Marvell Announces ThunderX3: 96 Cores & 384 Thread 3rd Gen Arm Server Processor
by Andrei Frumusanu on March 16, 2020 8:30 AM EST- Posted in
- Servers
- CPUs
- Marvell
- Arm
- Enterprise
- Enterprise CPUs
- Cavium
- ThunderX3

The Arm server ecosystem is well alive and thriving, finally getting into serious motion after several years of false-start attempts. Among the original pioneers in this space was Cavium, which went on to be acquired by Marvell in 2018. Among the company’s server CPU products is the ThunderX line; while the first generation ThunderX left quite a lot to be desired, the ThunderX2 was the first Arm server silicon that we deemed viable and competitive against Intel and AMD products. Since then, the ecosystem has accelerated quite a lot, and only last week we saw how impressive the new Amazon Graviton2 with the N1 chips ended up. Marvell didn’t stop at the ThunderX2, and had big ambitions for its newly acquired CPU division, and today is announcing the new ThunderX3.
The ThunderX3 is a continuation and successor to then-Cavium’s custom microarchitecture found in the TX2, adopting a lot of the key characteristics, most notably the capability of 4-way SMT. Adopting a new microarchitecture with higher IPC capabilities, the new TX3 also ups the clock frequencies, and now hosts up to a whopping 96 CPU cores, allowing the chip to scale up to 384 threads in a single socket.

Marvell sees the ecosystem shifting in terms of workloads as more and more applications are shifting to the cloud, and applications are changing in their nature, with more customers employing their own custom software stacks and scaling out these applications. This means that workloads aren’t necessarily focused just on single-threaded performance, but rather on the total throughput available in the system, at which point power efficiency also comes into play.

Like many other Arm vendors, Marvell sees a window of opportunity in the lack of execution of the x86 incumbents, very much calling out Intel’s stumbling in process leadership over the past few years, and in general x86 designs being higher power. Marvell describes that part of the problem is that the current systems by the x86 players were designed with a wide range of deployment targets ranging from consumer client devices to the actual server machines, never actually achieving the best results in either workloads. In contrast, the ThunderX line-up is reportedly designed specifically with server workloads in mind, being able to achieve higher power efficiency and thus also achieving higher total throughput in a system.
We’ve known that ThunderX3 has been coming for quite a while now, admittedly expecting it towards the latter half of 2019. We don’t know the behind-the-scenes timeline, but now Marvell is finally ready to talk about the new chip. Marvell’s CPU roadmap is on a 2-year cadence, and the chip company here explains that this is a practical timeline, allowing customers time to actually adopt a generation and get good return on investment on the platform before possibly switching over to the next one. Of course, this also gives the design team more time to bring to market larger performance jumps once the new generations are ready.
The ThunderX3 - 96 Cores and 384 Threads in Arm v8.3+

So, what is the new ThunderX3? It’s a ambitious design hosting up to 96 Arm v8.3+ custom cores running at up to frequencies of up to 3GHz all-core, at TDPs ranging from 100 to 240W depending on the SKU.
Marvell isn’t quite ready to go into much details of the new CPU microarchitecture just yet, saying that they’ll divulge a deeper disclosure of the TX3 cores later in the year (They’re aiming for Hotchips), but they do say that one key characteristic is that it now features 4 128-bit SIMD execution units, matching the vector execution throughput of AMD and Intel’s cores. When fully using these units, clock frequencies for all-core drop between 2.2 and 2.6GHz, limited by the thermal and power headroom available to the chip.
Having SMT4, the 96-core SKU is able to scale up to 384 threads in a socket, which is by far the highest thread count of any current and upcoming server CPU in the market, a big differentiating factor for the ThunderX3.
Marvell doesn’t go into details of the topology of the chip or its packaging technology, only alluding that it’ll have monolithic latencies between the CPU cores. The design comes in either 1 or 2 socket configurations, and the inter-socket communication uses CCPI (Cavium Cache Coherent Interconnect) in its 3rd generation, with 24 lanes at 28Gbit/s each, between the two sockets.
External connectivity is handled by 64 lanes of PCIe 4.0 with 16 controllers per socket, meaning up to 16 4x devices, with the choice of multiplexing them for higher bandwidth connectivity for 8x or 16x devices.
Memory capabilities of the chip is in line with current generation standards, featuring 8 DDR4-3200 memory controllers.
Marvell plans several SKUs, scaling the core count and memory controllers, in TDP targets ranging from 100W to 240W. These will all be based on the same silicon design, and binning the chips.
