The Snapdragon 865 Performance Preview: Setting the Stage for Flagship Android 2020
by Andrei Frumusanu on December 16, 2019 7:30 AM EST- Posted in
- Mobile
- Qualcomm
- Smartphones
- 5G
- Cortex A77
- Snapdragon 865
Machine Learning Inference Performance
AIMark 3
AIMark makes use of various vendor SDKs to implement the benchmarks. This means that the end-results really aren’t a proper apples-to-apples comparison, however it represents an approach that actually will be used by some vendors in their in-house applications or even some rare third-party app.
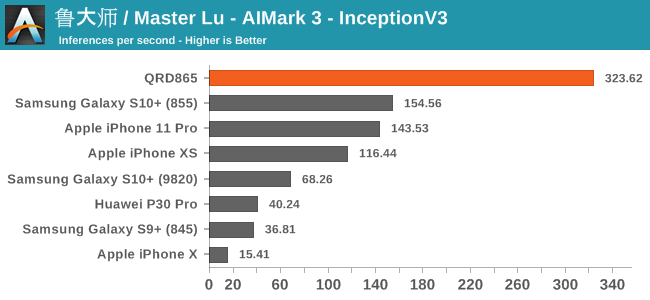
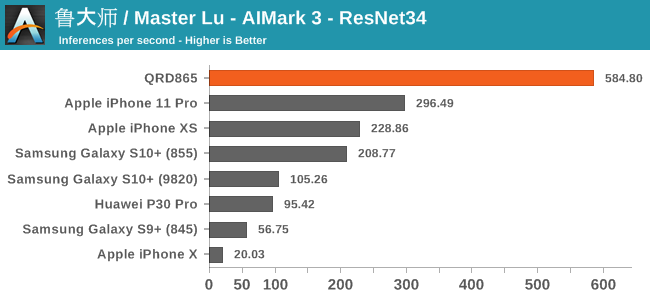
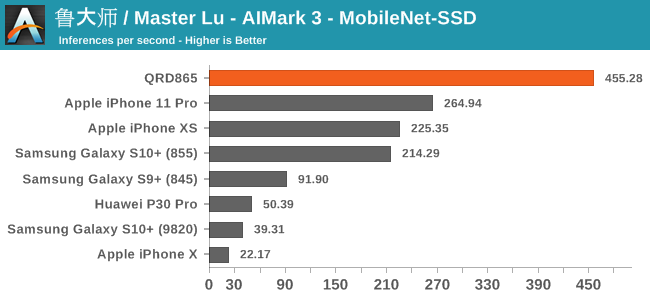
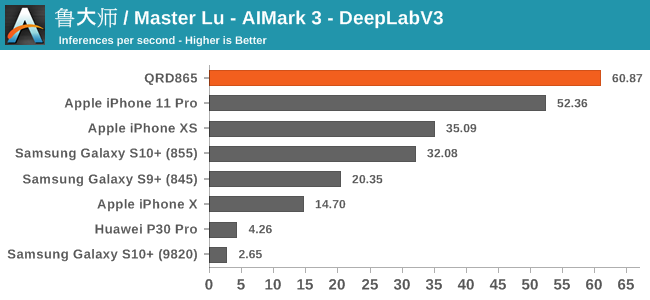
In AIMark 3, the benchmark uses each vendor’s proprietary SDK in order to accelerate the NN workloads most optimally. For Qualcomm’s devices, this means that seemingly the benchmark is also able to take advantage of the new Tensor cores. Here, the performance improvements of the new Snapdragon 865 chip is outstanding, posting in 2-3x performance compared to its predecessor.
AIBenchmark 3
AIBenchmark takes a different approach to benchmarking. Here the test uses the hardware agnostic NNAPI in order to accelerate inferencing, meaning it doesn’t use any proprietary aspects of a given hardware except for the drivers that actually enable the abstraction between software and hardware. This approach is more apples-to-apples, but also means that we can’t do cross-platform comparisons, like testing iPhones.
We’re publishing one-shot inference times. The difference here to sustained performance inference times is that these figures have more timing overhead on the part of the software stack from initialising the test to actually executing the computation.
