AMD Financial Analyst Day 2020 Round-Up: Laying A Path For Bigger & Better Things
by Ryan Smith on March 5, 2020 8:15 PM EST- Posted in
- CPUs
- AMD
- Radeon
- GPUs
- Infinity Fabric
- Zen 3
- RDNA2
- AMD FAD 2020
- CDNA

AMD’s first Financial Analyst Day since 2017 has just wrapped up. In the last three years AMD has undergone a dramatic change, launching its Zen CPU architecture, and greatly improving the trajectory of a company that was flirting with bankruptcy a few years ago. And now that AMD’s foundation is once again secure, the company has gathered to once again talk to its loyal (and looking at stock prices, now much richer) investors and how it’s planning to use this success to push into bigger and better things.
We’ve been covering FAD 2020 throughout the afternoon, and we have seen AMD make a number of announcements and roadmap reveals throughout the event. The individual announcements are below, and meanwhile now that the event has wrapped up we want to provide a quick summary of what AMD is going to be up to over the next five years.
AMD Shipped 260 Million Zen Cores by 2020
AMD Discusses ‘X3D’ Die Stacking and Packaging for Future Products: Hybrid 2.5D and 3D
AMD Moves From Infinity Fabric to Infinity Architecture: Connecting Everything to Everything
AMD Unveils CDNA GPU Architecture: A Dedicated GPU Architecture for Data Centers
AMD's 2020-2022 Client GPU Roadmap: RDNA 3 & Navi 3X On the Horizon With More Perf & Efficiency
AMD's RDNA 2 Gets A Codename: “Navi 2X” Comes This Year With 50% Improved Perf-Per-Watt
Updated AMD Ryzen and EPYC CPU Roadmaps March 2020: Milan, Genoa, and Vermeer
