Amazon's Arm-based Graviton2 Against AMD and Intel: Comparing Cloud Compute
by Andrei Frumusanu on March 10, 2020 8:30 AM EST- Posted in
- Servers
- CPUs
- Cloud Computing
- Amazon
- AWS
- Neoverse N1
- Graviton2
SPEC - MT Performance (4xlarge 16 vCPU)
The 64-core results were quite interesting and put the Graviton2 in a very competitive performance position, but all this talk about performance scaling varying depending on the loaded core count of the system made me wonder how the EC2 instances would perform at lower vCPU counts.
I fired up the same tests, just this time around with only rate-16 to match the number of vCPUs. These are 4xlarge EC2 instances with corresponding 16 vCPUs, but there’s one large caveat in this comparison that we must keep in mind: The Graviton2 instances very likely have no neighbours at this point in time in the test preview, meaning the performance scaling we’re seeing here is very much a best-case scenario for the Amazon chip. EC2 global capacity floats around at 60% active usage, and I imagine Amazon distributes this horizontally across the available sockets in their datacentres. How these performance figures will look like in the real world once Graviton2 ramps up in public availability is anybody’s guess.
The AMD system likely won’t care too much about such scenarios as their NUMA nature means they’re isolated from noisy neighbours anyhow, and we’re just seeing use of a single 8-core chip with its own memory controllers, but the Intel system will have possibly some neighbours doing some activity on the same socket and shared resources. I only ran one test run here; you’d probably need a lot of data to get a representative figure across EC2 usage.
For the Intel m5n instances, using an 4xlarge instance actually means you're only on on single socket this time around, meaning that the scaling behaviour in favour of higher per-thread performance isn't to be expected as high as on the Graviton2 system, as system DRAM bandwidth and L3 is halved compared to the 16xlarge figures on the previous page.
Also, since we’re testing 16 vCPU setups here, we can have an apples-to-apples comparison between the first- and second-generation Graviton systems which should be a fun comparison.
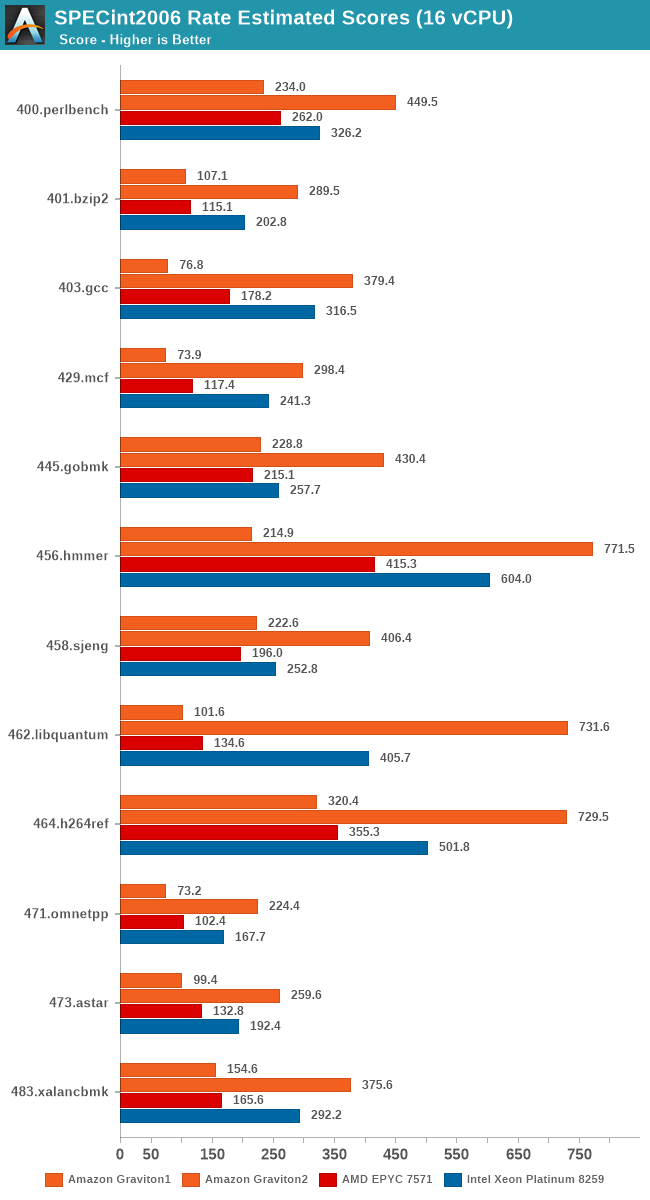
The comparison between the two generations of Graviton processors here is also astounding. Memory intensive workloads favour the newer Graviton2 by at least a factor of 2x, more often 3x, 4x, 5x and even up to 7x in libquantum.
