Imagination Announces A-Series GPU Architecture: "Most Important Launch in 15 Years"
by Andrei Frumusanu on December 2, 2019 8:00 PM ESTFixed Function Changes & Scalability
Zooming out from the ALU, we’re seeing a higher-level block configuration that’s very similar to past Imagination PowerVR GPUs. The ALUs themselves are still housed in the larger cluster block that’s called the USC, or unified shading cluster. The USC along with various other fixed function blocks is in turn housed in an SPU, or shader processing unit, effectively the scaling block regularly referred to as a “core”.
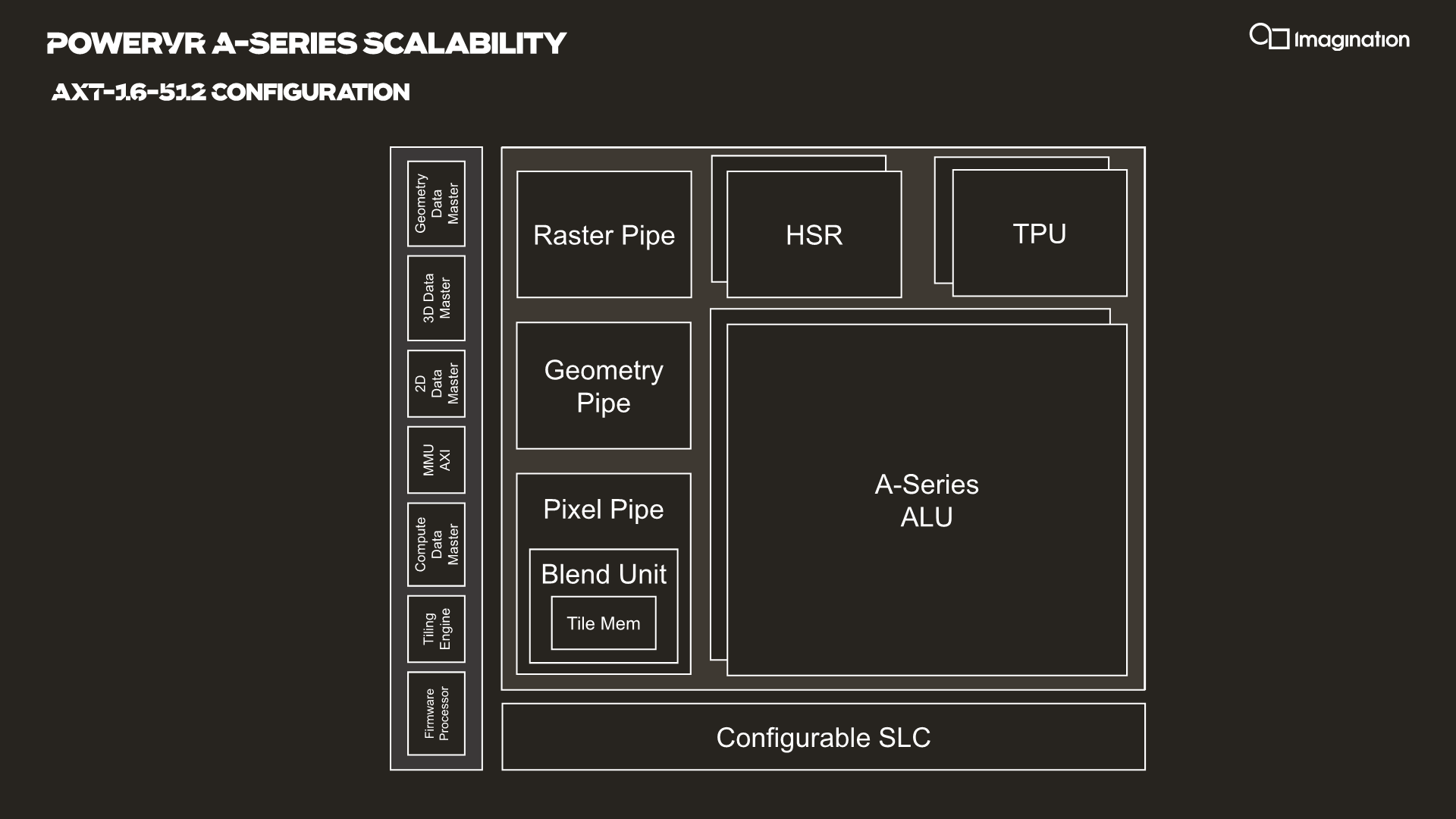
Each SPU houses two USCs in the current IP configuration, meaning we have two clusters of 128-wide ALUs. This is valid for all AXT parts, but we imagine the AXM-8-256 unit just has a single USC. The AXT-16-512 is the smallest configuration with a fully populated SPU.