AIBenchmark 3 - NNAPI CPU
We’re segregating the AIBenchmark scores by execution block, starting off with the regular CPU workloads that simply use TensorFlow libraries and do not attempt to run on specialized hardware blocks.
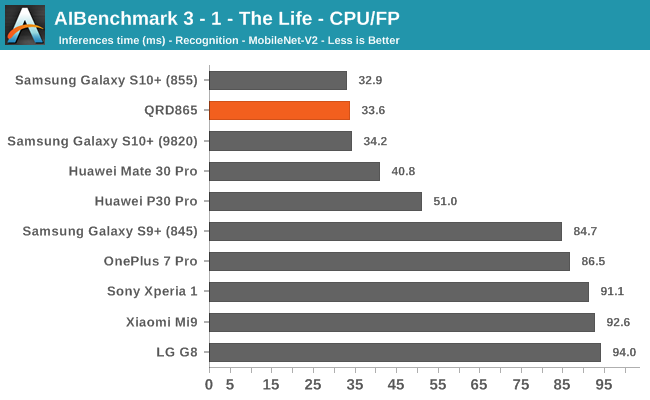
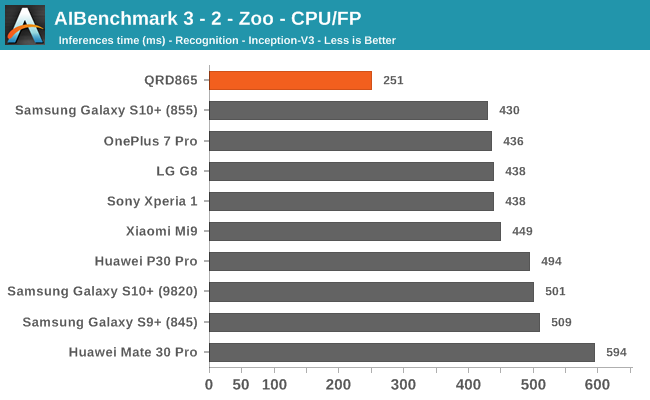
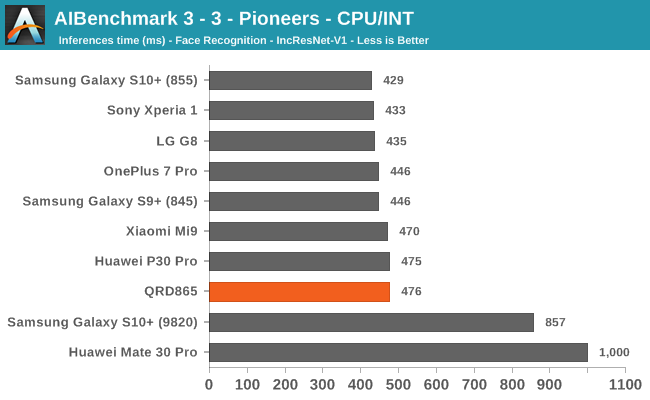
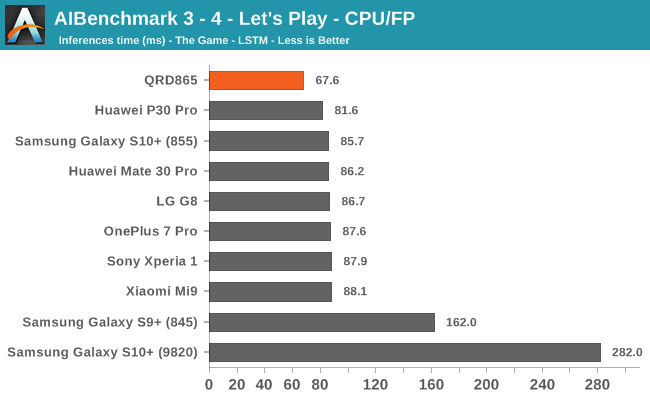
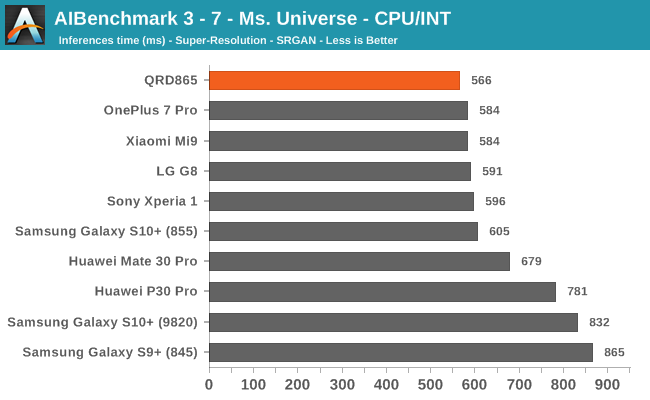

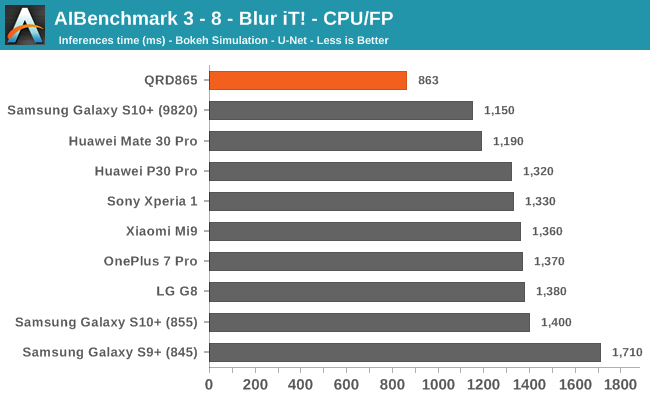
