Avantek's Arm Workstation: Ampere eMAG 8180 32-core Arm64 Review
by Andrei Frumusanu on May 22, 2020 8:00 AM ESTThe eMAG 8180: AppliedMicro's Legacy Skylark Core
While you’re reading this in 2020, and the eMAG Workstation had been released in 2019 – the CPU powering the system is actually quite ancient, tracing back its roots in the 2017 defunct AppliedMicro. Originally meant to be called the X-Gene3, the chip had originally been planned for the second half of 2017 before the AppliedMicro had went through several changes of ownership before the IP and designs ended up with Ampere Computing.

In that sense, the eMAG 8180 is more of a legacy design and quite distantly related to Ampere’s newer Altra system processors.
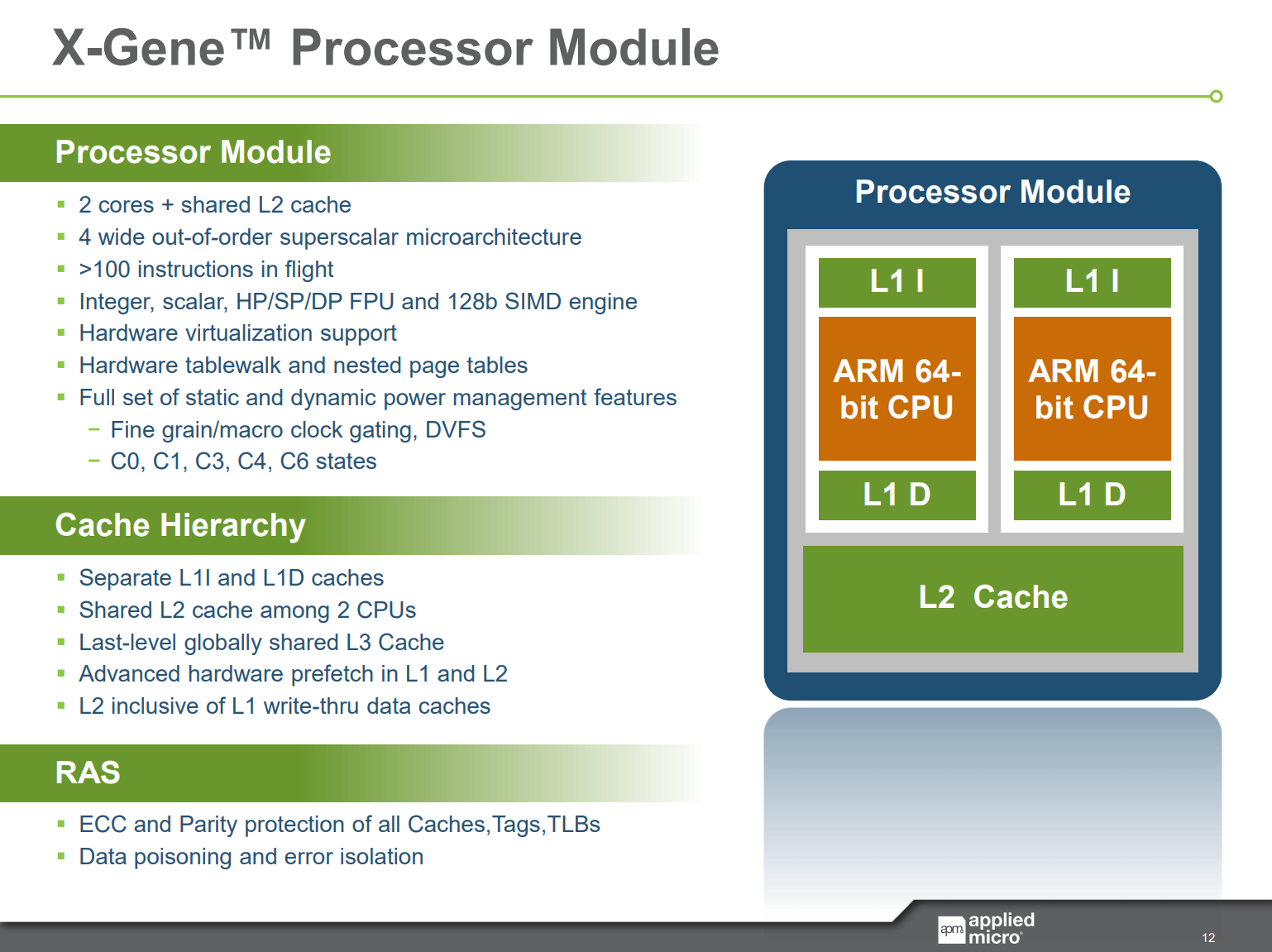
The Skylark cores in the eMAG 8180 are a custom core design having the X-Gene processor pedigree. It’s a 4-wide OOO processor that’s relatively narrow by today’s standards, characterised by quite high operating frequencies up to 3-3.3GHz and quite the unusual cache hierarchy, such as two core pairs sharing the same 256KB L2 cache.
