Intel 7nm Delayed By 6 Months; Company to Take “Pragmatic” Approach in Using Third-Party Fabs
by Ryan Smith on July 23, 2020 10:00 PM EST
While today second quarter earnings report from Intel represented a high-water mark for the company amid booming sales and revenues, unfortunately not everything disclosed today was good news from the company. As part of Intel’s quarterly earnings presentation, the company announced that their under-development 7nm manufacturing process has suffered a six month delay due to a defect in the process. As a result, the first consumer products aren’t due until at least late 2022, leaving Intel with 10nm as their best in-house manufacturing process for the next couple of years.
But even more important than that, the delay has spurred some soul searching within Intel, driving the company to pivot on its manufacturing plans and open the door to using third-party fabs for a much broader segment of its products. Going forward, the company will be taking what CEO Bob Swan and other leadership are calling a “pragmatic” approach, looking at both in-house and third-party fabs and using those fabs that make sense for the company and the product in question. And while the company has not announced any specific plans to outsource production – they are looking at it for products in the 2022-and-later timeframe – it would be hard to overstate how dramatic of a shift this is for the industry, and for a company that even five years ago was the world’s leader in silicon lithography manufacturing.

7nm Delayed By Six Months
But before we get too far into Intel’s future plans, let’s talk about the past and the present, and how those are driving Intel’s decision to look towards outside fabs. Ever since Intel’s 10nm process suffered repeated delays, Intel’s plan to get the company’s manufacturing side back on track was to nail the development of their 7nm process. The goal was to deliver 7nm on time – making up for the time lost from the 10nm delays – getting a solid process out that Intel could quickly ramp up, retaking the lead in the race to sustain Moore’s Law. A side-effect of this plan would have been that 10nm was to be a relatively short-lived process, allowing Intel to get off of the troubled process rather quickly and on to the more reliable 7nm process.