Large Generational Performance Improvements
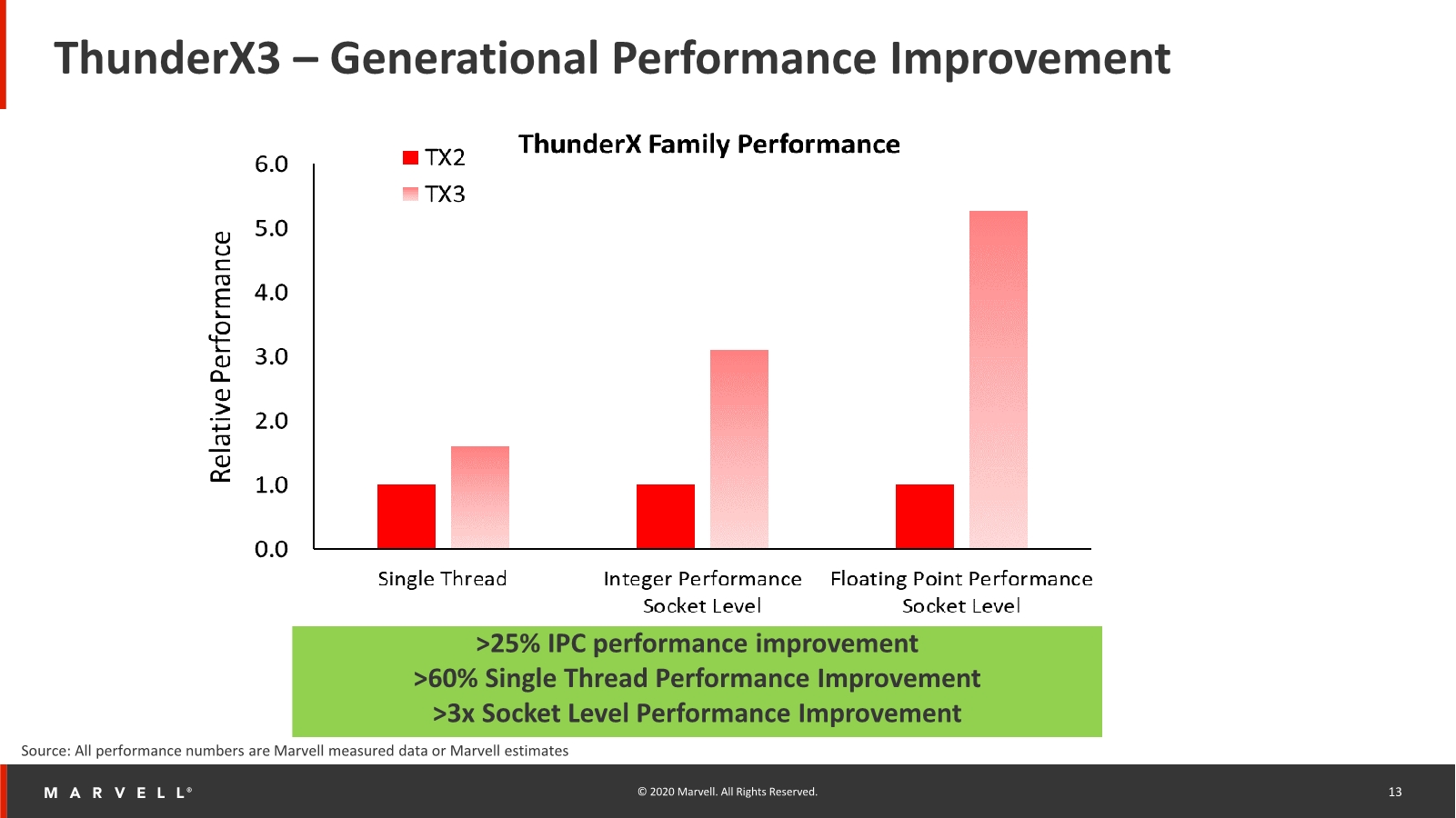
In a comparison to the previous generation ThunderX2, the TX3 lists some impressive performance increases. IPC is said to have increased by a minimum of 25% in workloads, with total single-threaded performance going up to at least 60% when combined with the clock frequency increases. If we use the TX2 figures we have at hand, this would mean the new chip would land slightly ahead of Neoverse-N1 systems such as the Graviton2, and match more aggressively clocked designs such as the Ampere Altra.
