The Snapdragon 865 Performance Preview: Setting the Stage for Flagship Android 2020
by Andrei Frumusanu on December 16, 2019 7:30 AM EST- Posted in
- Mobile
- Qualcomm
- Smartphones
- 5G
- Cortex A77
- Snapdragon 865
Machine Learning Inference Performance
AIMark 3
AIMark makes use of various vendor SDKs to implement the benchmarks. This means that the end-results really aren’t a proper apples-to-apples comparison, however it represents an approach that actually will be used by some vendors in their in-house applications or even some rare third-party app.
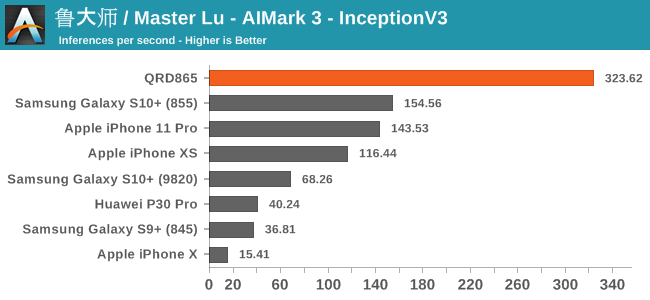
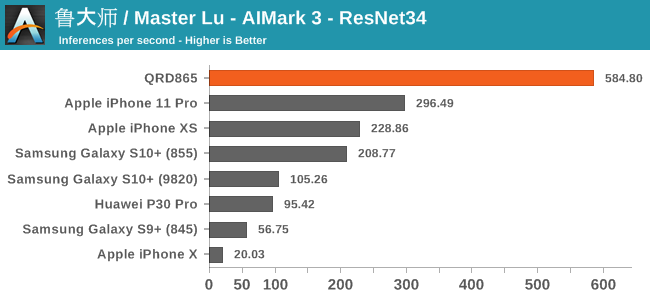
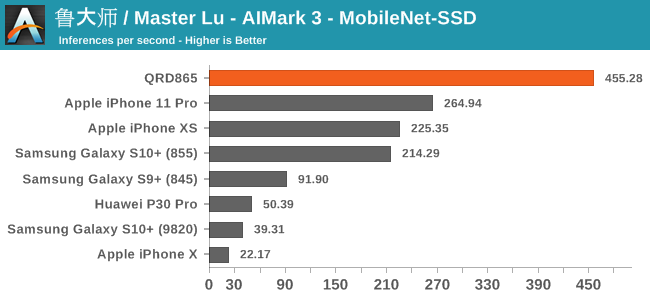
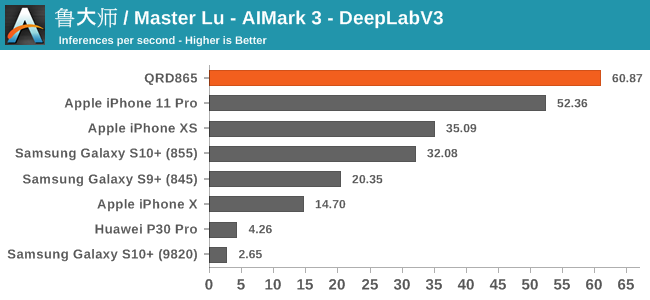
In AIMark 3, the benchmark uses each vendor’s proprietary SDK in order to accelerate the NN workloads most optimally. For Qualcomm’s devices, this means that seemingly the benchmark is also able to take advantage of the new Tensor cores. Here, the performance improvements of the new Snapdragon 865 chip is outstanding, posting in 2-3x performance compared to its predecessor.
AIBenchmark 3
AIBenchmark takes a different approach to benchmarking. Here the test uses the hardware agnostic NNAPI in order to accelerate inferencing, meaning it doesn’t use any proprietary aspects of a given hardware except for the drivers that actually enable the abstraction between software and hardware. This approach is more apples-to-apples, but also means that we can’t do cross-platform comparisons, like testing iPhones.
We’re publishing one-shot inference times. The difference here to sustained performance inference times is that these figures have more timing overhead on the part of the software stack from initialising the test to actually executing the computation.