Unfortunately for Intel, developing their 7nm process has not gone to plan. As revealed in today’s call, 7nm yields are roughly a full year behind schedule – that is, Intel expects it to take another year to get yields to where they wanted them for Q2 of 2020. As a result, the company has needed to push back the bulk of its 7nm product schedule by 6 months. The first 7nm client CPUs are now not expected before late 2022 or early 2023. Meanwhile the first 7nm server part is not expected until the first half of 2023.
The only 7nm part that remains (roughly) on schedule at this point is Ponte Vecchio, Intel’s Xe-HPC GPU that will be going into the Aurora supercomputer. That is expected to ship in late 2021 or early 2022, and even then Intel is evaluating whether to move the manufacturing of some of Ponte Vecchio’s parts to third-party fabs.
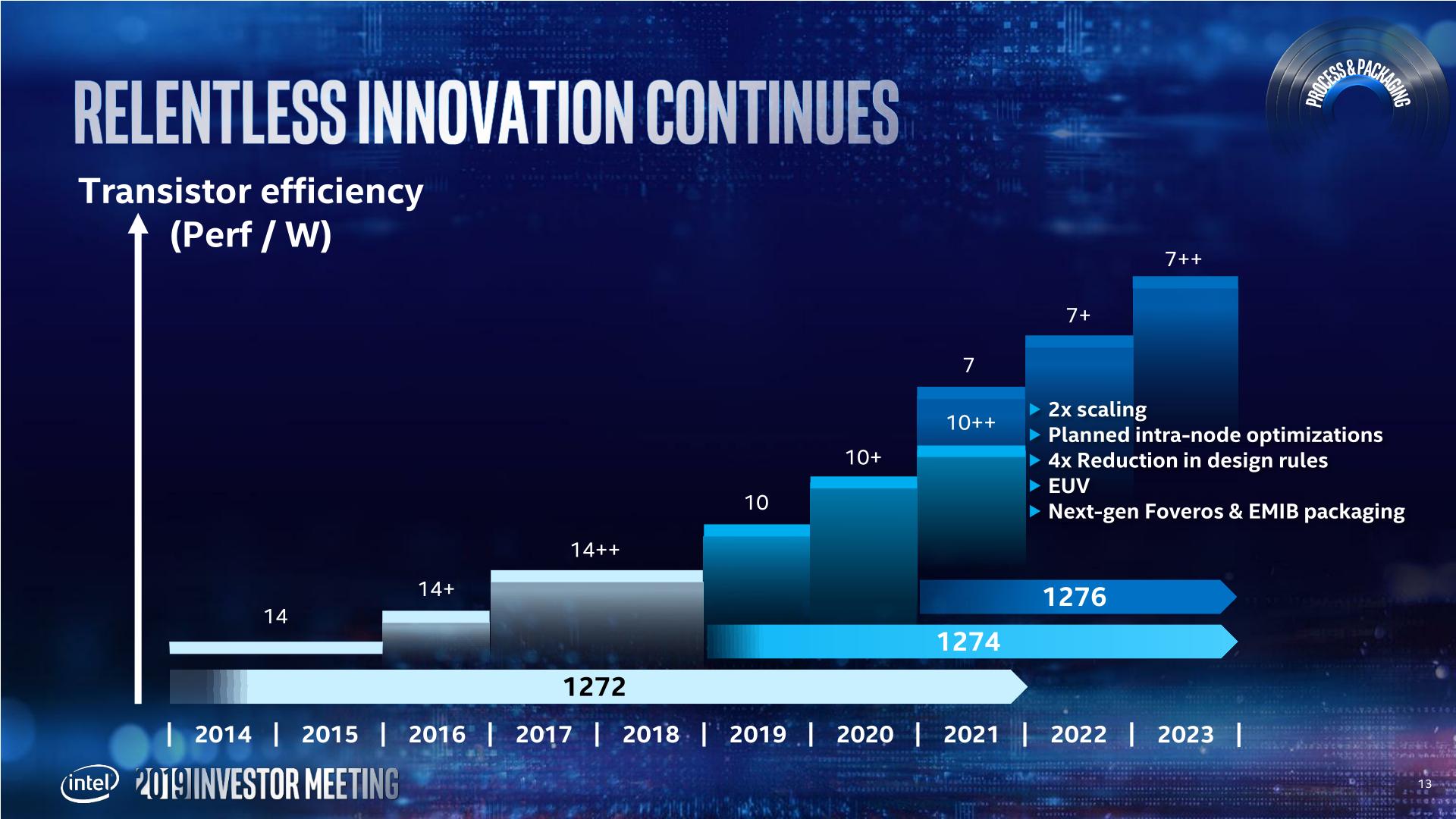
For Reference: Intel's Fab Schedule Circa May 2019
The good news, at least, is that despite all of this, Intel believes that they have a good grasp on the problem. With Swan describing the problem as a “defect mode” that was reducing yields, Intel has found the root cause of the issue and is moving to fix it, stating that that the company doesn’t believe that there are any fundamental roadblocks in their 7nm process. So as Intel’s current plans go, the company is still all-in on 7nm, and baring further issues, it’s going to become the cornerstone of their technology in 2023 when it begins volume shipping.
None the less, a six month delay is still a six month delay, and it comes at a time when Intel can ill afford it. Intel’s repeated 10nm problems set the company back years, and the ramifications to Intel’s product lines are ongoing as they continue to ship 14nm desktop and server processors. Meanwhile, though not wholly comparable in terms of node size, fab rival TSMC is set to start shipping 5nm parts this year, extending their lead over Intel and giving TSMC’s customers a leg-up in terms of things like power efficiency and die sizes. At the end of the day Intel has already been down this road once before with 10nm, and they’re intent on not repeating the same mistakes.
Being Pragmatic Means Knowing When to Yield
As a result of the 7nm delay, going forward Intel will be taking what Swan is calling a “pragmatic” approach in selecting what foundries to use. Intel will no longer be limiting themselves to near-exclusive use of their own fabs, and instead the company will be taking the capabilities (and costs) of third-party fabs into the equation. At the end of the day Intel still wants to produce market-leading chips, and they are now willing to use third-party fabs to accomplish this.