Socket-level integer performance has at least increased by 3-fold, both thanks to the more capable cores as well as their vastly increased core number to up to 96 cores. Because the new CPU has now more SIMD execution units, floating point performance is even higher, increasing to up to 5x.
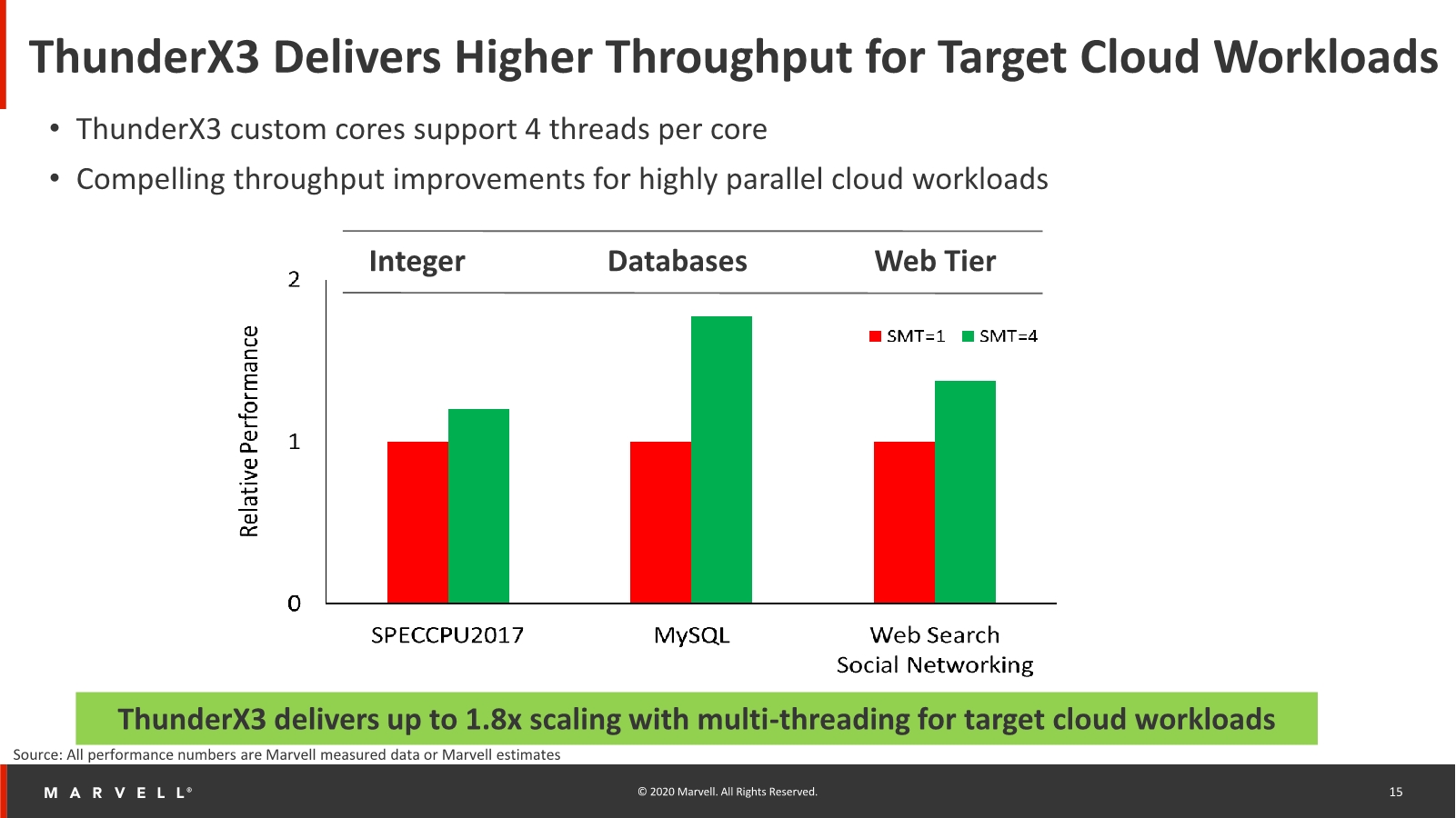
Because the chip comes with SMT4 and it’s been designed with cloud workloads, it is able to extract more throughput out of the silicon compared to other non-SMT or SMT2 designs. Cloud workloads here essentially means data-plane bound workloads in which the CPU has to wait on data from a more distant source, and SMT helps in such designs in that the idle execution clocks between data accesses is simply filled by a different thread, doing long latency accesses itself.