AIBenchmark 3 - NNAPI CPU
We’re segregating the AIBenchmark scores by execution block, starting off with the regular CPU workloads that simply use TensorFlow libraries and do not attempt to run on specialized hardware blocks.
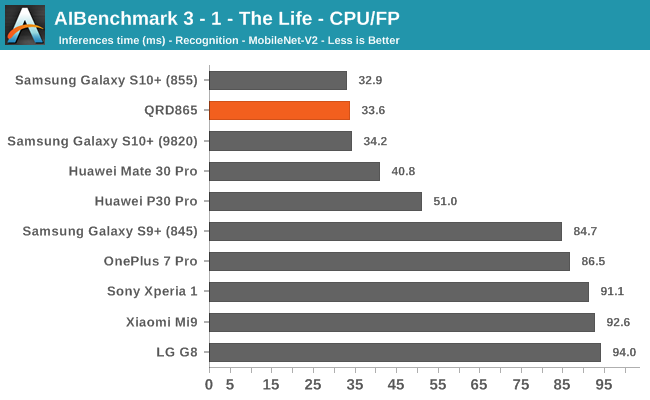
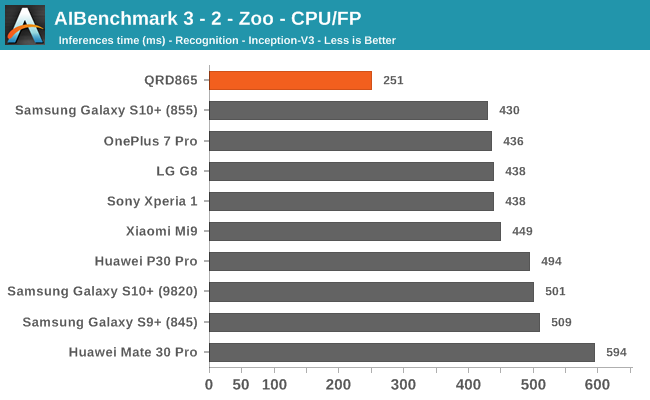
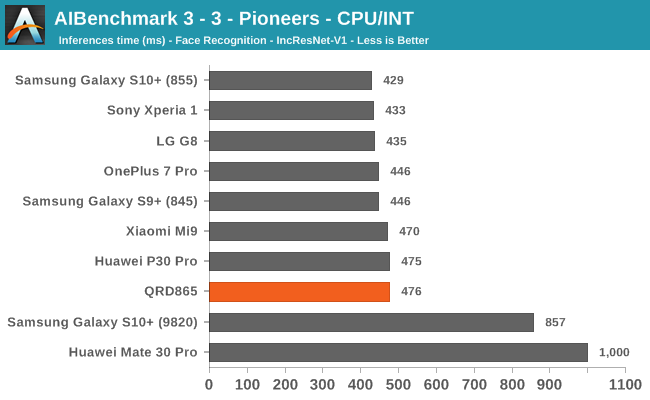
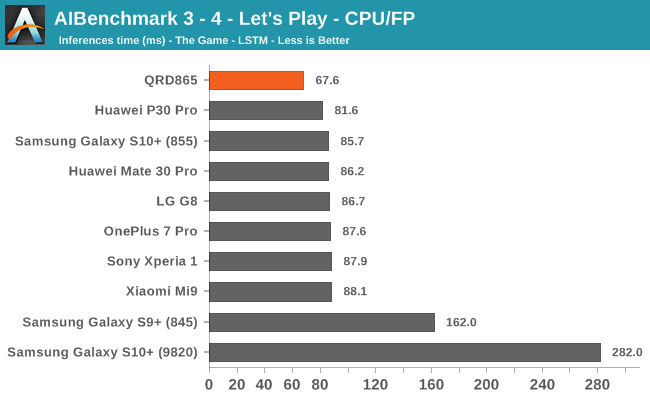
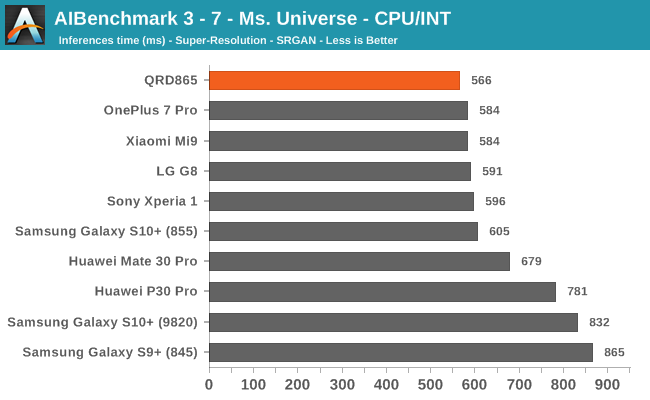

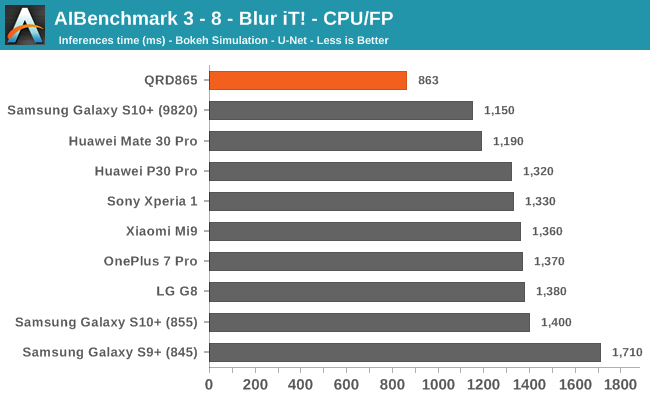