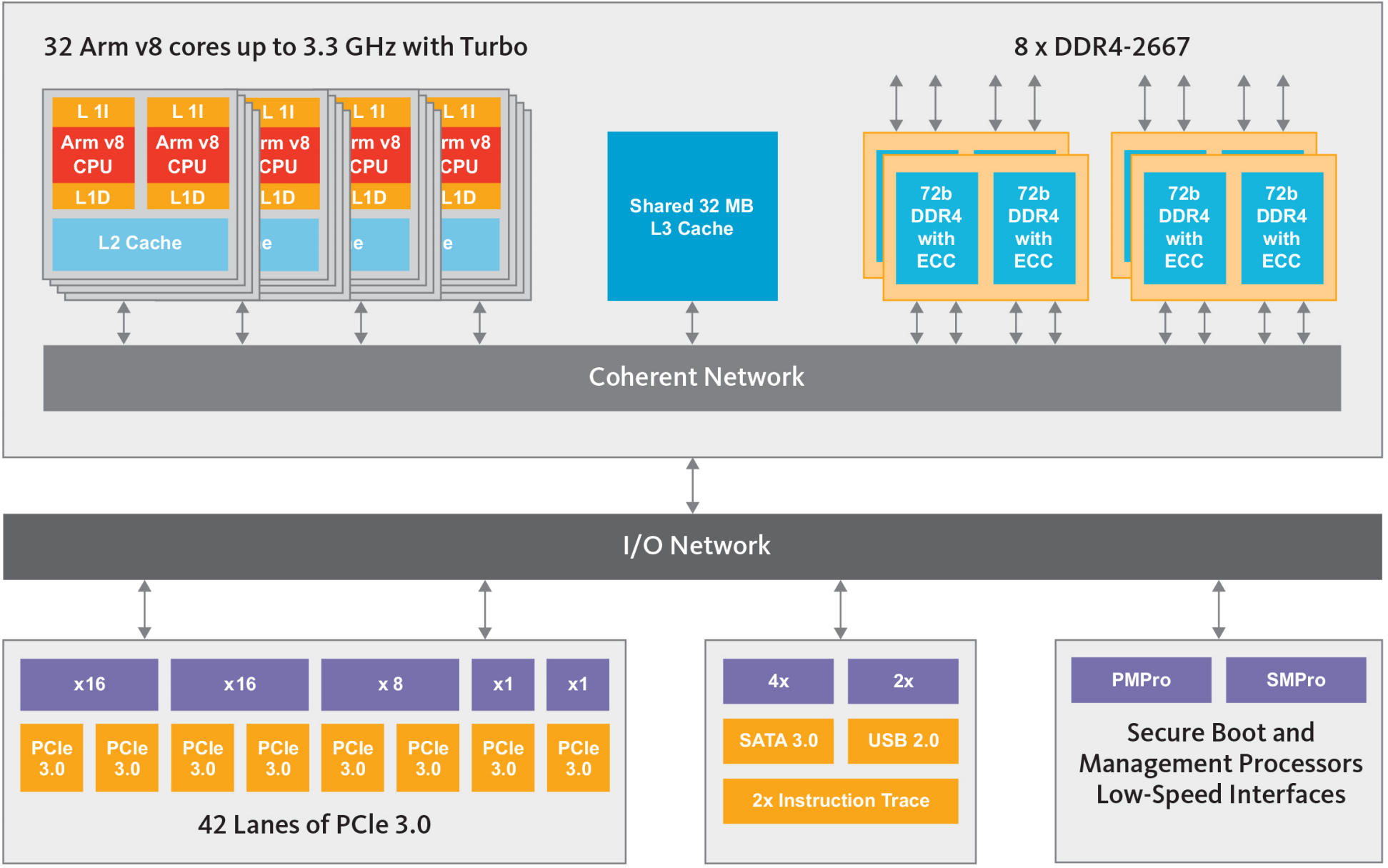
On a chip-level, the CPU is characterised by having a large coherent network tying all the CPU modules, the memory controllers, and a big large 32MB L3 cache together.
