The Microsoft Surface Laptop 3 Showdown: AMD's Ryzen Picasso vs. Intel's Ice Lake
by Brett Howse & Andrei Frumusanu on December 13, 2019 8:30 AM ESTSection by Andrei Frumusanu
SPEC2017 - ST & MT Performance
Starting off with SPEC, we’re trying to analyze the AMD and Intel systems in direct comparison to each other in a wide variety of workloads. In general, we shouldn’t be expecting too big surprises in the results as earlier this summer we had the opportunity to cover Intel’s Ice Lake CPUs, and the Surface Laptop 3 implementation of the Core i7-1065G7 should pretty much fall in line with those scores.
On AMD’s side, we hadn’t tested the company’s mobile processors in SPEC so this should represent a good opportunity to showcase the two companies’ products side-by-side. As a reminder, the Ryzen 7 3870U tested today is based on AMD’s Picasso chip, a 12nm implementation of the Zen+ microarchitecture, which isn’t quite as up-to-date as the 7nm Zen2 silicon that the company offers in its desktop Ryzen 3000 chips. In a sense, while both products tested today represent the companies’ best mobile products, for Intel it also represents the company’s best technologies, and thus the ICL part has a generational advantage over AMD's current product-line.
We’re limiting our testing this time around to SPEC2017 as it represents the more modern workload characterisations, and we’ve already covered the microarchitectural giveaways presented by SPEC2006 in past articles. We’re testing under WSL1 in Windows due to simplicity of compilation and compatibility, and are compiling the suite under LLVM compilers. The choice of LLVM is related to being able to have similar code generation across architectures and platforms. Our compiler versions and settings are as follows:
clang version 8.0.0-svn350067-1~exp1+0~20181226174230.701~1.gbp6019f2 (trunk) clang version 7.0.1 (ssh://git@github.com/flang-compiler/flang-driver.git 24bd54da5c41af04838bbe7b68f830840d47fc03) -Ofast -fomit-frame-pointer -march=x86-64 -mtune=core-avx2 -mfma -mavx -mavx2
Our compiler flags are straightforward, with basic –Ofast and relevant ISA switches to allow for AVX2 instructions.
Single-Threaded Performance: Intel Dominance
Starting off with single-threaded tests, we’re having a closer look at the integer SPEC20017 suite results.
We’re also adding in AMD and Intel’s top-performing desktop chips into the mix to better convey a context as to where these mobile parts fall in terms of absolute performance, which I think is a major consideration point for the Surface Laptop 3, particularly the Ice Lake models.
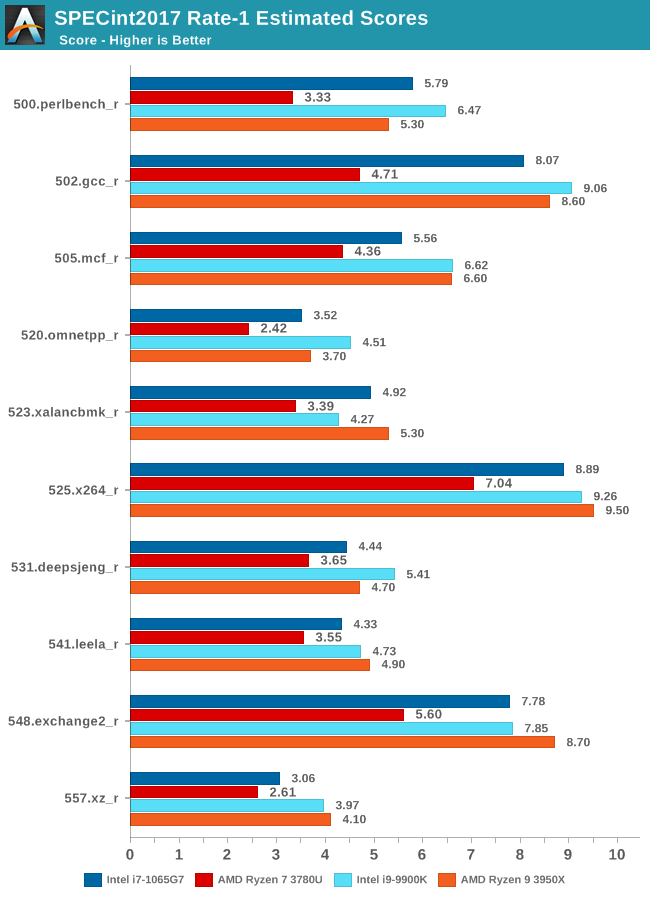
The first thing that comes to mind when looking at these results is that there’s a huge discrepancy between what the Intel and AMD models of the Surface Laptop 3. It’s very evident that Intel’s new Ice Lake CPUs and the Sunny Cove microarchitecture have quite a large lead over the Zen+ based Picasso SoC.