Starting off with the CPU accelerated benchmarks, we’re seeing some large improvements of the Snapdragon 865. It’s particularly the FP workloads that are seeing some big performance increases, and it seems these improvements are likely linked to the microarchitectural improvements of the A77.
AIBenchmark 3 - NNAPI INT8
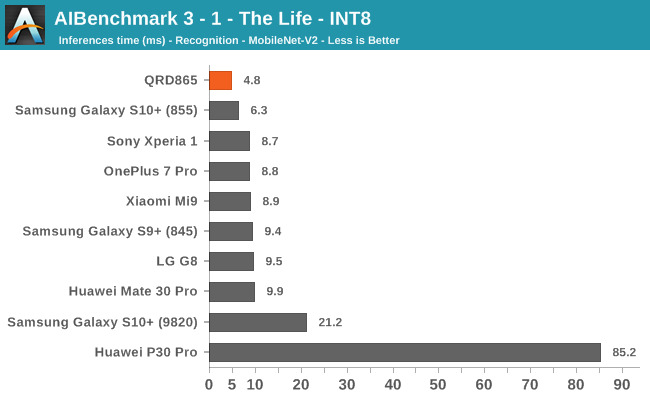
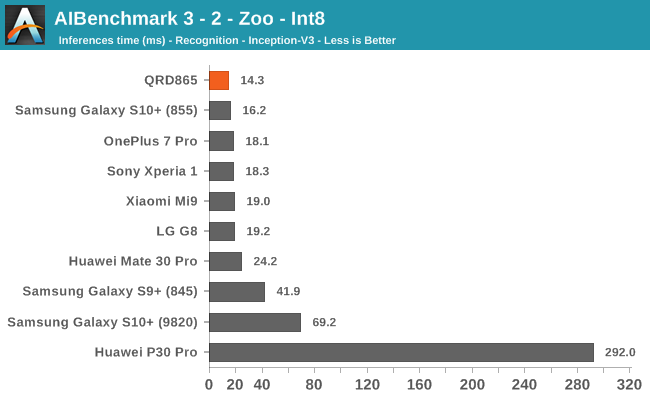
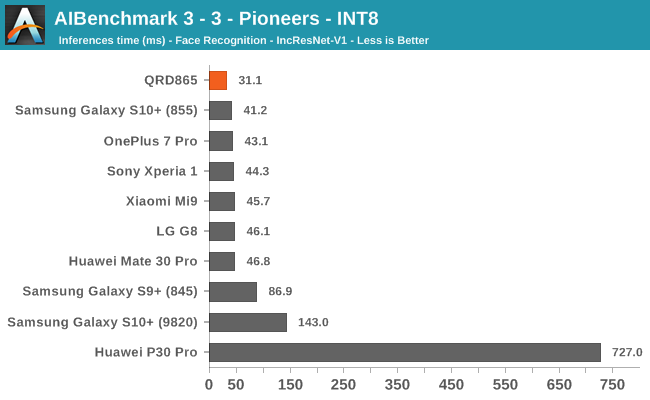
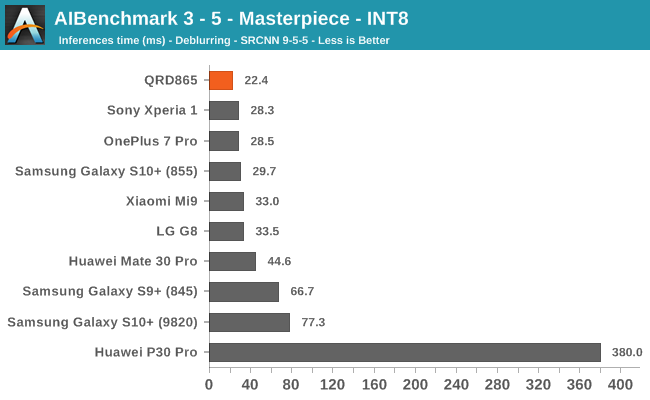