AMD Clarifies Comments on 7nm / 7nm+ for Future Products: EUV Not Specified
The big takeaway from the financial side of AMD is of course that the company is profitable. After at one point having more debts than cash, careful spending on AMD’s part along with the success of their Zen CPUs and recent GPUs has lifted AMD’s fortunes greatly. The company is now consistently profitable, revenues are growing, and at the same time it’s able to deliver results to shareholders while still using their new success to increase investments in critical R&D.
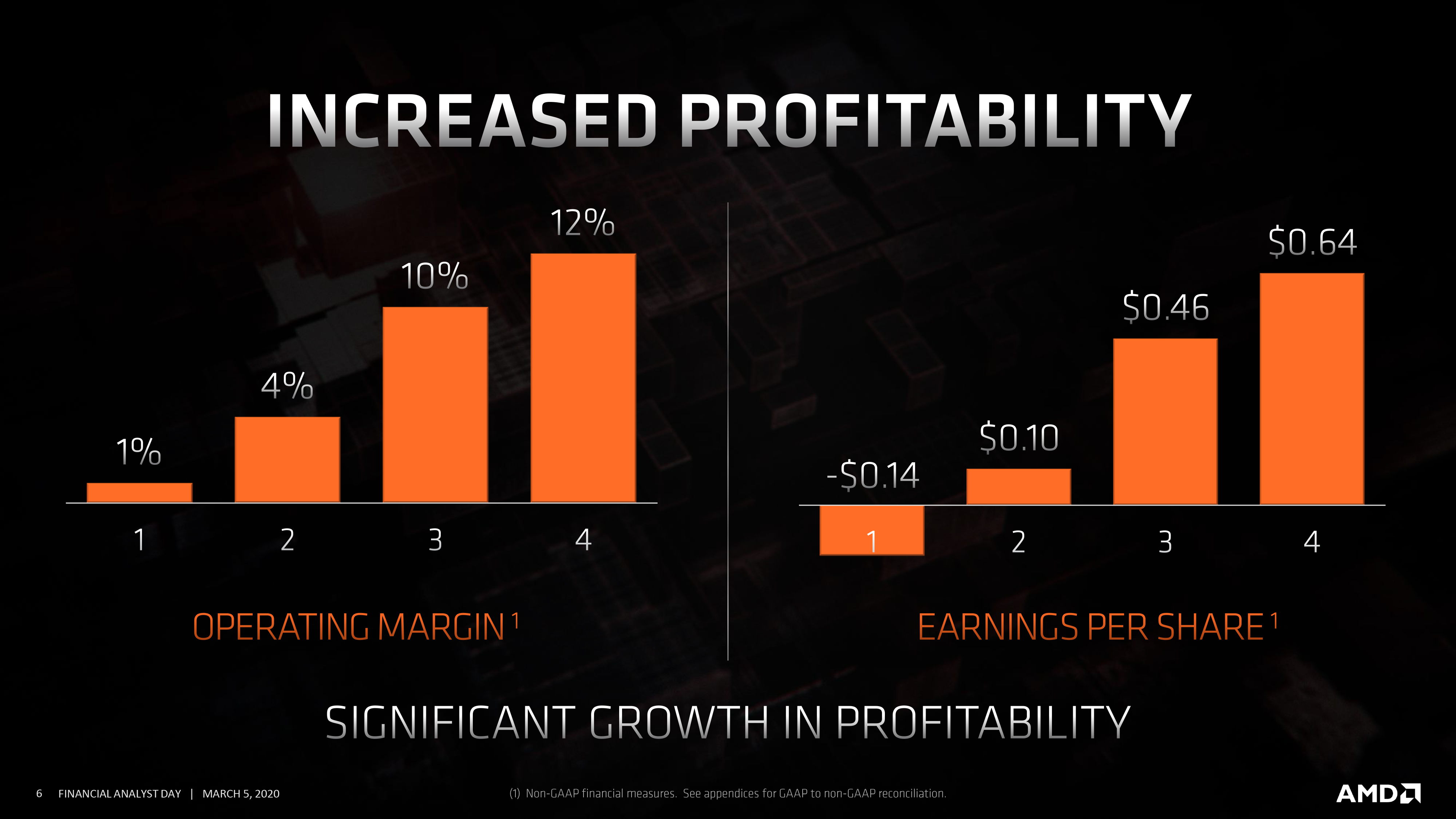
As a result, the AMD of 2020 is a much different company than the AMD of 2017. Instead of needing to survive, as was the case in 2017, AMD in 2020 gets to thrive. And as a result CEO Dr. Lisa Su is looking to taking AMD on to bigger and better things; to leverage AMD’s strengths to grow the company’s market share and take advantage of new opportunities, all while continuing her successful strategy of focused execution.
The big focus here (though far from sole) is on the data center market. Long the breadbasket of Intel and increasingly NVIDIA as well, it’s a highly profitable market that continues to grow. And it’s a market that slipped away from AMD, and which they’re now clawing back on the strength of their EPYC processors. Over the next 5 years AMD wants to take a much bigger piece of the total data center pie, and in fact the company expects to cross 10% market share of data center CPUs this next quarter. Which, by our reckoning, would be the first time they've hit that kind of market share in a decade (if not more), showing just how much things have changed for AMD.
