AMD's RDNA 2 Gets A Codename: “Navi 2X” Comes This Year With 50% Improved Perf-Per-Watt
by Ryan Smith on March 5, 2020 5:45 PM EST
While AMD’s Financial Analyst Day is first and foremost focused on the company’s financial performance – it’s right there in the title – this doesn’t stop the company from dropping a nugget or two of technical information along the way, to help excite investors on the future of the company.
One such nugget this year involves AMD’s forthcoming RDNA 2 family of client GPUs. The successor to the current RDNA (1) “Navi” family, RDNA 2 has been on AMD’s roadmap since last year. And it’s been previously revealed that, among other things, it will be the GPU architecture used in Microsoft’s forthcoming Xbox Series X gaming console. And while we’re still some time off from a full architecture reveal from AMD, the company is offering just a few more details on the architecture.
First and foremost, RDNA 2 is when AMD will fill out the rest of its consumer product stack, with their eye firmly on (finally) addressing the high-end, extreme performance segment of the market. The extreme high end of the market is small in volume, but it’s impossible to overstate how important it is to be seen there – to be seen as competing with the best of the best from other GPU vendors. While AMD isn’t talking about specific SKUs or performance metrics at this time, RDNA 2 will include GPUs that address this portion of the market, with AMD aiming for the performance necessary to deliver “uncompromising” 4K gaming.