ThunderX3 Performance Claims Against the Competition
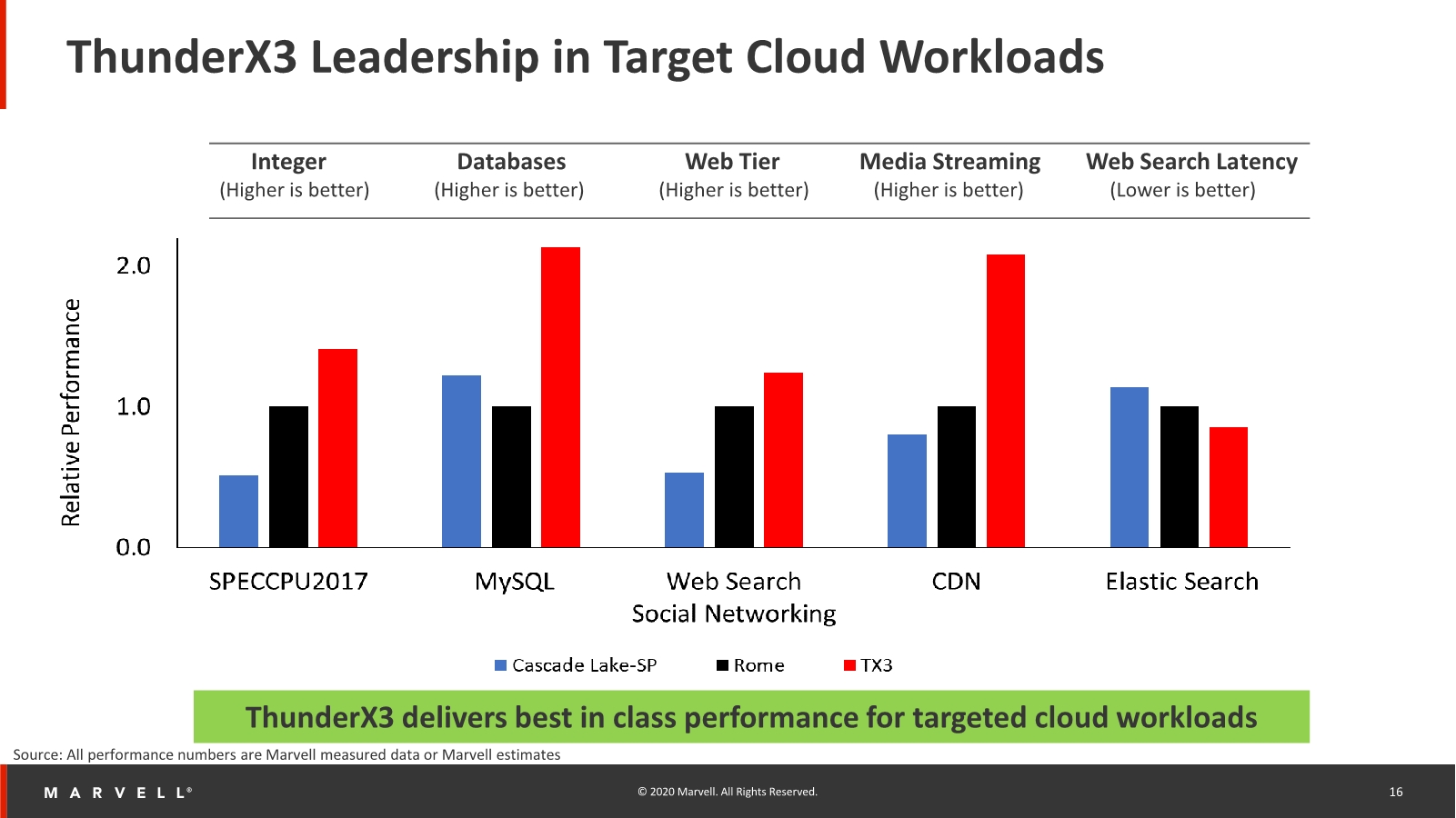
Using this advantage, the ThunderX3 is said to have significant throughput advantages compared to the incumbent x86 players, vastly exceeding the performance of anything that Intel has currently to offer, and also beating AMD’s Rome systems in extremely data-plane bound workloads thanks to the SMT4 and higher core counts.
More execution and compute bound workloads will see the least advantages here, as the SMT4 advantages greatly diminishes.