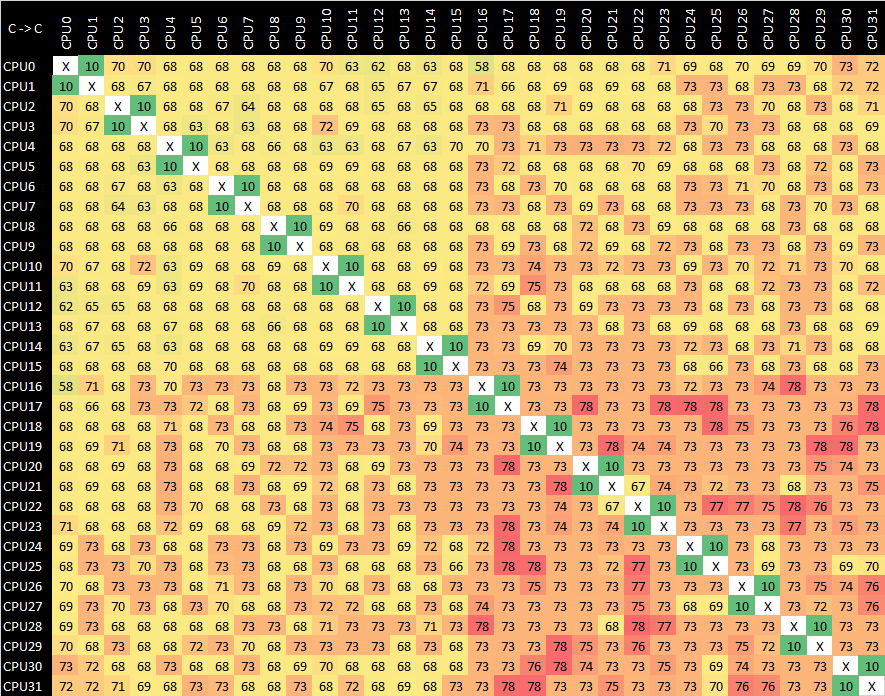
What’s surprising here is that the core-to-core latency across the whole chip isn’t bad at all, ranging from 68-73ns. While this certainly doesn’t keep up with more recent monolithic designs, this is an Arm v8.0 core lacking CAS atomic operations – so the above figures are done via regular sequential exclusive load / exclusive stores which aren’t as fast. The coherency here going over the 32MB L3 cache certainly helps the system punch above its weight for a design of its time.