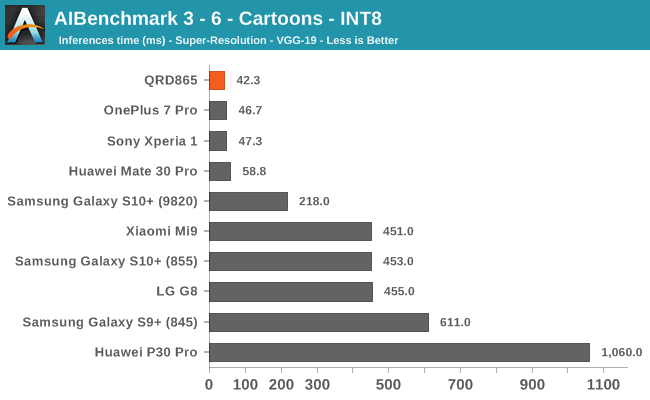
INT8 workload acceleration in AI Benchmark happens on the HVX cores of the DSP rather than the Tensor cores, for which the benchmark currently doesn’t have support for. The performance increases here are relatively in line with what we expect in terms of iterative clock frequency increases of the IP block.
AIBenchmark 3 - NNAPI FP16
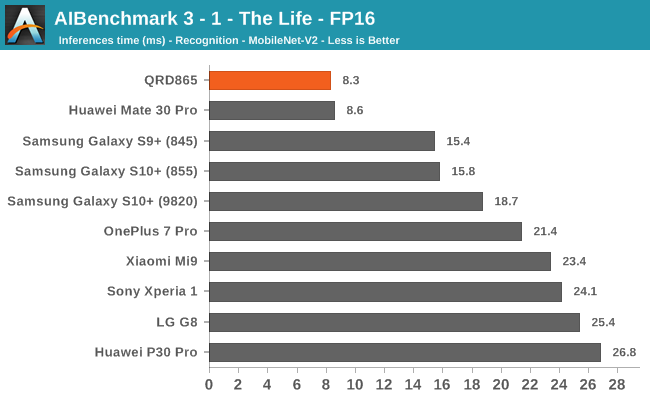
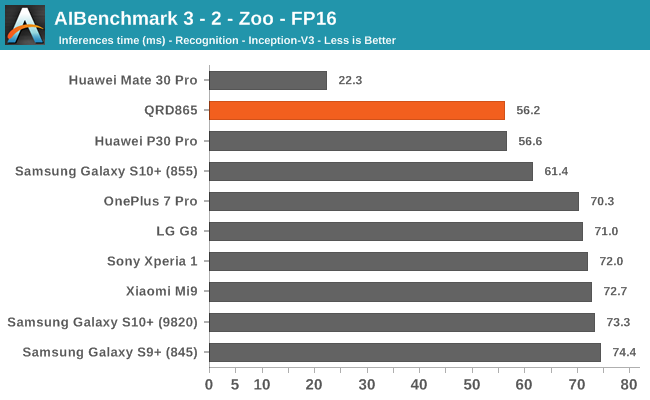
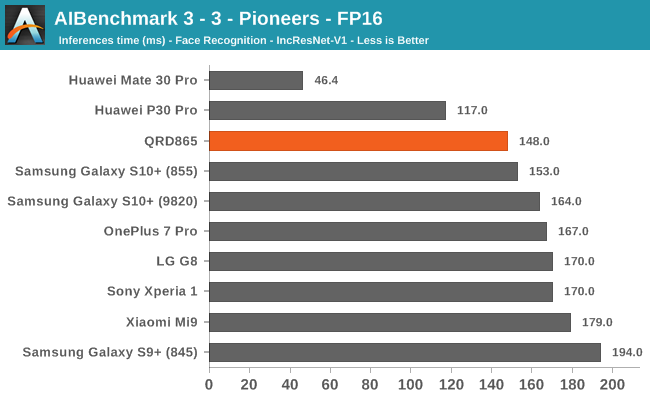