Each SPU has its own geometry pipeline, and up to two texture processing units. The A-Series carries over the per-TPU throughput design from the Furian architecture, meaning the block is able to sample 8 bilinear filtered texels per clock. The A-Series doubles this up now per SPU and the AXT models feature two TPUs, bringing up the total texture fillrate to 16 samples per clock per SPU.
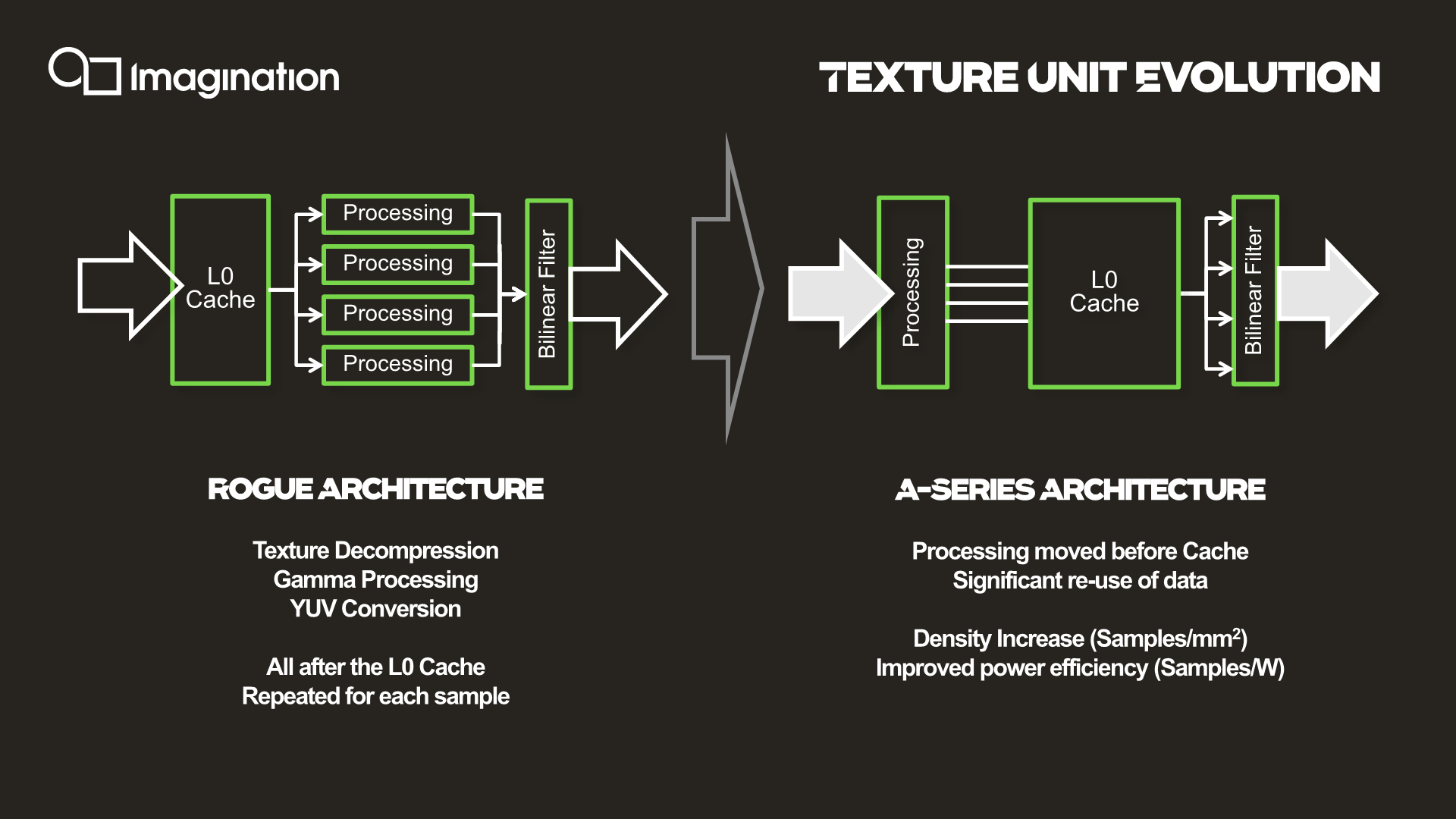
The microarchitecture of the texture units has also evolved beyond just their throughput. A bigger improvement that Imagination is disclosing is the handling and location of the L0 cache. The L0 cache has been relocated within the texturing workflow to between the processing and filtering stages, allowing the L0 cache to hold the outputs of the processing stage, rather than the inputs. This allows for what Imagination calls significant data reuse, as texels don't need to be re-processed each time they're needed. And given how many times a texel may need to be sampled during anisotropic filtering, it's