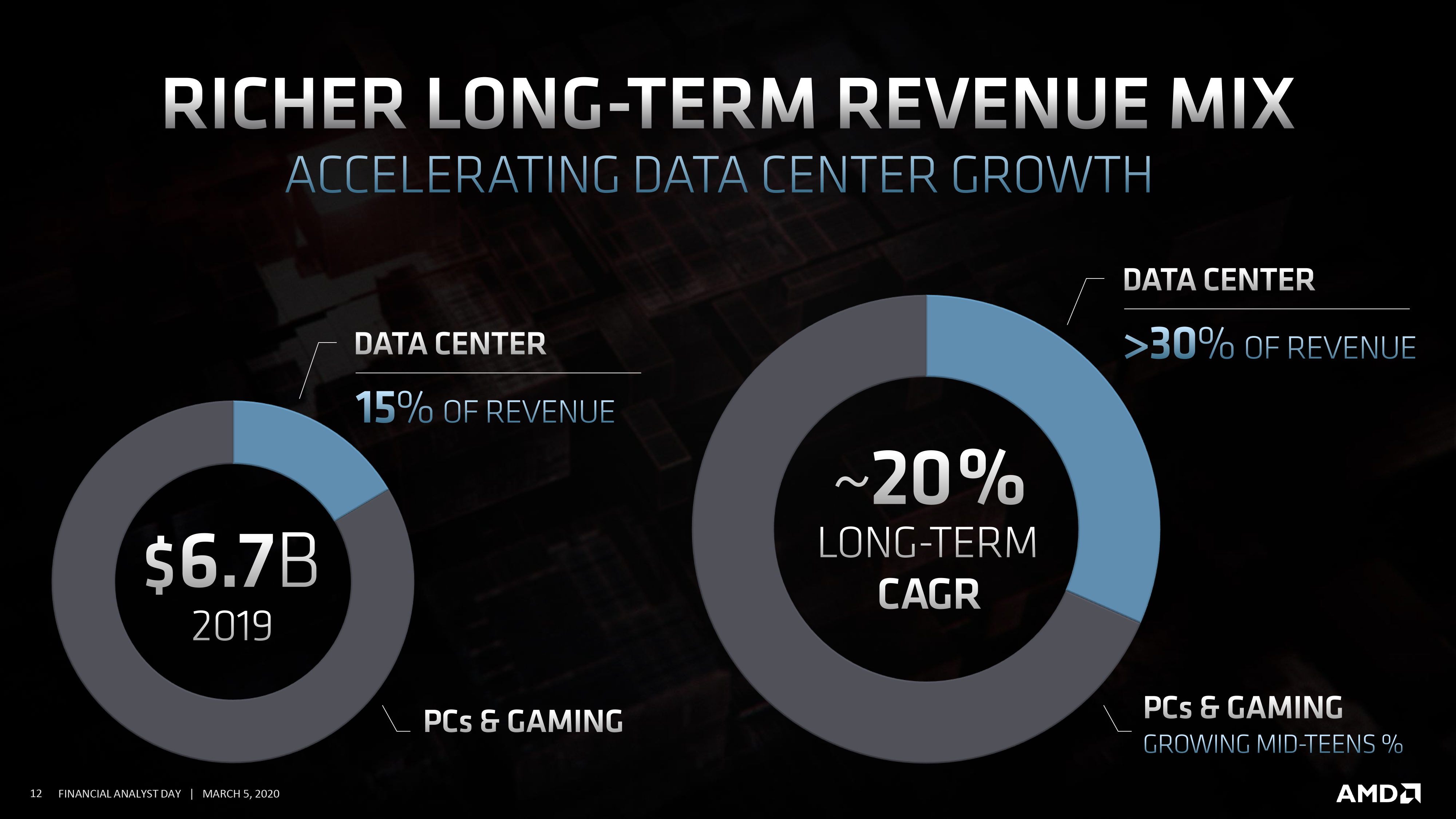
The biggest tool here of course will be pushing the envelope with future EPYC processors. Showing off an extended roadmap for EPYC processors that goes out to AMD’s Zen 4 CPU architecture, the company is hard at work on its Milan and Genoa. Genoa in particular is a hot topic, as the United States Dept. of Energy just selected it to be used as the CPU in the forthcoming, 2 exaflop El Capitan supercomputer.

And the GPU? A part based on AMD’s forthcoming CDNA 2 compute GPU architecture.

Revealed today as part of AMD’s roadmaps, CDNA is AMD’s new designation for their compute-focused GPU architecture. A successor of sorts of the GCN architecture used in previous server GPUs like Vega 20, AMD’s server GPUs are now a distinct family separate from AMD’s RDNA architecture and the consumer GPUs that come from that branch of the family. By focusing on compute features, machine learning performance, and multi-GPU scalability, AMD has ambitious plans for their server GPU architecture. The CDNA family will see its first dedicated GPU released later this year, while GPUs based on the CDNA 2 architecture are due by the end of 2022.

