Amazon's Arm-based Graviton2 Against AMD and Intel: Comparing Cloud Compute
by Andrei Frumusanu on March 10, 2020 8:30 AM EST- Posted in
- Servers
- CPUs
- Cloud Computing
- Amazon
- AWS
- Neoverse N1
- Graviton2
SPEC - Single Threaded Performance
We have some great expectations for the single-threaded performance of the Graviton2 and the Neoverse N1 CPU. In the mobile space, we’ve already seen the Cortex-A76 showcase some extremely competitive performance when compared to x86 platforms running at server frequencies. In particular, the comparison against the first-generation Graviton SoC and its Cortex-A72 cores should be interesting, so I also went ahead and also included comparison numbers on that platform – these figures should put better context into the massive generational uplift that Arm has achieved.
The performance figures tested here are not on a full vCPU instance of the platforms, but rather on “xlarge” variants with only 4 vCPUs, reason for this was simply we didn’t feel too much like paying 95% more for the computing time while the rest of the cores were sitting idle. This isn’t exactly the most optimal method for testing single-threaded performance though, depending on the platform.
One thing to consider in such a small vCPU instance is that you’re only using a fraction of the hardware platform for yourself, while there’s a possibility that there’s other users on other VMs running on the same platform. Such a setup is called having “noisy neighbours”, essentially meaning you’re co-hosted with other users on the same hardware. I did try to verify the figures by running them a few times, and the numbers were consistent on the Graviton2 and AMD platforms. The Graviton2 is still on preview availability so I don’t expect many users using up Amazon’s current deployments, and the AMD unit seemingly didn’t have issues and looked to remain at 2.9GHz throughout most of the testing. On the Intel Xeon platform however, I did see some larger variations, and I think that was mostly due to noisy neighbours brining down the boost clocks of the system down from its 3.2GHz peak. The published numbers here is the higher result set which should be running at around 3.2GHz.
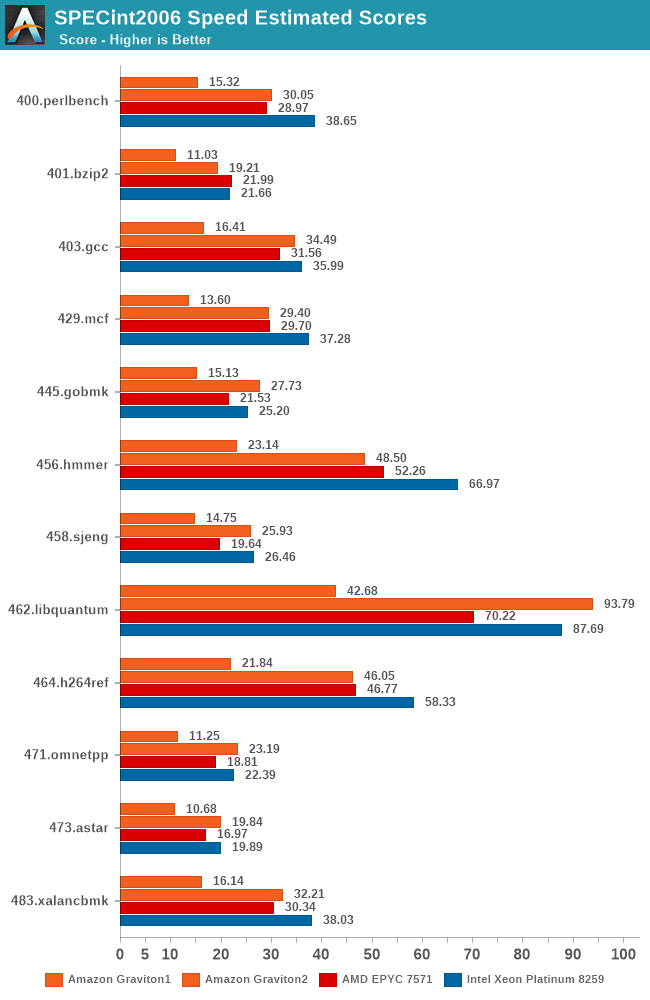
Starting off with SPECint2006, the Graviton2 and N1 CPU are doing extremely well. It’s showcasing almost double the ST performance across the table compared to the A72 based SoC, and it’s even beating the EPYC 7571 across most benchmarks, slightly lagging behind the Xeon instance in some benchmarks.
