Amazon's Arm-based Graviton2 Against AMD and Intel: Comparing Cloud Compute
by Andrei Frumusanu on March 10, 2020 8:30 AM EST- Posted in
- Servers
- CPUs
- Cloud Computing
- Amazon
- AWS
- Neoverse N1
- Graviton2
SPEC - Single Threaded Performance
We have some great expectations for the single-threaded performance of the Graviton2 and the Neoverse N1 CPU. In the mobile space, we’ve already seen the Cortex-A76 showcase some extremely competitive performance when compared to x86 platforms running at server frequencies. In particular, the comparison against the first-generation Graviton SoC and its Cortex-A72 cores should be interesting, so I also went ahead and also included comparison numbers on that platform – these figures should put better context into the massive generational uplift that Arm has achieved.
The performance figures tested here are not on a full vCPU instance of the platforms, but rather on “xlarge” variants with only 4 vCPUs, reason for this was simply we didn’t feel too much like paying 95% more for the computing time while the rest of the cores were sitting idle. This isn’t exactly the most optimal method for testing single-threaded performance though, depending on the platform.
One thing to consider in such a small vCPU instance is that you’re only using a fraction of the hardware platform for yourself, while there’s a possibility that there’s other users on other VMs running on the same platform. Such a setup is called having “noisy neighbours”, essentially meaning you’re co-hosted with other users on the same hardware. I did try to verify the figures by running them a few times, and the numbers were consistent on the Graviton2 and AMD platforms. The Graviton2 is still on preview availability so I don’t expect many users using up Amazon’s current deployments, and the AMD unit seemingly didn’t have issues and looked to remain at 2.9GHz throughout most of the testing. On the Intel Xeon platform however, I did see some larger variations, and I think that was mostly due to noisy neighbours brining down the boost clocks of the system down from its 3.2GHz peak. The published numbers here is the higher result set which should be running at around 3.2GHz.
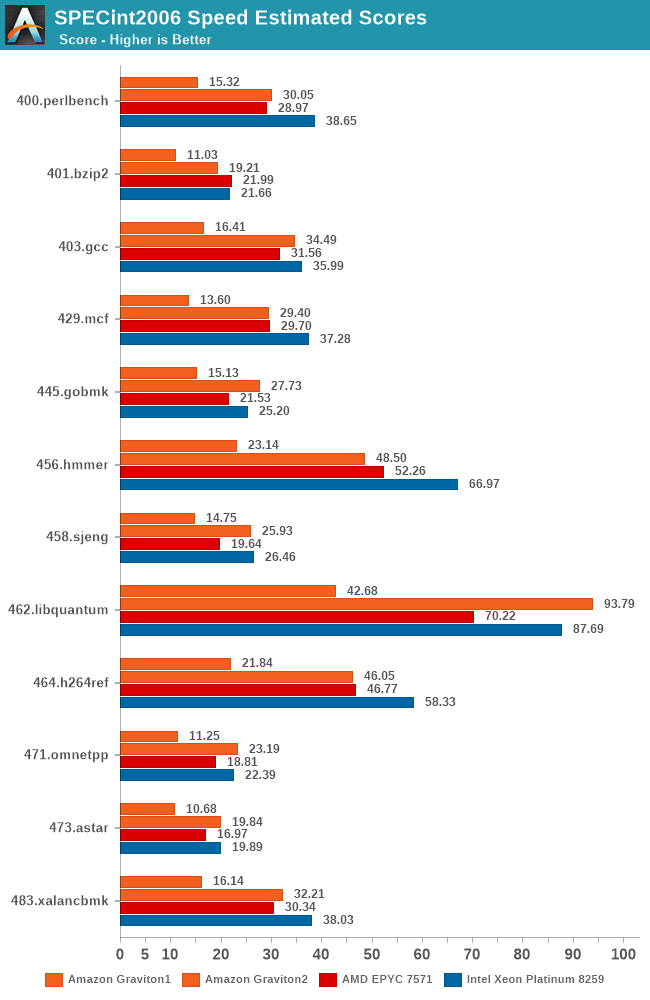
Starting off with SPECint2006, the Graviton2 and N1 CPU are doing extremely well. It’s showcasing almost double the ST performance across the table compared to the A72 based SoC, and it’s even beating the EPYC 7571 across most benchmarks, slightly lagging behind the Xeon instance in some benchmarks.