We will continue to invest in our future process technology roadmap, but we will be pragmatic and objective in deploying the process technology that delivers the most predictability and performance for our customers, whether that be our process, external foundry process or a combination of both.
-Intel CEO Bob Swan
While Intel isn’t committing to any specific manufacturing plans today, the message from Intel is clear: they will do what they need to in order to deliver new products according to their release roadmap. This means relying on third-party fabs as a contingency plan and leaving virtually every option on the table, including manufacturing a product entirely at a third-party fab if that is truly the best option. Ultimately, the question Intel is facing is how much should they rely on their 7nm fabs, and how much should they rely on third parties.
Meanwhile, underpinning this newfound philosophy of flexibility are Intel’s recent developments in what the company is terming “disaggregated die” technologies like EMIB and Foveros. These multi-chip packaging technologies, which have been rolled out in products like Kaby Lake-G and Intel’s new Core-L “Lakefield” processors, allow for multiple dissimilar dies to be used on a single package. In Lakefield’s case, that was accomplished by layering a 10nm compute die on top of a 22nm I/O die, allowing Intel to make the performance critical parts of the chip on the relatively expensive 10nm process, while non-critical parts were built on an extremely power efficient version of 22nm.
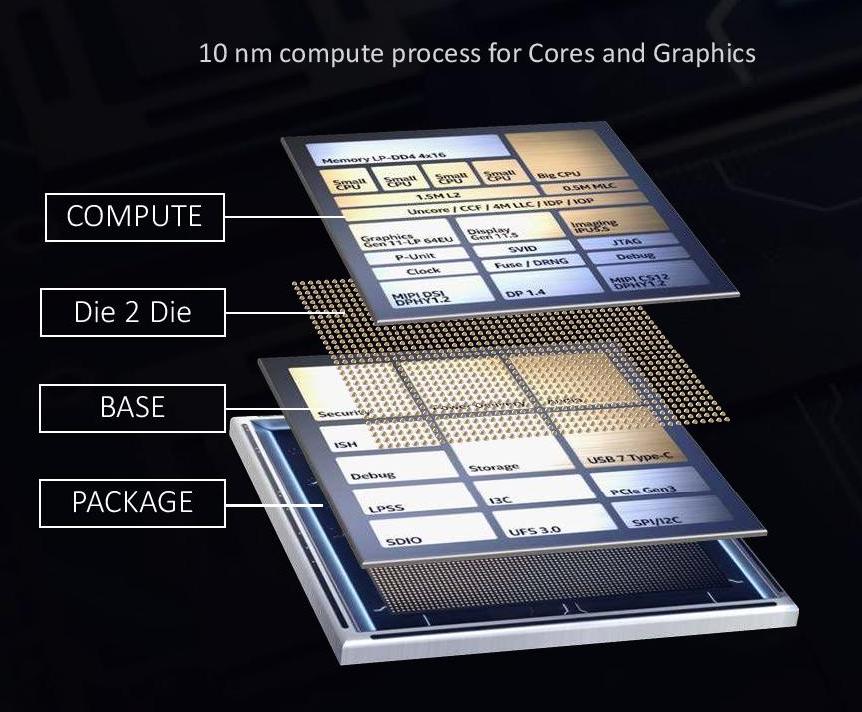
Lakefield, in turn, is the first of what will be many products from Intel using this technology. By gluing chips together Intel can not only better manage yield issues – defects are far less disruptive when they impact a small chiplet instead of a large monolithic die – but it means Intel can continue to mix-and-match different process nodes. And not just different Intel process nodes, but third-party process nodes as well.