Starting off with the CPU accelerated benchmarks, we’re seeing some large improvements of the Snapdragon 865. It’s particularly the FP workloads that are seeing some big performance increases, and it seems these improvements are likely linked to the microarchitectural improvements of the A77.
AIBenchmark 3 - NNAPI INT8
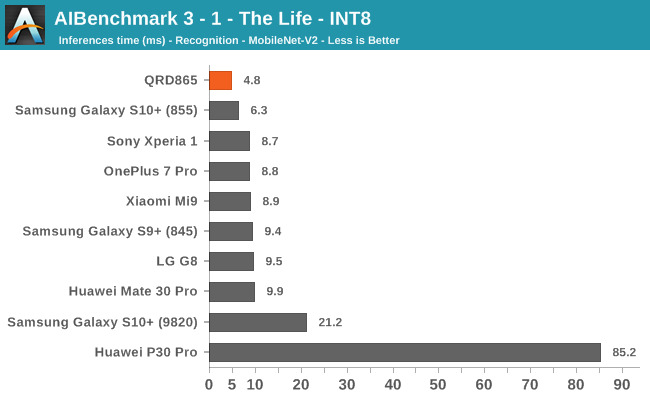
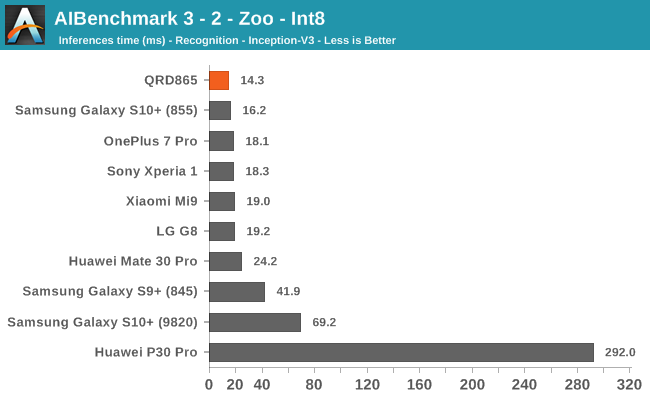
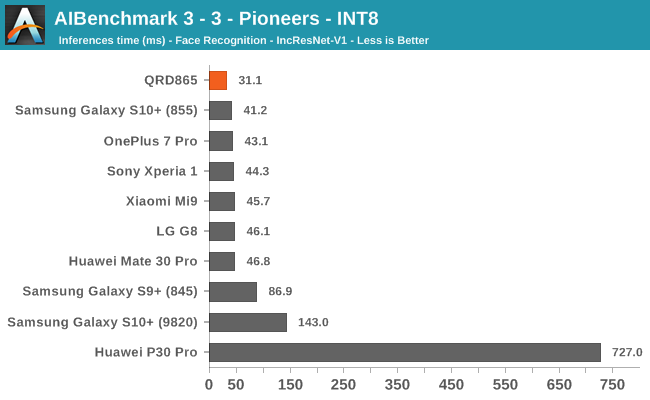
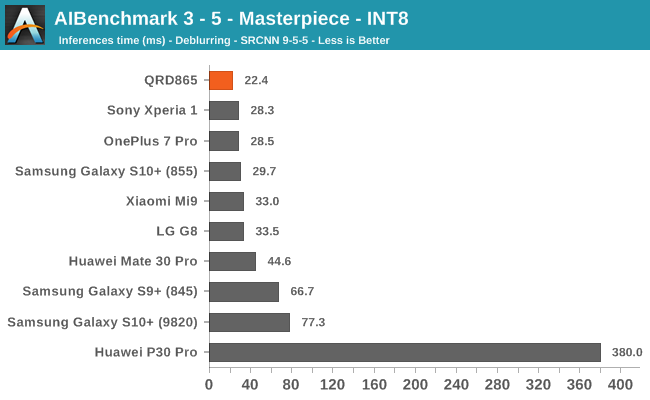
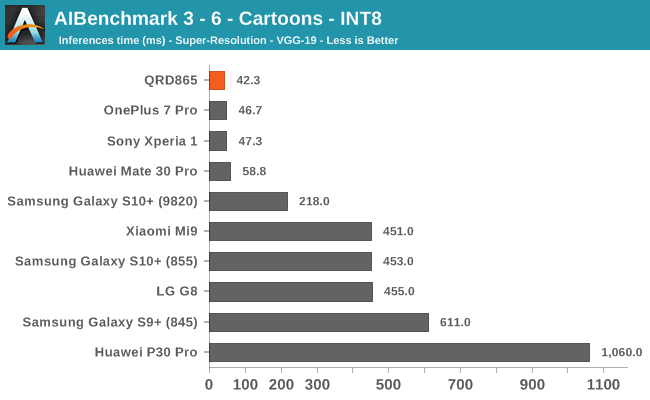