But don’t call it "Big Navi". RDNA 2 isn’t just a series of bigger-than-RDNA (1) chips. The GPUs, which will be the codename “Navi 2X” family, also incorporate new graphics features that set them apart from earlier products. AMD isn’t being exhaustive here – and indeed they’re largely already confirming what we know from the Xbox Series X announcement – but hardware ray tracing as well as variable rate shading are on tap for RDNA 2. This stands to be important for AMD at multiple levels, not the least of which is closing the current feature gap with arch-rival NVIDIA.
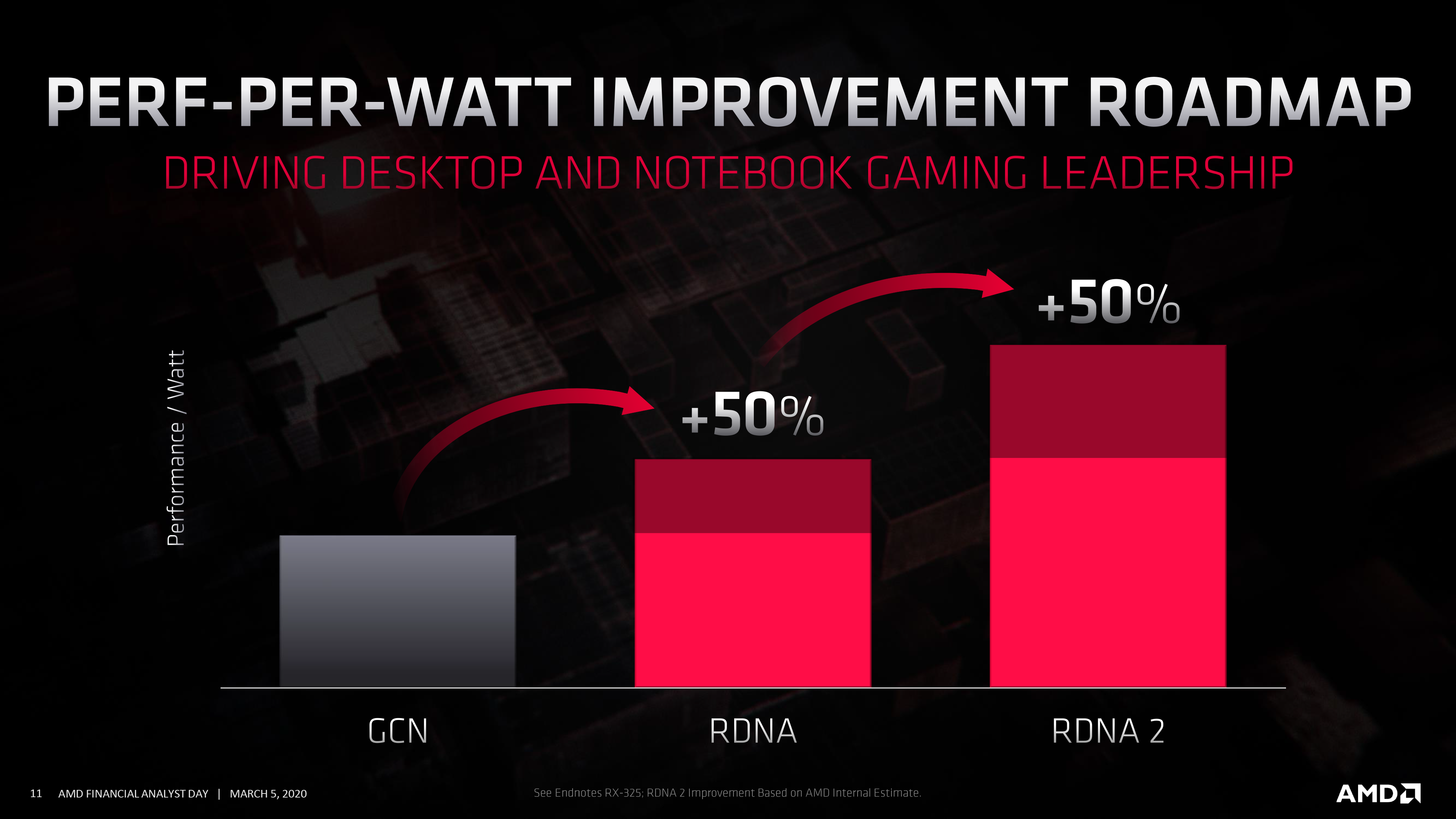
And AMD didn’t stop there, either. Even to my own surprise, AMD isn’t just doing RDNA (1) with more features; RDNA 2 will also deliver on perf-per-watt improvements. All told, AMD is aiming for a 50% increase in perf-per-watt over RDNA (1), which is on par with the improvements that RDNA (1) delivered last year. Again speaking at a high level, these efficiency improvements will come from several areas, including microarchitectural enhancements (AMD even lists improved IPC here), as well as optimizations to physical routing and unspecified logic enhancements to “reduce complexity and switching power.”
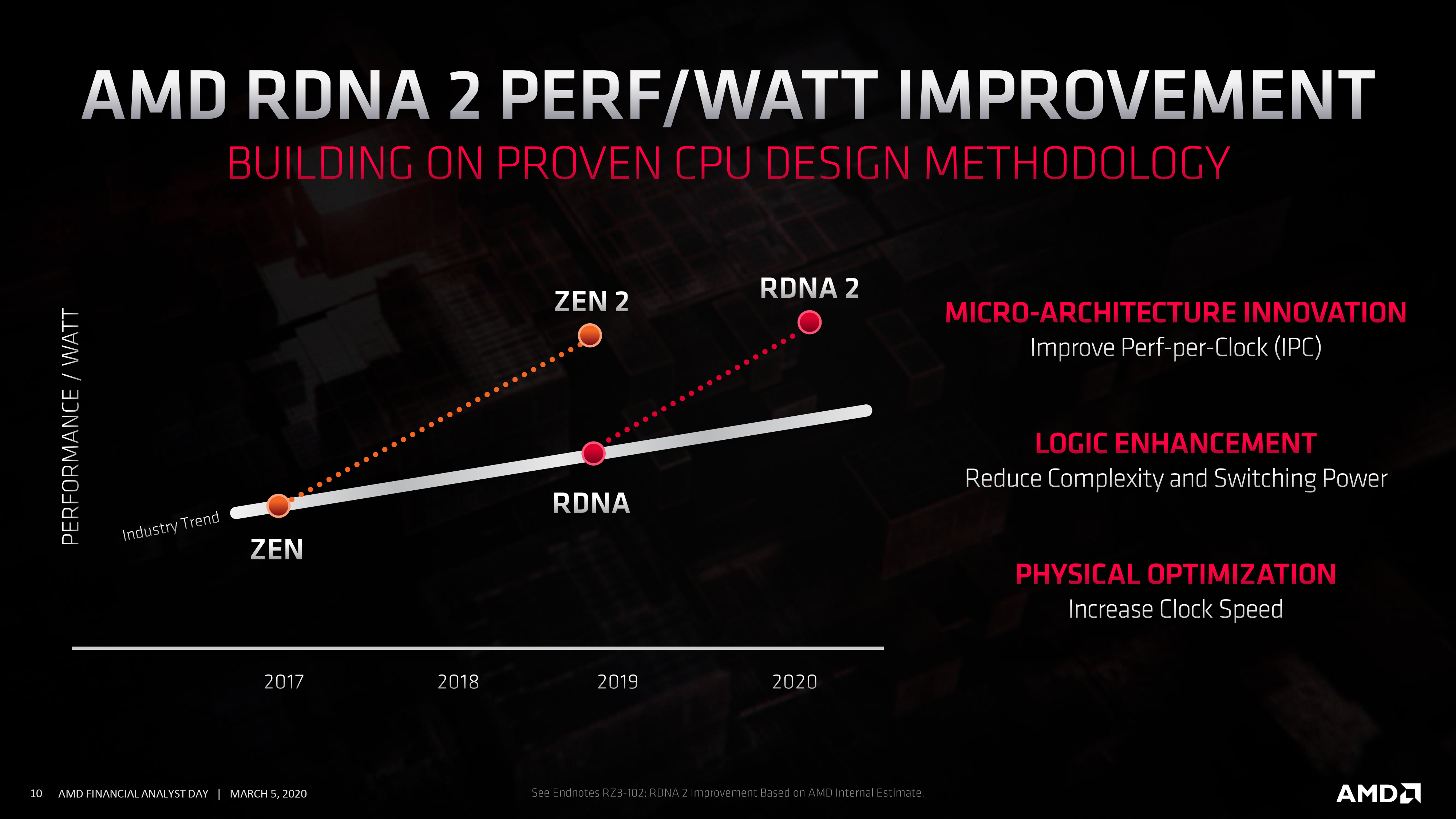
Process nodes will also play some kind of a role here. While AMD is still going to be on a 7nm process here – and they are distancing themselves from saying that they'll be using TSMC’s EUV-based “N7+” node – the company has clarified that they will be using an enhanced version of 7nm. To what extent those enhancements are we aren’t sure (possibly using TSMC’s N7P?), but AMD won’t be standing still on process tech.