We’ve already seen a very small taste of this with Kaby Lake-G, which used a GlobalFoundries-built GPU with an Intel-built CPU, albeit on a very coarse scale with minimal integration. But going forward intel’s flexibility plans mean they need to do it on a much larger and finer-grained scale. The upshot is that based on Lakefield there seems to be little doubt Intel can do this – which fab the chips come from shouldn’t have much of an impact on packaging – and instead it’s a question of how much of it Intel does. It’s clear that no matter what, Intel has to go the chiplet route for future products, as chiplets are what will enable Intel’s fab flexibility. But which of those chiplets will be Intel-made, and which of them will be made by third-party fabs? Intel will be spending the next couple of years figuring out just that.
Finally, it bears mentioning that none of this would even be possible without Intel’s other recent pivot towards divorcing product designs from process nodes. The company’s traditional vertically-integrated design philosophy has delivered a lot of excellent products over the years, but Intel has been feeling the pain of this decision since 10nm was delayed, and with it the use of their newer Sunny Cove CPU architecture. Intel has only recently gained the ability to port an architecture to multiple process nodes, and it’s clear they are going to be heavily relying on that ability as part of any third-party chipmaking.
But First, Ponte Vecchio
While the bulk of Intel’s announcement today deals with products set for the 2023 timeframe, the company has also publicly commented on what it means for their very first 7nm product, Ponte Vecchio. The Xe-HPC GPU is the flagship of Intel’s Xe GPU efforts, and Ponte Vecchio chips are a fundamental building block of the forthcoming Aurora Supercomputer. But even more importantly for Intel right now are delivery dates: Aurora is scheduled to be delivered in 2021, a year before Intel is set to deliver their first high-volume consumer 7nm parts. Ponte Vecchio is an extremely important product for Intel, and they only have a limited amount of time left to work on it.

As a result, Intel has confirmed that the company is also reevaluating what fabs are used for the various parts of Ponte. Curiously, Intel has stated that the chip was always going to use a mix of first-party and third-party fabs, though I wonder if Intel is being a bit fast & loose there by including the HBM memory (which Intel doesn’t produce) in that assessment. At any rate, even if you exclude the memory, that still leaves the I/O base die, the connectivity chips, and the GPU itself as separate dies, any of which could theoretically be shuffled off to a third party fab.
To be sure, like the other announcements today Intel is sharing their specific manufacturing plans – and it’s likely Intel hasn’t even made a final decision on where to make the various chips. But at the same time Intel is making it clear that they are considering all of their options. The Aurora supercomputer was already scrapped once (when it was planned to be a Xeon Phi system), so Uncle Sam is going to be eager to get his $500M supercomputer, and Intel in turn may need to swallow some of its pride to make it happen.
Many Unknowns, but Intel’s Transformation Is Certain
Wrapping things up, while there are a lot of unknowns and things left to be determined in Intel’s plan, there is one thing that is certain: no matter what happens, Intel will be transforming. At a minimum they will be transforming from a company that relies on monolithic dies to a company that embraces multi-chip packages, and depending on how things go with 7nm, they may also be transforming into a company that farms out much of its chip production to third parties. This is nothing short of a remarkable change for a company that ruled the world of chipmaking not even half a decade ago.
But it’s a remarkable change that needs to happen. Though undoubtedly a hard pill for Intel to swallow, Intel’s 7nm delay poses a significant risk to a company that is already bracing for hard times from their 10nm delay. So something needed to change, if only so that Intel has a contingency plan in place should 7nm slip yet again.
At the end of the day what happens next is still up in the air. Intel has decisions to make, and perhaps most importantly of all, Intel’s process technology team is facing a do-or-die situation with 7nm. Intel has invested a great deal in their 7nm process, and for both profit and product reasons, they would certainly prefer to use that. This means that if Intel can keep 7nm on track, then what is now just a contingency plan will likely remain just that.
But regardless of what happens, it’s clear that Intel can no longer bet the house on themselves. Silicon lithography is only getting harder, and a very mortal Intel has to prepare for the possibility that it's a race they may not win.








208 Comments
View All Comments
Spunjji - Friday, July 24, 2020 - link
FFS, when will random accounts stop posting this lie?Ice Lake on 10nm is ~50M transistors per mm²
Renoir on TSMC 7nm is 63.33M transistors per mm².
