Amazon's Arm-based Graviton2 Against AMD and Intel: Comparing Cloud Compute
by Andrei Frumusanu on March 10, 2020 8:30 AM EST- Posted in
- Servers
- CPUs
- Cloud Computing
- Amazon
- AWS
- Neoverse N1
- Graviton2
Compiler Setup, GCC vs LLVM
For further performance testing of the systems, we fell back to SPEC2006 and 2017. I wanted to make sure that there’s no heated discussions when it comes to the compilation of the test suites, so carefully investigated the compilers out there, particularly regarding the choice between GCC and LLVM.
Overall, I checked three different compiler setups: A freshly compiled GCC 9.2.0 release, Arm’s Allinea Studio Compiler 20 package which comes with both Arm’s closed source LLVM and Flang variants as well as a pre-compiled version of GCC 9.2.0, and Marvell’s branch of LLVM and Flang.
We had seen quite a push by Arm for us to consider GCC more closely than LLVM, as Arm had admitted that they’ve spent more time upstream optimising GCC than they’ve had for LLVM. Given the much more prevalent use of GCC in cloud and datacentre applications, I did somewhat agree with this given that’s most likely what you’ll see people use in such environments.
I ran some single-threaded tests across the different compiler setups, the compiler flags were straightforward with just a simple -Ofast flag as well as -march/-mcpu=cortex-a76 or =neoverse-n1 (alias) for the Arm compiler setup.
As always, our SPEC results aren't officially submitted results, and thus we have to label them merely as "estimates" for this article. Furthermore, SPEC2006 has been retired in favour of SPEC2017, but I still wanted to put up the figures for historical context, as well as mobile comparisons.
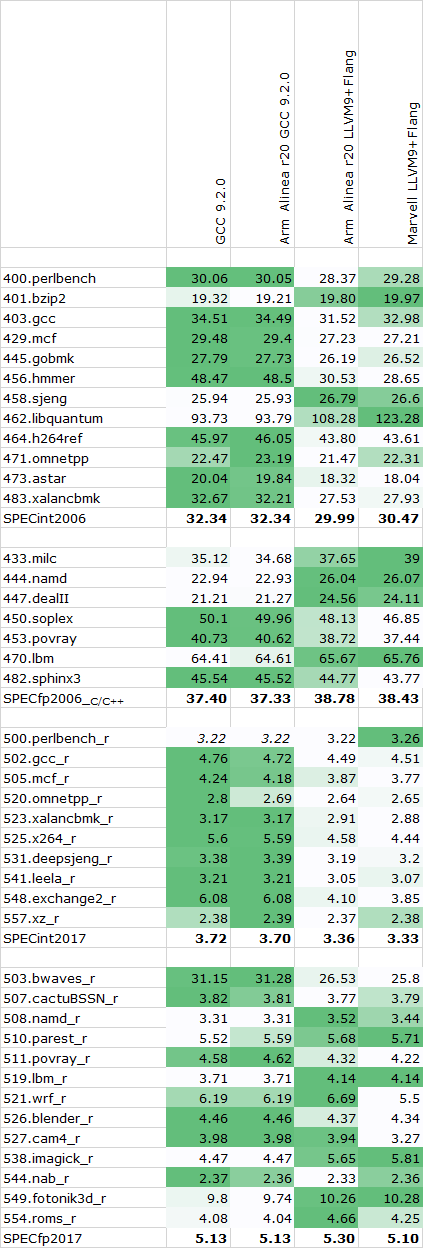
Graviton2 SPEC - Single Threaded - 2.5GHz
The overall results favour GCC in the SPECint workloads, while LLVM seemingly does better in the FP and memory heavy tests. Between the upstream GCC 9.2.0 and Arm’s precompiled version there’s seemingly no performance difference whatsoever, while there is some minor difference between Marvell’s setup and Arm’s branch of LLVM.
I ended up going forward with a clean compile of GCC 9.2.0 both for the Arm as well as x86 systems – meaning we’re using the exact same compiler for both architectures, just with different compile targets.
For x86, we’re again using the simple -Ofast flag for optimisations, and using the corresponding -march/-mtune targets for the EPYC and Intel platforms, meaning zenver1 and skylake-avx512.
Overall, it’s a bit odd to see GCC ahead in that many workloads given that LLVM the is the primary compiler for billions of Arm devices in the mobile space. Arm has said that they’re trying to put more effort into this compiler as seemingly it’s lagging behind GCC in terms of some optimisations.








96 Comments
View All Comments
eek2121 - Tuesday, March 10, 2020 - link
It is worth noting AnandTech’s own numbers: https://www.anandtech.com/show/14694/amd-rome-epyc...RallJ - Tuesday, March 10, 2020 - link
I understand that, but consider everything boils down to just $/vCPU/hr, I think a discussion around the new Xeon Gold R is warranted. For example, the existing dual-socket Xeon Amazon is using can be substituted by the new 6248R for 60% lower price while providing a modest turbo and base frequency improvement at lower a slight TDP reduction versus the existing Platinum they have. Unless Amazon decides to pocket the saving, that would have a massive impact on the vCPU $ comparison.https://www.anandtech.com/show/15542/intel-updates...
Andrei Frumusanu - Tuesday, March 10, 2020 - link
Hyperscalers never pay full list price for their special SKUs, so comparisons to public new SKUs like the 6248R are not relevant.We're happy to update the landscape once EC2 introduces newer generation instances, but for now, these are the current prices and costs for what's available today and in the next few months.
Spunjji - Wednesday, March 11, 2020 - link
I'm confused. Either you can think that everything boils down to $/vCPU/hr, in which case the only thing that's relevant is what Amazon actually offer, or you can think that "a discussion around the 'new' Xeon Gold R is warranted". They're mutually exclusive.close - Tuesday, March 10, 2020 - link
Great write-up Andrei. One question (I hope I didn't miss the answer in the article). Does Amazon's chip come out in front in the cost analysis because Amazon decided to take a loss or overcharge the other options, or is it an organic difference where it's intrinsically better?Andrei Frumusanu - Tuesday, March 10, 2020 - link
We have no idea of Amazon's internal cost structure, so take the cost analysis from and end-user TCO perspective.eek2121 - Tuesday, March 10, 2020 - link
I suspect the TDP of this chip is likely in the 150 watt range. We also know nothing about the operating environment of any of the chips. For example, the chip is rated for DDR4 3200, but is it running at 3200 speeds? The EPYC chip likely is NOT. So many questions here...Andrei Frumusanu - Tuesday, March 10, 2020 - link
It is running 3200, Amazon confirmed that.They didn't comment on TDP, but given Arm and Ampere's figures, I think my estimate is correct.
Flunk - Thursday, April 9, 2020 - link
They're comparing VMs with the same cost/hour. What number of cores/threads is isn't really relevant.autarchprinceps - Sunday, October 25, 2020 - link
That’s exactly why they reserved the entire hardware. If you run only a single workload on SMT, that single thread can use the entire core. That’s kind of the point of SMT.