INT8 workload acceleration in AI Benchmark happens on the HVX cores of the DSP rather than the Tensor cores, for which the benchmark currently doesn’t have support for. The performance increases here are relatively in line with what we expect in terms of iterative clock frequency increases of the IP block.
AIBenchmark 3 - NNAPI FP16
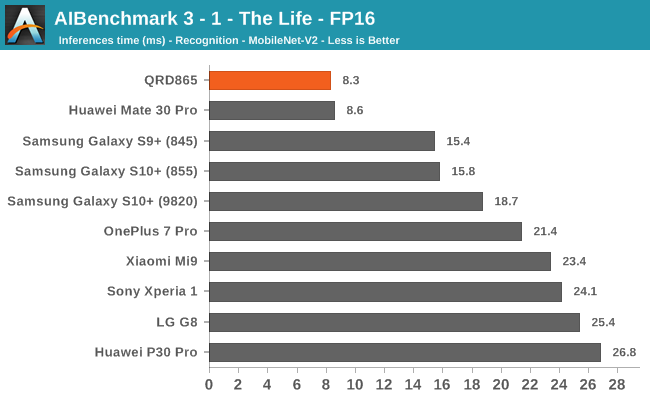
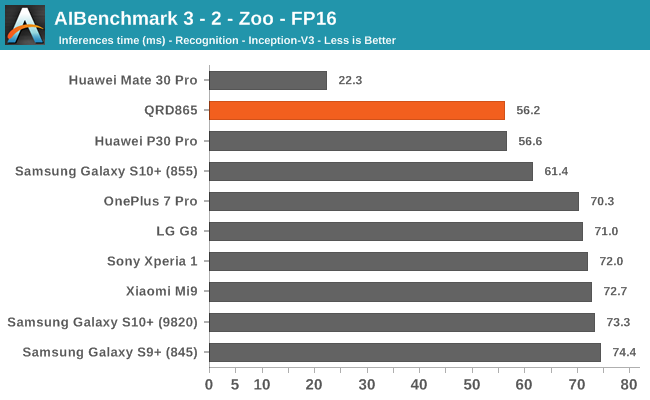
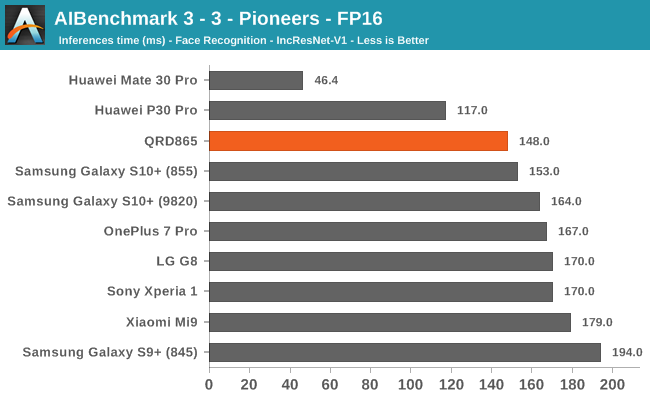
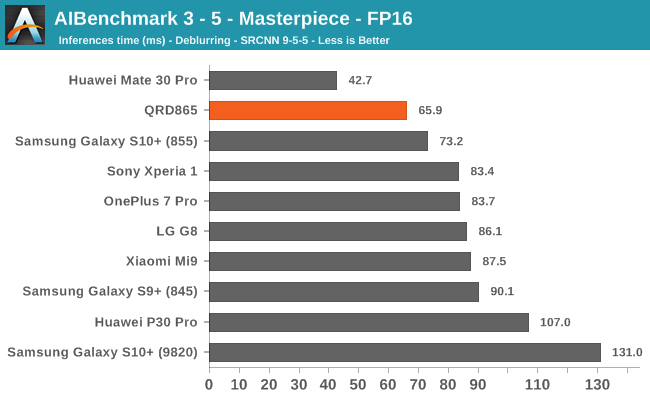