easy to see why. With the benefit of hindsight, this seems like an obvious improvement to make, but the company says that the design choices of the legacy configuration made sense at the time of conception and the workloads back then.
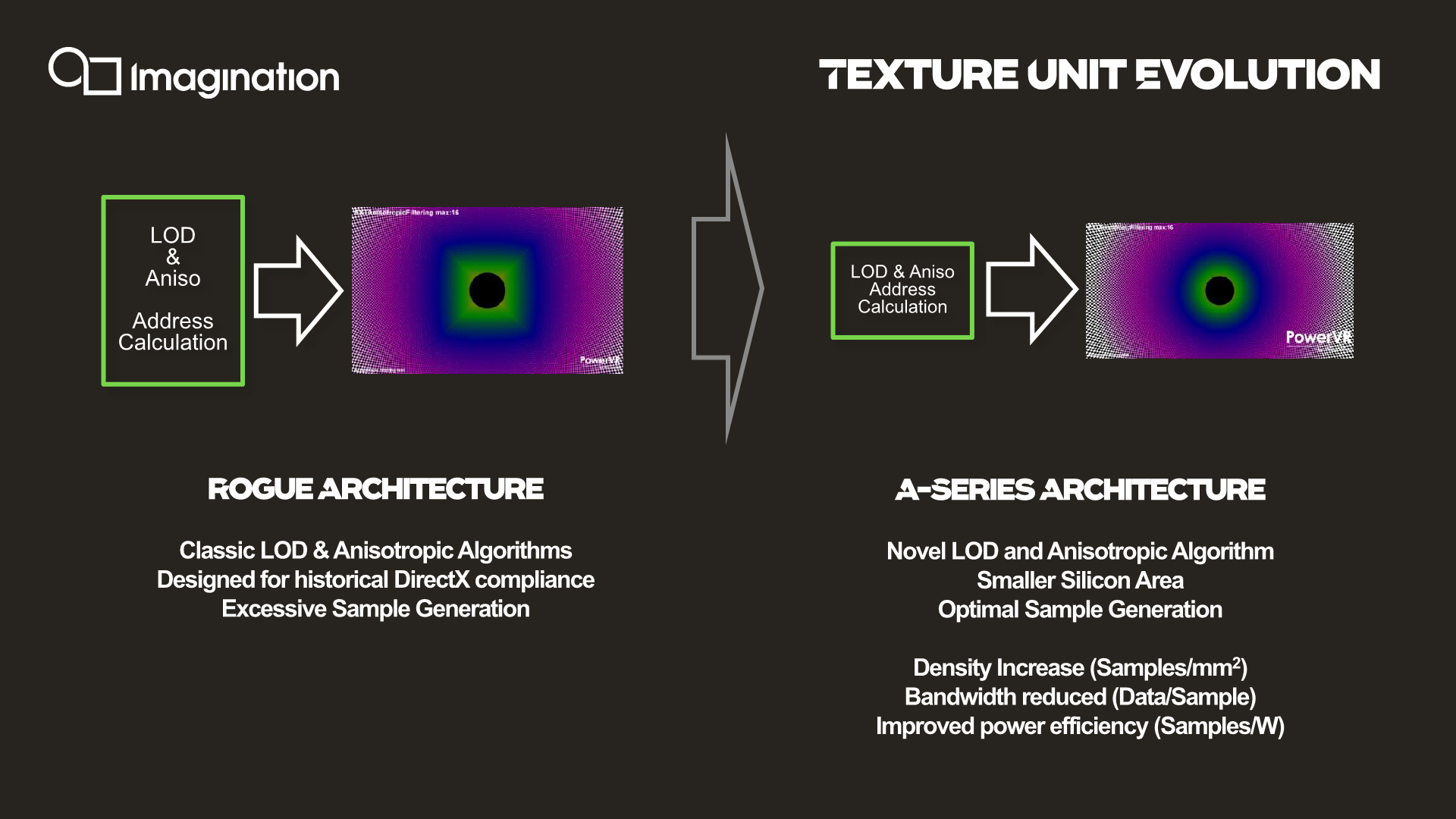
Imagination also talks about how the anisotropic filtering quality of the new architecture is much improved. In a set of comparison screenshots using a traditional texture tunnel, Imagination is showcasing that its new anisotropic filtering algorithms are far closer to being angle-independent – the ideal outcome for aniso filtering – as opposed to angle-dependent filtering with rather hard 90 degree angles on Rogue. Interestingly, Imagination is claiming that they've achieved this improved angle-independence even with fewer fewer samples, all of which serves to improve their efficiency and hardware density. With all of that said, since the comparison is against the Rogue architecture, I’m not entirely sure if it’s an actual novelty of the A-Series or rather a rehash of the anisotropic improvements that already got introduced in the 9XM series last year.
Another change in the fixed function units is found in the pixel pipeline, although superficially the throughput here doesn’t change compared to what we’ve seen on Furian. There’s still up to two PBEs with throughputs of up to 4 pixels per clock, and the design houses two such units for a total of 8 pixels per clock per SPU. There’s actually more internal distinction of the units though – at the front and back core it’s still able to handle 16 pixels per clock and also blend at 16 pixels per clock, although it’s limited on write out to 8 PPC on 1:1 pixel:texture situations.
Imagination’s doubling of the texture throughput whilst maintaining a steady pixel throughput means that the company is generally matching the decreasing pixel:texel fillrate throughput ratio we’ve also seen in other architectures such as from Qualcomm as well as the new Mali-G77, and now falls in at a 1:2 pixel:texel for the A-series.
