Workstation Graphics: AGP Cross Section 2004
by Derek Wilson on December 23, 2004 4:14 PM EST- Posted in
- GPUs
NVIDIA Quadro FX 4000 Technology
As with the ATI FireGL X3-256, NVIDIA's workstation core is based around its most recent consumer GPU. Unlike the top end offering from ATI, NVIDIA's highest end AGP workstation part is based on their highest end consumer level SKU. Thus, the Quadro FX 4000 has pixel processing advantage over the offerings from ATI and 3Dlabs in its 16 pipeline design. This will give it a shading advantage, but in the high end workstation space, geometry throughput is still most important. Fragment and pixel level impact has less effect in the workstation market than the consumer market, which is precisely the reason that last year's Quadro FX preformed much better than its consumer level partner. As with the ATI FireGL X3-256, since we're testing the consumer level part as well, we'll take a look at the common architecture and then hit on the additional features that make the NV40GL true workstation silicon.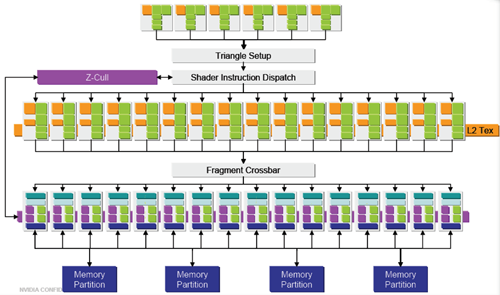
As we see the familiar pipeline laid out once again, we'll take a look at how NVIDIA defines each of these blocks, starting with the vertex pipeline and moving down. The VS 3.0 capable vertex pipelines are made up of MIMD (multiple input multiple data) processing blocks. Up to two instructions can be issued per clock per unit, and NVIDIA claims that it is able to hide completely the latency of vertex texture fetches in the pipeline.
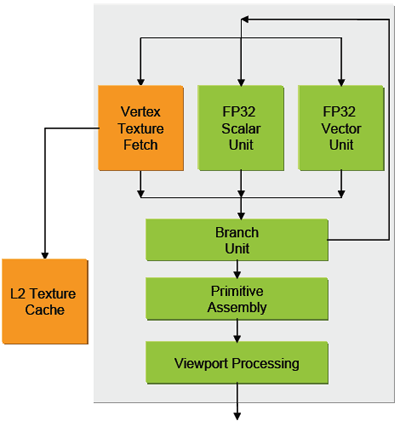
The side by side scalar and vector unit allow multiple instructions to be performed on different parts of the vertex at a time, if necessary (this is called co-issue in DX9 terminology). The 6 vertex units of the NV40 gives it more potential geometry power at a lower precision than the 3Dlabs part (on a component level, we're looking at a possible 24 32-bit components per clock). This does depend on the layout of 3Dlabs SIMD arrays and their driver's ability to schedule code for them. There is no hardware imposed limit on instructions that the vertex engine can handle, though currently software limits shader length to 65k instructions.
Visibility is computed in much the same way at the previous descriptions. The early/hierarchical z process eliminates blocks of pixels that are completely occluded and eliminates them from going through the pixel pipeline. For pixels that aren't clearly occluded, groups travel in quads four (a block of four pixels in a square pattern on a surface) through pixel pipelines. Each quad shares an L1 cache (which makes sense as each quad should have a strong locality of reference). Each of the 16 pixel pipelines looks like this on the inside:
![]()
The two shader units inside each pixel pipeline are 4 wide and can handle dual-issue and co-issue of instructions. The easy way to look at this is that each pipeline can optimally handle executing two instructions on two pixels at a time (meaning that it can perform up to 8 32-bit operations per clock cycle). This is only when not loading a texture, as texture loading will supercede the operation of one of the shader units. The pixel units are able to support shaders with lengths up to 65k instructions. Since we are not told the exact nature of the hardware, it seems very likely that NVIDIA would do some very complex resource management at the driver level and rotate texture loads and shader execution on a per quad basis. This would allow them to have less physical hardware than what software is able to "see" or make use of. To put it in perspective, if NVIDIA had all the physical processing units to brute force 8 32-bit floating operations in each of the 16 pipelines per clock cycle, that would mean needing the power of 128x 32 floating point units divided among some number of SIMD blocks. This would be approximately 2.7 times the fragment hardware packed in the Wildcat Realizm 200 GPU. In the end, we suspect that NVIDIA shares more resource than what we know about, but they just don't give us the detail to the metal that we have with the 3Dlabs part. At the same time, knowing how the 3Dlabs driver manages some of its resources in more detail would help us understand its performance characteristics better as well.