The Graviton2 is doing particularly well in the memory tests, and latency sensitive tests like 429.mcf are faring significantly better than what we see on the mobile Cortex-A76 SoCs.
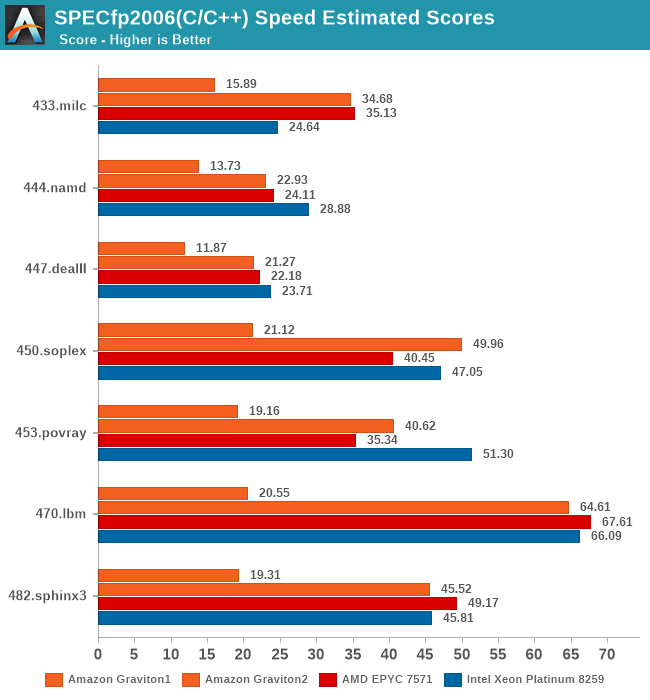
In the C/C++ tests of SPECfp2006 (identical set to what se test on mobile, no Fortran compiler available on those platforms), we see the Graviton2 do even better. The delta to the Cortex-A72 platform is even bigger thanks to the more memory sensitive nature of these tests. Here, the Graviton2 is also a lot closer to the x86 competition, staying neck-in-neck with the AMD and Intel platforms.
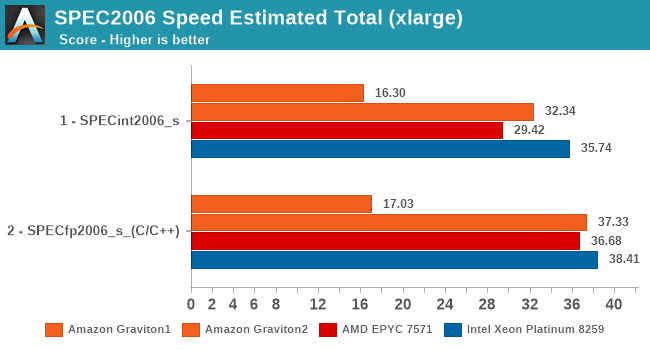
For the aggregate stores in SPEC2006, the performance uplift compared to the first-gen Graviton is 2x in integer workloads, and 2.2x in FP workloads. Intel is slightly ahead in integer ST performance here, but that gap is reduced to a very thin margin on the FP tests. It’s a great showcase of the Neoverse N1’s IPC capabilities, as the cores are only running at 2.5GHz compared to ~2.9GHz for the AMD system and ~3.2GHz for the Intel system.
Compared to a mobile Cortex-A76 such as in the Kirin 990 (which is the best A76 implementation out there), the resulting IPC is 32% better for the Graviton2 in SPECint2006, and 10% better for SPECfp2006. This goes to show what kind of a massive difference the memory subsystem can have on a system that is otherwise similar in terms of the CPU microarchitecture. We must not forget that the N1 here has the whole 32MB L3 cache available all to itself, even when using a smaller two core vCPU instance.