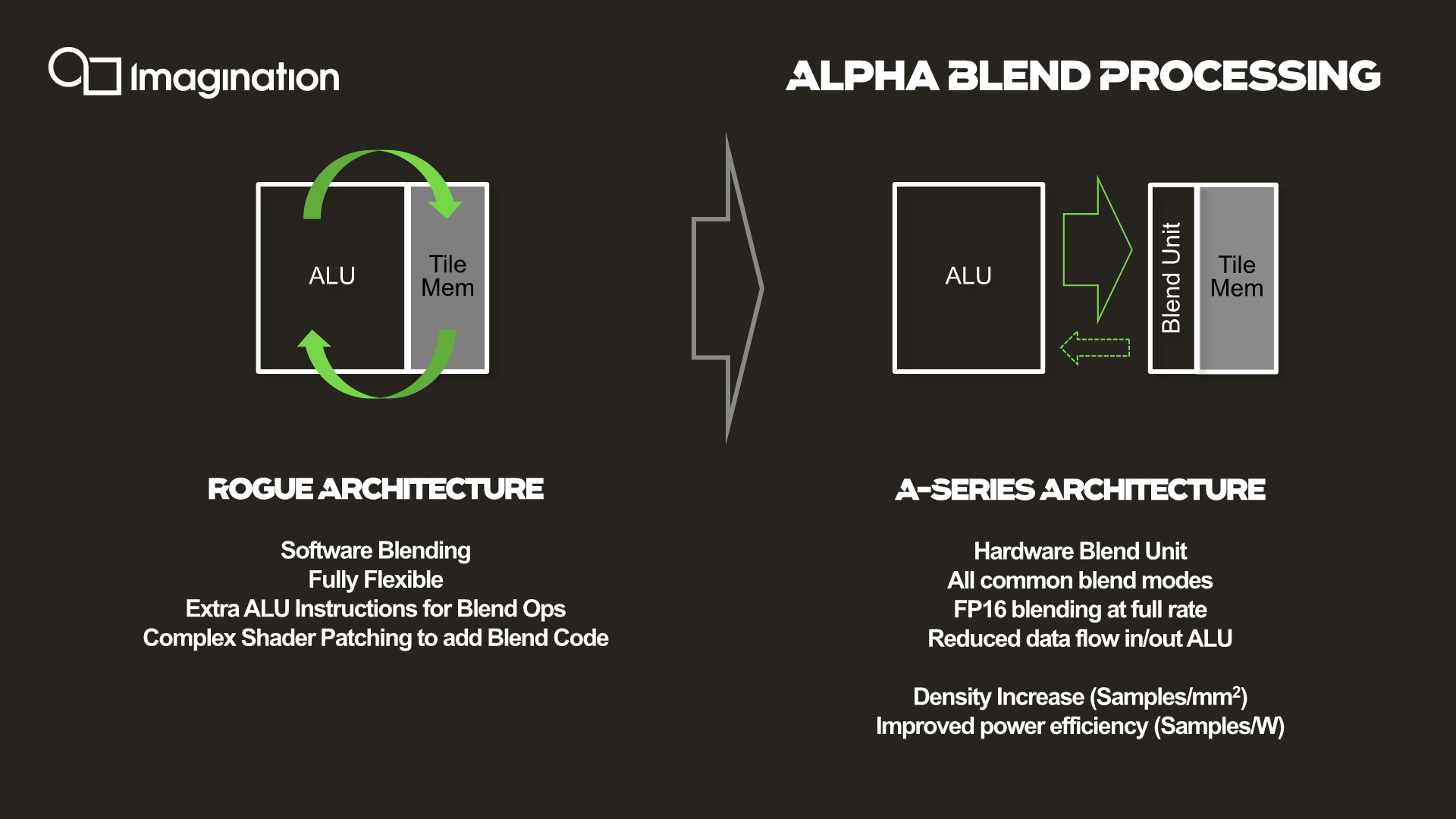
Alpha blending is now done on a dedicated hardware unit in the pixel pipeline instead of being computed by the ALUs. The change results in higher performance through the use of fixed function hardware, allowing for things such as FP16 blending at full rate, and frees up the ALUs themselves so that they can use their computation resources on other work. Density is improved, but more importantly it’s also improving power efficiency as it’s avoiding using more expensive and less task-specific hardware for the same tasks.
It’s to be noted that for the AXM series, the company uses customized fixed function units that are more area efficient, rather than just only scaling the numbers of units.
Scaling Things Up
With the SPU being the coarsest scaling block of the architecture, Imagination is building larger GPU configurations by simply adding in more SPUs. Essentially this is the “core” scaling of Imagination's GPU designs.