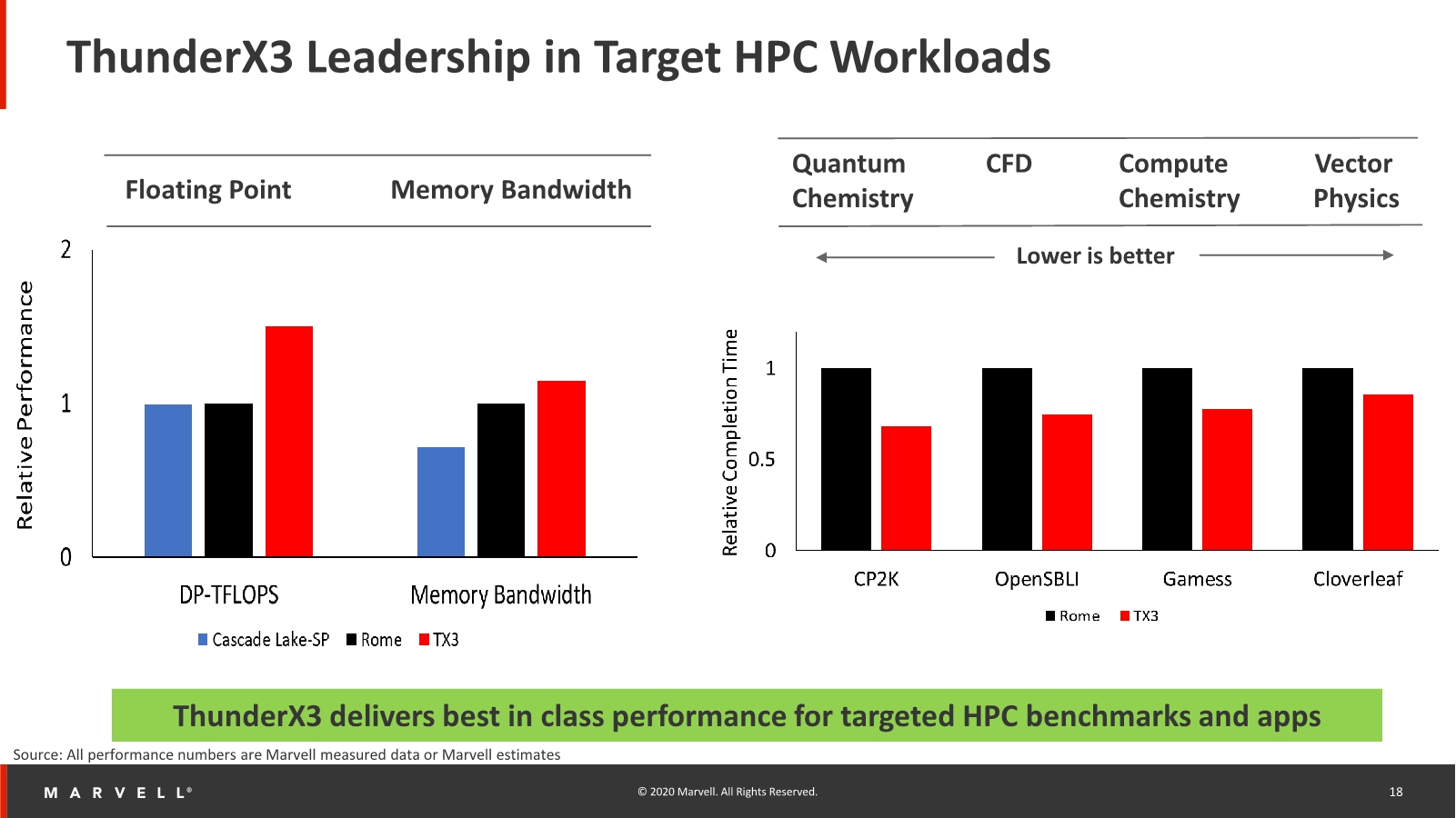
Yet for HPC and in particular floating-point workloads, the ThunderX3 is said to also be able to showcase its strengths thanks to the increased SIMD units as well as the overall power efficiency of the system, allowing for significant higher performance in such calculations. Memory bandwidth is also higher than a comparative AMD Rome based system because the lower latencies the TX3 is able to achieve. It’s to be noted that the ThunderX3 will be coming to market later in the year, by which time they’ll have to compete with AMD’s newer Milan server CPU.
