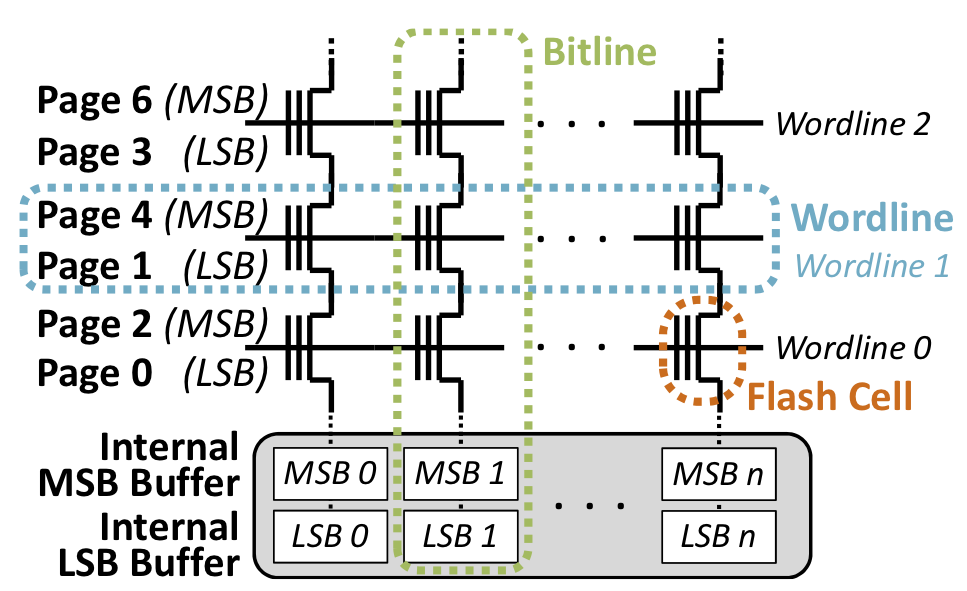
Flash memory cells that are in a partially programmed state are particularly at risk of suffering from a read disturb error, where attempts to read from that cell or an adjacent cell may change the voltage of the partially programmed cell. Open Channel SSDs deal with this by simply disallowing reads from such pages, but the zoned storage model tries to avoid imposing extra restrictions on read commands. ZNS SSDs will typically cache recently-written data so that a read command can be handled without touching partially programmed NAND pages. The available memory for such caching is what leads to a limit on the number of open zones.
If an open zone with some partially programmed memory cells is to be closed, the drive has two choices: finish programming those cells using some filler data, keep track of the hole in the zone, and hope the host doesn't try to use the full zone capacity later. Alternatively, the drive can keep buffering recently-written data even for closed zones. Depending on how many active zones a drive wants to support, this can still allow for a ZNS SSD to get by with much less DRAM than a conventional SSD, so this approach is what's more likely to be used in practice. A SSD that supports both zoned and block IO namespaces will probably be able to keep all of its zones active or open simultaneously.
In principle, a ZNS SSD could expose each individual flash erase block as a separate zone that would be several megabytes, depending on the underlying flash memory. This would mean writes to a single zone are limited to the write speed of a single NAND flash die. For recent TLC NAND flash, single die write speeds go up to about 82 MB/s (Samsung 6th-gen V-NAND) and for QLC the single-die write speed can be below 10MB/s. In practice, drives will tend to support zone sizes that aggregate many erase blocks across multiple dies and all of the controller's channels, so that sequential writes (or reads) to a single zone can be as fast as would be supported on a conventional FTL-based SSD.
A recent Western Digital demo with a 512GB ZNS prototype SSD showed the drive using a zone size of 256MB (for 2047 zones total) but also supporting 2GB zones. Within a single zoned namespace, all zones will use the same zone size, but a drive can support reformatting a namespace to change its zone size or multiple namespaces with different zone sizes.
Hints or Warnings
Many recent NVMe features allow SSDs and host software to exchange optional hints about data layout, access patterns and lifetimes. This is an SSD driven feature to the host, rather than requiring both sides to support using this information. ZNS makes zones an explicit concept that the host must deal with directly, but takes the hinting approach for some of the remaining internal operations of the SSD.
ZNS SSDs don't perform garbage collection in the sense of traditional SSDs, but they are still responsible for wear leveling. That can sometimes mean the drive will have to re-locate data to different physical NAND erase blocks, especially if the drive is relatively full with data that is infrequently modified. Rewriting an entire zone of, say, 256MB is a pretty big background job that would have a noticeable impact on the latency of handling IO commands coming from the host. A ZNS SSD can notify the host that it recommends resetting a zone because it plans to do some background work on that zone soon, and can include an estimate of how many seconds until that will happen. This gives the host an opportunity to reset the zone, which may involve the host doing some garbage collection of its own if only some of the data in the zone is still needed. (To help with such situations, NVMe has also added a Copy command to collect disparate chunks of data into a single contiguous chunk, without the data having to leave the SSD.)
Similarly, a ZNS SSD can recommend that an active zone should be moved to the Full state by the host either writing to the rest of the zone's capacity, or issuing a Zone Finish command.
When the host software pays heed to both of the above hints and takes the recommended actions, the SSD will be able to avoid almost all of the background operations that have a large impact on performance or write amplification. But because these are merely hints, if the host software ignores them or simply isn't in a position to comply, the SSD is still obligated to preserve user data throughout its background processing. There may still be some side effects, such as the drive having to move an open or active zone to the full state in exceptional circumstances, and host software must be written to tolerate these events. It's also impossible to completely eliminate write amplification. For example, static data may need to be rewritten eventually to prevent uncorrectable errors from accumulated read disturb errors.
Supporting Multiple Writers
The requirement to write data sequentially within a zone presents obvious challenges for software to manage data layout and especially updates to existing data. But it also creates a performance bottleneck when multiple threads want to write to the same zone. Each write command sent to the SSD needs to be addressed to the LBA currently pointed to by the zone's write pointer. When multiple threads are writing to a zone, there's a race condition where the write pointer can be advanced by another thread's write between when a thread checks for the location of the write pointer and when its write command gets to the SSD. That will lead to writes being rejected by the SSD. To prevent this, software has to synchronize between threads to properly serialize writes to each zone. The resulting locking overhead will tend to cause write performance to decrease when more threads are writing, and it is difficult to get the queue depth above 1.