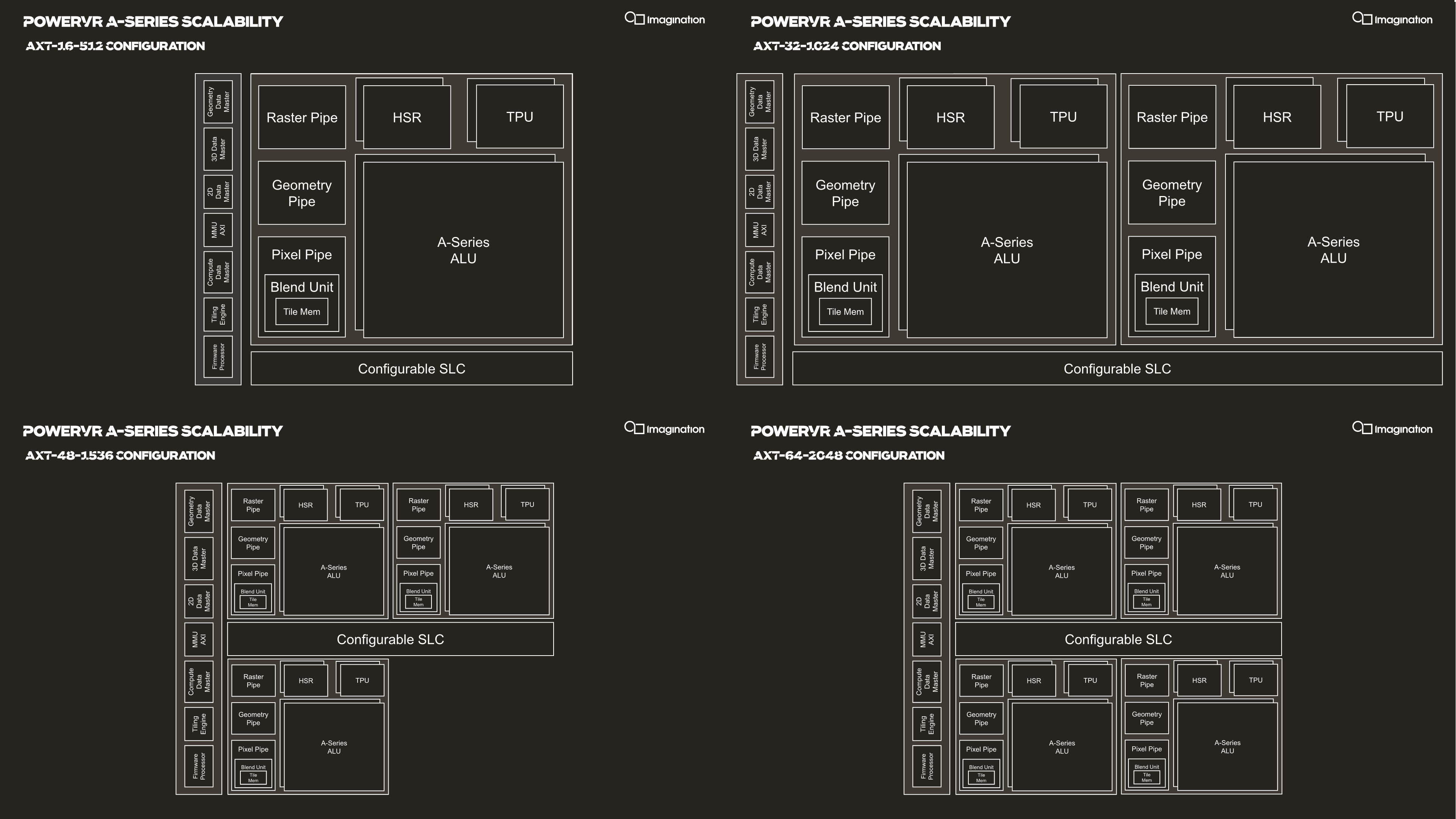
Scaling of SPUs across the AXT line happens in multiples of 16-512 across the range, both in terms of their product names as well as their texture and FLOPs/clock capabilities, which is rather simple to grasp and very quickly understand a configuration’s capabilities. As mentioned in the introduction, Imagination views the AXT-32-1024 as being the most popular choice for vendors targeting the high-end premium smartphone SoC segment, which possibly some vendors opting to go with the AXT-48-1536 for a larger area and lower clock speeds for more efficiency. The AXT-64-2048 would be a really big GPU which the company could build if there’s costumer interest.