The Intel model's performance is near identical to what we’ve measured back in August on Intel’s development platform: we again see the chip being able to keep up with even Intel’s best performing desktop solutions which are running at far higher frequencies and larger power draw.
The Ryzen 7 3780U isn’t quite able to showcase a similar positioning, as it’s notably further behind the Ryzen 9 3950X with the newer Zen2 microarchitecture and faster memory configuration.
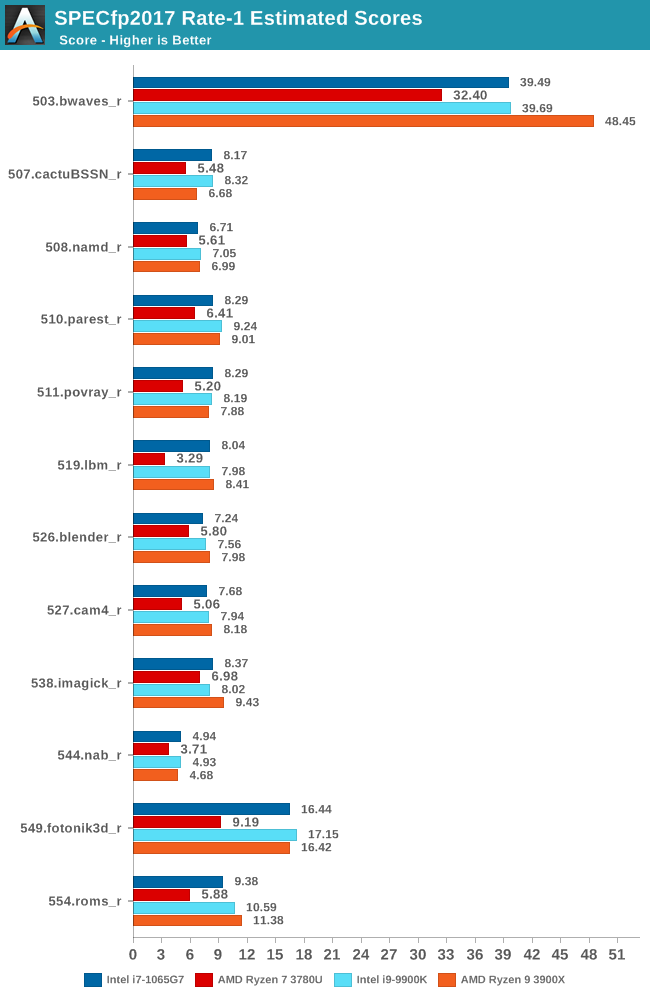
The situation in the floating-point suite is very similar, with the Core i7-1065G7 taking a quite considerable lead over the Ryzen 7 3780U. The 519.lbm results here are interesting due to the fact that AMD’s platform is behind by a factor greater than 2x – the test is memory bandwidth and subsystem limited so it’s possibly a bigger bottleneck on the slower DDR4-2400 memory that the system has to make due with. Intel’s LPDDR4X-3733 is able to well keep up with the desktop platforms in such situations.
But even in less memory intensive workloads such as 511.povray, AMD’s IPC disadvantage is too great and even with a theoretical higher peak frequency of 500MHz, the Zen+ based design is too far behind Intel’s new microarchitecture.
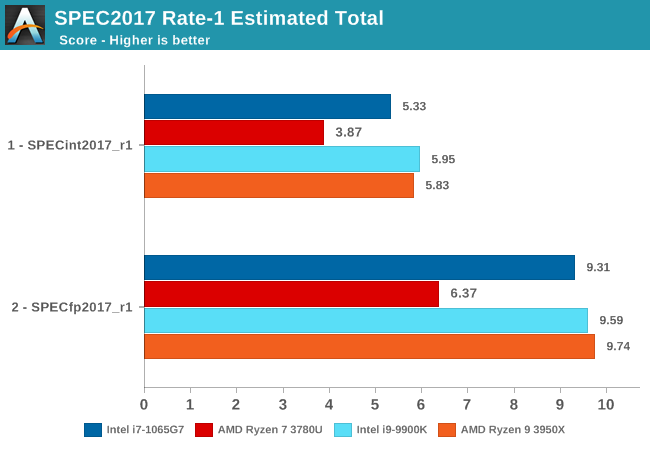
The overall SPEC2017 ST scores are pretty one-sided, with the Intel variant of the Surface Laptop 3 being ahead by 37% in the integer suite, and 46% in the floating-point suite. We hadn’t really expected the AMD system to be able to keep up with the Intel CPU, but these results really just expose the technological differences between the two designs. AMD’s Zen2 and LPDDR4X APUs can’t come early enough, as this is a gap that the company needs to close as soon as possible if it wants to compete in high-end laptop designs.