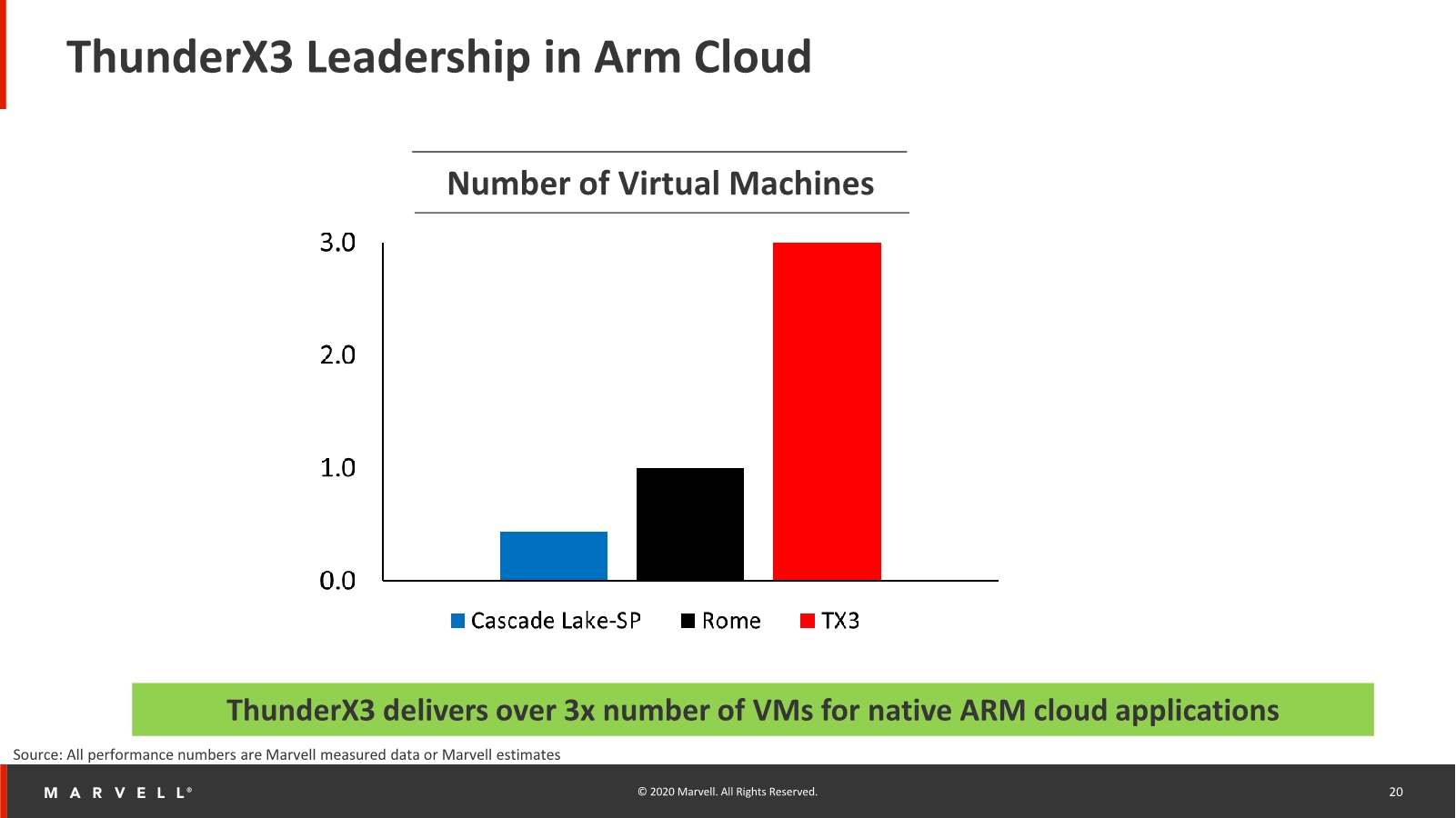
Marvell says that Arm in the cloud is gaining a lot of traction, and the company is already the market leader in terms of deployments of its ThunderX2 system among companies and hyperscalers (Microsoft Azure currently being the one publicly disclosed, but it’s said that there are more). I don’t really know if having a extremely high number of virtual machines being hosted on a single chip is actually an advantage (because of SMT4, per-VM performance might be quite bad), but Marvell does state that they’d be the leader in this metric with the ThunderX3, thanks to be able to host up to 384 threads.