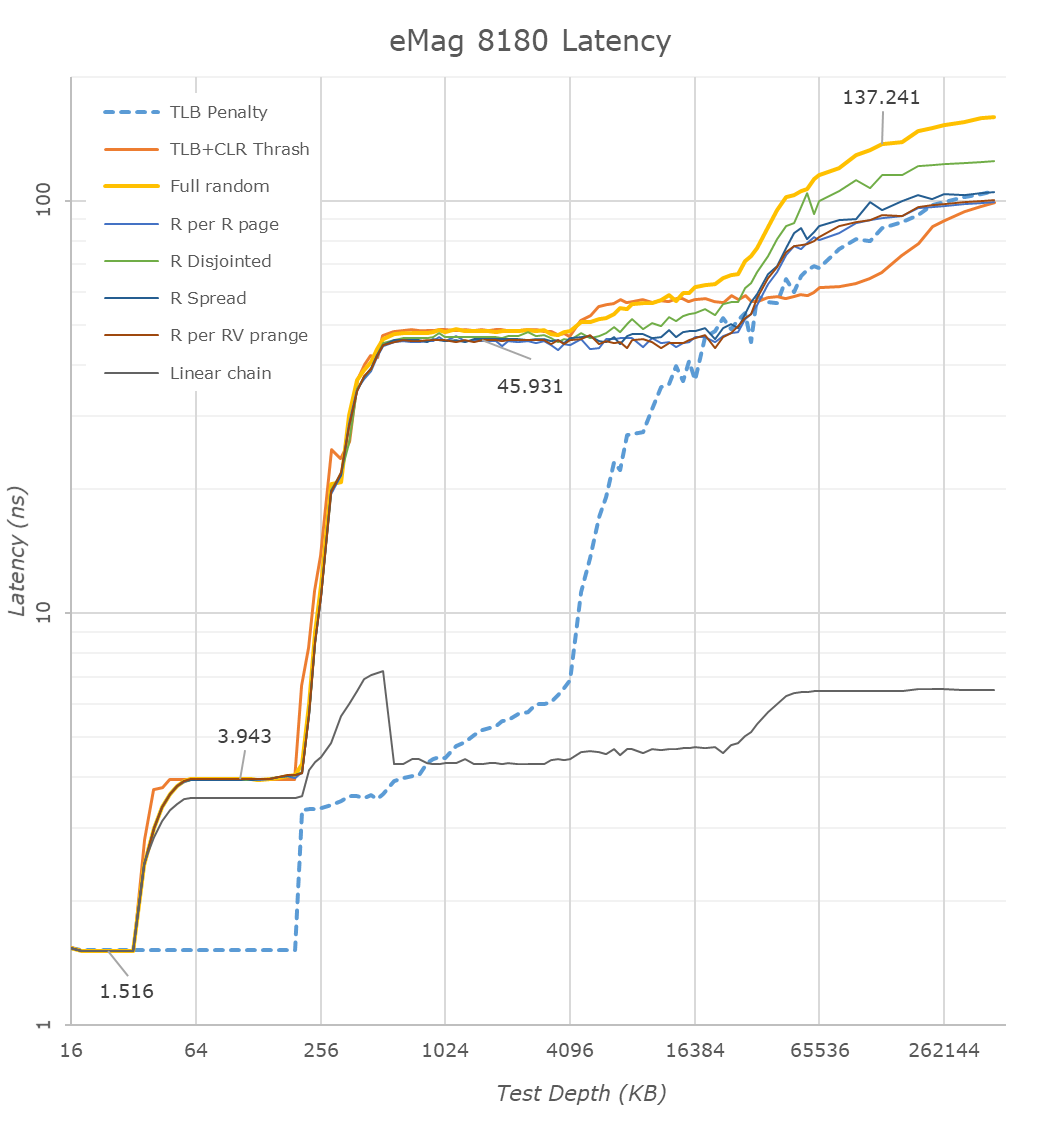
The CPU cores have 32KB L1 instruction and data caches – the access latencies here are 5 cycles. The 256KB L2 caches has a 13-cycle access latency, while the 32LB L3 cache has some massive 45ns+ access latencies that are much slower than any other comparable design out there.
We note the core’s L1 TLB ends at 48 pages (192KB) and the L2 TLB at 1024 pages (4MB), after which page-miss access times increasingly result in worse latencies.