Moving on to the ROP pipelines, NVIDIA handles FSAA and z/stencil/color compression and rasterization here. During z only operations (such as in some shadowing and other depth only algorithms), the color portion of the ROP can handle z functionality. This means that the NV40GL is capable of 32 z/stencil operations per clock during depth only passes. This might not be as useful in the workstation segment as it is on the consumer side in games such as Doom 3.
The NVIDIA part also has the ability to support a 16-bit floating point framebuffer as the Wildcat Realizm GPU. This gives it the same functionality in display capabilities. The Quadro FX 4000 supports two dual-link DVI-I connectors, though the board is not upgradeable to genlock and framelock support. There is a separate (more expensive) product called the Quadro FX 4000 SDI, which has one dual-link DVI-I connector and two SDI connectors for broadcast video that supports genlock. If there is demand, we may compare this product to the 3Dlabs solution (and other broadcast or large scale visualization solutions).
It's unclear whether or not this part has the video processor (recently dubbed PureVideo) of NV40 built into it as well. It's possible that this feature was left out to make room for some of the workstation specific elements of the NV40GL. What, exactly, are the enhancements that were added to NV40 that make the Quadro FX 4000 a better workstation part? Let's take a look.
Hardware antialiased lines and points is the first and oldest component supported by the Quadro line that hasn't been enabled in the GeForce series. The feature just isn't necessary for gamers or consumer land applications, as it is used specifically to smooth the drawing of lines and points in wireframe modes. Antialiasing individual primitives is much more accurate and cleaner than FSAA algorithms, and is very desireable in applications where wireframe mode is used the majority of the time (which includes most of the CAD/CAM/DCC world).
OpenGL logic operations are supported, which allows things like hardware XORs to combine elements in a scene. Logic operations are performed between the fragment shader and the framebuffer in the OpenGL pipeline and have programmatic control over how (and if) data makes it down the pipeline.
The NV40GL supports 8 clip regions while NV40 only supports 1 clip region. The importance of having multiple clip regions is in accelerating 3D when overlapped by other windows. When a 3D window is clipped, the buffer can't be treated as one block in the frame buffer, but must be set up as multiple clip regions. On GeForce cards, when a 3D window needs to be broken up into multiple regions, the 3D can no longer be hardware accelerated. Though the name is similar, this is different than the also-supported hardware accelerated clip planes. In a 3D scene, a near clip plane defines the position beyond which geometry will be visible. Some applications allow the user to move or create clip planes to cut away parts of drawings and "look inside".
Memory management on the Quadro line is geared towards professional applications rather than towards games, though we aren't given much indication as to the differences in the algorithms used. The NV40GL is able to support things like quad-buffered stereo, which the NV40 is not capable of.
Two-sided lighting is supported in the fixed function pipeline on the Quadro FX 4000. Even though the GeForce 6 Series supports two-sided lighting through SM 3.0, professional applications do not normally implement lighting via shader programs yet. It's much easier and more straight forward to use the fixed function path to create lights, and hardware accelerated two-sided lighting is a nice feature to have for these applications.
Overlay planes are supported in hardware as well. There are a couple different options on the type of overlay plane to allow, but the idea is to have a lower memory footprint (usually 8bit) transparent layer rendered above the 3D scene in order to support things like pop-up windows or selection effects without clipping or drawing into the actual scene itself. This can significantly improve performance for applications and hardware that support its use.
Driver optimizations are also geared specifically towards each professional application that the user may want to run with the Quadro. Different overlay modes or other settings may be optimal for a different application. In addition, OpenGL, stability, and image quality are the most important aspects of driver development on the Quadro side.








25 Comments
View All Comments
Sword - Friday, December 24, 2004 - link
Hi again,I want to add to my first post that there were 2 parts and a complex assembly (>110 very complex parts without simplified rep).
The amount of data to process was pretty high (XP shows >400 Mb and it can goes up to 600 Mb).
About the specific features, I believe that most of the CAD users do not use them. People like me, mechanical engineers and other engineers, are using the software like Pro/E, UGS, Solidworks, Inventor and Catia for solid modeling without any textures or special effects.