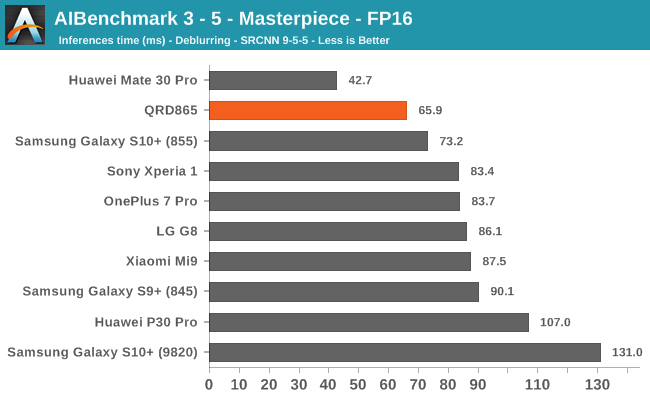
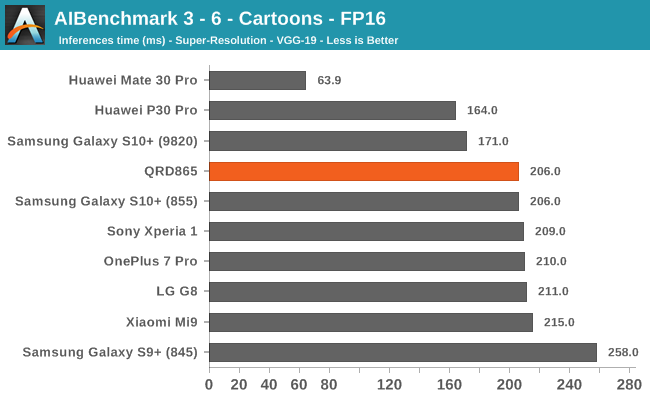
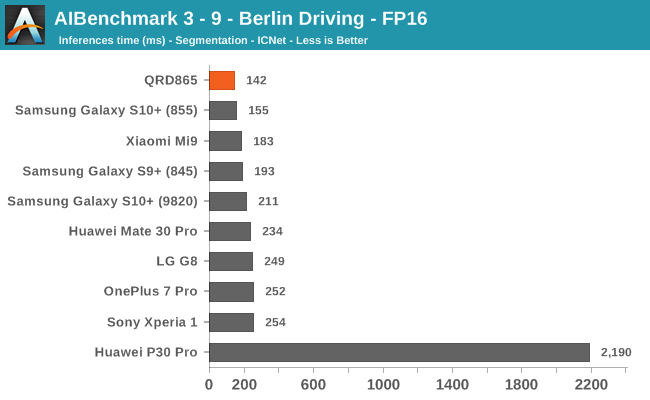
FP16 acceleration on the Snapdragon 865 through NNAPI is likely facilitated through the GPU, and we’re seeing iterative improvements in the scores. Huawei’s Mate 30 Pro is in the lead in the vast majority of the tests as it’s able to make use of its NPU which support FP16 acceleration, and its performance here is quite significantly ahead of the Qualcomm chipsets.