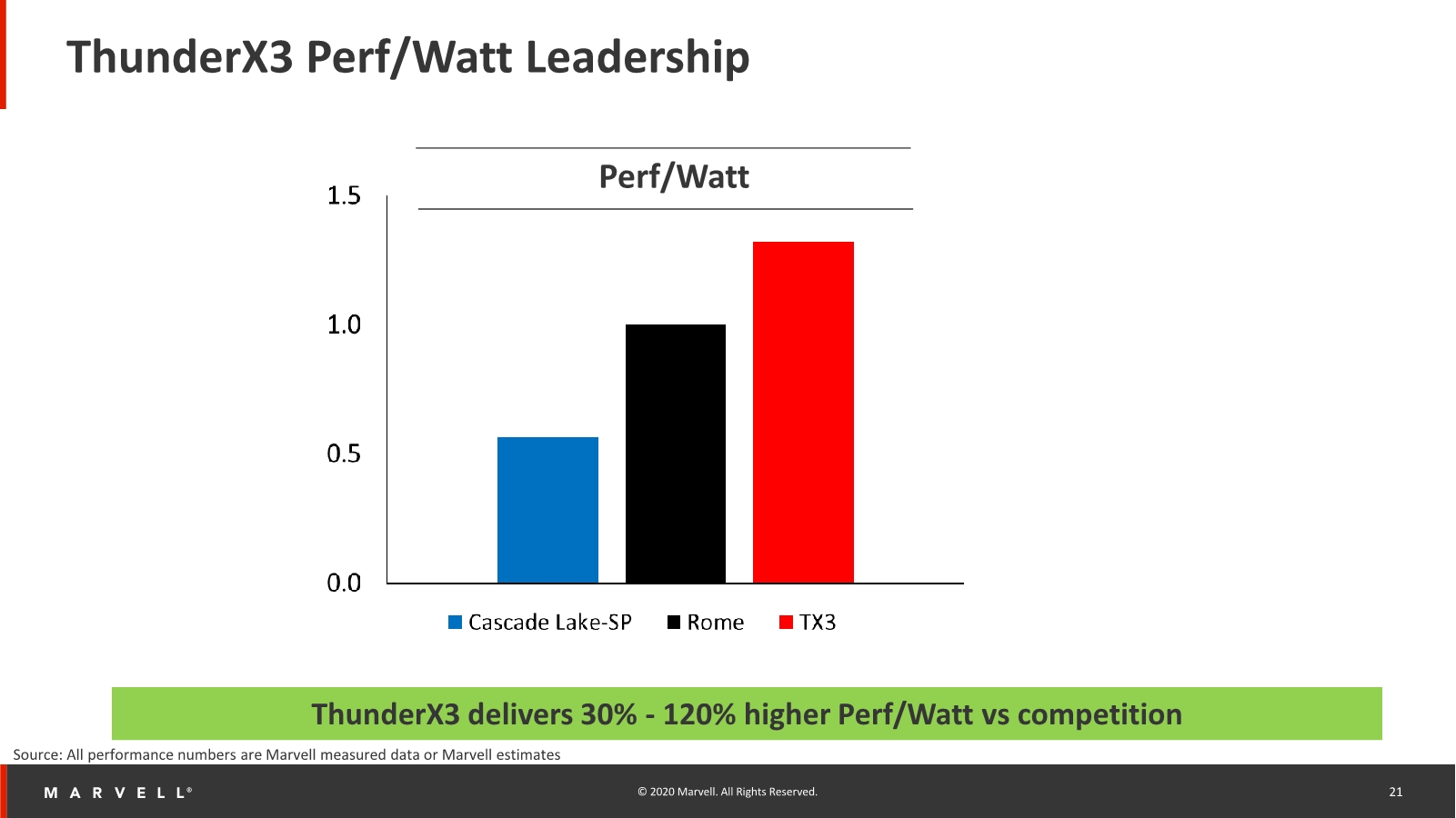
Finally, the company claims a 30% perf/W advantage over AMD’s Rome platform across an average of different workloads, thanks to the more targeted microarchitecture design. The more interesting comparison here would have been a showcase or estimate of how the ThunderX3 would fare against Neoverse-N1 systems such as the Graviton2 or the Altra, as undoubtedly the latter system would pose the closest competitor to the new Marvell offering. Given that the Altra isn’t available yet, we don’t know for sure how the systems will compete against each other, but I do suspect that the ThunderX3 to do better in at least FP workloads, and of course it has an indisputable advantage in data-plane workloads thanks to the SMT4 capability.