Along with great GPU performance, the other big upgrade for the CDNA family is incorporating AMD’s Infinity Architecture (née Infinity Fabric). Already extensively used in AMD’s EYPC CPUs, the interconnect technology is coming to AMD’s GPUs, where it will play a part both in AMD’s multi-GPU efforts, as well as AMD’s grander plans for heterogeneous computing. With the third generation of the technology scheduled to offer full CPU/GPU coherency, allowing for a single unified memory space, the Infinity Architecture will be how AMD leverages both their CPU and GPU architectures to secure even bigger wins by using them together.
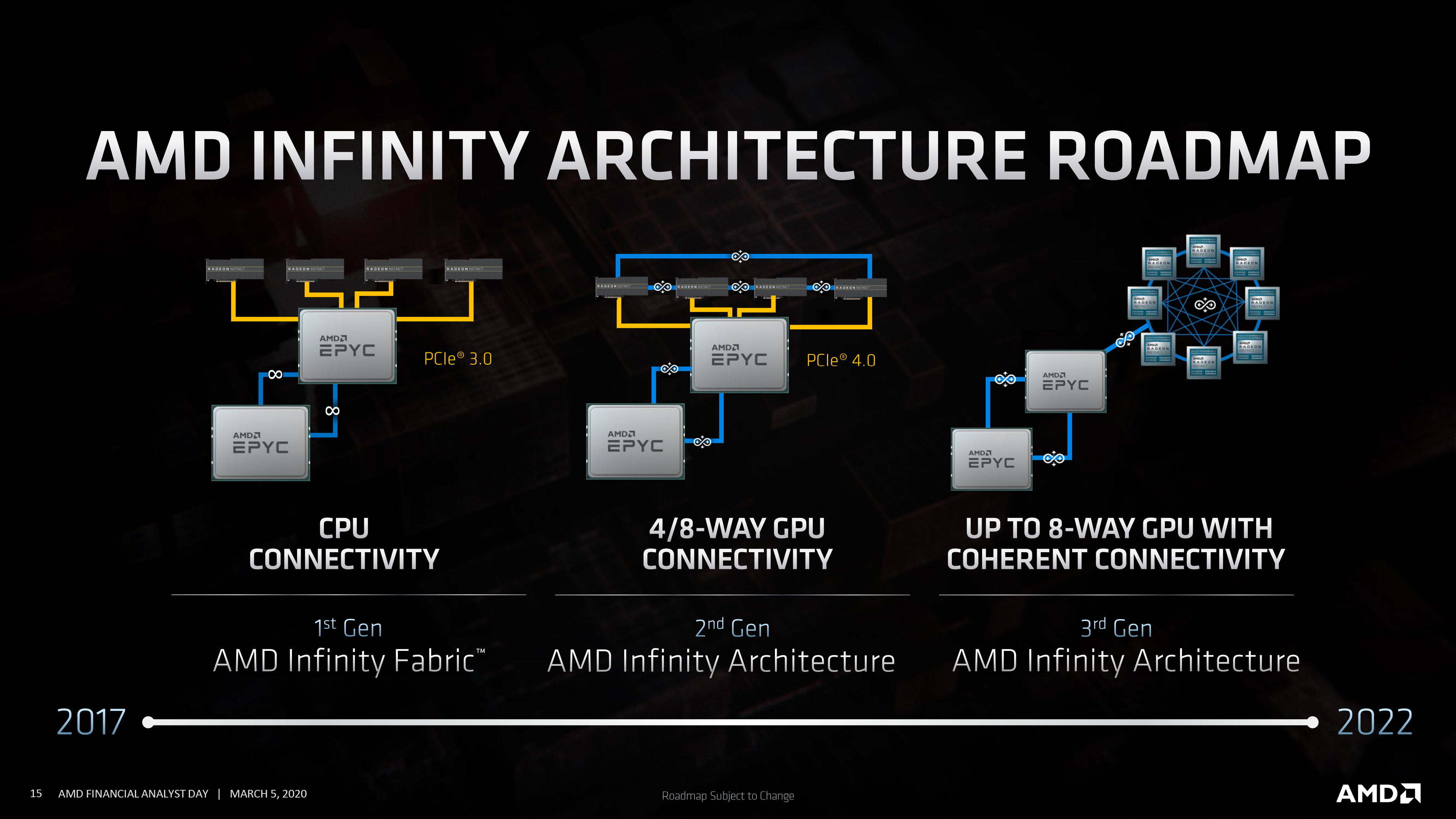
And not to be left out of all of this are AMD’s consumer products. While admittedly not receiving quite the same focus today as their server products – there isn’t quite the same opportunity for profit growth – AMD is hard at work for new consumer CPUs and GPUs.