Multi-Threaded Performance: Continued Intel Advantage
While it’s clear that Intel has a large single-threaded performance advantage, we wanted to also see the competitive situation in a multi-threaded/multi-process comparison between the two chips. In the Rate-N test configuration of SPEC, we’re launching 8 instances on both platforms to fully saturate the system and have two processes per physical CPU.
In the MT tests, the AMD system ran at frequencies between 2.9-3.35GHz, whilst the Intel platform ran between 2.6-3.5GHz, depending on workload. TDP, or better said, peak power consumption, plays a bigger role in these tests as the 4-6 hours runtime of the test means we’re really stressing the cooling solutions of the laptops. Intel’s chip here is allowed to draw up to 44W for short durations before it falls down to a sustained 25W. We weren’t able to accurately measure the power draw for the AMD platform but we do note that it looks like under prolonged stress the CPU was around 10°C colder than the Intel variant, with ~70°C at 2.9GHz for the Ryzen system versus 80°C at 2.6GHz for the Intel system, which could point out to a lower sustained power draw for the AMD system.
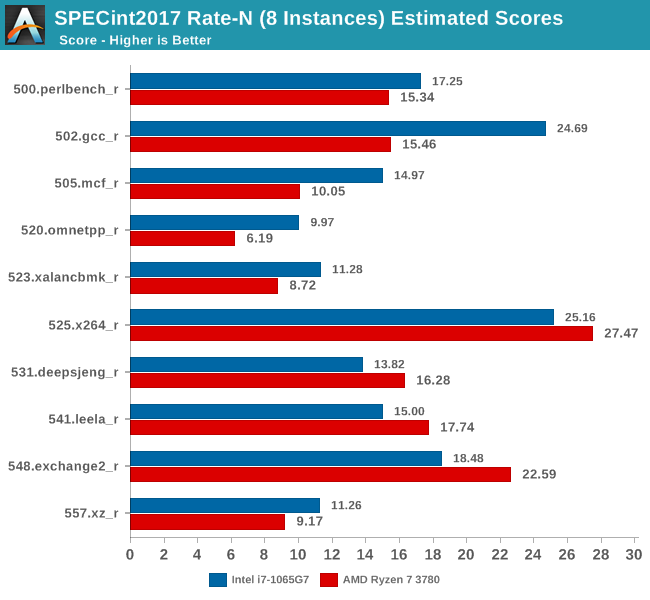
In the integer suite, we mostly seeing the Intel system being ahead, but this time around AMD also manages to win a few tests. The tests where AMD fared best were workloads which have a higher execution characterization, compared to more strictly memory-bound tests such as mcf or omnetpp, where Intel has a clear lead in. Intel’s lead in 502.gcc is pretty massive as well as surprising – I hadn’t expected such a gap, but then again, it’s quite in line with what we saw in the ST results.

In the floating-point suite AMD loses the few advantages that it had, and falls further behind the Intel platform. The FP suite is a lot more memory bound, and Picasso’s memory subsystem here just can’t keep up. The 519.lbm and 554.roms results are particularly shocking as they’re essentially almost no faster than the single-threaded results – the system here is utterly bottlenecked and can’t even scale up in performance over multiple cores.
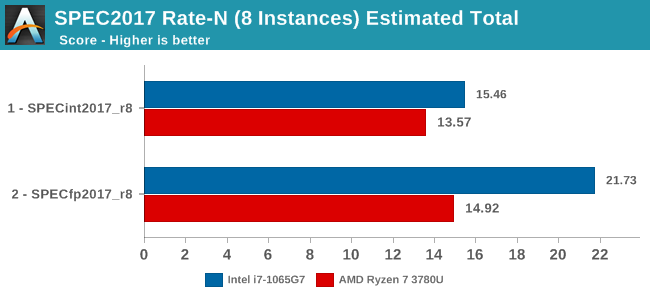
The overall results for the Rate-8 tests across all physical and logical cores of both the Ice Lake and Picasso systems see a similar performance discrepancy as showcased in the ST results: The Intel Core i7-1065G7 is ahead by 13.9% in the integer suite and a massive 45.6% in the FP suite. The one bottleneck that’s seemingly holding back the AMD system the most is its memory subsystem, and workloads which particularly stress this part of the CPU microarchitectures are the tests in which the Ryzen system fared by far the worst.