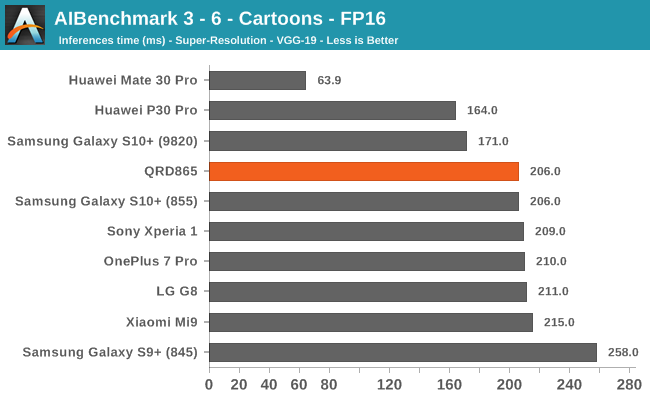
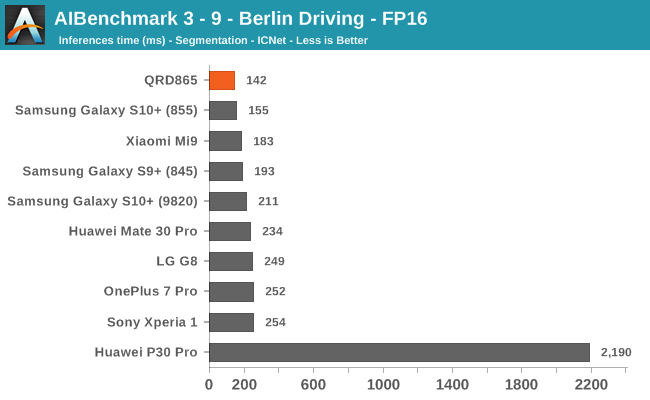
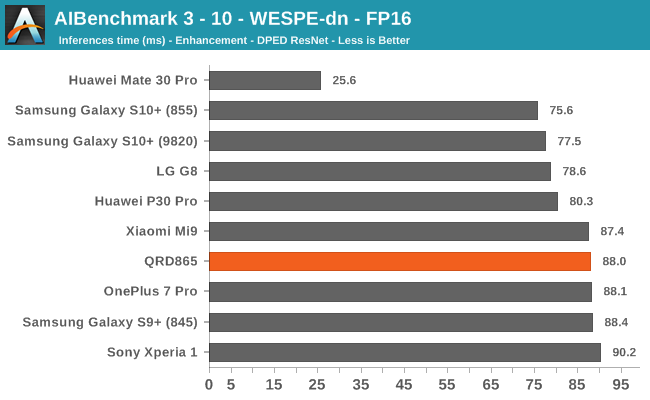
FP16 acceleration on the Snapdragon 865 through NNAPI is likely facilitated through the GPU, and we’re seeing iterative improvements in the scores. Huawei’s Mate 30 Pro is in the lead in the vast majority of the tests as it’s able to make use of its NPU which support FP16 acceleration, and its performance here is quite significantly ahead of the Qualcomm chipsets.