On the GPU side of matters, AMD dropped a few more details on their previously revealed RDNA 2 architecture. With GPUs (and game consoles) using the architecture due to arrive later this year, RDNA 2 and the Navi 2X GPUs based on it will offer a mix of new features and efficiency improvements. With regards to features, the updated architecture will add hardware ray tracing as well as variable rate shading, closing the feature gap with rival NVIDIA. Meanwhile AMD is touting a 50% improvement in performance-per-watt, a sizable jump in efficiency that would be on par with the original RDNA architecture.

And AMD is aiming high, as well. After playing second-fiddle to NVIDIA for the past few years in terms of the performance of their top GPUs, AMD is planning to offer video cards with top-tier performance, capable of delivering “uncompromising” 4K gaming. AMD’s rivals won’t be standing still, of course, but AMD believes they have the technology and the energy efficiency needed to deliver the extreme performance that enthusiasts are looking for.

Following RDNA 2 will be RDNA 3. AMD isn’t saying much about the architecture other than that the chips for it will be the Navi 3X family, but it will iterate on RDNA2 by delivering even greater improvements in performance and efficiency. The architecture is slated to use a new process node – so not the 7nm variant used in RDNA 2 – but AMD is not disclosing that node at this time, opting to simply label it as “advanced node.” RDNA 3 GPUs will show up by the end of 2022.

As for AMD’s consumer CPUs, as mentioned previously, the development of their Zen 3 CPU architecture remains on track. So fourth generation Ryzen processors based on the updated CPU architecture are expected by the end of this year (though, we suspect, after Zen 3 ships for EPYC).
Finally, along with specific product updates, AMD also talked briefly about some of their general technology focuses over the next 5 years. As Moore’s Law is continuing to slow down, newer and more exotic chip packaging methods are required to keep chip performance improvements going. And AMD, who is already well-versed in 2.5D technologies thanks to its use of chipsets on Zen 2 processors, is also looking at 3D stacking.

Dubbed “X3D”, the company wants to use a hybrid of 2.5D and 3D stacking to achieve a significant increase in bandwidth density. All told, AMD is touting a potentially better than 10x improvement in bandwidth density over today’s chiplets if their plans come to fruition.

Finally, the focus on future technologies has also required that AMD take a bit more care in what they say regarding future manufacturing nodes. AMD’s 2020 roadmaps have scrubbed any mention of “7nm+”, which was on their future roadmaps, in order to avoid any confusion with TSMC’s EUV-based “N7+” node. To be sure, AMD’s so-called second generation of 7nm parts will still be using an enhanced version of 7nm versus the variant used on current Zen 2 and Navi chips, but AMD is being a little more careful as to not imply that it’s going to be EUV-based.
And with that, that’s a wrap on AMD’s 2020 Financial Analyst Day. The company has laid out an aggressive roadmap with regards to both technology and what it means for their financial performance, so now it will be up to Dr. Lisa Su and the rest of AMD to deliver on those lofty goals. Coming off of a remarkable turnaround over the last few years, AMD is in perhaps the best position it’s seen in almost a decade, and if AMD’s efforts can match their aspirations, then the next five years will undoubtedly launch them into a bigger and better place.








51 Comments
View All Comments
Modatu - Friday, March 6, 2020 - link
This is all good to hear, but what about the software ecosystem? At the moment CUDA is king in the GPGPU space, how do they want to address this?On the CPU side there are several HPC applications that are heavily tuned to the Intel compiler stack, what is their angle on this front?