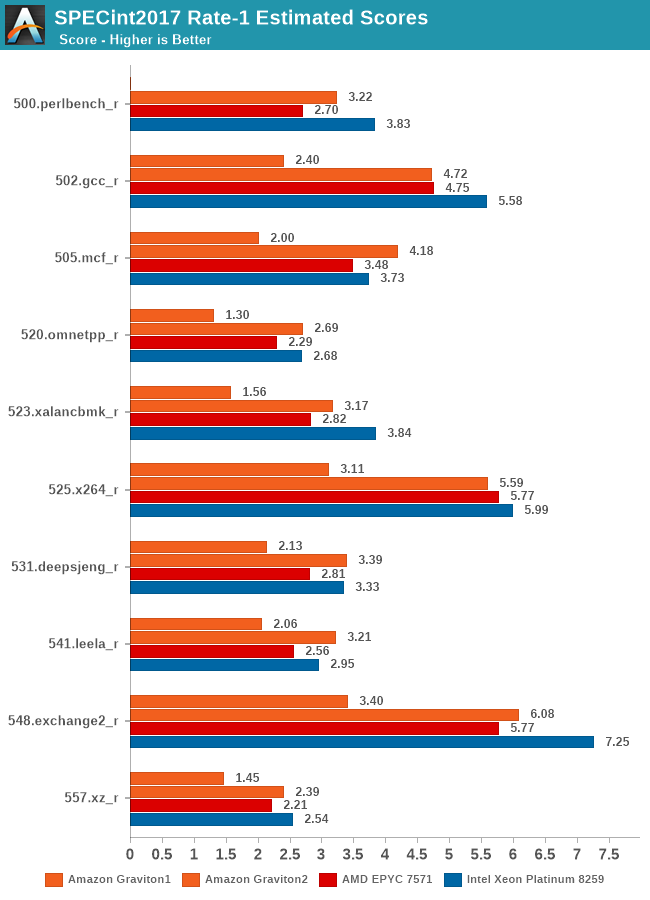
We’re also covering the SPEC2017 results. In general, the new suite slightly changes up the workloads and, in some cases, increases their complexity, but in SPECint2017, there’s also tests which are laxer compared to their 2006 variants, for example 505.mcf is only using half the memory footprint compared to 429.mcf.
Still, the Graviton2 again here is showcasing some extremely good performance across the board, and is largely mimicking the 2006 results.
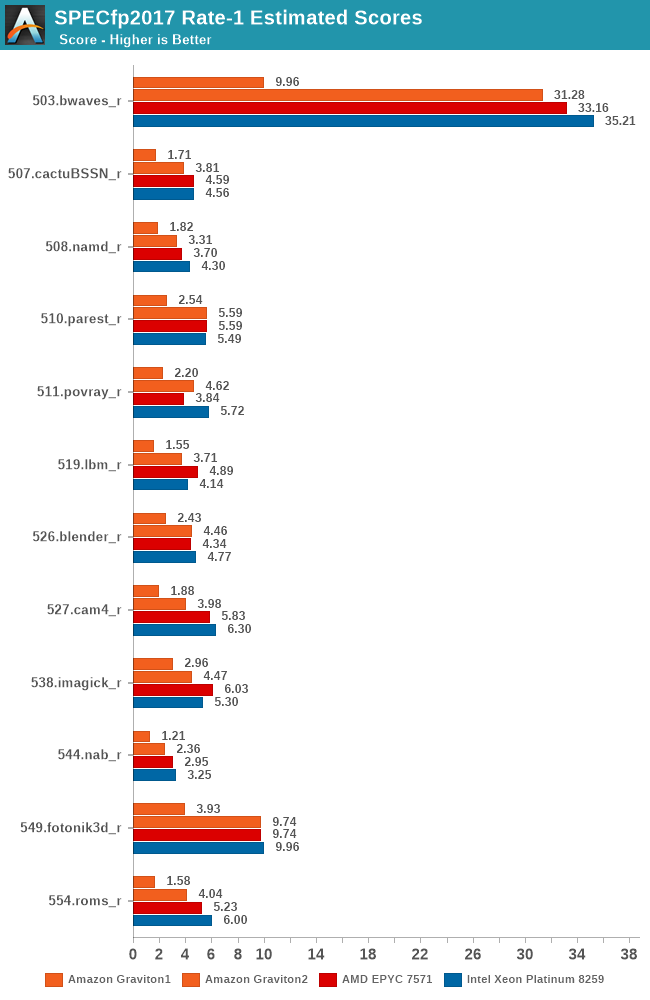
The fp2017 results are definitely a more complex set, but again, the Graviton 2 doesn’t have issues keeping up, although this time around it does more often than not lose out to the x86 parts.