More Information at Hotchips 2020
Marvell hasn’t yet disclosed much about the cache configuration or any other specifics of the system, for example what kind of interconnect the cores will be using or what kind of CPU topology they will be arranged in. The ThunderX3’s success seemingly will depend on how it’s able to scale performance across all of its 96 cores and the 384 threads – but at least as an initial impression, it seems that it might do quite well.
Today is just the initial announcement of the TX3, and Marvell will be revealing more details and information about the new CPU and the product line-up over the following months till the eventual availability later in the year.








44 Comments
View All Comments
senttoschool - Monday, March 16, 2020 - link
That’s fine. I don’t think ARM makers expect total domination upon release.I think this is a 5-10 year shift.
You first need significantly better hardware to convince some software makers to switch. That’s how it gets started. You also have an 800 gorilla in Amazon pushing this.
mdriftmeyer - Tuesday, March 17, 2020 - link
This is a never will be shift. It's will have its targeted areas and no it will not replace the advancements of and the massive ones to come from AMD, never mind Intel.eek2121 - Monday, March 16, 2020 - link
Linux runs just fine on ARM.eastcoast_pete - Monday, March 16, 2020 - link
If ARM and it's licensees would want to jumpstart development, make a thousand or more free workstation-type systems with your newest and hottest server chips available longer-term free of charge for the top developers in that space. Even the big boys will start playing with a free toy. It would mean even more for smaller, independent developers, and don't forget to give special consideration to those individuals involved in open-source software, starting with Linux. I know such a "giveaway/free loan" would cost tens of millions of dollars, but it'd give them buzz and likely help getting that software out there.rahvin - Monday, March 16, 2020 - link
Unlikely. There aren't just a handful of software companies. Even if they did get working with the top 10 commercial applications they'd still be handicapped by the broad support x86 offers.jeremyshaw - Monday, March 16, 2020 - link
For Nvidia, ARM is rapidly becoming do or die. AMD CPUs are no longer a joke, and Intel is pushing its dGPU ambitions to survive as well. IBM is faltering without a good foundry, and they chose their old partner Samsung, who is still largely unproven at HPC equipment.Nvidia is out in the cold, here, and are desperate enough to have ported their CUDA development stack to ARM and are now trying to roadmap the Jetson series. None of that matters, IMO, without a laptop somewhere, and I don't see Nvidia entering that market, ever. The other ARM laptop attempts by MSFT/Qualcomm has been largely misguided whiffs.
This is all assuming Nvidia can even get the ARM CPU developers to follow their roadmap better than IBM could, or if the ARM CPU companies even want to.
Yojimbo - Monday, March 16, 2020 - link
NVIDIA was supposedly out in the cold ever since Intel declared war on them and AMD bought ATI 14? years ago. AMD or Intel are going to have to improve their GPU ecosystem a whole lot to convince people to use their GPUs for commercial compute. It's very easy to attach an NVIDIA GPU with an Intel processor or an NVIDIA GPU with an AMD processor. In fact, if one is interested in GPU compute, it is the GPU and its ecosystem that is what's important. One can use an AMD or an Intel platform with the NVIDIA GPU.NVIDIA expanding their software to ARM is not desperate, it's just a natural expansion of their ecosystem. Now it is on x86, OpenPower, and ARM. If RISC-V comes along they will support that, too.
Yojimbo - Monday, March 16, 2020 - link
Oh, and you seem to be under the impression that NVIDIA's GPUs are primarily linked to IBM's CPUs. IBM CPUs account for a very small number of CPUs hosting NVIDIA's data center GPUs. Almost all are Intel processors. NVIDIA will have access to the host bus with CXL just like they do with IBM now. Intel tried to keep NVIDIA off their bus, but once Intel went to GPUs they could no longer do that. NVIDIA's partnership with IBM has mostly to do with supercomputer contracts, which is high profile but both a very small part of the market and also a part of the market that is much, much easier to address. In supercomputing they use compiler directives to target accelerators. In commercial applications they use a whole lot of CUDA code.FunBunny2 - Monday, March 16, 2020 - link
"n supercomputing they use compiler directives to target accelerators. "it's called PRAGMA, and why do folks make such a freaking big deal about different cpu. it's a solved problem for a really long time. now, actually finding all the bits and pieces that need be flagged well could be. but the tools are there.
vvid - Tuesday, March 17, 2020 - link
>> The other ARM laptop attempts by MSFT/Qualcomm has been largely misguided whiffs.I have Galaxy Book S and it is awesome. A76 is enough to emulate x86 apps without a hassle. Don't yet have any native apps except benchmarks. Visual studio and dev software works fine.