All in all, Intel’s process node, microarchitectural IPC, and memory technology lead in the Ice Lake solution is seemingly just too much for the Picasso chip to be able to compete with. Let’s move on to our standard test suite benchmarks and see if the we can correlate similar results in other workloads…








174 Comments
View All Comments
Fataliity - Saturday, December 14, 2019 - link
That came out wrong re-reading it. sorry its late. AMD's die is twice the size which should let it cool better. and apu ccx is 60mm squared, intel's for 4 cores is almost the same on ice lake. So yes a similar power for similar heat would make sense. We don't know what's coolin the inside on both of these either though, that could make a big difference. However, I still think it's questionable when Intel boosts and hits 100 degrees C, just looks like they're pushing the CPU as far as possible to make it look as good as it can, knowing the new APU's are coming out soon.And yes, the fact that it can draw 42 watts on CPU at boost definitely seems like an unfair advantage. The temps also reflect that in 25 seconds it overheats due to it too, forcing to ramp down.
Fataliity - Saturday, December 14, 2019 - link
And I looked into the IO. It should pull 10-15W, including graphics idle, putting Ryzen on par with Ice Lake around 20-25 watts. Which would make more sense.pifaa - Saturday, December 14, 2019 - link
Personal opinion. The review is very obviously biased towards Intel. The tests are carefully sellected to demonstrate Intel dominance, which in the real world is non present anymore. The only advantage Intel still has over AMD in the mobile space, is power consumption. As we see, that advantage is shrinking fast.m53 - Saturday, December 14, 2019 - link
Personal opinion. The earth is flat.GruenSein - Saturday, December 14, 2019 - link
The results are no surprise. It’s Intel‘s newest architecture and manufacturing node against AMD‘s year old Zen1+ on 12nm. It’s too bad that AMD take their time updating mobile parts and APUs. A Zen2 + Navi on 7nm should be much more competitive. This is the inverse situation we see in desktop parts where there is no sunny cove and still 14nm for Intelyeeeeman - Saturday, December 14, 2019 - link
Lets see what AMD brings to the table with zen 2. Intel does have a better ipc with ice lake, even compared to zen 2, but it has a handicap in the fact that it is built on 10nm and they have only 4 cores in 15w tdp. I am pretty confident that AMD can afford a 6 core in the same tdp, like comet lake.dragosmp - Saturday, December 14, 2019 - link
The boost behavior is very erratic on the AMD. I assume this ramping up/down under load is quite inefficient and buts a high emphasis on how fast the CPU can ramp up and down.Looks very erratic to the point of being defective. Multi-core loads though are fine. Does this mean when a low-threaded task is ran the scheduler bunny hops the task on all cores? This used to be a problem on Ryzen1 and thought it was solved with an AMD driver, but it came back maybe on this MS product.
I suspect a few % performance were left on the table, but like most here I assume the GPU is bandwidth-starved and high speed memory can't come soon enough for AMD. Quite surprising how poor they are with feeding the GPU, lack of dev on the GPU side in the last few years has hurt a lot.
AshlayW - Saturday, December 14, 2019 - link
Awesome result for the Ice Lake chip. But let's keep expectations in check here; the Ryzen part is based on a uArch from 2017 with slight optimisations, and also has half the L3 cache size due to a significant process disadvantage. While a very valid product v product comparison it is not particularly 'fair' as Intel's development (sunk) costs for the ICL and 10nm node are astronomically higher than Picasso's.I consider this 'flavour' until AMD can finally pull its finger out of its rear and get Zen2 mobile cores on 7nm, which should match or beat this. Finally, the memory limitation on the Picasso part is severely holding it back. I have no idea they wouldn't have opted for DDR4-2933 (what Picasso supports natively), which can lower its clock rate in less demanding tasks for higher efficiency. In some of these tests, this could have allowed AMD the win (which would have been particularly impressive given the huge aforementioned uArch/Node advantages Intel has). The bandwidth would have especially helped in the graphics tests. If the AMD surface design is significantly cheaper (I am willing to bet AMD can give these chips for 25% of what Intel is selling the ICL for) it could slot nicely in as a lower performing, but also much lower cost alternative.
I will wait patiently for Renoir to see what 7nm Zen2 can do in mobile; arguablly where it is most needed.
scineram - Monday, December 16, 2019 - link
I think they worried about power with faster memory.MBarton - Monday, December 30, 2019 - link
profit margin limited and not enough leftover Zen 2 after satisfying Epyc orders, THR3/Ryzen 3k, and console orders.