AIBenchmark 3 - NNAPI FP32
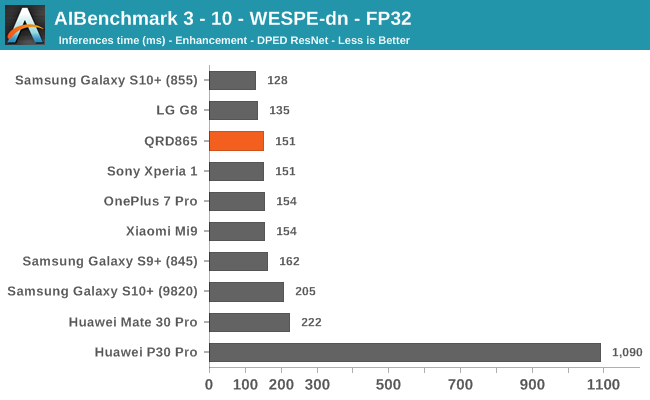
Finally, the FP32 test should be accelerated by the GPU. Oddly enough here the QRD865 doesn’t fare as well as some of the best S855 devices. It’s to be noted that the results here today were based on an early software stack for the S865 – it’s possible and even very likely that things will improve over the coming months, and the results will be different on commercial devices.
Overall, there’s again a conundrum for us in regards to AI benchmarks today, the tests need to be continuously developed in order to properly support the hardware. The test currently doesn’t make use of the Tensor cores of the Snapdragon 865, so it’s not able to showcase one of the biggest areas of improvement for the chipset. In that sense, benchmarks don’t really mean very much, and the true power of the chipset will only be exhibited by first-party applications such as the camera apps, of the upcoming Snapdragon 865 devices.








178 Comments
View All Comments
rpg1966 - Monday, December 16, 2019 - link
How is Apple so far ahead in some/many respects, given that Arm is dedicated to designing these microarchitectures?eastcoast_pete - Monday, December 16, 2019 - link
In addition to spending $$$ on R&D, Apple can optimize (tailor, really) its SoCs 100% to its OS and vice versa. Also, not sure if anybody has figures just how much the (internal) costs of Apple's SoCs are compared to what Samsung, Xiaomi etc. pay QC for their flagship SoCs. Would be interesting to know how much this boils down to costs.jospoortvliet - Monday, December 16, 2019 - link
I think cody I'd the big factor. Qualcomm and arm keep chips small for cost reasons. Apple throws transistors at the problem and cares little...s.yu - Monday, December 16, 2019 - link
I like the approach of throwing transistors :)generalako - Monday, December 16, 2019 - link
Can we stop with these excuses? What cost reasons? Whose stopping them from making two architectures then, letting OEMs decide which to use -- if Apple does it, why not them? Samsung aiming at large cores with their failed M4 clearly points towards a desire/intention to have larger cores that are more performant. Let's not make the assumption that there's no need here--there clearly is.Furthermore, where is the excuse in ARM still being on the A55 for the third straight year? Or Qualcomm being on their GPU architecture for 3 straight years, with so incremental GPU improvements the past two years that they not only let Apple both match and vastly surpass them, but are even getting matched by Mali?
There's simply no excuse for the laziness going on. ARM's architecture is actually impressive, with still big year-on-year IPC gains (whereas Apple has actually stagnated here the past two years). But abandoning any work on efficiency cores is inexcusable. As is the fact that none of the OEMs has done anything to deal with this problem.