The Graviton2 is doing particularly well in the memory tests, and latency sensitive tests like 429.mcf are faring significantly better than what we see on the mobile Cortex-A76 SoCs.
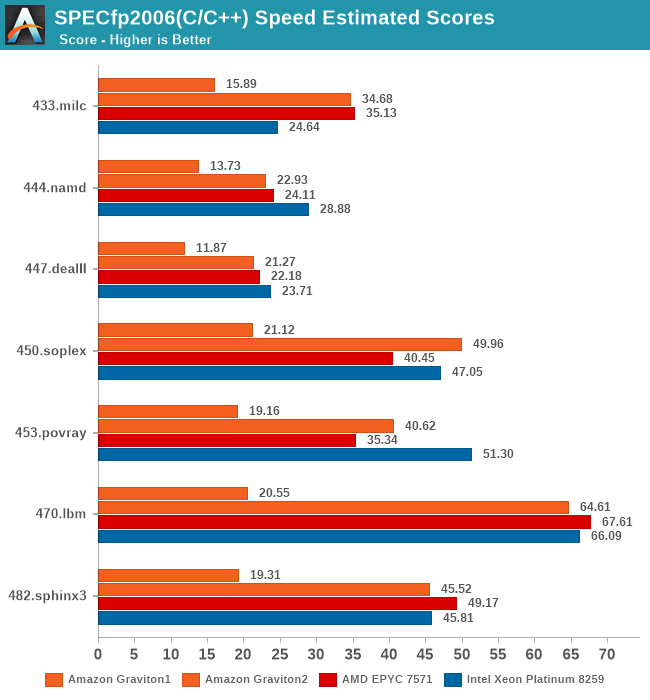
In the C/C++ tests of SPECfp2006 (identical set to what se test on mobile, no Fortran compiler available on those platforms), we see the Graviton2 do even better. The delta to the Cortex-A72 platform is even bigger thanks to the more memory sensitive nature of these tests. Here, the Graviton2 is also a lot closer to the x86 competition, staying neck-in-neck with the AMD and Intel platforms.
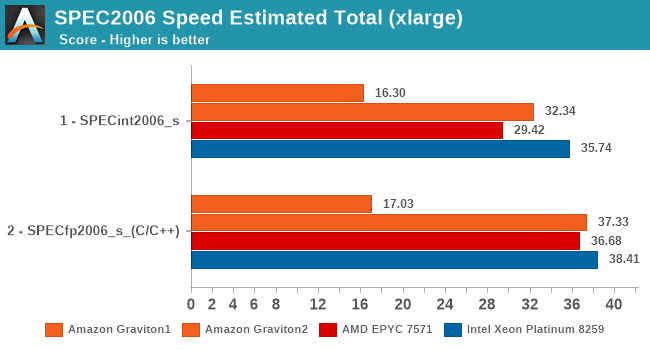
For the aggregate stores in SPEC2006, the performance uplift compared to the first-gen Graviton is 2x in integer workloads, and 2.2x in FP workloads. Intel is slightly ahead in integer ST performance here, but that gap is reduced to a very thin margin on the FP tests. It’s a great showcase of the Neoverse N1’s IPC capabilities, as the cores are only running at 2.5GHz compared to ~2.9GHz for the AMD system and ~3.2GHz for the Intel system.
Compared to a mobile Cortex-A76 such as in the Kirin 990 (which is the best A76 implementation out there), the resulting IPC is 32% better for the Graviton2 in SPECint2006, and 10% better for SPECfp2006. This goes to show what kind of a massive difference the memory subsystem can have on a system that is otherwise similar in terms of the CPU microarchitecture. We must not forget that the N1 here has the whole 32MB L3 cache available all to itself, even when using a smaller two core vCPU instance.