The AMD system as expected doesn’t gain much scaling from using less cores as there’s no more shared resources available on a per-thread basis. The Intel chip fares slightly better per-thread, but doesn’t see the same higher performance scaling (Or should I say, reverse-scaling) as achieved by the Graviton2.
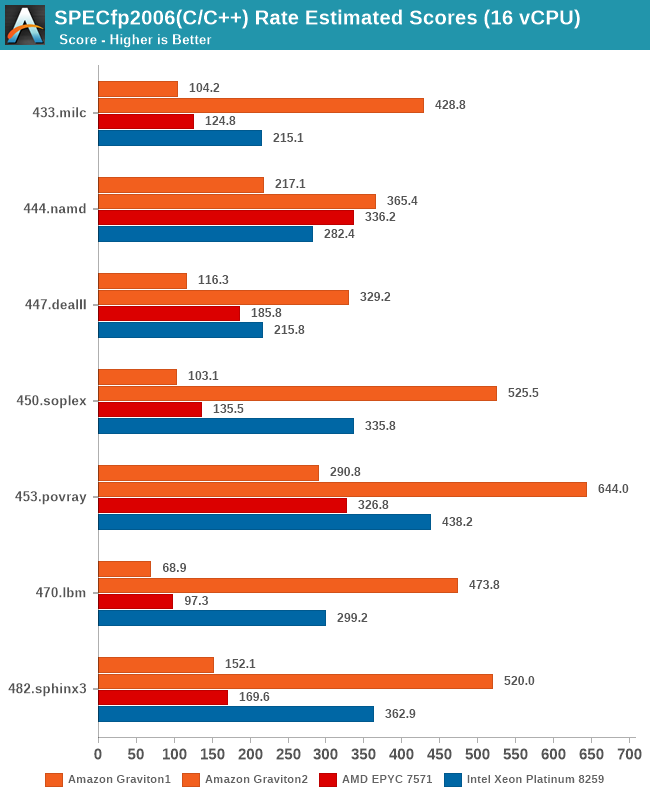
In fp2006, we see more or less the same kind of results.
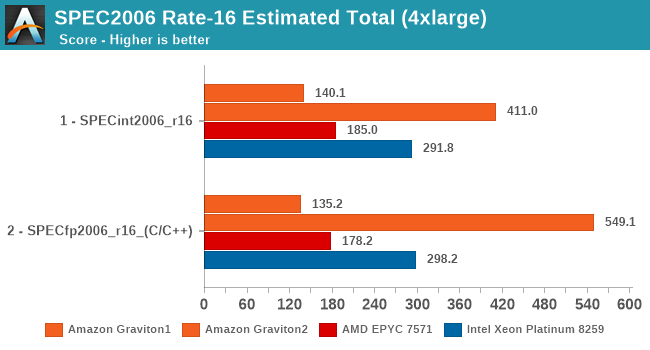
Overall, in the 16-vCPU rate results the Graviton2 surpasses the performance advantage it showcased in the 64-core results, ending up with an even bigger margin.