In contrast with the quite large cache access latencies, the DRAM access latency isn’t all that bad at around 137ns full random at 128MB depth.
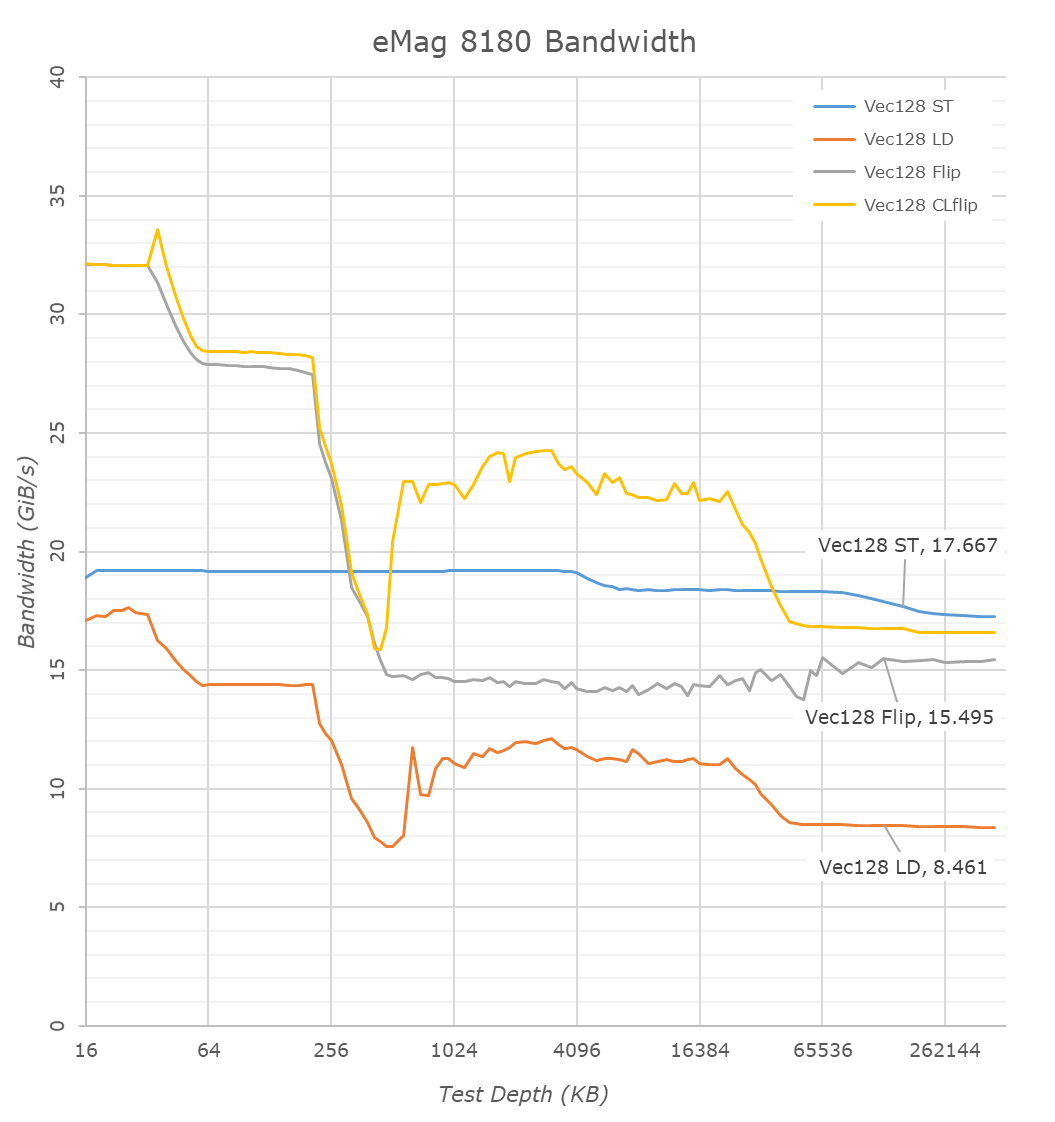
Single-core bandwidth of the Skylark cores isn’t too pretty, load and store bandwidth into the L1 and L2 seem to be limited at 8B/cycle and a combined 16B/cycle for concurrent load & stores. The dip between the L2 and L3 is usually a showcase of a bandwidth bottleneck when evicting/replacing a cacheline, and the load bandwidth at the DRAM level is also quite disappointing.