My comment was really to point that the high end features seams useless in real world application for engineering.
I still believe that for 3D multimedia content, there is place for high-end workstation and the specviewperf benchmark is a good tool for that.
Dubb - Friday, December 24, 2004 - link
how about throwing in soft-quadro'd cards? when people realize with a little effort they can take a $350 6800GT to near-q4000 performance, that changes the pricing issue a bit.Slaimus - Friday, December 24, 2004 - link
If the Realizm 200 performs this well, it will be scary to see the 800 in action.DerekWilson - Friday, December 24, 2004 - link
dvinnen, workstation cards are higher margin -- selling consumer parts may be higher volume, but the competition is harder as well. Creative would have to really change their business model if they wanted to sell consumer parts.Sword, like we mentioned, the size of the data set tested has a large impact on performance in our tests. Also, Draven31 is correct -- a lot depends on the specific features that you end up using during your normal work day.
Draven31, 3dlabs drivers have improved greatly with the Realizm from what we've seen in the past. In fact, the Realizm does a much better job of video overlay playback as well.
Since one feature of the Quadro and Realizm cards is their ability to run genlock/framelock video walls, perhaps a video playback/editing test would make a good addition to our benchmark suite
Draven31 - Friday, December 24, 2004 - link
Coming up with the difference between the spec viewperf tests and real-world 3d work means finding out which "high-end card' features that the test is using and then turning them off in the tests. With NVidia cards, this usually starts with antialiased lines. It also depends on whether the application you are running even uses these features... in Lightwave3D, the 'pro' cards and the consumer cards are very comparable performance-wise because it doesn't use these so-called 'high-end' features very extensively.And while they may be faster in some Viewperf tests, 3dLabs drivers generally suck. Having owned and/or used several, I can tell you any app that uses DirectX overlays as part of its display routines is going to either be slow or not work at all. For actual application use, 3dLabs cards are useless. I've seen 3dLabs cards choke on directX apps, and that includes both games and applications that do windowed video playback on the desktop (for instance, video editing and compositing apps)
Sword - Thursday, December 23, 2004 - link
Hi everyone,I am a mechanical engineer in Canada and I am a fan of anandtech.
I made last year a very big comparison of mainstream vs workstation video card for our internal use (the company I work for).
The goal was to compare the different systems (and mainly video cards) to see if in Pro-Engineer and the kind of work with do we could take real advantage of high-end workstation video card.
My conclusion is very clear : in specviewperf there is a huge difference between mainstream video card and workstation video card. BUT, in the day-to-day work, there is no real difference in our reaults.
To summarize, I made a benchmark in Pro/E using the trail files with 3 of our most complex parts. I made comparison in shading, wireframe, hidden line and I also verified the regeneration time for each part. The benchmark was almost 1 hour long. I compared 3D Labs product, ATI professionnal, Nvidia professionnal and Nvidia mainstream.
My point is : do not believe specviewperf !! Make your own comparison with your actual day-to-day work to see if you really have to spend 1000 $ per video cards. Also, take the time to choose the right components so you minimize the calculation time.
If anyone at Anandtech is willing to take a look at my study, I am willing to share the results.
Thank you
dvinnen - Thursday, December 23, 2004 - link
I always wondered why Creative (they own 3dLabs) never made a consumer edition of the Wildcat. Seems like a smallish market when it wouldn't be all that hard to expand into consumer cards.Cygni - Thursday, December 23, 2004 - link
Im surprised by the power of the Wildcat, really... great for the dollar.DerekWilson - Thursday, December 23, 2004 - link
mattsaccount,glad we could help out with that :-)
there have been some reports of people getting consumer level driver to install on workstatoin class parts, which should give better performance numbers for the ATI and NVIDIA parts under games if possible. But keep in mind that the trend in workstation parts is to clock them at lower speeds than the current highest end consumer level products for heat and stability reasons.
if you're a gamer who's insane about performance, you'd be much better off paying $800 on ebay for the ultra rare uberclocked parts from ATI and NVIDIA than going out and getting a workstation class card.
Now, if you're a programmer, having access to the workstation level features is fun and interesting. But probably not worth the money in most cases.
Only people who want workstation class features should buy workstation class cards.
Derek Wilson
mattsaccount - Thursday, December 23, 2004 - link
Yes, very interesting. This gives me and lots of others something to point to when someone asks why they shouldn't get the multi-thousand dollar video card if they want top gaming performance :)