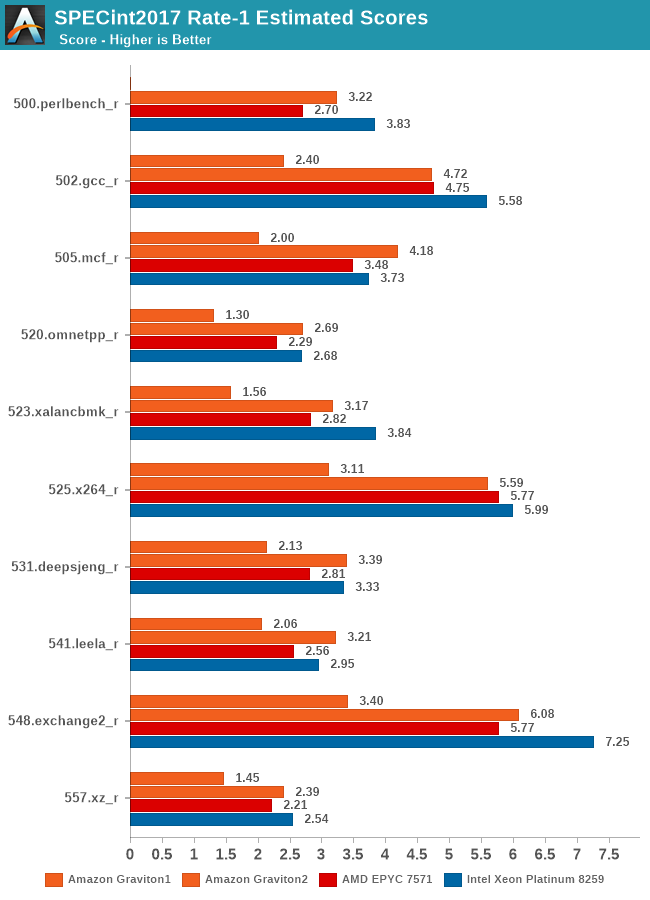
We’re also covering the SPEC2017 results. In general, the new suite slightly changes up the workloads and, in some cases, increases their complexity, but in SPECint2017, there’s also tests which are laxer compared to their 2006 variants, for example 505.mcf is only using half the memory footprint compared to 429.mcf.
Still, the Graviton2 again here is showcasing some extremely good performance across the board, and is largely mimicking the 2006 results.
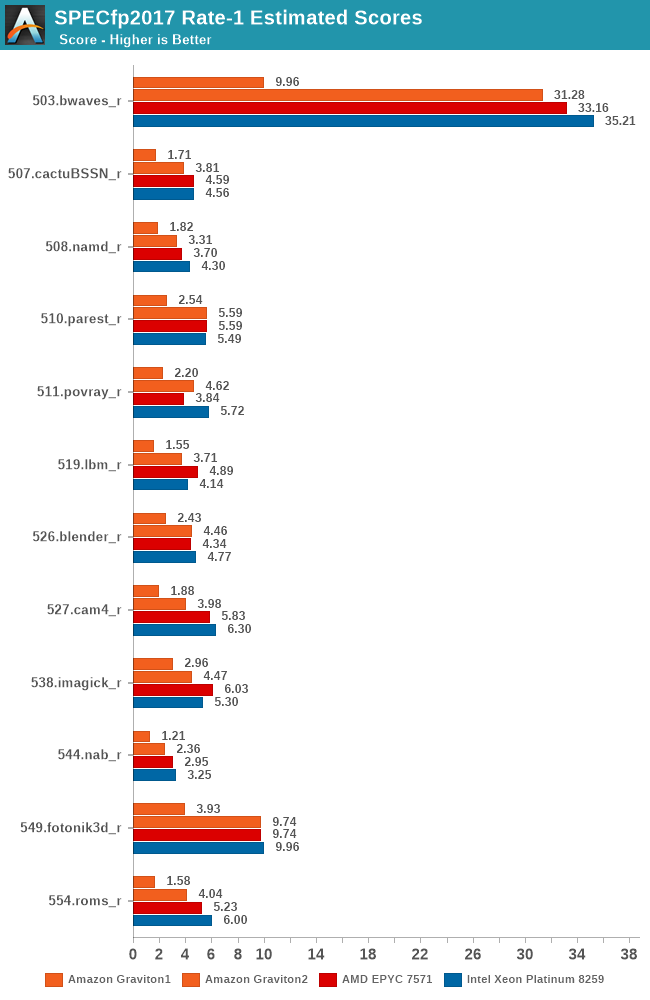
The fp2017 results are definitely a more complex set, but again, the Graviton 2 doesn’t have issues keeping up, although this time around it does more often than not lose out to the x86 parts.