This strong focus on perf-per-watt, in turn, will be a key component of how AMD can launch itself back into being a fully viable, top-to-bottom competitor with NVIDIA. While AMD is already generally at parity with NVIDIA here, part of that advantage comes from an atypical advantage in manufacturing nodes that AMD can’t rely on keeping. NVIDIA isn’t standing still for 2020, and neither can AMD. Improving power efficiency for RDNA 2 (and beyond) will be essential for convincingly beating NVIDIA.

Overall, AMD has significant ambitions with RDNA 2, and it shows. The architecture will be the cornerstone of a generation of consoles, and it will be AMD’s first real shot in the last few years at taking back the flagship video card performance crown. So we’re eagerly awaiting to see what else RDNA 2 will bring to the table, and when this year the first video cards based on the new architecture will begin shipping.








46 Comments
View All Comments
mode_13h - Sunday, March 8, 2020 - link
AMD also provides staff members to assist major game developers, but that's not all. They also provide full source code to their accelerated libraries. See: https://gpuopen.com/games-cgi/I believe both Nvidia and AMD also provide some form of financial support for major game titles, in exchange for optimizations targeting their respective hardware, though I don't know the specifics.
SydneyBlue120d - Friday, March 6, 2020 - link
Any updates on the Samsung mobile project?BenSkywalker - Friday, March 6, 2020 - link
"Poor Volta"That was three years ago, and AMD still hasn't released anything that comes close to backing that up. I'm all for advancement no matter which company is doing it, but let's say AMD's GPU claims have earned them a wait until we see it status at best.
In realistic terms their existing parts are capable of excellent efficiency, they simply clock them out of their sweet spot chasing nVidia. When these parts hit, if performance isn't lining up the way they wanted I fully expect they will push the clocks and kill the efficiency once more.
CiccioB - Friday, March 6, 2020 - link
That's completely wrong.
Power efficiency is measured as the work done / energy used.
If you clock your big beast at a low clock you get fantastic efficiency, but that is useless if you then have the performance of the smallest chip made by the competitors that consumes as much but costs 1/10th.
The first AMD's problem since the introduction of GCN has been power efficiency, which goes together to computing efficiency (work done / transistor needed).
Both these indexes were extremely low for AMD (with respect to the competition) and this has opened a widening gap since RDNA.
To compete in term of performances, AMD has to use bigger and much power hungry chips. To limit the dimension gap between its chips and the competitor's similar performer ones they had to pump up the clocks, worsening the power efficiency (but avoiding to go into negative gain margins).
With Turing Nvidia passed to be the one using the bigger dies, but kept power efficiency crown.
With RDNA AMD increased their computing efficiency, that normalized with respect to the production node used, it is now equal to Pascal. This at a cost, however: they worsened a lot their computation efficiency, by almost doubling the number of transistors while not adding any new feature (but packet math) with respect to Polaris.
A RDNA chip is almost as big as Turing one (in number of transistors) but features Pascal capabilities.
With RDNA2 AMD is now in a different scenery with respect to RDNA vs Turing.
1. The PP, even if using 7Np or 7N+ is not going to give much improvements in terms of density and very limited in terms of power efficiency.