Granted I am looking at this from a pretty niche scientific computing / HPC side.
Gc - Friday, March 6, 2020 - link
AMD's latest on HPC software might have been at SC19. It looks like much of the work on HPC applications was done by developer communities of those applications. I'd guess that AMD's emphasis is on the critical hardware-specific portions (compilers, drivers, OS-level management tools, etc.). AMD might have supported some proof-of-concept ports for testing their compilers, but doesn't have the application expertise to maintain ports of applications and libraries. I guess this means AMD (or AMD's customers, such as HPE/Cray) need good HPC developer relations engineers.> AMD Introduces ROCm 3.0
>
> Community support for the pre-exascale software ecosystem continues to grow. This ecosystem
> is built on ROCm, the foundational open source components for GPU compute provided by AMD.
> The ROCm development cycle features monthly releases offering developers a regular cadence
> of continuous improvements and updates to compilers, libraries, profilers, debuggers and system
> management tools. Major development milestones featured at SC19 include:
>
> + Introduction of ROCm 3.0 with new innovations to support HIP-clang – a compiler built upon
> LLVM, improved CUDA conversion capability with hipify-clang, library optimizations for both HPC
> and ML.
>
> + ROCm upstream integration into leading TensorFlow and PyTorch machine learning
> frameworks for applications like reinforcement learning, autonomous driving, and image and
> video detection.
>
> + Expanded acceleration support for HPC programing models and applications like OpenMP
> programing, LAMMPS, and NAMD.
>
> + New support for system and workload deployment tools like Kubernetes, Singularity, SLURM,
> TAU and others.
Yojimbo - Friday, March 6, 2020 - link
Supercomputing uses mostly large, legacy code bases that are parallelized with compiler directives. So just building good hardware is enough, along with tens or a hundred million dollars worth of effort, done by AMD and the national labs over the course of 2 or 3 years, to optimize the compilers for AMDs hardwareThe majority of the burgeoning market for GPU compute relies on CUDA. NVIDIA isn't spending hundreds of millions of dollars a year, maybe even a billion dollars a year now, on their software ecosystem, directly targeting various verticals through efforts including libraries, integration into storage, databases, and the cloud, just because they can. Improved CUDA conversion will cut it for a national lab that doesn't care much for the small fraction of the code dependent on native CUDA, but it will perform significantly worse than native code and thus make their hardware uncompetitive in most of the commercial market.
Modatu - Friday, March 6, 2020 - link
Yeah unfortunately, this does not sound too good.I mean we are talking about two 600 pound gorillas who pushed their respective software stacks deep into the market.
I hope they succeed in a way that makes them a real contender (from the software side).
realbabilu - Friday, March 6, 2020 - link
Don't know about Cuda opencl counter. They tuned clang and flang to AOCC amd optimized compiler to face Intel compiler in Linux only. They packing also blis,fftw,libflame,scalapack into AOCL and optimized library versus Intel MKL.My last fortran polyhedron bench, AOCC + Openblas is slightly better on matrix inverse than AOCC+ AOCL, GCC + Openblas. But the speed compiled AOCC + openblas on desktop ryzen 3600X still slightly under intel.compiler + Intel.mkl result on notebook i7-9750H.
The znver2 tune increase the speed like Qax Intel did. Still I hope amd had better software development like Intel has for all.platform including windows.
R3MF - Friday, March 6, 2020 - link
any news on desktop Renoir?del42sa - Friday, March 6, 2020 - link
nosenttoschool - Friday, March 6, 2020 - link
The biggest consumer announcement seems to be that RDNA2 has 50% higher performance per watt while staying on the same node.I don’t expect it to beat Ampere but it gives it a fighting chance.
adriaaaaan - Friday, March 6, 2020 - link
My only concern with next gen amd is support for dlss, nvidia has taken the technology from a gimmicky feature to something with incredible promise, particularly now that ray tracing is the new standard.eva02langley - Friday, March 6, 2020 - link
You understand that this is bad upscalling? Play your games at lower resolution and have better visual fidelity, no needs to purchase tensor cores for that.