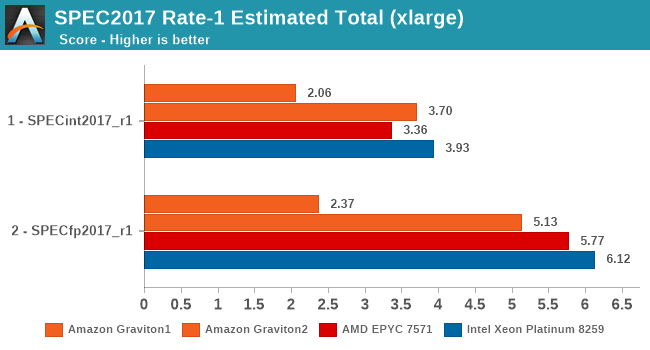
In SPECint2017 the Graviton2 is able to showcase a better relative positioning compared to the 2006 tests, just shy of keeping up with the 3.2GHz Cascade Lake system, however in the fp2017 results it’s faring a bit worse than the 2006 system, showcasing a larger margin where it falls behind the competition.
Again, compared to the A1 based Graviton1 instances, the new chip essentially showcases double the single-thread performance, signifying that Arm is now able to compete amongst the big boys in the courtyard.
The results here are a bit shy of what Arm had projected for the N1 platform last year, but the reason for that is that Amazon was quite conservative in terms of the clock frequencies of the Graviton2, as well as only employing 32MB of L3 cache versus the 64MB that Arm had envisioned for a 64-core part. At least on the frequency side, Ampere’s new Altra system running at 3GHz should see scores 20% higher than the figures presented by the Graviton2.
Lastly, let’s again not forget that this isn’t the whole competitive landscape as we don’t have AMD Rome-based instances available to us at this point of time, I’m pretty sure those figures will be a larger leap ahead of the pack presented here.








96 Comments
View All Comments
anonomouse - Tuesday, March 10, 2020 - link
Will there be more articles on this, covering other workloads than SPEC? You see lots of academic and industry papers talking about how real cloud/hyperscaler/server workloads have deep software stacks with large instruction-side footprints and static branch footprints, whereas SPEC is really... not that. Those workloads tend to have lower IPC on all platforms, and it would be interesting to see how Graviton2 performs on those from the instruction-supply side of things (1 core) as well as how I-side bandwidth scales horizontally with thread counts given the coherent I-Cache.Andrei Frumusanu - Tuesday, March 10, 2020 - link
Concrete suggestions in terms of workloads too look at and can be reasonably deployed are welcome- we currently don't have a well defined test suite for such things.FunBunny2 - Tuesday, March 10, 2020 - link
"Concrete suggestions in terms of workloads"OLTP on RDBMS?? real one, of course, not MySql. :)
Andrei Frumusanu - Tuesday, March 10, 2020 - link
I mean an actual concrete example of such a structured benchmark, me going around doing random DB operations just opens up more criticism on why we didn't use test framework XYZ.FunBunny2 - Tuesday, March 10, 2020 - link
here's one: https://hammerdb.com/ don't know, perhaps likely, that you can get the source and compile for any db/OS of interest. didn't say it was simple. :)Andrei Frumusanu - Wednesday, March 11, 2020 - link
It's just I'm hearing a lot of "we want something specific" without actually specifying anything, me doing some random workload myself that isn't validated in terms of characterisation isn't in my view any better than the well understood nature of SPEC.anonomouse - Wednesday, March 11, 2020 - link
Have you looked at the benchmarks in GCP PerfKitBenchmarker (https://github.com/GoogleCloudPlatform/PerfKitBenc... It includes benchmark versions of various popular benchmarks including variants of ycsb on different databases, oltp, cloudsuite, hadoop, and a bunch of wrapper infrastructure around running the tests on cloud providers.anonomouse - Wednesday, March 11, 2020 - link
Okay so maybe the comment system doesn't have well with links:https://github.com/GoogleCloudPlatform/PerfKitBenc...
http://googlecloudplatform.github.io/PerfKitBenchm...
yeeeeman - Tuesday, March 10, 2020 - link
Ok, now imagine this chip with apple custom cores. Even Zen wouldn't stand a chance.HStewart - Tuesday, March 10, 2020 - link
You can't truly say that. Keep in mind both Apple and Amazon are aim at there own custom environments - things are like different in real world.