Retycint - Monday, December 16, 2019 - link
Probably because ARM designs for general use - mobiles, tablets, TVs, cars etc, whereas Apple designs specifically for their devices. So naturally Apple is able to devote more resources and time to optimize for their platform, and also design cores/chips specific to their use (phone or tablet).But then again I'm an outsider, so the reality could be entirely different
generalako - Monday, December 16, 2019 - link
TIL using the same A55 architecture is "for general use" /sIf ARM had actually done their job and released efficiency cores more often, like Apple does every year, we'd have far more performant and efficient smartphones today across the spectrum. Flagship phones would benefit in idle use (including standby), and also in assigning far more resource-mild works to these cores than they do today.
But mid-range and low-end phones would benefit a huge amount here, with efficiency cores performing close to performance cores (often 1-2 older gen clocked substantially lower). That would also be cheaper, as it would make cluster of 2 performance cores not as necessary--fitting right in with your logic of making cheap designs for general use.
quadrivial - Monday, December 16, 2019 - link
There's a few reasons.Apple seems to have started before arm did. They launched their design just 2 years or so after the announcement of a64 while arm needed the usual 4-5 years for a new design. I don't believe apples designers are that much better than normal (I think they handed them the ISA and threatened to buy out MIPS if they didn't). Arm has never recovered that lead time.
That said, PA Semi had a bunch of great designers who has already done a lot of work with low power designs (mostly POWER designs if I recall correctly).
Another factor is a32 support. It's a much more complex design and doesn't do performance, power consumption, or die area any favors. Apple has ecosystem control, so they just dropped the complex parts and just did a64. This also drastically reduces time to design any particular part of the core and less time to verify everything meaning more time optimizing vs teams trying to do both at once.
Finally, Apple has a vested interest in getting faster as fast as possible. Arm and the mobile market want gradual performance updates to encourage upgrades. Even if they could design an iPhone killer today, I don't think they would. There's already enough trouble with people believing their phones are fast enough as is.
Apple isn't designing these chips for phones though. They make them for their pro tablets. The performance push is even more important for laptops though. The current chip is close to x86 in mobile performance. Their upcoming 5nm designs should be right at x86 performance for consumer applications while using a fraction of the power. They're already including a harvested mobile chip in every laptop for their T2. Getting rid of Intel on their MacBook air would do two things. It would improve profits per unit by a hundred dollars or so (that's almost 10% of low end models). It also threatens Intel to get them better deals on higher end models.
We may see arm move in a similar direction, but they can't get away with mandating their users and developers change architectures. Their early attempts with things like the surface or server chips (a57 was mostly for servers with a72 being the more mobile-focused design) fell flat. As a result, they seem to be taking a conservative approach that eliminates risk to their core market.
The success or failure of the 8cx will probably be extremely impactful on future arm designs. If it achieves success, then focusing on shipping powerful, 64-bit only chip designs seems much more likely. I like my Pixelbook, but I'd be willing to try an 8cx if the price and features were right (that includes support for Linux containers).
Raqia - Monday, December 16, 2019 - link
Nice post! You're right, it really does seem like Apple's own implementations defined the ARM v8.x spec given how soon after ARM's release their chips dropped. ARM is also crimped by the need to address server markets so their chips have a more complex cache and uncore hierarchies than Apple's and generally smaller caches with lower single threaded performance. Their customers' area budgets are also more limited compared to Apple who doesn't generally integrate a modem into their SoC designs.aliasfox - Monday, December 16, 2019 - link
I would also add that Qualcomm only makes a dozen or so dollars per chip, whereas Apple makes hundreds of dollars per newest generation iPhone and iPad Pro. Qualcomm's business model just puts them at a disadvantage in this case - they have to make a chip that's not only competitive in performance, but at a low enough cost that a) they can make money selling it, and b) handset vendors can make money using it. Apple doesn't really have to worry about that because for all intents and purposes, their chip division is a part of their mobile division.I wonder if it's in the cards for Apple to ever include both an Intel processor as well as a full fledged mobile chip in the future, working in the same way as integrated/discrete graphics - the system would primarily run on the A13x, with the Intel chip firing up for Intel-binary apps as needed.