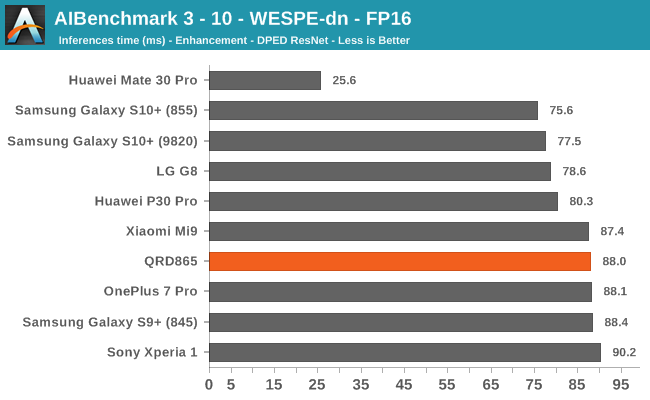
AIBenchmark 3 - NNAPI FP32
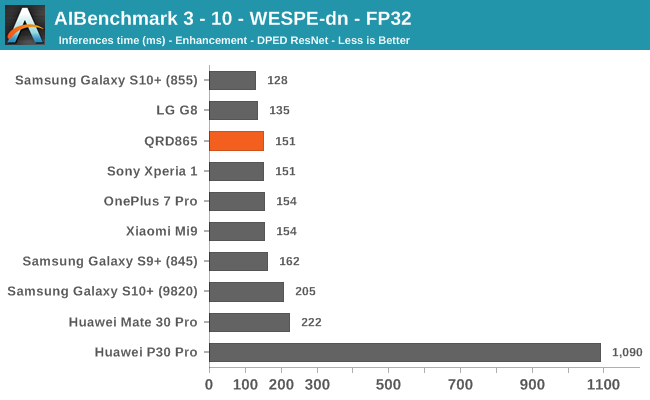
Finally, the FP32 test should be accelerated by the GPU. Oddly enough here the QRD865 doesn’t fare as well as some of the best S855 devices. It’s to be noted that the results here today were based on an early software stack for the S865 – it’s possible and even very likely that things will improve over the coming months, and the results will be different on commercial devices.
Overall, there’s again a conundrum for us in regards to AI benchmarks today, the tests need to be continuously developed in order to properly support the hardware. The test currently doesn’t make use of the Tensor cores of the Snapdragon 865, so it’s not able to showcase one of the biggest areas of improvement for the chipset. In that sense, benchmarks don’t really mean very much, and the true power of the chipset will only be exhibited by first-party applications such as the camera apps, of the upcoming Snapdragon 865 devices.








178 Comments
View All Comments
quadrivial - Monday, December 16, 2019 - link
I think there could be some possibility of AMD striking that deal with some stipulations. They have the semi-custom experience to make it happen and they don't have much to lose in mobile. AMD already included a small arm chip on their processors. They already use AMD GPUs too. A multi-chip package with be great here.I've given some thought to the idea of 8 Zen cores, 8 core ARM complex, 24CU Navi, 32GB HBM2, and a semi-custom IO die to the it together. You could bin all of these out for lower-spec'd devices. The size of this complex would be much smaller than a normal dedicated GPU, CPU, and RAM while using a bit less power. Most lower end devices would probably only need 2 x86 cores and 8-11CU with 8GB of RAM.
zanon - Wednesday, December 18, 2019 - link
>"I wonder if it's in the cards for Apple to ever include both an Intel processor as well as a full fledged mobile chip in the future, working in the same way as integrated/discrete graphics - the system would primarily run on the A13x, with the Intel chip firing up for Intel-binary apps as needed."Doubt it, if only because x64 is already coming out of patent protection, and with each passing year newer feature revisions will have the same thing happen. By 2025 or 2026 or so, Apple (or anyone else) will just flat out be able to implement x86-64 all the way up to Core 2 at least however they like (be it hardware, software, or some combo with code morphing or the like). That would probably be enough to cover most BC, sure stuff wouldn't run as fast but it would run. And there'd be a lot of power efficiency to be gained as well.