2. A bunch of new features have to be added to close the gap with the competition, from RT HW acceleration, possible AI acceleration (for filtering and new algorithms that could be exploited for new advanced features), VSR and geometry engine improvements (this has been a serious problem for AMD since Terascale, now widened by the implementation of dynamic mesh shading by Nvidia). This is going to cost transistor.
3. To reach the top of the list in performance, AMD needs to add much more computing resources, which means many more transistors.
Now, seen the number of transistors that they are using with RDNA to be at Pascal level, I can't imagine how big (in term of transistor counts) the new GPUs needs to be to be competitive with Nvidia's biggest beasts. And how they can maintain power efficiency, seen they now can't go wide as they did with RDNA.
It's a real tough task what is trying to do AMD.
The good news is that they finally have decided to split their GPUs architectures: one for gaming and one for computing. As it previously was, they were good in neither of the two jobs.
Fataliity - Friday, March 6, 2020 - link
If you clock your big beast at a low clock you get fantastic efficiency, but that is useless if you then have the performance of the smallest chip made by the competitors that consumes as much but costs 1/10th.--Navi's efficiency is around 1500mhz. That's not 1/10th the speed of the competition. A 5700XT at 1500mhz would be around a 2060 super, and consume way less power.
With RDNA2 AMD is now in a different scenery with respect to RDNA vs Turing.
1. The PP, even if using 7Np or 7N+ is not going to give much improvements in terms of density and very limited in terms of power efficiency.
--RDNA is just the Vega die shrink with a new scheduler. So Vega 7nm was 40mT/mm2. RDNA is 40.5mT/mm2. The new scheduler allowed AMD to target Wave 16, 32, and 64. Vega's issue, was games weren't coded for their wave setup, meaning the best programmed games only hit about 60-70% of the use of the cores, while for computation they were amazing. And with a node shrink, RDNA2 will hit 60-80mT/mm2. RDNA2 is a ground-up 7nm design, RDNA is just vega with a new scheduler.
2. A bunch of new features have to be added to close the gap with the competition, from RT HW acceleration, possible AI acceleration (for filtering and new algorithms that could be exploited for new advanced features), VSR and geometry engine improvements (this has been a serious problem for AMD since Terascale, now widened by the implementation of dynamic mesh shading by Nvidia). This is going to cost transistor.
--RDNA2 already has hybrid ray-tracing, with a bvr path to accelerate it, similar to Nvidia. Why does it need AI cores? It's not for computation, it's for gaming. VSR is already implemented if you watched their presentation. Microsoft also has a patented version. Ray-tracing itself takes less than 10% of the transistors of a die. Your very mis-informed.
3. To reach the top of the list in performance, AMD needs to add much more computing resources, which means many more transistors.
--AMD can already reach the top with RDNA, if they made an 80CU die. But its only 7 months until RDNA2 comes out, so making it now, the masks costs wouldn't pay off before the next-gen, and the investment would be negative. RDNA2 will be around for 18months and it will recoup the investment and possibly take the performance crown.
Good thing your not an analyst. You're not very good at analyzing. But your arguments sound good if you don't look into it.
mode_13h - Sunday, March 8, 2020 - link
> RDNA is just the Vega die shrink with a new scheduler.Definitely not. Wave32 is much deeper than "a new scheduler". See my other post for some of NAVI's other changes.
mode_13h - Sunday, March 8, 2020 - link
> Why does it need AI cores? It's not for computation, it's for gaming.Nvidia relies on its Tensor Cores for good denoising performance with Global Illumination. Except, the performance of GI in Raytraced games is still so bad that most don't use it.
mode_13h - Sunday, March 8, 2020 - link
Yeah, you should really judge GPUs' efficiency at their stock specs. And if those specs push a design past its efficiency sweet spot, then too bad, cuz that's how the manufacturer chose to clock it.It's a moot exercise to play the "what if it had been clocked x% lower" game. Perhaps of academic interest, but it's of virtually no consequence if that's not how they actually shipped it.
Spunjji - Friday, March 13, 2020 - link
It's of interest when you're comparing the efficiency of an architecture, rather than the performance/value/etc. of a specific product. That is pretty academic, but then what are we here for if not to be nerdy about these things? :)mode_13h - Sunday, March 8, 2020 - link
> they worsened a lot their computation efficiency, by almost doubling the number of transistors while not adding any new feature (but packet math) with respect to Polaris.It's not accurate to say it added no new features. RDNA added:
* Hardware GCN compatibility
* 2x scalar throughput
* primitive shaders
* PCIe 4.0
* GDDR6
* Image sharpening
* Improved DSBR
I do agree that it would probably do well to drop GCN support. As improvements in area-efficiency tend to provide benefits in energy-efficiency, and we know RDNA 2 will have significant amounts of the latter, I'm also expecting it to feature the former.