Overall, the performance here is only half of a more modern Arm core, but again, this is a 2015-2016 core design.








35 Comments
View All Comments
SarahKerrigan - Friday, May 22, 2020 - link
The X-Gene microarchitecture was never particularly stellar and by the time eMag rolled around it was woefully obsolete. I did some testing on eMag a few months back and it was pretty dire. When I spent some time on Graviton2 last week, it was like night and day compared to eMag (frequently 2+ times the single-thread perf despite a much lower clock), so I have high hopes for Altra.SarahKerrigan - Friday, May 22, 2020 - link
By the way, Andrei, you may want to correct the ST SPECFP subtest result graph - it looks like you used Graviton as a template and forgot to change the labels to eMag, because right now it only mentions Graviton1, and Graviton2, and Intel, not eMag.Andrei Frumusanu - Friday, May 22, 2020 - link
Thanks, good catch.Flunk - Friday, May 22, 2020 - link
Interesting to see even if this hardware only makes sense for very specialized purposes. ARM processors have gone from only applicable to mobile devices to something that would have made sense in a server a few years ago.SarahKerrigan - Friday, May 22, 2020 - link
This isn't exactly a good representative of ARM processors; chips like Graviton2 are competitive for server workloads today, and make eMag look like a toy by comparison.eastcoast_pete - Friday, May 22, 2020 - link
Thanks Andrei, good and in-depth review! You and others here have already commented on the great difference of this legacy CPU to Ampere's Altra or Amazon's Graviton 2. What I am also very curious about is Fujitsu's ARM-based multicore CPU (A64FX). Amongst other features, it supports 512-bit scalable vector extensions (SVEs), so same width as Intel's AVX512. I wonder if someone at Fujitsu reads Anandtech, and maybe send you a setup for review, although a PRIMEHPC might be out of the scope here. Still, that's an ARM v8 design that should beat the Graviton 2 and the Altra, especially if applications can make use of the wide SVEs.anonomouse - Friday, May 22, 2020 - link
Based on what we know of the A64FX, it’ll almost certainly *only* beat Graviton 2/Altra in cases where it can heavily utilize wide vectors. In all other scenarios it really doesn’t have a lot of execution width, and only runs at 2.2Ghz. The disclosures in their Microarchitecture guide also don’t showcase anything impressive looking on the branch predictor, which is fine for the typical HPC workloads it will run. That thing is very heavily purpose designed for HPC, and it’s clear they focused on that and not general performance.SarahKerrigan - Friday, May 22, 2020 - link
Indeed. It's a specialized chip. I would expect no miracles from it on general-purpose loads.eastcoast_pete - Friday, May 22, 2020 - link
Agree with you and anonomouse on general purpose loads; my interest in wide vectors is mainly due to their utility for video processing and encoding, if (!) the software supports it. For those applications, AVX512 is what keeps Intel competitive with EPYCs in the x64 space. As a question, is anything like an AV1 encoder even available for ARM v8, and specifically to use wide SVEs?Wilco1 - Saturday, May 23, 2020 - link
There are many AV1 codecs which have AArch64 optimizations, but most focus on older mobile phone cores (eg. http://www.jbkempf.com/blog/post/2019/dav1d-0.5.0-... ), so likely need further work on latest microarchitectures with up to 4 128-bit Neon pipes.It's early days for SVE, the first version (as in A64FX) is aimed at HPC. Video codecs will be optimized for SVE2 when hardware becomes available.