| PowerVR GPU Comparison | ||||
| AXT-16-512 | GT9524 | GT8525 | GT7200 Plus | |
| Core Configuration |
1 SPU (Shader Processing Unit) - "GPU Core" 2 USCs (Unified Shading Clusters) - ALU Clusters |
|||
| FP32 FLOPS/Clock MADD = 2 FLOPs MUL = 1 FLOP |
512 (2x (128x MADD)) |
240 (2x (40x MADD+MUL)) |
192 (2x (32x MADD+MUL)) |
128 (2x (16x MADD+MADD)) |
| FP16 Ratio | 2:1 (Vec2) | |||
| Pixels / Clock | 8 | 4 | ||
| Texels / Clock | 16 | 8 | 4 | |
| Architecture | A-Series (Albiorix) |
Series-9XTP (Furian) |
Series-8XT (Furian) |
Series-7XT (Rogue) |
Comparing the smallest AXT-16-512 configuration with a single SPU and two USCs against similar configurations across the generations, we indeed see that the new A-Series does bring large architectural changes.
Imagination is marketing a 4x increase in ALU throughput, but again that’s against the 9XM GPUs, which are equal in ALU configuration to the Series-7XT in the table. However, it’s not to say that the increases aren’t any less impressive when comparing to the previous 9XTP family; a rise from 240 FLOPs/clock to 512 is still a 2.13x increase.
I think what’s actually more important to note here is the architecture has very big building blocks. At 512 FLOPs and 8 pixels per clock, an AXT SPU is significantly bigger than an Arm Mali-G77 core which comes in at “only” 64 FLOPs/clock and 2 pixels per clock, meaning an AXT core is roughly equivalent to eight G77 cores in computational power and four G77s in fillrate throughput, which is a massive difference in terms of design scaling. Naturally, in terms of effective density and power efficiency, few big cores will always win over a flock of small cores, as demonstrated by Qualcomm and Apple’s recent 2- and 4-core designs.








143 Comments
View All Comments
Eliadbu - Tuesday, December 3, 2019 - link
Same as Nvidia AMD Apple ARM and almost all other fabless manufacturers "bring it out". Actual manufacturing is one part of story of creating and bringing processor to life.mode_13h - Wednesday, December 4, 2019 - link
Actually, like *none* of those! Those guys all sell chips.Imagination sells IP to other companies, which bundle it into their SoCs. However, Imagination still needs to work with fabs to make their design compatible with the process nodes customers are likely to want to use.
mode_13h - Wednesday, December 4, 2019 - link
Oops, I see you said ARM. Okay, so that's the one example that's like Imagination - ARM doesn't sell chips, either.rpg1966 - Monday, December 2, 2019 - link
"currently there’s no publicly announced or available chips which make use of the company’s 8XT or 9XTP designs"Does this mean they went through two entire design processes with zero sales? Surely not?
rpg1966 - Monday, December 2, 2019 - link
nvm, that's just the XT series, it seems.Spunjji - Tuesday, December 3, 2019 - link
Yeah, I think they only really ever sold those larger GPUs to Apple before.melgross - Tuesday, December 3, 2019 - link
Correct.ABR - Tuesday, December 3, 2019 - link
Nice article, but need to see products to see it working in practice. So how about that RDNA architecture article? There are a few out there now, working off of AMD's material, but it would be nice to see AT's perspective on how much it resets the competition with Nvidia, and what we could expect Samsung will be able to come up with out of it on mobile.mode_13h - Wednesday, December 4, 2019 - link
Nobody knows the precise details of the AMD/Samsung collaboration, so it's really hard to speculate on how the result will turn out.techjam - Tuesday, December 3, 2019 - link
Exciting news! Hopefully this will push Qualcomm to up their game. Not that the Adreno GPU's are bad but the yearly increases are fairly modest.One concern though, that naming scheme is awful. Starting with A and moving down to D? Seriously?