To address this limitation, the ZNS specification includes an optional append command that can be used instead of the write command. Append commands are always addressed to the beginning of the zone, but the SSD will write the data wherever the write pointer is when it gets around to processing that command. When signaling completion of that command, the SSD returns to the host the LBAs of where the data actually landed. This eliminates the synchronization requirement and allows many threads to write new data to a zone simultaneously with no core-to-core communication at all. The downside is that even more complexity has been moved into host software, which now must record data locations after the fact instead of trying to allocate space before writing data. Even returning the address where data ended up to the application has proven to be a challenge for existing IO APIs, which are usually only set up to return error codes to the application.

The append command isn't the only possible solution to this scalability challenge; it's just the one that has been standardized with this initial version of the NVMe ZNS specification. Other solutions have been proposed and implemented in prototypes or non-standard zoned SSDs. Radian Memory has been supporting their own form of zoned storage on their SSDs for years. Their solution is to allow out of order writes within a certain distance ahead of the write pointer. The SSD will cache these writes and advance the write pointer up to the first gap in data that has arrived so far. There's another NVMe Technical Proposal on its way toward standardization to define a Zone Random Write Area (ZRWA) that allows random writes and in-place overwriting of data while it's still in the SSD's cache. Both of these methods require more resources on the SSD than the Zone Append command, but arguably make life easier for software developers. Since Zone Append, ZRWA and any other solution has to be an optional extension to the basic ZNS feature set, there's potential for some annoying fragmentation here.








45 Comments
View All Comments
Carmen00 - Friday, August 7, 2020 - link
Fantastic article, both in-depth and accessible, a great primer for what's coming up on the horizon. This is what excellence in tech journalism looks like!Steven Wells - Saturday, August 8, 2020 - link
Agree with @Carmen00. Super well written. Fingers crossed that one of these “Not a rotating rust emulator” architectures can get airborne. As long as the flash memory chip designers are unconstrained to do great things to reduce cost generation to generation with the SSD maintaining the fixed abstraction I’m all for this.Javier Gonzalez - Friday, August 7, 2020 - link
Great article Billy. A couple of pointers to other parts of the ecosystem that are being upstreamed at the moment are:- QEMU support for ZNS emulation (several patches posted in the mailing list)
- Extensions to fio: Currently posted and waiting for stabilizing support for append in the kernel
- nvme-cli: Several patches for ZNS management are already merged
Also, a comment to xZTL is that it is intended to be used on several LSM-based databases. We ported RocksDB as a first step, but other DBs are being ported on top. xZTL gives the necessary abstractions for the DB backend to be pretty thin - you can see the RocksDB HDFS backend as an example.
Again, great article!
Billy Tallis - Friday, August 7, 2020 - link
Thanks for the feedback, and for your presentations that were a valuable source for this article!Javier Gonzalez - Friday, August 7, 2020 - link
Happy to hear that it helped.Feel free to reach out if you have questions on a follow-up article :)
jabber - Friday, August 7, 2020 - link
And for all that, will still slow to Kbps and take two hours when copying a 2GB folder full of KB sized microfiles.We now need better more efficient file systems not hardware.
AntonErtl - Friday, August 7, 2020 - link
Thank you for this very interesting article.It seems to me that ZNS strikes the right abstraction balance:
It leaves wear leveling to the device, which probably does know more about wear and device characteristics, and the interface makes the job of wear leveling more straightforward than the classic block interface.
A key-value would cover a significant part of what a file system does, and it seems to me that after all these years, there is still enough going on in this area that we do not want to bake it into drive firmware.
Spunjji - Friday, August 7, 2020 - link
Everything up to the "Supporting Multiple Writers" section seemed pretty universally positive... and then it all got a bit hazy for me. Kinda seems like they introduced a whole new problem, there?I guess if this isn't meant to go much further than enterprise hardware then it likely won't be much of an issue, but still, that's a pretty keen limitation.
Spunjji - Friday, August 7, 2020 - link
Great article, by the way. Realised I didn't mention that, but I really appreciate the perspective that's in-depth but not too-in-depth for the average tech-head 😁AntonErtl - Saturday, August 8, 2020 - link
As long as the zone is not divided between file systems, or direct-access databases, it is natural that writes are are synchronized and sequenced. And talking to the SSD through one NVMe/PCIe interface means that all writes (even to multiple zones) are sent to the drive in sequence.OTOH, you have software and hardware with synchronous interfaces (waits for some feedback before sending the next request), and in such a setting doing everything through one thread costs throughput.
So you can either design everything to work with asynchronous interfaces (e.g., SCSI tagged command queuing), at least at all single-thread levels, or you design synchronous interfaces that work with multiple threads. The "write it somewhere, and then tell where you wrote" approach seems to be along the latter lines. What's the status of asynchronous interfaces for NVMe?