Intel's transistor density was *supposed to be higher* on 10nm, a claimed 100M transistors per mm². They relaxed it - twice - to meet yield targets. The world's most dense process is useless if you can't use it to manufacture a working chip.
DigitalFreak - Friday, July 24, 2020 - link
But, but, I read it on WCCFTech. It has to be true, right? /sSpunjji - Friday, July 24, 2020 - link
I think people just copy/paste the first result for "Intel 10nm density", which is of course their marketing claim. God forbid you try to find out what Ice Lake's density actually is.Even Lakefield - which relegates most of the components that scale poorly to the 22nm die - is pretty rubbish compared with what AMD did with Renoir on TSMC 7nm.
regsEx - Saturday, July 25, 2020 - link
Zen 2 4-core logic is 37 sq mm.ICL-U 4-core logic is 31 sq mm.
Don't remember for sure, afair Zen 2 has more cache. But Intel is more feature-rich, so should have more transistors.
Spunjji - Wednesday, July 29, 2020 - link
Are you quoting Matisse or Renoir for Zen 2? I was specifically referring to Renoir, which was laid down after AMD's first round of experience with manufacturing on 7nm and has shown significant improvements in density over Matisse; this is despite it also having to integrate all of the un-core, which Matisse does not.regsEx - Saturday, July 25, 2020 - link
And Intel never disclosed transistor count in ICL.Spunjji - Wednesday, July 29, 2020 - link
Jim Keller circa 2019 begs to differ.https://www.pcgamesn.com/intel/next-gen-cpu-archit...
You would think they'd be boasting about it if it had actually hit their projected density, though.
Santoval - Saturday, July 25, 2020 - link
"They relaxed it - twice - to meet yield targets".They do not need to relax their density in a technical sense, they just need to modify the layout of the three different 10nm cells in each processor. As a brief reminder (there's a more detailed one in the link below) what Intel calls "10nm node" refers to cells with three different densities :
The 100.8 MTr/mm² is the high density cell library, but that is commonly only used for I/O and uncore parts of the processor - except perhaps when very high efficiency (at the expense of performance) *and* very small size are required, as in the case of the Lakefield 10nm logic die. I suspect that Intel fabbed the entire die except perhaps the Sunny Cove core at that density. This cell variant is also perfect for misleading marketing targeted at the general public (while at IEDM they disclosed the truth..).
There are also the "Ultra High Performance" cells, with a density of just 67 MTr/mm² (intended largely for CPU cores and iGPUs) and the "High Performance" cells with an intermediate density of ~81 MTr/mm², for every bit that requires a moderate density and possibly for the cores of the mobile -U and -Y SoCs.
Since Intel already developed three distinct cell libraries of three different densities they wouldn't need to relax either of them, they would just need to use more low and mid density cells in each processor and I'm quite certain that's how they "relaxed" their transistor density. The end result is the same but it must be much simpler (and thus cheaper) for them to "relax" transistor density in that way.
https://www.anandtech.com/show/13405/intel-10nm-ca...
Spunjji - Wednesday, July 29, 2020 - link
Their total density still doesn't meet the original spec for "Ultra High Performance" cells alone, though. It's hard to be sure - because they're being cagey about transistor counts and die size - but based on Jim Keller's statements about Ice Lake's rough transistor count vs. its measured die size, they're way down from where they'd be if the vast majority of their chip hit 67 MTr/mm². The best information I have suggests that even with Lakefield's compute die, which excises lots of the uncore to the "22nm" interface die, they're still in the ~60MTr/mm² region.Santoval - Saturday, July 25, 2020 - link
p.s. By the way, do you have a source for these two densities? Ice Lake's density, in particular, sounds extremely low. Even if Intel used their lowest density 10nm cells for the *entire* die then its transistor density should not be less than 67 MTr/mm². So where does this 50 MTr/mm² value come from?