Midwayman - Monday, December 16, 2019 - link
OSX on arm seems a given soon. That would allow them to really blur the line between their ipad pro and the lower end laptops. Even if they are still technically different OSes it would make getting real pro apps onto the ipad pro a ton easier. MS tried this of course but didn't have the clout or tablet market to really make it happen. Apple is in a position to force the issue and has switch architectures in the past.levizx - Tuesday, December 17, 2019 - link
Nope, Apple still support AArch32, and Apple 64bit is only ahead of ARM by 1 year max, actual S810 silicon by Qualcomm was only 15 months later than A7, you can't possibly say Apple started earlier AND took 2-3 years LESS than ARM's partners to design silicon. That would mean Apple has to beat A57 by at least 3 year. Reality says otherwise.quadrivial - Tuesday, December 17, 2019 - link
Apple dropped aarch32 starting with A11.ARM announced their 64-bit ISA on 27 October 2011. The A7 launched 19 September 2013 -- less than two years later. Anandtech's first review of a finished A53 and A57 product was 10 Feb 2015 -- almost 3.5 years later and their product was obviously rushed with new revision coming out after and A57 being entirely replaced and forgotten.
Qualcomm and others were shocked because they only had 2 years to do their designs and they weren't anywhere near complete. A ground-up new design in 23 months with a band new ISA isn't possible under and circumstances.
https://www.google.com/amp/s/appleinsider.com/arti...
ksec - Monday, December 16, 2019 - link
Apple SoC uses more Die Space for CPU Core, it is as simple as that, so they are not a fair comparison. For roughly the same die size, Qualcomm has to fit in the Modem, while Apple has the modem external.rpg1966 - Monday, December 16, 2019 - link
I'm not sure I understand the "fair" bit? The other chip makers are free to design a larger-core variant if they so choose. And, the 865 has the modem external, just like the Apple chips. Also, generally speaking, the SoC + external modem approach should require more power, yet Apple seems to do very well on those benchmarks.Maybe it's more as per another reply, i.e. Apple just optimises everything, one example being throwing out a32.
generalako - Monday, December 16, 2019 - link
That's not an argument -- the modem costs money for both parties either way at the end of the day. Also, Cortex Cores are pretty great, with still bigger year-on-year improvements than Apple (which seems to have stagnated), so it is closing the gap, albeit slowly. The big complaint however is in things like Qualcomm's complacency in GPU, or in ARM doing shit-all to give us a new efficiency core architecture, after 3 years.Apple has surpassed them hugely here, to the point that their efficiency cores perform more than 2x as much with half the power. Now, if you want bring price into here, think about how much that costs OEMs. It costs them by forcing them to use mid-range SoCs that use expensive performance cores, when they could make due with only efficiency cores that performed better. It costs them, as well as flagship phones, in a lot of power efficiency, forcing them to do hardware compromises, or spend more on larger batteries, to compete.
generalako - Monday, December 16, 2019 - link
ARM has been catching up, though. The IPC increases since A11 have been pretty meagre, whereas A76 was a pretty sizeable jump (cutting a lot of the gap), and A77 is doing a 25% IPC jump, whereas the A13 did what, half that? Of course Apple still has a huge foothold, but the gap has been getting smaller...ARM's issue right now, though, is in efficiency cores. The fact that their Cambrdige team hasn't developed anything for 3 straight years now (going into the 4th), whereas Apple's yearly architecture improvement has given them efficiency cores that is monumentally better in both performance and efficiency, is getting embarrassing at this points. It's hurting Android phones a lot and getting kind of ridiculous at this point. No less frustrating that none of the SoC actors are bothering to make any dedicated architectures themselves to make up for it. Qualcomm is complacent in even their GPUs, which have been on the same architecture for 3 straight years and has in this time completely lost its crown to Apple--even ARM's Mali has caught up!
FunBunny2 - Tuesday, December 17, 2019 - link
"How is Apple so far ahead in some/many respects, given that Arm is dedicated to designing these microarchitectures?"based on what I've read in public reporting, Apple appears to mostly thrown hardware at the ISA. Apple has the full-boat ISA license, so they can take the abstract spec and lay it out on the silicon anyway they want. but what it appears is that all that godzilla transistor budget has gone to caches(s) and such, rather than a smarter ALU, fur instance. may haps AT has done an analysis just exactly what Apple did to the spec or RD to make their versions? did they actually 'innovate' the (micro-?) architecture, or did they, in fact, just bulk up the various parts with more transistors?