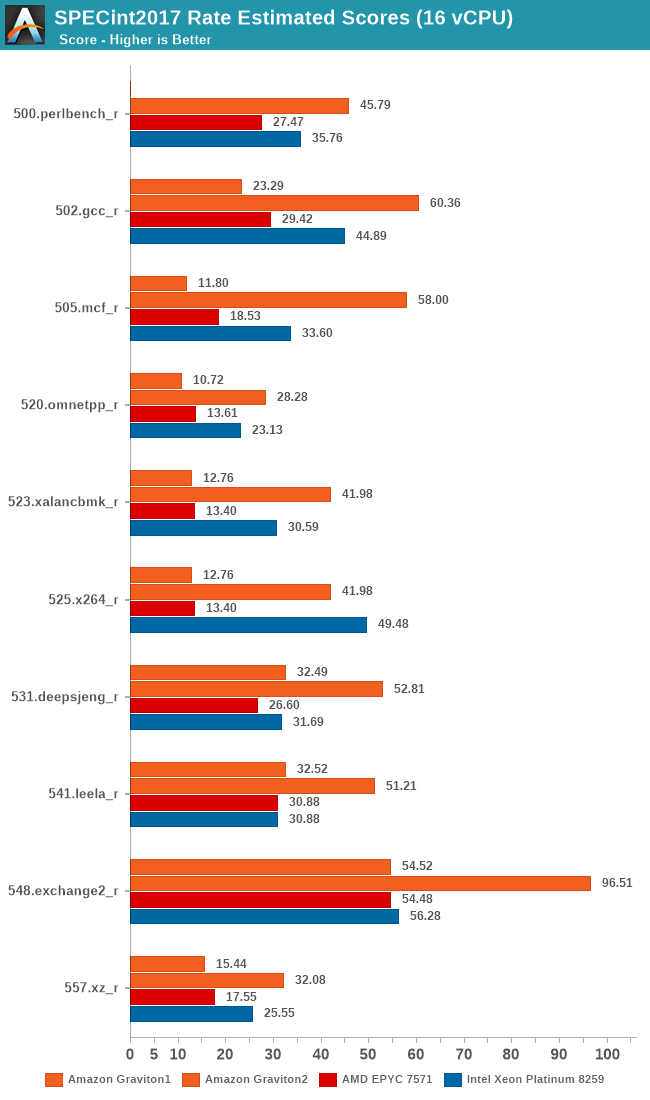
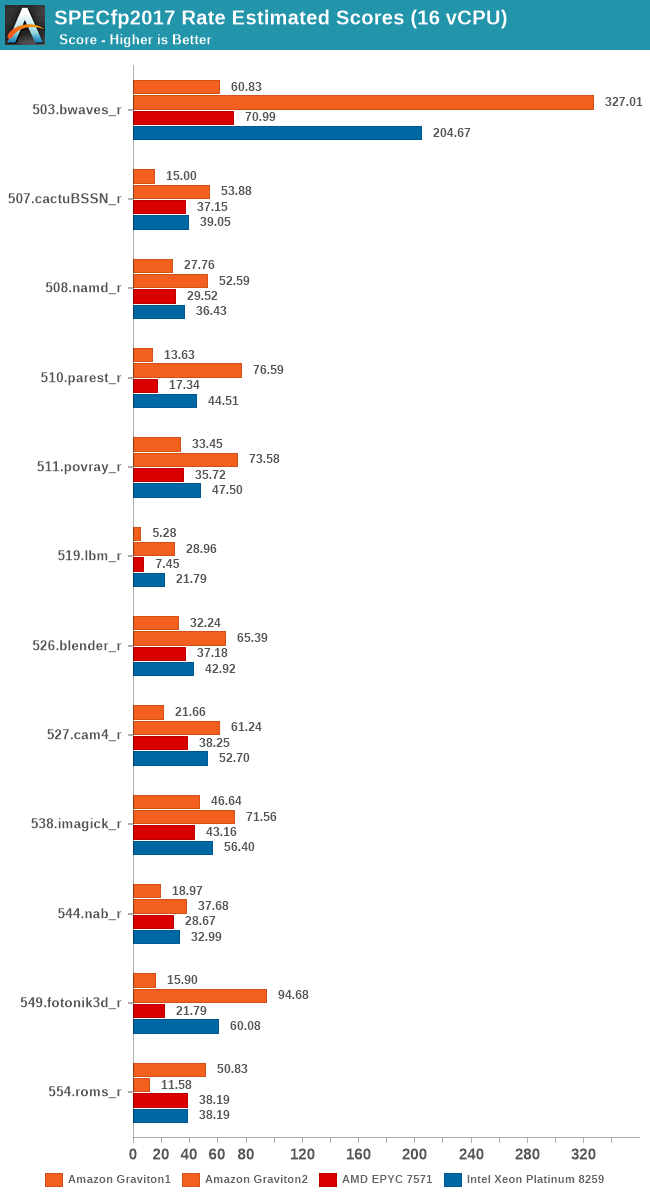
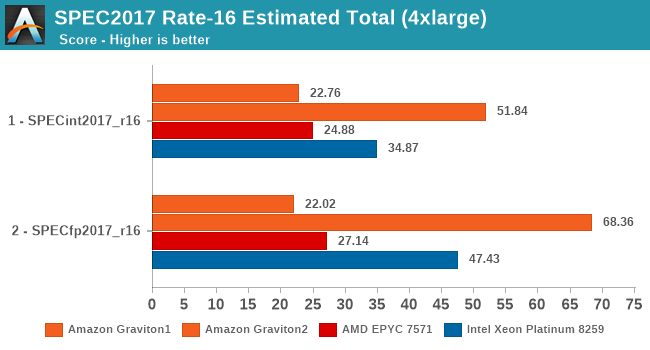
The SPEC2017 results again show the same conclusion – the Graviton2 really gains a ton of per-thread performance through the ability to use more of the chip’s L3 cache and 8 memory channels. Whilst on the 64-rate results the Graviton2 and the Xeon were neck-in-neck in fp2017, here the Graviton ends up with a 44% performance advantage.