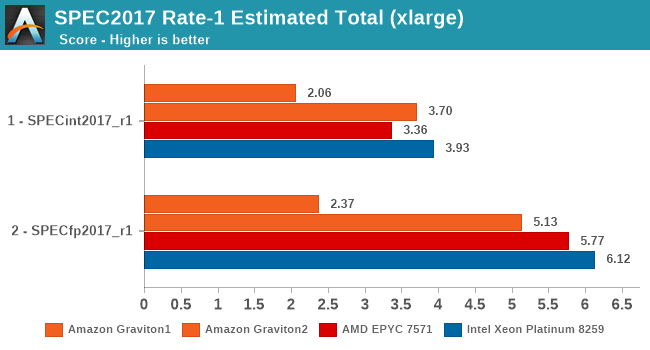
In SPECint2017 the Graviton2 is able to showcase a better relative positioning compared to the 2006 tests, just shy of keeping up with the 3.2GHz Cascade Lake system, however in the fp2017 results it’s faring a bit worse than the 2006 system, showcasing a larger margin where it falls behind the competition.
Again, compared to the A1 based Graviton1 instances, the new chip essentially showcases double the single-thread performance, signifying that Arm is now able to compete amongst the big boys in the courtyard.
The results here are a bit shy of what Arm had projected for the N1 platform last year, but the reason for that is that Amazon was quite conservative in terms of the clock frequencies of the Graviton2, as well as only employing 32MB of L3 cache versus the 64MB that Arm had envisioned for a 64-core part. At least on the frequency side, Ampere’s new Altra system running at 3GHz should see scores 20% higher than the figures presented by the Graviton2.
Lastly, let’s again not forget that this isn’t the whole competitive landscape as we don’t have AMD Rome-based instances available to us at this point of time, I’m pretty sure those figures will be a larger leap ahead of the pack presented here.








96 Comments
View All Comments
Wilco1 - Friday, March 13, 2020 - link
Developing a chip based on a standard Arm core is much cheaper. Arm chip volumes are much higher than Intel and AMD, the costs are spread out over billions of chips.ksec - Tuesday, March 10, 2020 - link
ARM's licensing comparatively speaking is extremely cheap even for their most expensive N1 Core Blueprint. The development and production cost are largely on ARM's because of the platform model. So Amazon is only really paying for the cost to Fab with TSMC, I would be surprised if those chip cost more than $300. Which is at least a few thousand less than Intel or even AMD.Amazon will have to paid for all the software cost though. Making sure all their tools, and software runs on ARM. That is very expensive in engineering cost, but paid off in long term.
extide - Friday, March 13, 2020 - link
Actual production cost is going to be more like $50 or so. WAY less than $300.ksec - Monday, March 30, 2020 - link
Only the Wafer Cost alone would be $50+ assuming 100% yield. That is excluding licensing and additional R&D. At their volume I would not be surprised it stack up to $300FunBunny2 - Tuesday, March 10, 2020 - link
"Vertical integration is powerful."I find it amusing that compute folks are reinventing the wheel from Henry Ford!! River Rouge.
mrvco - Tuesday, March 10, 2020 - link
It would be interesting to see how the AWS instances compare to performance-competitive Azure instances on a value basis.kliend - Tuesday, March 10, 2020 - link
Anecdotally, Yes. Amazon is always trying to bring in users for little/no immediate profit.skaurus - Tuesday, March 10, 2020 - link
At scale, predictability is more important in infrastructure than cost. It may seem that if we have everything we need compiled for Arm, we can just switch over. But these things often look easier in theory than practice. I'd be wary to move existing service to Arm instances, or even starting a new one when I just want to iterate fast and just be sure that underlying level doesn't have any new surprises.It will be fine If I have time to experiment, or later, when the dust settles. Right now, I doubt that switching over to these instances once they are available, is actually easy or even smart decision.
FunBunny2 - Tuesday, March 10, 2020 - link
"It may seem that if we have everything we need compiled for Arm, we can just switch over. But these things often look easier in theory than practice. "with language compliant compilers, I don't buy that argument. it can certainly be true that RISC-ier processors yield larger binaries and slower performance, but real application failure has to be due to OS mismatches. C is the universal assembler.
mm0zct - Wednesday, March 11, 2020 - link
Beware that in C struct packing is ABI dependent, if you write out a struct to disk on x86_64, and try and read it back in on Aarch64, you might have a bad time unless you use the packed pragma and use specified-width types. This is the sort of thing that might get you if you try to migrate between architectures.Also many languages (including C) have hand optimised math libraries with inline assembler, which might still be using plain-C fallbacks on other architectures. There was a good article discussing the migration to Aarch64 at Cloudflare, they particulary encountered issues with go not being optimised on Aarch64 yet https://blog.cloudflare.com/arm-takes-wing/