Again, I can’t put enough emphasis on this, but these results are a best-case scenario for the 4xlarge 16vCPU results of the Graviton2. If production instances are able to achieve such figures will very largely depend on the draw of luck on whether you’re going to be alone on the physical hardware or whether you’ll have any neighbours on the chip. And even if you have neighbours, the performance figures will largely depend on what kind of workloads they will be running alongside your use-cases.
I saw a few articles out there comparing the performance between the m6g instances against the m5 generation instances (Skylake-SP hardware), but most of these tests were done only on medium (1 vCPU) to xlarge (4 vCPUs). When reading such pieces, it’s naturally important to keep in mind the vast scaling advantage the Graviton2 chip has – the smaller your instance is the more chance you’ll have noisy neighbours on the hardware, something that currently just doesn’t happen in the Graviton2’s preview phase.








96 Comments
View All Comments
Wilco1 - Friday, March 13, 2020 - link
Developing a chip based on a standard Arm core is much cheaper. Arm chip volumes are much higher than Intel and AMD, the costs are spread out over billions of chips.ksec - Tuesday, March 10, 2020 - link
ARM's licensing comparatively speaking is extremely cheap even for their most expensive N1 Core Blueprint. The development and production cost are largely on ARM's because of the platform model. So Amazon is only really paying for the cost to Fab with TSMC, I would be surprised if those chip cost more than $300. Which is at least a few thousand less than Intel or even AMD.Amazon will have to paid for all the software cost though. Making sure all their tools, and software runs on ARM. That is very expensive in engineering cost, but paid off in long term.
extide - Friday, March 13, 2020 - link
Actual production cost is going to be more like $50 or so. WAY less than $300.ksec - Monday, March 30, 2020 - link
Only the Wafer Cost alone would be $50+ assuming 100% yield. That is excluding licensing and additional R&D. At their volume I would not be surprised it stack up to $300FunBunny2 - Tuesday, March 10, 2020 - link
"Vertical integration is powerful."I find it amusing that compute folks are reinventing the wheel from Henry Ford!! River Rouge.
mrvco - Tuesday, March 10, 2020 - link
It would be interesting to see how the AWS instances compare to performance-competitive Azure instances on a value basis.kliend - Tuesday, March 10, 2020 - link
Anecdotally, Yes. Amazon is always trying to bring in users for little/no immediate profit.skaurus - Tuesday, March 10, 2020 - link
At scale, predictability is more important in infrastructure than cost. It may seem that if we have everything we need compiled for Arm, we can just switch over. But these things often look easier in theory than practice. I'd be wary to move existing service to Arm instances, or even starting a new one when I just want to iterate fast and just be sure that underlying level doesn't have any new surprises.It will be fine If I have time to experiment, or later, when the dust settles. Right now, I doubt that switching over to these instances once they are available, is actually easy or even smart decision.
FunBunny2 - Tuesday, March 10, 2020 - link
"It may seem that if we have everything we need compiled for Arm, we can just switch over. But these things often look easier in theory than practice. "with language compliant compilers, I don't buy that argument. it can certainly be true that RISC-ier processors yield larger binaries and slower performance, but real application failure has to be due to OS mismatches. C is the universal assembler.
mm0zct - Wednesday, March 11, 2020 - link
Beware that in C struct packing is ABI dependent, if you write out a struct to disk on x86_64, and try and read it back in on Aarch64, you might have a bad time unless you use the packed pragma and use specified-width types. This is the sort of thing that might get you if you try to migrate between architectures.Also many languages (including C) have hand optimised math libraries with inline assembler, which might still be using plain-C fallbacks on other architectures. There was a good article discussing the migration to Aarch64 at Cloudflare, they particulary encountered issues with go not being optimised on Aarch64 yet https://blog.cloudflare.com/arm-takes-wing/